Omówienie i dostosowywanie jednostek przesyłania strumieniowego usługi Stream Analytics
Omówienie jednostki przesyłania strumieniowego i węzła przesyłania strumieniowego
Jednostki przesyłania strumieniowego (SU) reprezentują zasoby obliczeniowe przydzielone do wykonania zadania usługi Stream Analytics. Im większa liczba jednostek przesyłania strumieniowego, tym większa ilość zasobów procesora i pamięci jest przydzielana do zadania. Ta pojemność pozwala skupić się na logice zapytań i abstrakcjach konieczność zarządzania sprzętem w celu uruchomienia zadania usługi Stream Analytics w odpowiednim czasie.
Usługa Azure Stream Analytics obsługuje dwie struktury jednostek przesyłania strumieniowego: SU V1 (do wycofania) i SU V2(zalecane).
Model SU V1 to oryginalna oferta usługi Azure Stream Analytics (ASA), w której każde 6 jednostek przesyłania strumieniowego odpowiada jednemu węzłowi przesyłania strumieniowego dla zadania. Zadania mogą być uruchamiane z 1 i 3 jednostkami SU, a także odpowiadają ułamkowemu węzłom przesyłania strumieniowego. Skalowanie odbywa się w przyrostach 6 poza 6 zadaniami przesyłania strumieniowego, do 12, 18, 24 i nowszych, dodając więcej węzłów przesyłania strumieniowego, które zapewniają rozproszone zasoby obliczeniowe.
Model SU V2 (zalecane) to uproszczona struktura z korzystnymi cenami dla tych samych zasobów obliczeniowych. W modelu SU V2 1 jednostka SU V2 odpowiada jednemu węzłowi przesyłania strumieniowego dla zadania. 2 SU V2s odpowiada 2, 3 do 3 itd. Zadania z 1/3 i 2/3 jednostki SU V2 są również dostępne w jednym węźle przesyłania strumieniowego, ale ułamek zasobów obliczeniowych. Zadania 1/3 i 2/3 SU V2 zapewniają ekonomiczną opcję dla obciążeń wymagających mniejszej skali.
Podstawowa moc obliczeniowa jednostek przesyłania strumieniowego w wersji 1 i 2 jest następująca:
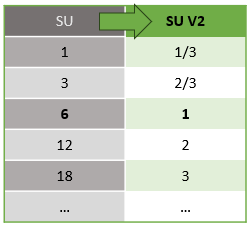
Aby uzyskać informacje na temat cen jednostek SU, odwiedź stronę cennika usługi Azure Stream Analytics.
Omówienie konwersji jednostek przesyłania strumieniowego i ich zastosowania
Istnieje automatyczna konwersja jednostek przesyłania strumieniowego, która występuje z warstwy interfejsu API REST do interfejsu użytkownika (witryna Azure Portal i program Visual Studio Code). Ta konwersja jest również widoczna w dzienniku aktywności, gdzie wartości SU są inne niż wartości w interfejsie użytkownika. Takie zachowanie jest wykonywane zgodnie z projektem i przyczyną jest to, że pola interfejsu API REST są ograniczone do wartości całkowitych, a zadania usługi ASA obsługują węzły ułamkowe (1/3 i 2/3 jednostki przesyłania strumieniowego). Interfejs użytkownika usługi ASA wyświetla wartości węzłów 1/3, 2/3, 1, 2, 3, ... itp., podczas gdy zaplecze (dzienniki aktywności, warstwa interfejsu API REST) wyświetla te same wartości pomnożone przez 10 co 3, 7, 10, 20, 30 odpowiednio.
| Standardowa | Standardowa V2 (UI) | Standardowa V2 (zaplecze, takie jak dzienniki, interfejs API REST itp.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Dzięki temu możemy przekazać ten sam stopień szczegółowości i wyeliminować punkt dziesiętny w warstwie interfejsu API dla jednostek SKU w wersji 2. Ta konwersja jest automatyczna i nie ma wpływu na wydajność zadania.
Omówienie użycia i wykorzystania pamięci
W celu uzyskania małych opóźnień przetwarzania strumieni całe przetwarzanie dla zadań usługi Azure Stream Analytics jest wykonywane w pamięci. Gdy zabraknie pamięci, zadanie przesyłania strumieniowego kończy się niepowodzeniem. W związku z tym w przypadku zadania produkcyjnego ważne jest monitorowanie użycia zasobów zadania przesyłania strumieniowego i upewnienie się, że przydzielono wystarczający zasób, aby utrzymać zadania uruchomione 24/7.
Metryka procentowego wykorzystania jednostek przesyłania strumieniowego, która waha się od 0% do 100%, opisuje zużycie pamięci obciążenia. W przypadku zadania przesyłania strumieniowego z minimalnym zużyciem ta metryka zwykle wynosi od 10% do 20%. Jeśli wykorzystanie jednostek SU% jest wysokie (powyżej 80%), lub jeśli zdarzenia wejściowe zostaną wycofane (nawet przy niskim wykorzystaniu jednostek przesyłania strumieniowego, ponieważ nie pokazuje użycia procesora CPU), obciążenie prawdopodobnie wymaga większej liczby zasobów obliczeniowych, co wymaga zwiększenia liczby jednostek przesyłania strumieniowego. Najlepiej zachować metryki SU poniżej 80%, aby uwzględnić okazjonalne wzrosty. Aby reagować na zwiększone obciążenia i zwiększyć liczbę jednostek przesyłania strumieniowego, rozważ ustawienie alertu o wartości 80% dla metryki Wykorzystanie jednostek przesyłania strumieniowego. Ponadto możesz użyć metryk opóźnienia znaku wodnego i zdarzeń zaległych, aby sprawdzić, czy istnieje wpływ.
Konfigurowanie jednostek przesyłania strumieniowego usługi Stream Analytics (SU)
Zaloguj się do Portalu Azure.
Na liście zasobów znajdź zadanie usługi Stream Analytics, które chcesz skalować, a następnie otwórz je.
Na stronie zadania w obszarze Konfigurowanie nagłówka wybierz pozycję Skaluj. Domyślna liczba jednostek jednostki SU to 1 podczas tworzenia zadania.
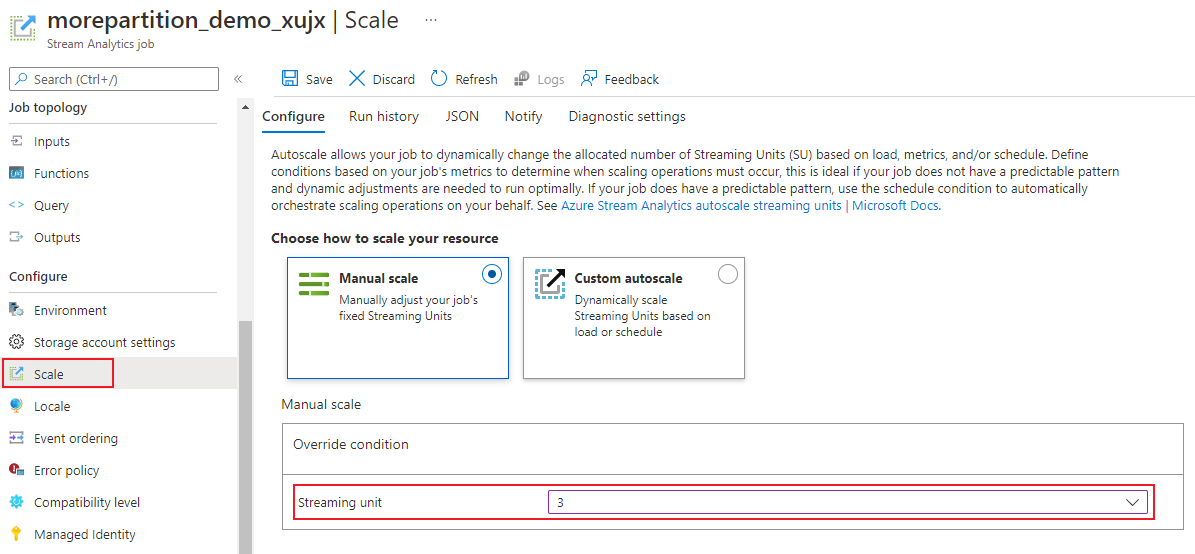
Wybierz opcję SU na liście rozwijanej, aby ustawić jednostki SU dla zadania. Zwróć uwagę, że masz ograniczenie do określonego zakresu jednostek SU.
Możesz zmienić liczbę jednostek jednostki SU przypisanych do zadania podczas jego działania. Możesz ograniczyć wybór spośród zestawu wartości SU, gdy zadanie jest uruchomione, jeśli zadanie używa danych wyjściowych bez partycjonowania. Lub ma zapytanie wieloetapowe z różnymi wartościami PARTITION BY.
Monitorowanie wydajności zadań
Za pomocą witryny Azure Portal można śledzić metryki związane z wydajnością zadania. Aby dowiedzieć się więcej o definicji metryk, zobacz Metryki zadań usługi Azure Stream Analytics. Aby dowiedzieć się więcej na temat monitorowania metryk w portalu, zobacz Monitorowanie zadania usługi Stream Analytics za pomocą witryny Azure Portal.
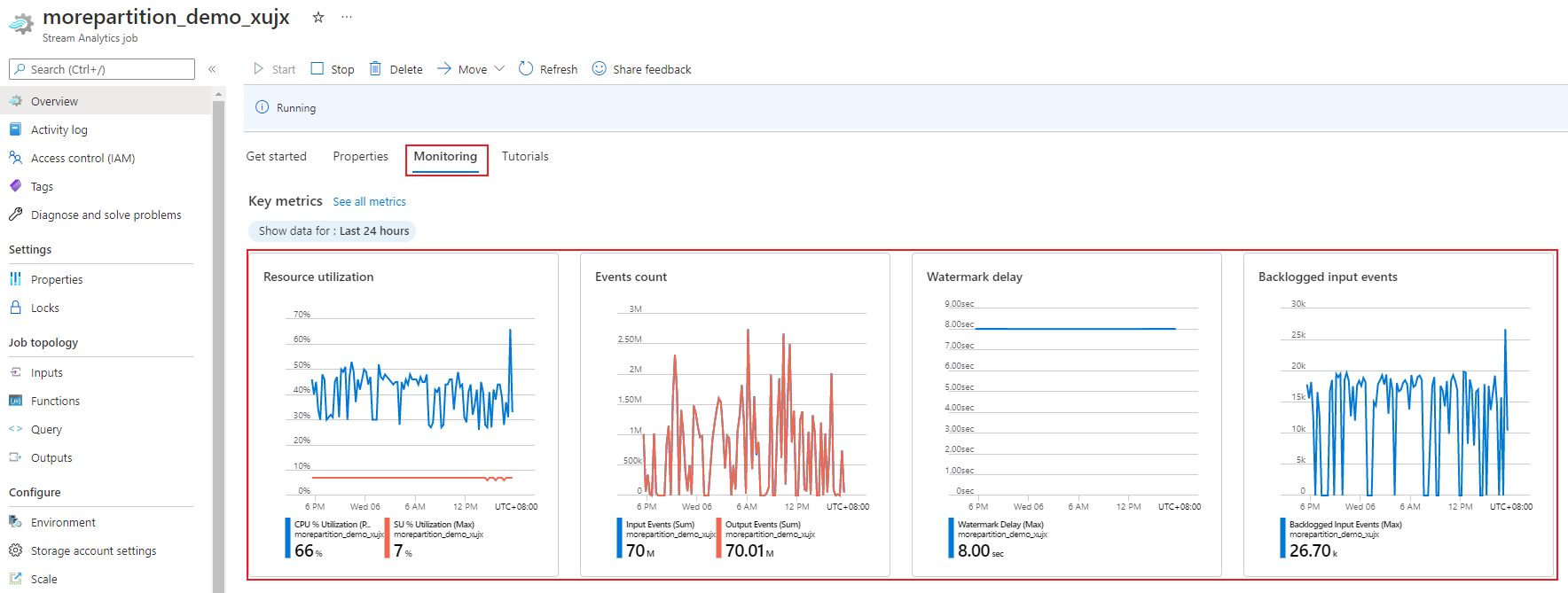
Oblicz oczekiwaną przepływność obciążenia. Jeśli przepływność jest mniejsza niż oczekiwano, dostosuj partycję wejściową, dostosuj zapytanie i dodaj jednostki SU do zadania.
How many SUs are required for a job? (Ile jednostek przesyłania strumieniowego jest wymaganych dla zadania?)
Wybranie liczby wymaganych jednostek SU dla określonego zadania zależy od konfiguracji partycji dla danych wejściowych i zapytania zdefiniowanego w zadaniu. Na stronie Skalowanie można ustawić odpowiednią liczbę jednostek jednostki SU. Najlepszym rozwiązaniem jest przydzielenie większej liczby jednostek jednostki jednostki SU niż jest to konieczne. Aparat przetwarzania usługi Stream Analytics optymalizuje opóźnienia i przepływność kosztem przydzielania dodatkowej pamięci.
Ogólnie rzecz biorąc, najlepszym rozwiązaniem jest rozpoczęcie od 1 SU V2 dla zapytań, które nie używają PARTYCJI BY. Następnie określ słodką plamę przy użyciu metody próbnej i błędu, w której należy zmodyfikować liczbę jednostek przesyłania strumieniowego po przekazaniu reprezentatywnych ilości danych i przeanalizować metrykę Wykorzystanie jednostek SU%. Maksymalna liczba jednostek przesyłania strumieniowego, które mogą być używane przez zadanie usługi Stream Analytics, zależy od liczby kroków w zapytaniu zdefiniowanym dla zadania i liczby partycji w każdym kroku. Więcej informacji na temat limitów można znaleźć tutaj.
Aby uzyskać więcej informacji na temat wybierania odpowiedniej liczby jednostek przesyłania strumieniowego, zobacz tę stronę: Skalowanie zadań usługi Azure Stream Analytics w celu zwiększenia przepływności.
Uwaga
Wybór liczby jednostek ściągnięć dla określonego zadania zależy od konfiguracji partycji dla danych wejściowych i zapytania zdefiniowanego dla zadania. Możesz wybrać limit przydziału w jednostkach jednostki SU dla zadania. Aby uzyskać informacje na temat limitu przydziału subskrypcji usługi Azure Stream Analytics, odwiedź stronę Limity usługi Stream Analytics. Aby zwiększyć liczbę jednostek jednostki ru dla subskrypcji poza tym limitem przydziału, skontaktuj się z pomoc techniczna firmy Microsoft. Prawidłowe wartości jednostek SU na zadanie to 1/3, 2/3, 1, 2, 3 itd.
Czynniki zwiększające procentowe wykorzystanie jednostek przesyłania strumieniowego
Elementy zapytania czasowego (zorientowane na czas) to podstawowy zestaw operatorów stanowych udostępnianych przez usługę Stream Analytics. Usługa Stream Analytics zarządza stanem tych operacji wewnętrznie w imieniu użytkownika, zarządzając zużyciem pamięci, punktami kontrolnymi na potrzeby odporności i odzyskiwaniem stanu podczas uaktualniania usługi. Mimo że usługa Stream Analytics w pełni zarządza stanami, istnieje wiele zaleceń dotyczących najlepszych rozwiązań, które użytkownicy powinni rozważyć.
Zadanie ze złożoną logiką zapytań może mieć wysokie wykorzystanie jednostek przesyłania strumieniowego nawet wtedy, gdy nie odbiera stale zdarzeń wejściowych. Może się to zdarzyć po nagłym skoku liczby zdarzeń wejściowych i wyjściowych. Zadanie może nadal utrzymywać stan w pamięci, jeśli zapytanie jest złożone.
Wykorzystanie SU% może nagle spaść do 0 przez krótki okres, zanim wróci do oczekiwanych poziomów. Dzieje się tak z powodu przejściowych błędów lub uaktualnień zainicjowanych przez system. Zwiększenie liczby jednostek przesyłania strumieniowego dla zadania może nie zmniejszyć wykorzystania jednostek SU%, jeśli zapytanie nie jest w pełni równoległe.
Porównując wykorzystanie w danym okresie, użyj metryk szybkości zdarzeń. Metryki InputEvents i OutputEvents pokazują, ile zdarzeń zostało odczytanych i przetworzonych. Istnieją również metryki wskazujące liczbę zdarzeń błędów, takie jak błędy deserializacji. W przypadku wzrostu liczby zdarzeń na jednostkę czasu liczba jednostek SU% zwiększa się w większości przypadków.
Logika zapytań stanowych w elementach czasowych
Jedną z unikatowych funkcji zadania usługi Azure Stream Analytics jest wykonywanie przetwarzania stanowego, takiego jak agregacje okienne, sprzężenia czasowe i funkcje analityczne czasowe. Każdy z tych operatorów przechowuje informacje o stanie. Maksymalny rozmiar okna dla tych elementów zapytania wynosi siedem dni.
Koncepcja okna czasowego pojawia się w kilku elementach zapytania usługi Stream Analytics:
Agregacje okienne: GROUP BY of Tumbling, Hopping i Przesuwane okna
Sprzężenia czasowe: JOIN with DATEDIFF, funkcja
Funkcje analityczne czasowe: ISFIRST, LAST i LAG z CZASEM TRWANIA LIMITU
Następujące czynniki wpływają na użycie pamięci (część metryki jednostek przesyłania strumieniowego) przez zadania usługi Stream Analytics:
Agregacje okienne
Pamięć zużywana (rozmiar stanu) dla agregacji okien nie zawsze jest proporcjonalna bezpośrednio do rozmiaru okna. Zamiast tego zużywana pamięć jest proporcjonalna do kardynalności danych lub liczby grup w każdym przedziale czasu.
Na przykład w poniższym zapytaniu liczba skojarzona z clusterid nią jest kardynalnością zapytania.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Aby rozwiązać wszelkie problemy spowodowane wysoką kardynalnością w poprzednim zapytaniu, można wysyłać zdarzenia do usługi Event Hubs podzielone na partycje według clusterid, a następnie skalować zapytanie w poziomie, umożliwiając systemowi przetwarzanie poszczególnych partycji wejściowych oddzielnie przy użyciu funkcji PARTITION BY , jak pokazano w poniższym przykładzie:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Po podzieleniu zapytania na partycje jest ono rozłożone na wiele węzłów. W rezultacie liczba wartości przychodzących clusterid do każdego węzła jest zmniejszana, zmniejszając kardynalność grupy według operatora.
Partycje usługi Event Hubs powinny być partycjonowane przez klucz grupowania, aby uniknąć konieczności wykonania kroku redukcji. Aby uzyskać więcej informacji, zobacz Omówienie usługi Event Hubs.
Sprzężenia czasowe
Ilość zużytej pamięci (rozmiar stanu) sprzężenia czasowego jest proporcjonalna do liczby zdarzeń w tymczasowym pomieszczeniu przełącznika sprzężenia, co jest współczynnikiem wprowadzania zdarzeń pomnożonym przez rozmiar pokoju wiggle. Innymi słowy, pamięć zużywana przez sprzężenia jest proporcjonalna do zakresu czasu DateDiff pomnożonego przez średni współczynnik zdarzeń.
Liczba niezgodnych zdarzeń w sprzężeniu wpływa na wykorzystanie pamięci dla zapytania. Następujące zapytanie służy do znajdowania wyświetleń reklam, które generują kliknięcia:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
W tym przykładzie jest możliwe, że wiele reklam jest wyświetlanych, a kilka osób klika je i musi zachować wszystkie zdarzenia w przedziale czasu. Używana pamięć jest proporcjonalna do wielkości okna i szybkości zdarzeń.
Aby skorygować to zachowanie, wyślij zdarzenia do usługi Event Hubs partycjonowane przez klucze sprzężenia (w tym przypadku identyfikator) i przeprowadź skalowanie zapytania w poziomie, umożliwiając systemowi przetwarzanie poszczególnych partycji wejściowych oddzielnie przy użyciu partycji WEDŁUG , jak pokazano poniżej:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Po podzieleniu zapytania na partycje jest ono rozłożone na wiele węzłów. W rezultacie liczba zdarzeń przychodzących do każdego węzła jest zmniejszana, zmniejszając tym samym rozmiar stanu przechowywanego w oknie sprzężenia.
Funkcje analityczne czasowe
Ilość zużytej pamięci (rozmiar stanu) funkcji analitycznej czasowej jest proporcjonalna do współczynnika zdarzeń pomnożonego przez czas trwania. Pamięć zużywana przez funkcje analityczne nie jest proporcjonalna do rozmiaru okna, ale raczej liczby partycji w każdym przedziale czasu.
Korygowanie jest podobne do sprzężenia czasowego. Zapytanie można skalować w poziomie przy użyciu funkcji PARTITION BY.
Bufor poza kolejnością
Użytkownik może skonfigurować rozmiar buforu poza kolejnością w okienku konfiguracji Zamawianie zdarzeń. Bufor jest używany do przechowywania danych wejściowych przez czas trwania okna i zmienia ich kolejność. Rozmiar buforu jest proporcjonalny do współczynnika wprowadzania zdarzeń pomnożoną przez rozmiar okna poza kolejnością. Domyślny rozmiar okna to 0.
Aby skorygować przepełnienie buforu poza kolejnością, przeprowadź skalowanie zapytania w poziomie przy użyciu funkcji PARTITION BY. Po podzieleniu zapytania na partycje jest ono rozłożone na wiele węzłów. W rezultacie liczba zdarzeń przychodzących do każdego węzła jest zmniejszana, co zmniejsza liczbę zdarzeń w każdym buforze zmiany kolejności.
Liczba partycji wejściowych
Każda partycja wejściowa zadania wejściowego ma bufor. Większa liczba partycji wejściowych, tym więcej zasobów zużywa zadanie. W przypadku każdej jednostki przesyłania strumieniowego usługa Azure Stream Analytics może przetwarzać około 7 MB/s danych wejściowych. W związku z tym można zoptymalizować, pasując do liczby jednostek przesyłania strumieniowego usługi Stream Analytics z liczbą partycji w centrum zdarzeń.
Zazwyczaj zadanie skonfigurowane przy użyciu jednostki przesyłania strumieniowego 1/3 jest wystarczające dla centrum zdarzeń z dwoma partycjami (co jest minimum dla centrum zdarzeń). Jeśli centrum zdarzeń ma więcej partycji, zadanie usługi Stream Analytics zużywa więcej zasobów, ale niekoniecznie używa dodatkowej przepływności udostępnianej przez usługę Event Hubs.
W przypadku zadania z 1 jednostką przesyłania strumieniowego w wersji 2 może być konieczne 4 lub 8 partycji z centrum zdarzeń. Należy jednak unikać zbyt wielu niepotrzebnych partycji, ponieważ powoduje to nadmierne użycie zasobów. Na przykład centrum zdarzeń z 16 partycjami lub większymi w zadaniu usługi Stream Analytics, które ma 1 jednostkę przesyłania strumieniowego.
Dane referencyjne
Dane referencyjne w usłudze ASA są ładowane do pamięci w celu szybkiego wyszukiwania. W przypadku bieżącej implementacji każda operacja sprzężenia z danymi referencyjnymi przechowuje kopię danych referencyjnych w pamięci, nawet jeśli wielokrotnie łączysz się z tymi samymi danymi referencyjnymi. W przypadku zapytań z funkcją PARTITION BY każda partycja ma kopię danych referencyjnych, więc partycje są w pełni oddzielone. Dzięki efektowi mnożnika użycie pamięci może szybko uzyskać bardzo duże, jeśli łączysz się z danymi referencyjnymi wiele razy z wieloma partycjami.
Korzystanie z funkcji funkcji zdefiniowanej przez użytkownika
Po dodaniu funkcji UDF usługa Azure Stream Analytics ładuje środowisko uruchomieniowe Języka JavaScript do pamięci, co wpływa na jednostki SU%.
Następne kroki
- Tworzenie równoległych zapytań w usłudze Azure Stream Analytics
- Skalowanie zadań usługi Azure Stream Analytics w celu zwiększenia przepływności
- Metryki zadań usługi Azure Stream Analytics
- Wymiary metryk zadań usługi Azure Stream Analytics
- Monitorowanie zadania usługi Stream Analytics za pomocą witryny Azure Portal
- Analizowanie wydajności zadań usługi Stream Analytics przy użyciu wymiarów metryk
- Opis i dostosowywanie jednostek przesyłania strumieniowego