Wdrażanie modelu w klastrze usługi Azure Kubernetes Service przy użyciu wersji 1
Ważne
W tym artykule wyjaśniono, jak wdrożyć model przy użyciu interfejsu wiersza polecenia usługi Azure Machine Learning (wersja 1) i zestawu Azure Machine Learning SDK dla języka Python (wersja 1). Aby zapoznać się z zalecanym podejściem dla wersji 2, zobacz Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online.
Dowiedz się, jak za pomocą usługi Azure Machine Learning wdrożyć model jako usługę internetową w usłudze Azure Kubernetes Service (AKS). Usługa AKS jest dobra dla wdrożeń produkcyjnych o dużej skali. Użyj usługi AKS, jeśli potrzebujesz co najmniej jednej z następujących funkcji:
- Krótki czas odpowiedzi
- Skalowanie automatyczne wdrożonej usługi
- Rejestrowanie
- Zbieranie danych modelu
- Authentication
- Zakończenie szyfrowania TLS
- Opcje przyspieszania sprzętowego, takie jak procesor GPU i układy FPGA (Field-Programowalne macierze bramowe)
Podczas wdrażania w usłudze AKS należy wdrożyć go w klastrze usługi AKS połączonym z obszarem roboczym. Aby uzyskać informacje na temat łączenia klastra usługi AKS z obszarem roboczym, zobacz Tworzenie i dołączanie klastra usługi Azure Kubernetes Service.
Ważne
Zalecamy debugowanie lokalnie przed wdrożeniem w usłudze internetowej. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z wdrożeniem modelu lokalnego.
Uwaga
Punkty końcowe usługi Azure Machine Learning (wersja 2) zapewniają ulepszone, prostsze środowisko wdrażania. Punkty końcowe obsługują scenariusze wnioskowania w czasie rzeczywistym i wsadowego. Punkty końcowe zapewniają ujednolicony interfejs do wywoływania wdrożeń modeli i zarządzania nimi w różnych typach obliczeniowych. Zobacz Co to są punkty końcowe usługi Azure Machine Learning?.
Wymagania wstępne
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji, zobacz Tworzenie obszaru roboczego usługi Azure Machine Learning.
Model uczenia maszynowego zarejestrowany w obszarze roboczym. Jeśli nie masz zarejestrowanego modelu, zobacz Wdrażanie modeli uczenia maszynowego na platformie Azure.
Rozszerzenie interfejsu wiersza polecenia platformy Azure (wersja 1) dla usługi Machine Learning, zestawu SDK języka Python usługi Azure Machine Learning lub rozszerzenia programu Visual Studio Code usługi Azure Machine Learning.
Ważne
Niektóre polecenia interfejsu wiersza polecenia platformy Azure w tym artykule używają
azure-cli-mlrozszerzenia , lub w wersji 1 dla usługi Azure Machine Learning. Obsługa rozszerzenia w wersji 1 zakończy się 30 września 2025 r. Będzie można zainstalować rozszerzenie v1 i używać go do tej daty.Zalecamy przejście do
mlrozszerzenia , lub w wersji 2 przed 30 września 2025 r. Aby uzyskać więcej informacji na temat rozszerzenia w wersji 2, zobacz Rozszerzenie interfejsu wiersza polecenia usługi Azure ML i zestaw Python SDK w wersji 2.Fragmenty kodu języka Python w tym artykule zakładają, że ustawiono następujące zmienne:
ws- Ustaw na obszar roboczy.model- Ustaw na zarejestrowany model.inference_config— Ustaw na konfigurację wnioskowania dla modelu.
Aby uzyskać więcej informacji na temat ustawiania tych zmiennych, zobacz How and where to deploy models (Jak i gdzie wdrażać modele).
Fragmenty kodu interfejsu wiersza polecenia w tym artykule zakładają, że utworzono już dokument inferenceconfig.json . Aby uzyskać więcej informacji na temat tworzenia tego dokumentu, zobacz Wdrażanie modeli uczenia maszynowego na platformie Azure.
Klaster usługi AKS połączony z obszarem roboczym. Aby uzyskać więcej informacji, zobacz Tworzenie i dołączanie klastra usługi Azure Kubernetes Service.
- Jeśli chcesz wdrożyć modele w węzłach procesora GPU lub węzłach FPGA (lub dowolnym konkretnym produkcie), musisz utworzyć klaster z określonym produktem. Nie ma obsługi tworzenia puli węzłów pomocniczych w istniejącym klastrze i wdrażania modeli w puli węzłów pomocniczych.
Omówienie procesów wdrażania
Słowo wdrażanie jest używane zarówno w rozwiązaniu Kubernetes, jak i w usłudze Azure Machine Learning. Wdrożenie ma różne znaczenie w tych dwóch kontekstach. Na platformie Kubernetes wdrożenie jest konkretną jednostką określoną z deklaratywnym plikiem YAML. Wdrożenie platformy Kubernetes ma zdefiniowany cykl życia i konkretne relacje z innymi jednostkami kubernetes, takimi jak Pods i ReplicaSets. Informacje na temat platformy Kubernetes można uzyskać z dokumentacji i filmów wideo na stronie Co to jest platforma Kubernetes?.
W usłudze Azure Machine Learning wdrożenie jest używane w bardziej ogólnym sensie udostępniania i czyszczenia zasobów projektu. Kroki, które usługa Azure Machine Learning uwzględnia część wdrożenia, to:
- Spakuj pliki w folderze projektu, ignorując te określone w pliku amlignore lub gitignore
- Skalowanie klastra obliczeniowego w górę (dotyczy rozwiązania Kubernetes)
- Kompilowanie lub pobieranie pliku dockerfile do węzła obliczeniowego (dotyczy platformy Kubernetes)
- System oblicza skrót:
- Obraz podstawowy
- Niestandardowe kroki platformy Docker (zobacz Wdrażanie modelu przy użyciu niestandardowego obrazu podstawowego platformy Docker)
- Definicja conda YAML (zobacz Tworzenie i używanie środowisk oprogramowania w usłudze Azure Machine Learning)
- System używa tego skrótu jako klucza w wyszukiwaniu obszaru roboczego usługi Azure Container Registry (ACR)
- Jeśli nie zostanie znaleziony, szuka dopasowania w globalnej usłudze ACR
- Jeśli nie zostanie znaleziony, system skompiluje nowy obraz, który jest buforowany i wypchnięty do obszaru roboczego usługi ACR
- System oblicza skrót:
- Pobieranie spakowanego pliku projektu do magazynu tymczasowego w węźle obliczeniowym
- Rozpakowanie pliku projektu
- Wykonywanie węzła obliczeniowego
python <entry script> <arguments> - Zapisywanie dzienników, plików modelu i innych plików zapisanych w plikach ./output na koncie magazynu skojarzonym z obszarem roboczym
- Skalowanie zasobów obliczeniowych w dół, w tym usuwanie magazynu tymczasowego (dotyczy rozwiązania Kubernetes)
Router usługi Azure Machine Learning
Składnik frontonu (azureml-fe), który kieruje przychodzące żądania wnioskowania do wdrożonych usług automatycznie skaluje się w razie potrzeby. Skalowanie pliku azureml-fe jest oparte na celu i rozmiarze klastra usługi AKS (liczba węzłów). Cel klastra i węzły są konfigurowane podczas tworzenia lub dołączania klastra usługi AKS. Istnieje jedna usługa azureml-fe na klaster, która może być uruchomiona na wielu zasobnikach.
Ważne
- W przypadku korzystania z klastra skonfigurowanego jako
dev-testprogram autoskalator jest wyłączony. Nawet w przypadku klastrów FastProd/DenseProd funkcja Self-Scaler jest włączona tylko wtedy, gdy dane telemetryczne pokazują, że są potrzebne. - Usługa Azure Machine Learning nie przekazuje ani nie przechowuje dzienników z żadnych kontenerów, w tym kontenerów systemowych. W celu kompleksowego debugowania zaleca się włączenie usługi Container Insights dla klastra usługi AKS. Dzięki temu można zapisywać dzienniki kontenerów, zarządzać nimi i udostępniać je zespołowi AML w razie potrzeby. Bez tego język AML nie może zagwarantować obsługi problemów związanych z azureml-fe.
- Maksymalny ładunek żądania to 100 MB.
Usługa Azureml-fe skaluje zarówno w górę (w pionie), aby używać większej liczby rdzeni, jak i na poziomie (w poziomie) w celu używania większej liczby zasobników. Podczas podejmowania decyzji o skalowaniu w górę używany jest czas kierowania przychodzących żądań wnioskowania. Jeśli ten czas przekroczy próg, nastąpi skalowanie w górę. Jeśli czas kierowania żądań przychodzących będzie nadal przekraczać próg, nastąpi skalowanie w poziomie.
Podczas skalowania w dół i w dół używane jest użycie procesora CPU. Jeśli próg użycia procesora CPU zostanie osiągnięty, fronton jest najpierw skalowany w dół. Jeśli użycie procesora CPU spadnie do progu skalowania w poziomie, nastąpi operacja skalowania w poziomie. Skalowanie w górę i w górę występuje tylko wtedy, gdy jest wystarczająca ilość dostępnych zasobów klastra.
W przypadku skalowania w górę lub w dół zasobniki azureml-fe są uruchamiane ponownie, aby zastosować zmiany procesora CPU/pamięci. Ponowne uruchomienia nie wpływają na żądania wnioskowania.
Informacje o wymaganiach dotyczących łączności dla klastra wnioskowania usługi AKS
Gdy usługa Azure Machine Learning tworzy lub dołącza klaster usługi AKS, klaster usługi AKS jest wdrażany przy użyciu jednego z następujących dwóch modeli sieciowych:
- Sieć Kubenet: zasoby sieciowe są zwykle tworzone i konfigurowane jako klaster usługi AKS jest wdrażany.
- Sieć usługi Azure Container Networking Interface (CNI): klaster usługi AKS jest połączony z istniejącym zasobem i konfiguracjami sieci wirtualnej.
W przypadku sieci Kubenet sieć jest tworzona i prawidłowo skonfigurowana dla usługi Azure Machine Learning Service. W przypadku sieci CNI należy zrozumieć wymagania dotyczące łączności i zapewnić rozpoznawanie nazw DNS i łączność wychodzącą na potrzeby wnioskowania usługi AKS. Na przykład możesz użyć zapory do blokowania ruchu sieciowego.
Na poniższym diagramie przedstawiono wymagania dotyczące łączności dla wnioskowania usługi AKS. Czarne strzałki reprezentują rzeczywistą komunikację, a niebieskie strzałki reprezentują nazwy domen. Może być konieczne dodanie wpisów dla tych hostów do zapory lub do niestandardowego serwera DNS.
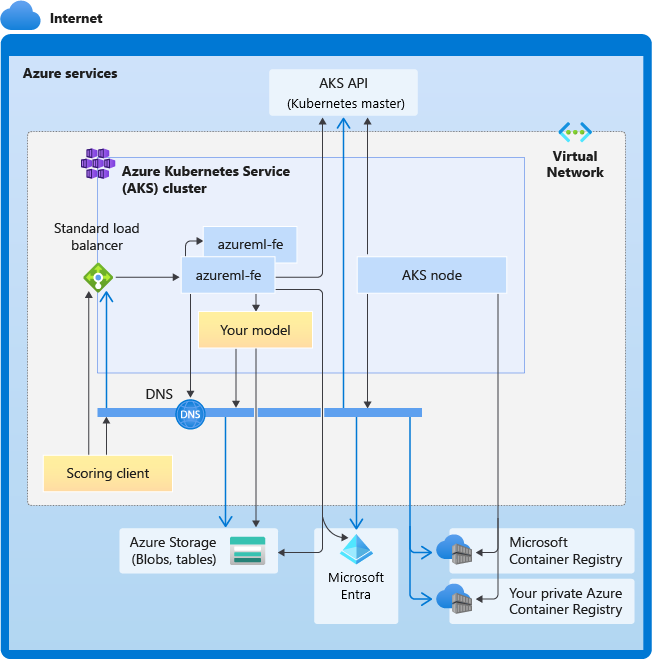
Aby uzyskać ogólne wymagania dotyczące łączności z usługą AKS, zobacz Ograniczanie ruchu sieciowego za pomocą usługi Azure Firewall w usłudze AKS.
Aby uzyskać dostęp do usług Azure Machine Learning za zaporą, zobacz Konfigurowanie ruchu sieciowego przychodzącego i wychodzącego.
Ogólne wymagania dotyczące rozpoznawania nazw DNS
Rozpoznawanie nazw DNS w istniejącej sieci wirtualnej jest pod Kontrolą. Na przykład zapora lub niestandardowy serwer DNS. Następujące hosty muszą być dostępne:
| Nazwa hosta | Używana przez |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Serwer interfejsu API usługi AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Twoja usługa Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Konto usługi Azure Storage (magazyn tabel) |
<account>.blob.core.windows.net |
Konto usługi Azure Storage (magazyn obiektów blob) |
api.azureml.ms |
Uwierzytelnianie Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Punkt końcowy usługi Kusto na potrzeby przekazywania danych telemetrycznych |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Nazwa domeny punktu końcowego w przypadku automatycznego generowania za pomocą usługi Azure Machine Learning. Jeśli użyto niestandardowej nazwy domeny, ten wpis nie jest potrzebny. |
Wymagania dotyczące łączności w kolejności chronologicznej
W procesie tworzenia lub dołączania usługi AKS router usługi Azure Machine Learning (azureml-fe) jest wdrażany w klastrze usługi AKS. Aby wdrożyć router usługi Azure Machine Learning, węzeł usługi AKS powinien mieć możliwość:
- Rozpoznawanie nazw DNS dla serwera interfejsu API usługi AKS
- Rozpoznawanie nazw DNS dla mcR w celu pobrania obrazów platformy Docker dla routera usługi Azure Machine Learning
- Pobieranie obrazów z mcR, gdzie wymagana jest łączność wychodząca
Zaraz po wdrożeniu usługi azureml-fe próbuje rozpocząć pracę i wymaga to wykonania następujących czynności:
- Rozpoznawanie nazw DNS dla serwera interfejsu API usługi AKS
- Wykonywanie zapytań względem serwera interfejsu API usługi AKS w celu odnalezienia innych wystąpień samego (jest to usługa z wieloma zasobnikami)
- Nawiązywanie połączenia z innymi wystąpieniami samego siebie
Po uruchomieniu polecenia azureml-fe wymagane jest następujące połączenie, aby działać prawidłowo:
- Nawiązywanie połączenia z usługą Azure Storage w celu pobrania konfiguracji dynamicznej
- Rozpoznawanie nazw DNS dla serwera uwierzytelniania Entra firmy Microsoft api.azureml.ms i komunikowanie się z nim, gdy wdrożona usługa używa uwierzytelniania Firmy Microsoft Entra.
- Wykonywanie zapytań względem serwera interfejsu API usługi AKS w celu odnajdywania wdrożonych modeli
- Komunikacja z wdrożonym modelem POD
W czasie wdrażania modelu w przypadku pomyślnego wdrożenia modelu węzeł usługi AKS powinien mieć możliwość:
- Rozpoznawanie nazw DNS dla usługi ACR klienta
- Pobieranie obrazów z usługi ACR klienta
- Rozpoznawanie nazw DNS dla obiektów BLOB platformy Azure, w których jest przechowywany model
- Pobieranie modeli z usługi Azure BLOBs
Po wdrożeniu modelu i uruchomieniu usługi usługa azureml-fe automatycznie odnajduje go przy użyciu interfejsu API usługi AKS i jest gotowy do kierowania żądania do niego. Musi być w stanie komunikować się z modelami POD.
Uwaga
Jeśli wdrożony model wymaga łączności (na przykład wykonywania zapytań względem zewnętrznej bazy danych lub innej usługi REST lub pobierania obiektu BLOB), należy włączyć zarówno rozpoznawanie nazw DNS, jak i komunikację wychodzącą dla tych usług.
Wdrażanie w usłudze AKS
Aby wdrożyć model w usłudze AKS, utwórz konfigurację wdrożenia, która opisuje wymagane zasoby obliczeniowe. Na przykład liczba rdzeni i pamięci. Potrzebna jest również konfiguracja wnioskowania, która opisuje środowisko potrzebne do hostowania modelu i usługi internetowej. Aby uzyskać więcej informacji na temat tworzenia konfiguracji wnioskowania, zobacz How and where to deploy models (Jak i gdzie wdrażać modele).
Uwaga
Liczba wdrażanych modeli jest ograniczona do 1000 modeli na wdrożenie (na kontener).
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Aby uzyskać więcej informacji na temat klas, metod i parametrów używanych w tym przykładzie, zobacz następujące dokumenty referencyjne:
Skalowanie automatyczne
DOTYCZY: Zestaw SDK języka Python w wersji 1
Składnik, który obsługuje skalowanie automatyczne dla wdrożeń modelu usługi Azure Machine Learning, to azureml-fe, który jest routerem żądań inteligentnych. Ponieważ wszystkie żądania wnioskowania przechodzą przez nie, mają niezbędne dane do automatycznego skalowania wdrożonych modeli.
Ważne
Nie włączaj narzędzia Kubernetes Horizontal Pod Autoscaler (HPA) dla wdrożeń modeli. Powoduje to, że dwa składniki automatycznego skalowania konkurują ze sobą. Usługa Azureml-fe jest przeznaczona do automatycznego skalowania modeli wdrożonych przez usługę Azure Machine Learning, gdzie hpA musi odgadnąć lub przybliżone wykorzystanie modelu z ogólnej metryki, takiej jak użycie procesora CPU lub niestandardowa konfiguracja metryki.
Usługa Azureml-fe nie skaluje liczby węzłów w klastrze usługi AKS, ponieważ może to prowadzić do nieoczekiwanego wzrostu kosztów. Zamiast tego skaluje liczbę replik modelu w granicach klastra fizycznego. Jeśli musisz skalować liczbę węzłów w klastrze, możesz ręcznie skalować klaster lub skonfigurować skalowanie automatyczne klastra usługi AKS.
Skalowanie automatyczne może być kontrolowane przez ustawienie autoscale_target_utilization, autoscale_min_replicasi autoscale_max_replicas dla usługi internetowej AKS. W poniższym przykładzie pokazano, jak włączyć skalowanie automatyczne:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Decyzje dotyczące skalowania w górę lub w dół są oparte na wykorzystaniu bieżących replik kontenerów. Liczba replik zajętych (przetwarzanie żądania) podzielona przez łączną liczbę bieżących replik jest bieżącym wykorzystaniem. Jeśli ta liczba przekroczy autoscale_target_utilizationwartość , zostanie utworzonych więcej replik. Jeśli jest niższa, repliki zostaną zmniejszone. Domyślnie użycie docelowe wynosi 70%.
Decyzje dotyczące dodawania replik są chętne i szybkie (około 1 sekundy). Decyzje o usunięciu replik są konserwatywne (około 1 minuta).
Wymagane repliki można obliczyć przy użyciu następującego kodu:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Aby uzyskać więcej informacji na temat ustawiania autoscale_target_utilization, autoscale_max_replicasi autoscale_min_replicas, zobacz dokumentację modułu AksWebservice .
Uwierzytelnianie usługi internetowej
Podczas wdrażania w usłudze Azure Kubernetes Service uwierzytelnianie oparte na kluczach jest domyślnie włączone. Możesz również włączyć uwierzytelnianie oparte na tokenach. Uwierzytelnianie oparte na tokenach wymaga, aby klienci używali konta firmy Microsoft Entra do żądania tokenu uwierzytelniania, który jest używany do wprowadzania żądań do wdrożonej usługi.
Aby wyłączyć uwierzytelnianie, ustaw auth_enabled=False parametr podczas tworzenia konfiguracji wdrożenia. Poniższy przykład wyłącza uwierzytelnianie przy użyciu zestawu SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Aby uzyskać informacje na temat uwierzytelniania z aplikacji klienckiej, zobacz Korzystanie z modelu usługi Azure Machine Learning wdrożonego jako usługa internetowa.
Uwierzytelnianie za pomocą kluczy
Jeśli uwierzytelnianie klucza jest włączone, możesz użyć get_keys metody w celu pobrania podstawowego i pomocniczego klucza uwierzytelniania:
primary, secondary = service.get_keys()
print(primary)
Ważne
Jeśli musisz ponownie wygenerować klucz, użyj polecenia service.regen_key.
Uwierzytelnianie za pomocą tokenów
Aby włączyć uwierzytelnianie tokenu token_auth_enabled=True , ustaw parametr podczas tworzenia lub aktualizowania wdrożenia. Poniższy przykład umożliwia uwierzytelnianie tokenów przy użyciu zestawu SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Jeśli uwierzytelnianie tokenu jest włączone, możesz użyć get_token metody w celu pobrania tokenu JWT i czasu wygaśnięcia tego tokenu:
token, refresh_by = service.get_token()
print(token)
Ważne
Po upływie czasu tokenu należy zażądać nowego tokenu refresh_by .
Firma Microsoft zdecydowanie zaleca utworzenie obszaru roboczego usługi Azure Machine Learning w tym samym regionie co klaster usługi AKS. Aby uwierzytelnić się przy użyciu tokenu, usługa internetowa wykonuje wywołanie regionu, w którym jest tworzony obszar roboczy usługi Azure Machine Learning. Jeśli region obszaru roboczego jest niedostępny, nie można pobrać tokenu dla usługi internetowej, nawet jeśli klaster znajduje się w innym regionie niż obszar roboczy. Dzięki temu uwierzytelnianie oparte na tokenach będzie niedostępne do momentu ponownego udostępnienia regionu obszaru roboczego. Ponadto im większa odległość między regionem klastra a regionem obszaru roboczego, tym dłużej trwa pobieranie tokenu.
Aby pobrać token, musisz użyć zestawu SDK usługi Azure Machine Learning lub polecenia az ml service get-access-token .
Skanowanie pod kątem luk w zabezpieczeniach
Microsoft Defender dla Chmury zapewnia ujednolicone zarządzanie zabezpieczeniami i zaawansowaną ochronę przed zagrożeniami w ramach obciążeń chmury hybrydowej. Należy zezwolić Microsoft Defender dla Chmury na skanowanie zasobów i postępować zgodnie z zaleceniami. Aby uzyskać więcej informacji, zobacz Zabezpieczenia kontenerów w usłudze Microsoft Defender dla kontenerów.
Powiązana zawartość
- Używanie kontroli dostępu opartej na rolach platformy Azure na potrzeby autoryzacji platformy Kubernetes
- Zabezpieczanie środowiska wnioskowania usługi Azure Machine Learning za pomocą sieci wirtualnych
- Wdrażanie modelu w punkcie końcowym online przy użyciu niestandardowego kontenera
- Rozwiązywanie problemów z wdrażaniem modelu zdalnego
- Aktualizowanie wdrożonej usługi internetowej
- Zabezpieczanie usługi internetowej za pomocą usługi Azure Machine Learning przy użyciu protokołu TLS
- Korzystanie z modelu usługi Azure Machine Learning wdrożonego jako usługa internetowa
- Monitorowanie i zbieranie danych z punktów końcowych usługi internetowej ML
- Zbieranie danych z modeli w środowisku produkcyjnym