Baza danych typu lake
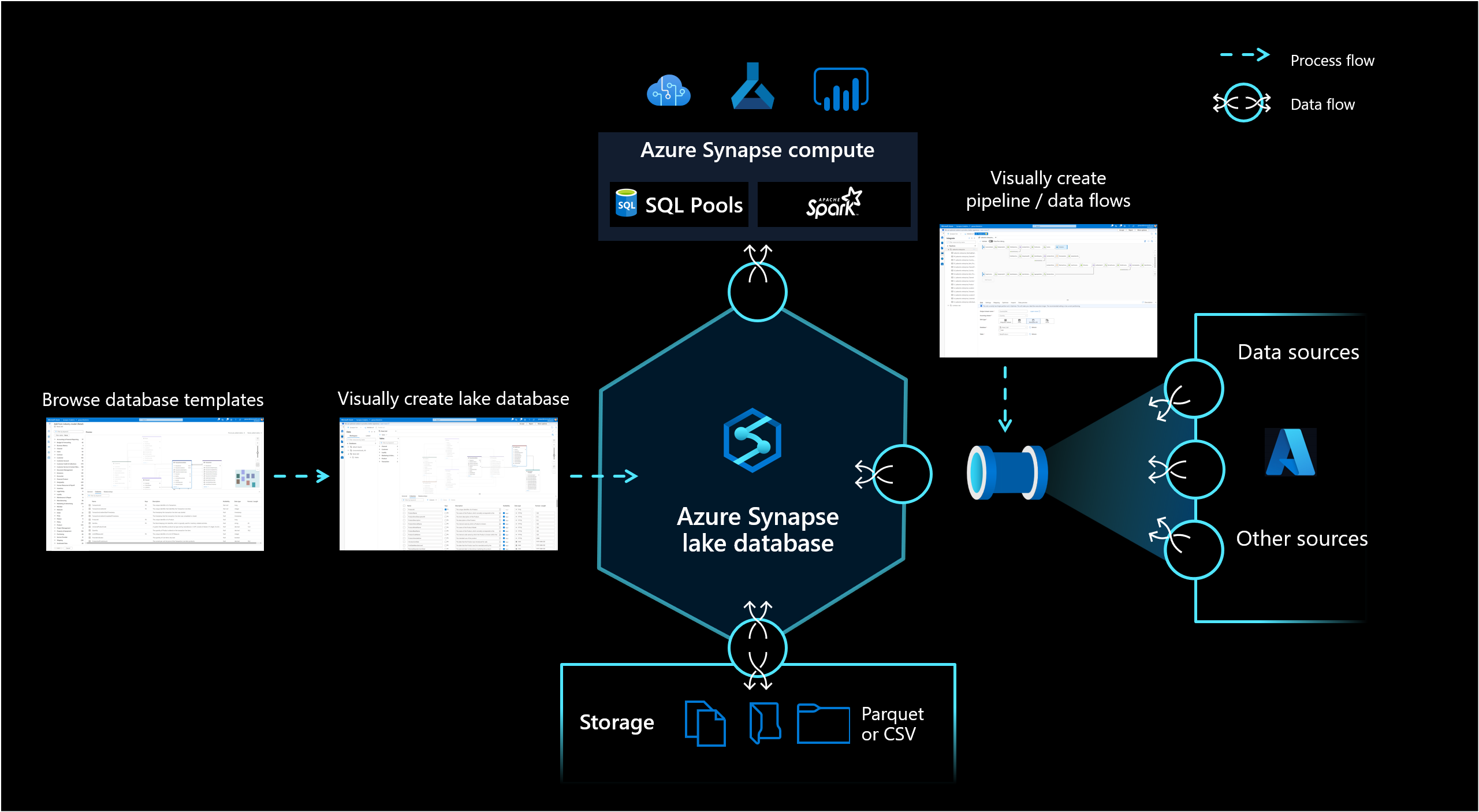
Baza danych lake w usłudze Azure Synapse Analytics umożliwia klientom łączenie projektu bazy danych, metadanych informacji o przechowywanych danych oraz możliwość opisania sposobu i miejsca przechowywania danych. Baza danych typu Lake rozwiązuje problem z dzisiejszymi magazynami danych, w których trudno zrozumieć, jak dane są ustrukturyzowane.
Projektant bazy danych
Nowy projektant bazy danych w programie Synapse Studio umożliwia utworzenie modelu danych dla bazy danych typu lake i dodanie do niej dodatkowych informacji. Każdą jednostkę i atrybut można opisać, aby uzyskać więcej informacji na temat modelu, który zawiera nie tylko jednostki, ale także relacje. W szczególności niezdolność do modelowania relacji była wyzwaniem dla interakcji z usługą Data Lake. To wyzwanie zostało teraz rozwiązane za pomocą zintegrowanego projektanta, który zapewnia możliwości, które były dostępne w bazach danych, ale nie w jeziorze. Ponadto możliwość dodawania opisów i możliwych wartości demonstracyjnych do modelu umożliwia osobom korzystającym z niego w przyszłości uzyskanie informacji, w których będą potrzebne, aby lepiej zrozumieć dane.
Uwaga
Maksymalny rozmiar metadanych w bazie danych typu lake wynosi 10 GB. Próba opublikowania lub zaktualizowania modelu przekraczającego 10 GB rozmiaru zakończy się niepowodzeniem. Aby rozwiązać ten problem, zmniejsz rozmiar modelu, usuwając tabele i kolumny. Rozważ podzielenie dużych modeli na wiele baz danych lake, aby uniknąć tego limitu.
Magazyn danych
Bazy danych typu Lake używają magazynu typu data lake na koncie usługi Azure Storage do przechowywania danych bazy danych. Dane mogą być przechowywane w formacie Parquet, Delta lub CSV, a różne ustawienia mogą służyć do optymalizacji magazynu. Każda baza danych typu lake używa połączonej usługi do definiowania lokalizacji głównego folderu danych. Dla każdej jednostki oddzielne foldery są tworzone domyślnie w tym folderze bazy danych w usłudze Data Lake. Domyślnie wszystkie tabele w bazie danych typu lake używają tego samego formatu, ale formaty i lokalizację danych można zmienić na jednostkę, jeśli jest to wymagane.
Uwaga
Publikowanie bazy danych typu lake nie tworzy żadnych podstawowych struktur ani schematów potrzebnych do wykonywania zapytań dotyczących danych na platformie Spark lub w języku SQL. Po opublikowaniu załaduj dane do bazy danych lake przy użyciu potoków , aby rozpocząć wykonywanie zapytań.
Obecnie obsługa formatu delta dla baz danych typu lake nie jest obsługiwana w programie Synapse Studio.
Synchronizacja obiektów bazy danych typu lake między magazynem a usługą Synapse jest jednokierunkowa. Pamiętaj, aby wykonać wszelkie modyfikacje tworzenia lub schematu obiektów bazy danych typu lake przy użyciu projektanta bazy danych w programie Synapse Studio. Jeśli zamiast tego wprowadzisz takie zmiany z platformy Spark lub bezpośrednio w magazynie, definicje baz danych typu lake staną się nieaktualne. W takim przypadku w projektancie baz danych mogą być widoczne stare definicje bazy danych lake. Aby zsynchronizować bazy danych typu lake, należy replikować i publikować takie zmiany w projektancie baz danych.
Obliczenia bazy danych
Baza danych lake jest uwidaczniana w bezserwerowej puli SQL usługi Synapse SQL, a platforma Apache Spark zapewnia użytkownikom możliwość oddzielenia magazynu od zasobów obliczeniowych. Metadane skojarzone z bazą danych lake ułatwiają korzystanie z różnych aparatów obliczeniowych nie tylko w celu zapewnienia zintegrowanego środowiska, ale także używania dodatkowych informacji (na przykład relacji), które nie były pierwotnie obsługiwane w usłudze Data Lake.
Powiązana zawartość
Kontynuuj eksplorowanie możliwości projektanta bazy danych, korzystając z poniższych linków.