Partycjonowanie danych wyjściowych niestandardowych obiektów blob w usłudze Azure Stream Analytics
Usługa Azure Stream Analytics obsługuje partycjonowanie niestandardowych danych wyjściowych obiektów blob z niestandardowymi polami lub atrybutami i niestandardowymi DateTime wzorcami ścieżek.
Pole niestandardowe lub atrybuty
Niestandardowe atrybuty pól lub danych wejściowych usprawniają podrzędne przepływy pracy przetwarzania danych i raportowania, umożliwiając większą kontrolę nad danymi wyjściowymi.
Opcje klucza partycji
Klucz partycji lub nazwa kolumny używane do partycjonowania danych wejściowych może zawierać dowolny znak akceptowany dla nazw obiektów blob. Nie można używać pól zagnieżdżonych jako klucza partycji, chyba że są one używane wraz z aliasami. Można jednak użyć niektórych znaków, aby utworzyć hierarchię plików. Aby na przykład utworzyć kolumnę łączącą dane z dwóch innych kolumn w celu utworzenia unikatowego klucza partycji, możesz użyć następującego zapytania:
SELECT name, id, CONCAT(name, "/", id) AS nameid
Klucz partycji musi mieć NVARCHAR(MAX)wartość , BIGINT, FLOATlub BIT (poziom zgodności 1.2 lub wyższy). Typy DateTime, Arrayi Records nie są obsługiwane, ale mogą być używane jako klucze partycji, jeśli są konwertowane na ciągi. Aby uzyskać więcej informacji, zobacz Typy danych usługi Azure Stream Analytics.
Przykład
Załóżmy, że zadanie pobiera dane wejściowe z sesji użytkownika na żywo połączonych z zewnętrzną usługą gier wideo, w której pozyskane dane zawierają kolumnę client_id identyfikującą sesje. Aby podzielić dane według client_id, ustaw pole wzorzec ścieżki obiektu blob, aby uwzględnić token {client_id} partycji we właściwościach wyjściowych obiektu blob podczas tworzenia zadania. Ponieważ dane z różnymi client_id wartościami przepływają przez zadanie usługi Stream Analytics, dane wyjściowe są zapisywane w osobnych folderach na podstawie pojedynczej client_id wartości na folder.

Podobnie, jeśli dane wejściowe zadania były danymi czujników z milionów czujników, w których każdy czujnik miał sensor_idwartość , wzorzec ścieżki będzie partycjonować {sensor_id} poszczególne dane czujnika do różnych folderów.
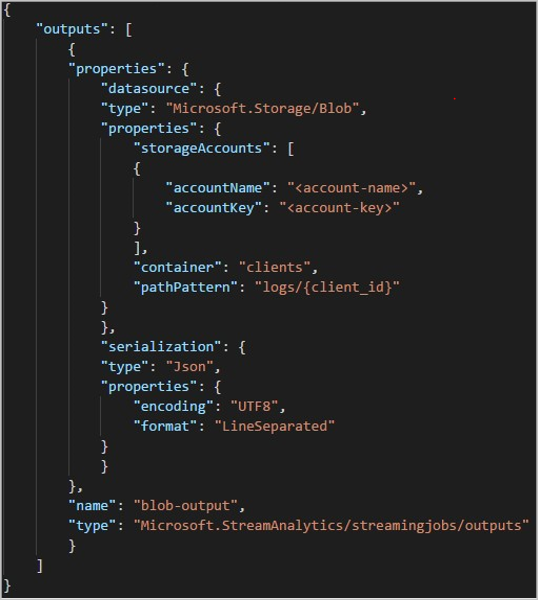
W przypadku korzystania z interfejsu API REST sekcja danych wyjściowych pliku JSON używanego dla tego żądania może wyglądać jak na poniższej ilustracji:
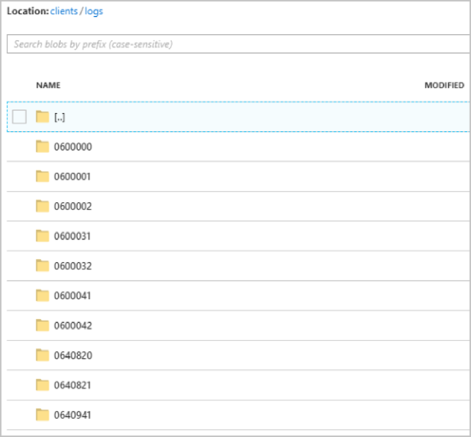
Po uruchomieniu clients zadania kontener może wyglądać jak na poniższej ilustracji:
Każdy folder może zawierać wiele obiektów blob, w których każdy obiekt blob zawiera co najmniej jeden rekord. W poprzednim przykładzie w folderze oznaczonym "06000000" następującą zawartością znajduje się pojedynczy obiekt blob:
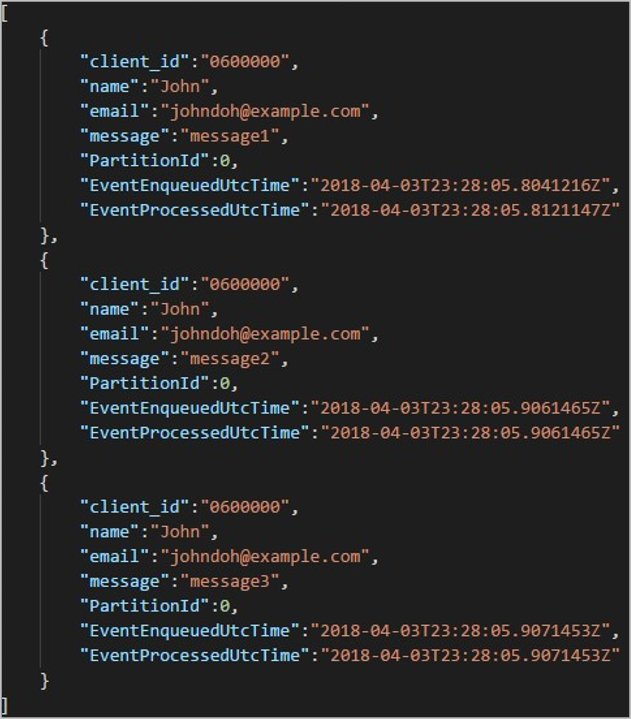
Zwróć uwagę, że każdy rekord w obiekcie blob ma kolumnę zgodną client_id z nazwą folderu, ponieważ kolumna używana do partycjonowania danych wyjściowych w ścieżce wyjściowej to client_id.
Ograniczenia
Tylko jeden niestandardowy klucz partycji jest dozwolony we właściwości wyjściowej obiektu blob wzorca ścieżki. Wszystkie następujące wzorce ścieżek są prawidłowe:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Jeśli klienci chcą użyć więcej niż jednego pola wejściowego, mogą utworzyć klucz złożony w zapytaniu o niestandardową partycję ścieżki w danych wyjściowych obiektu blob przy użyciu polecenia
CONCAT. Może to być na przykładselect concat (col1, col2) as compositeColumn into blobOutput from input. Następnie mogą określićcompositeColumnjako ścieżkę niestandardową w usłudze Azure Blob Storage.Klucze partycji są niewrażliwe na wielkość liter, więc klucze partycji, takie jak
Johnijohnsą równoważne. Ponadto wyrażenia nie mogą być używane jako klucze partycji. Na przykład{columnA + columnB}nie działa.Gdy strumień wejściowy składa się z rekordów z kardynalnością klucza partycji poniżej 8000, rekordy są dołączane do istniejących obiektów blob. W razie potrzeby tworzą tylko nowe obiekty blob. Jeśli kardynalność jest ponad 8000, nie ma gwarancji, że istniejące obiekty blob zostaną zapisane. Nowe obiekty blob nie zostaną utworzone dla dowolnej liczby rekordów z tym samym kluczem partycji.
Jeśli dane wyjściowe obiektu blob są konfigurowane jako niezmienne, usługa Stream Analytics tworzy nowy obiekt blob za każdym razem, gdy są wysyłane dane.
Niestandardowe wzorce ścieżki daty/godziny
Niestandardowe DateTime wzorce ścieżek umożliwiają określenie formatu wyjściowego zgodnego z konwencjami przesyłania strumieniowego Hive, dzięki czemu usługa Stream Analytics umożliwia wysyłanie danych do usług Azure HDInsight i Azure Databricks na potrzeby przetwarzania podrzędnego. Niestandardowe DateTime wzorce ścieżek są łatwo implementowane przy użyciu słowa kluczowego datetime w polu Prefiks ścieżki danych wyjściowych obiektu blob wraz z specyfikatorem formatu. Może to być na przykład {datetime:yyyy}.
Obsługiwane tokeny
Następujące tokeny specyfikatora formatu mogą być używane samodzielnie lub w połączeniu w celu osiągnięcia formatów niestandardowych DateTime .
| Specyfikator formatu | opis | Wyniki dla przykładowego czasu 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Rok jako czterocyfrowy numer | 2018 |
| {datetime:MM} | Miesiąc od 01 do 12 | 01 |
| {datetime:M} | Miesiąc od 1 do 12 | 1 |
| {datetime:dd} | Dzień od 01 do 31 | 02 |
| {datetime:d} | Dzień od 1 do 31 | 2 |
| {datetime:HH} | Godzina przy użyciu formatu 24-godzinnego z zakresu od 00 do 23 | 10 |
| {datetime:mm} | Minuty od 00 do 60 | 6 |
| {datetime:m} | Minuty od 0 do 60 | 6 |
| {datetime:ss} | Sekundy od 00 do 60 | 08 |
Jeśli nie chcesz używać wzorców niestandardowych DateTime , możesz dodać {date} token i/lub {time} do pola Prefiks ścieżki, aby wygenerować listę rozwijaną z wbudowanymi DateTime formatami.
Rozszerzalność i ograniczenia
Do osiągnięcia limitu znaków prefiksu ścieżki można użyć tylu tokenów ({datetime:<specifier>}), jak chcesz. Specyfikatory formatu nie mogą być łączone w ramach jednego tokenu poza kombinacjami wymienionymi już na liście rozwijanej daty i godziny.
Dla partycji ścieżki :logs/MM/dd
| Prawidłowe wyrażenie | Nieprawidłowe wyrażenie |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Możesz użyć tego samego specyfikatora formatu wiele razy w prefiksie ścieżki. Token musi być powtarzany za każdym razem.
Konwencje przesyłania strumieniowego Hive
Niestandardowe wzorce ścieżek dla usługi Blob Storage mogą być używane z konwencją przesyłania strumieniowego Hive, która oczekuje, że foldery zostaną oznaczone etykietą column= w nazwie folderu.
Może to być na przykład year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Dane wyjściowe niestandardowe eliminują problemy ze zmianą tabel i ręczne dodawanie partycji do danych portów między usługą Stream Analytics i programem Hive. Zamiast tego wiele folderów można dodawać automatycznie przy użyciu:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Przykład
Tworzenie konta magazynu, grupy zasobów, zadania usługi Stream Analytics i źródła danych wejściowych zgodnie z przewodnikiem Szybki start usługi Stream Analytics w witrynie Azure Portal . Użyj tych samych przykładowych danych używanych w przewodniku Szybki start. Przykładowe dane są również dostępne w usłudze GitHub.
Utwórz ujście danych wyjściowych obiektu blob przy użyciu następującej konfiguracji:
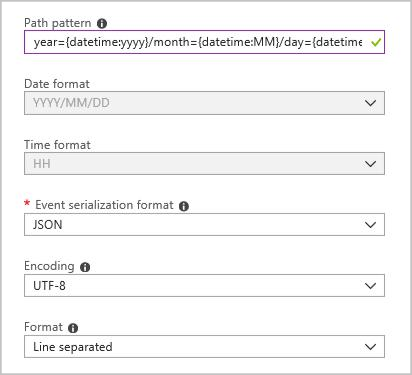
Wzorzec pełnej ścieżki to:
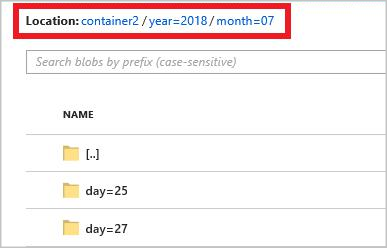
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Po uruchomieniu zadania struktura folderów oparta na wzorcu ścieżki jest tworzona w kontenerze obiektów blob. Możesz przejść do szczegółów na poziomie dnia.