Integrowanie usługi Azure Stream Analytics z usługą Azure Machine Learning
Modele uczenia maszynowego można zaimplementować jako funkcję zdefiniowaną przez użytkownika (UDF) w zadaniach usługi Azure Stream Analytics, aby wykonywać ocenianie i przewidywania w czasie rzeczywistym na danych wejściowych przesyłania strumieniowego. Usługa Azure Machine Learning umożliwia korzystanie z dowolnego popularnego narzędzia typu open source, takiego jak TensorFlow, scikit-learn lub PyTorch, do przygotowywania, trenowania i wdrażania modeli.
Wymagania wstępne
Przed dodaniem modelu uczenia maszynowego jako funkcji do zadania usługi Stream Analytics wykonaj następujące kroki:
Użyj usługi Azure Machine Learning, aby wdrożyć model jako usługę internetową.
Punkt końcowy uczenia maszynowego musi mieć skojarzony program Swagger , który pomaga usłudze Stream Analytics zrozumieć schemat danych wejściowych i wyjściowych. Możesz użyć tej przykładowej definicji struktury Swagger jako odwołania, aby upewnić się, że został on poprawnie skonfigurowany.
Upewnij się, że usługa internetowa akceptuje i zwraca dane serializowane w formacie JSON.
Wdróż model w usłudze Azure Kubernetes Service na potrzeby wdrożeń produkcyjnych na dużą skalę. Jeśli usługa internetowa nie może obsłużyć liczby żądań pochodzących z zadania, wydajność zadania usługi Stream Analytics będzie obniżona, co ma wpływ na opóźnienie. Modele wdrożone w usłudze Azure Container Instances są obsługiwane tylko w przypadku korzystania z witryny Azure Portal.
Dodawanie modelu uczenia maszynowego do zadania
Funkcje usługi Azure Machine Learning można dodać do zadania usługi Stream Analytics bezpośrednio z witryny Azure Portal lub programu Visual Studio Code.
Azure Portal
Przejdź do zadania usługi Stream Analytics w witrynie Azure Portal i wybierz pozycję Funkcje w obszarze Topologia zadania. Następnie wybierz pozycję Azure Machine Learning Service z menu rozwijanego + Dodaj .
Wypełnij formularz funkcji usługi Azure Machine Learning Service następującymi wartościami właściwości:
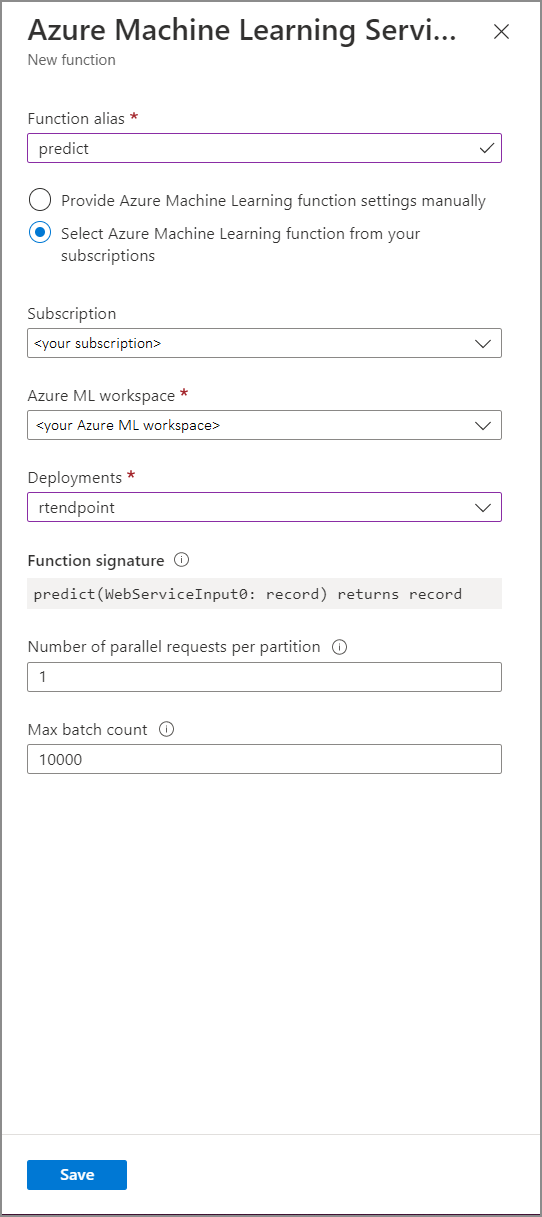
W poniższej tabeli opisano każdą właściwość funkcji usługi Azure Machine Learning Service w usłudze Stream Analytics.
| Właściwości | opis |
|---|---|
| Alias funkcji | Wprowadź nazwę, aby wywołać funkcję w zapytaniu. |
| Subskrypcja | Swoją subskrypcję platformy Azure. |
| Obszar roboczy usługi Azure Machine Learning | Obszar roboczy usługi Azure Machine Learning użyty do wdrożenia modelu jako usługi internetowej. |
| Punkt końcowy | Usługa internetowa hostująca model. |
| Podpis funkcji | Podpis usługi internetowej wywnioskowany ze specyfikacji schematu interfejsu API. Jeśli nie można załadować podpisu, sprawdź, czy podano przykładowe dane wejściowe i wyjściowe w skryfcie oceniania, aby automatycznie wygenerować schemat. |
| Liczba żądań równoległych na partycję | Jest to zaawansowana konfiguracja zoptymalizowana pod kątem wysokiej przepływności. Ta liczba reprezentuje współbieżne żądania wysyłane z każdej partycji zadania do usługi internetowej. Zadania z sześcioma jednostkami przesyłania strumieniowego (SU) i niższymi mają jedną partycję. Zadania z 12 jednostkami SU mają dwie partycje, 18 jednostek jednostki operacyjnego ma trzy partycje i tak dalej. Jeśli na przykład zadanie ma dwie partycje i ustawisz ten parametr na cztery, będzie osiem współbieżnych żądań z zadania do usługi internetowej. |
| Maksymalna liczba partii | Jest to zaawansowana konfiguracja optymalizacji przepływności na dużą skalę. Ta liczba reprezentuje maksymalną liczbę zdarzeń, które są wsadowe razem w jednym żądaniu wysyłanym do usługi internetowej. |
Wywoływanie punktu końcowego uczenia maszynowego z zapytania
Gdy zapytanie usługi Stream Analytics wywołuje funkcję zdefiniowanej przez użytkownika usługi Azure Machine Learning, zadanie tworzy serializowane żądanie JSON do usługi internetowej. Żądanie jest oparte na schemacie specyficznym dla modelu, który usługa Stream Analytics wywnioskuje z struktury swagger punktu końcowego.
Ostrzeżenie
Punkty końcowe usługi Machine Learning nie są wywoływane podczas testowania za pomocą edytora zapytań witryny Azure Portal, ponieważ zadanie nie jest uruchomione. Aby przetestować wywołanie punktu końcowego z portalu, zadanie usługi Stream Analytics musi być uruchomione.
Następujące zapytanie usługi Stream Analytics jest przykładem sposobu wywoływania funkcji zdefiniowanej przez użytkownika usługi Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Jeśli dane wejściowe wysyłane do funkcji zdefiniowanej przez użytkownika uczenia maszynowego są niespójne ze schematem, który jest oczekiwany, punkt końcowy zwróci odpowiedź z kodem błędu 400, co spowoduje przejście zadania usługi Stream Analytics do stanu niepowodzenia. Zaleca się włączenie dzienników zasobów dla zadania, co umożliwi łatwe debugowanie i rozwiązywanie takich problemów. Dlatego zdecydowanie zaleca się:
- Sprawdzanie, czy dane wejściowe do funkcji zdefiniowanej przez użytkownika uczenia maszynowego nie mają wartości null
- Zweryfikuj typ każdego pola, które jest wejściem do funkcji zdefiniowanej przez użytkownika uczenia maszynowego, aby upewnić się, że pasuje do oczekiwanego punktu końcowego
Uwaga
Funkcje zdefiniowane przez użytkownika uczenia maszynowego są oceniane dla każdego wiersza danego kroku zapytania, nawet w przypadku wywołania za pomocą wyrażenia warunkowego (tj. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Jeśli jest taka potrzeba, użyj klauzuli WITH , aby utworzyć rozbieżne ścieżki, wywołując funkcję UDF uczenia maszynowego tylko wtedy, gdy jest to wymagane, przed użyciem funkcji UNION do ponownego scalania ścieżek.
Przekazywanie wielu parametrów wejściowych do funkcji zdefiniowanej przez użytkownika
Najczęstsze przykłady danych wejściowych do modeli uczenia maszynowego to tablice numpy i ramki danych. Tablicę można utworzyć przy użyciu funkcji UDF języka JavaScript i utworzyć serializowaną ramkę danych JSON przy użyciu klauzuli WITH .
Tworzenie tablicy wejściowej
Możesz utworzyć funkcję UDF języka JavaScript, która akceptuje N danych wejściowych i tworzy tablicę, która może służyć jako dane wejściowe do funkcji zdefiniowanej przez użytkownika usługi Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Po dodaniu funkcji zdefiniowanej przez użytkownika języka JavaScript do zadania możesz wywołać funkcję zdefiniowanej przez użytkownika usługi Azure Machine Learning przy użyciu następującego zapytania:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Poniższy kod JSON to przykładowe żądanie:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Tworzenie ramki danych Pandas lub PySpark
Możesz użyć WITH klauzuli , aby utworzyć serializowaną ramkę danych JSON, którą można przekazać jako dane wejściowe do funkcji zdefiniowanej przez użytkownika usługi Azure Machine Learning, jak pokazano poniżej.
Poniższe zapytanie tworzy ramkę danych, wybierając wymagane pola i używając ramki danych jako danych wejściowych do funkcji zdefiniowanej przez użytkownika usługi Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Poniższy kod JSON to przykładowe żądanie z poprzedniego zapytania:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optymalizowanie wydajności funkcji zdefiniowanych przez użytkownika usługi Azure Machine Learning
Podczas wdrażania modelu w usłudze Azure Kubernetes Service można profilować model w celu określenia wykorzystania zasobów. Możesz również włączyć usługę App Insights dla wdrożeń, aby poznać współczynniki żądań, czasy odpowiedzi i współczynniki niepowodzeń.
Jeśli masz scenariusz z wysoką przepływnością zdarzeń, może być konieczne zmianę następujących parametrów w usłudze Stream Analytics, aby osiągnąć optymalną wydajność z małymi opóźnieniami końcowymi:
- Maksymalna liczba partii.
- Liczba żądań równoległych na partycję.
Określanie odpowiedniego rozmiaru partii
Po wdrożeniu usługi internetowej wysyłasz przykładowe żądanie o różnych rozmiarach partii, począwszy od 50 i zwiększając je w kolejności setek. Na przykład 200, 500, 1000, 2000 itd. Zauważysz, że po pewnym rozmiarze partii opóźnienie odpowiedzi wzrasta. Punkt, po którym zwiększa się opóźnienie odpowiedzi, powinien być maksymalną liczbą partii dla zadania.
Określanie liczby żądań równoległych na partycję
W optymalnym skalowaniu zadanie usługi Stream Analytics powinno mieć możliwość wysyłania wielu równoległych żądań do usługi internetowej i uzyskania odpowiedzi w ciągu kilku milisekund. Opóźnienie odpowiedzi usługi internetowej może mieć bezpośredni wpływ na opóźnienie i wydajność zadania usługi Stream Analytics. Jeśli wywołanie zadania do usługi internetowej trwa długo, prawdopodobnie zobaczysz wzrost opóźnienia znaku wodnego i może również spowodować wzrost liczby zdarzeń wejściowych z zaległym wejściem.
Możesz osiągnąć małe opóźnienie, upewniając się, że klaster usługi Azure Kubernetes Service (AKS) został aprowizowany przy użyciu odpowiedniej liczby węzłów i replik. Niezwykle ważne jest, aby usługa internetowa była wysoce dostępna i zwraca pomyślne odpowiedzi. Jeśli zadanie otrzyma błąd, który może zostać ponowiony, na przykład niedostępna odpowiedź usługi (503), automatycznie ponowi próbę z wycofywaniem wykładniczym. Jeśli zadanie odbiera jeden z tych błędów jako odpowiedź z punktu końcowego, zadanie przejdzie do stanu niepowodzenia.
- Nieprawidłowe żądanie (400)
- Konflikt (409)
- Nie znaleziono (404)
- 401 Brak autoryzacji
Ograniczenia
Jeśli używasz usługi Azure ML Managed Endpoint Service, usługa Stream Analytics może obecnie uzyskiwać dostęp tylko do punktów końcowych z włączonym dostępem do sieci publicznej. Przeczytaj więcej na tej stronie na temat prywatnych punktów końcowych usługi Azure ML.