Wprowadzenie do monitorowania kondycji usługi Service Fabric
Usługa Azure Service Fabric wprowadza model kondycji, który zapewnia rozbudowaną, elastyczną i rozszerzalną ocenę kondycji i raportowanie. Model umożliwia niemal rzeczywiste monitorowanie stanu klastra i uruchomionych w nim usług. Możesz łatwo uzyskać informacje o kondycji i rozwiązać potencjalne problemy przed ich kaskadą i spowodować masowe awarie. W typowym modelu usługi wysyłają raporty na podstawie ich widoków lokalnych, a informacje te są agregowane w celu zapewnienia ogólnego widoku na poziomie klastra.
Składniki usługi Service Fabric używają tego zaawansowanego modelu kondycji do raportowania ich bieżącego stanu. Możesz użyć tego samego mechanizmu do raportowania kondycji z aplikacji. Jeśli zainwestujesz w wysokiej jakości raportowanie kondycji, które przechwytuje niestandardowe warunki, możesz wykrywać i rozwiązywać problemy z uruchomioną aplikacją znacznie łatwiej.
Uwaga
Uruchomiliśmy podsystem kondycji, aby zaspokoić potrzebę monitorowanych uaktualnień. Usługa Service Fabric zapewnia monitorowane uaktualnienia aplikacji i klastra, które zapewniają pełną dostępność, bez przestojów i minimum do żadnej interwencji użytkownika. Aby osiągnąć te cele, kondycja uaktualniania sprawdza kondycję na podstawie skonfigurowanych zasad uaktualniania. Uaktualnienie może być kontynuowane tylko wtedy, gdy kondycja uwzględnia żądane progi. W przeciwnym razie uaktualnienie zostanie automatycznie wycofane lub wstrzymane, aby umożliwić administratorom rozwiązanie tych problemów. Aby dowiedzieć się więcej na temat uaktualnień aplikacji, zobacz ten artykuł.
Magazyn kondycji
Magazyn kondycji przechowuje informacje dotyczące kondycji dotyczące jednostek w klastrze w celu łatwego pobierania i oceny. Jest ona implementowana jako utrwalone stanowe usługi Service Fabric w celu zapewnienia wysokiej dostępności i skalowalności. Magazyn kondycji jest częścią aplikacji fabric:/System i jest dostępny, gdy klaster jest uruchomiony.
Jednostki kondycji i hierarchia
Jednostki kondycji są zorganizowane w hierarchii logicznej, która przechwytuje interakcje i zależności między różnymi jednostkami. Magazyn kondycji automatycznie kompiluje jednostki kondycji i hierarchię na podstawie raportów otrzymanych ze składników usługi Service Fabric.
Jednostki kondycji odzwierciedlają jednostki usługi Service Fabric. (Na przykład jednostka aplikacji kondycji jest zgodna z wystąpieniem aplikacji wdrożonym w klastrze, a jednostka węzła kondycji jest zgodna z węzłem klastra usługi Service Fabric). Hierarchia kondycji przechwytuje interakcje jednostek systemowych i jest podstawą zaawansowanej oceny kondycji. Kluczowe pojęcia dotyczące usługi Service Fabric można uzyskać w temacie Service Fabric technical overview (Omówienie techniczne usługi Service Fabric). Aby uzyskać więcej informacji na temat aplikacji, zobacz Model aplikacji usługi Service Fabric.
Jednostki kondycji i hierarchia umożliwiają efektywne raportowanie, debugowanie i monitorowanie klastrów i aplikacji. Model kondycji zapewnia dokładną, szczegółową reprezentację kondycji wielu ruchomych elementów w klastrze.
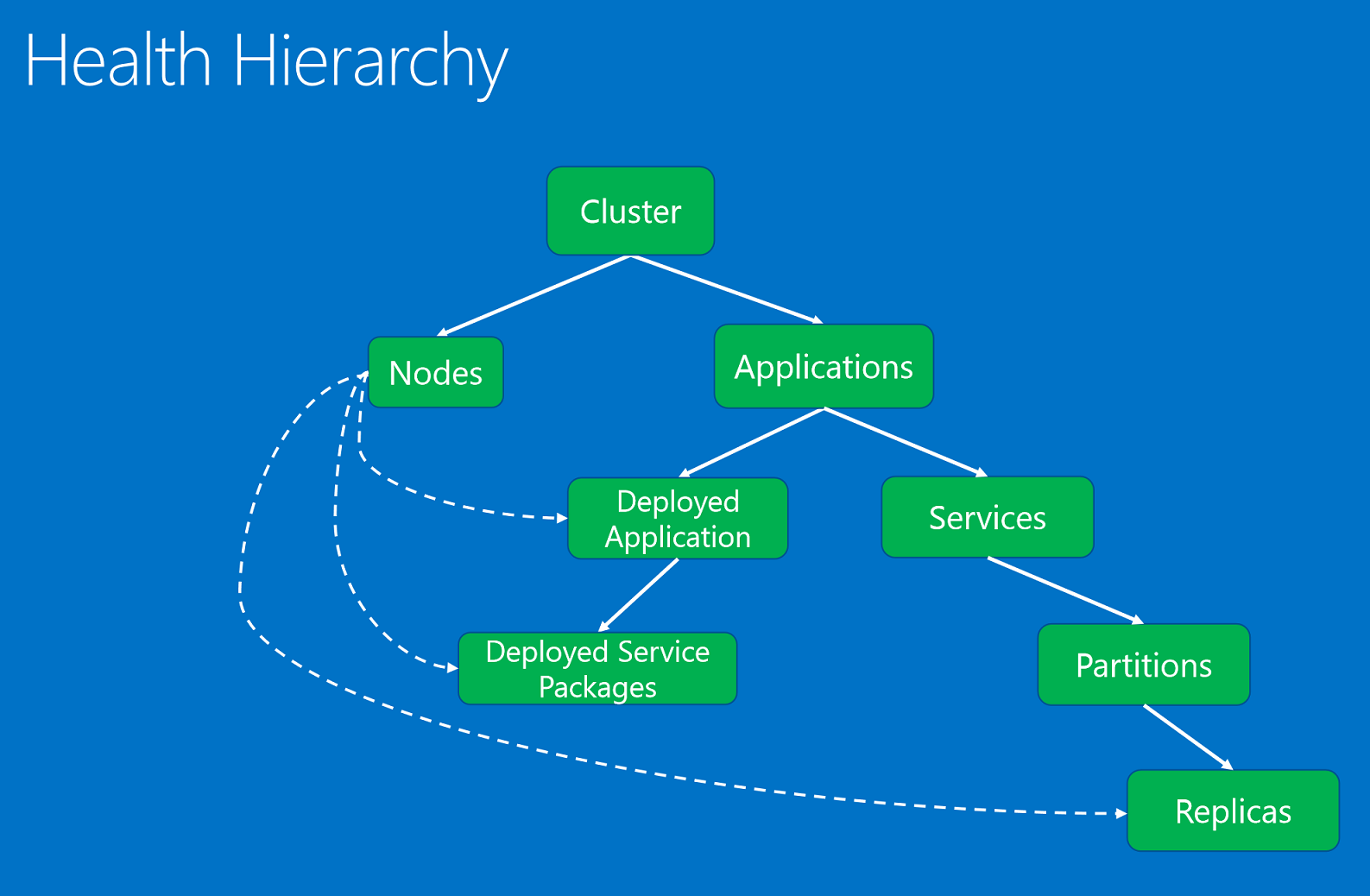 Jednostki kondycji zorganizowane w hierarchii na podstawie relacji nadrzędny-podrzędny.
Jednostki kondycji zorganizowane w hierarchii na podstawie relacji nadrzędny-podrzędny.
Jednostki kondycji to:
- Klaster. Reprezentuje kondycję klastra usługi Service Fabric. Raporty dotyczące kondycji klastra opisują warunki wpływające na cały klaster. Te warunki mają wpływ na wiele jednostek w klastrze lub samym klastrze. Na podstawie warunku reporter nie może zawęzić problemu do jednego lub większej liczby dzieci w złej kondycji. Przykłady obejmują mózg klastra podzielonego z powodu problemów z partycjonowaniem sieci lub komunikacją.
- Węzeł. Reprezentuje kondycję węzła usługi Service Fabric. Raporty dotyczące kondycji węzła opisują warunki wpływające na funkcjonalność węzła. Zwykle mają one wpływ na wszystkie wdrożone jednostki uruchomione na nim. Przykłady obejmują brak miejsca na dysku węzła (lub inne właściwości całego komputera, takie jak pamięć, połączenia) i gdy węzeł nie działa. Jednostka węzła jest identyfikowana przez nazwę węzła (ciąg).
- Aplikacja. Reprezentuje kondycję wystąpienia aplikacji uruchomionego w klastrze. Raporty kondycji aplikacji opisują warunki wpływające na ogólną kondycję aplikacji. Nie można ich zawęzić do poszczególnych elementów podrzędnych (usług lub wdrożonych aplikacji). Przykłady obejmują kompleksową interakcję między różnymi usługami w aplikacji. Jednostka aplikacji jest identyfikowana przez nazwę aplikacji (URI).
- Usługa. Reprezentuje kondycję usługi uruchomionej w klastrze. Kondycja usługi raporty opisują warunki wpływające na ogólną kondycję usługi. Reporter nie może zawęzić problemu do partycji lub repliki w złej kondycji. Przykłady obejmują konfigurację usługi (np. port lub zewnętrzny udział plików), która powoduje problemy ze wszystkimi partycjami. Jednostka usługi jest identyfikowana przez nazwę usługi (URI).
- Partycja. Reprezentuje kondycję partycji usługi. Raporty kondycji partycji opisują warunki wpływające na cały zestaw replik. Przykłady obejmują, gdy liczba replik jest mniejsza niż liczba obiektów docelowych i gdy partycja znajduje się w utracie kworum. Jednostka partycji jest identyfikowana przez identyfikator partycji (GUID).
- Replika. Reprezentuje kondycję stanowej repliki usługi lub wystąpienia usługi bezstanowej. Replika jest najmniejszą jednostką, którą obserwatorzy i składniki systemowe mogą zgłaszać dla aplikacji. W przypadku usług stanowych przykłady obejmują replikę podstawową, która nie może replikować operacji do serwerów pomocniczych i powolnej replikacji. Ponadto wystąpienie bezstanowe może zgłaszać, gdy brakuje zasobów lub ma problemy z łącznością. Jednostka repliki jest identyfikowana przez identyfikator partycji (GUID) oraz identyfikator repliki lub wystąpienia (długi).
- DeployedApplication. Reprezentuje kondycję aplikacji uruchomionej w węźle. Wdrożone raporty kondycji aplikacji opisują warunki specyficzne dla aplikacji w węźle, których nie można zawęzić do pakietów usług wdrożonych w tym samym węźle. Przykłady obejmują błędy, gdy nie można pobrać pakietu aplikacji w tym węźle i problemy z konfigurowaniem podmiotów zabezpieczeń aplikacji w węźle. Wdrożona aplikacja jest identyfikowana przez nazwę aplikacji (URI) i nazwę węzła (ciąg).
- DeployedServicePackage. Reprezentuje kondycję pakietu usługi uruchomionego w węźle w klastrze. Opisuje warunki specyficzne dla pakietu usługi, który nie ma wpływu na inne pakiety usług w tym samym węźle dla tej samej aplikacji. Przykłady obejmują pakiet kodu w pakiecie usługi, którego nie można uruchomić, oraz pakiet konfiguracji, którego nie można odczytać. Wdrożony pakiet usługi jest identyfikowany przez nazwę aplikacji (URI), nazwę węzła (ciąg), nazwę manifestu usługi (ciąg) i identyfikator aktywacji pakietu usługi (ciąg).
Stopień szczegółowości modelu kondycji ułatwia wykrywanie i rozwiązywanie problemów. Jeśli na przykład usługa nie odpowiada, można zgłosić, że wystąpienie aplikacji jest w złej kondycji. Raportowanie na tym poziomie nie jest jednak idealne, ponieważ problem może nie mieć wpływu na wszystkie usługi w tej aplikacji. Raport powinien być stosowany do usługi w złej kondycji lub do określonej partycji podrzędnej, jeśli więcej informacji wskazuje na daną partycję. Dane są automatycznie wyświetlane w hierarchii, a partycja w złej kondycji jest widoczna na poziomach usług i aplikacji. Ta agregacja pomaga szybciej wskazać i rozwiązać główną przyczynę problemu.
Hierarchia kondycji składa się z relacji nadrzędny-podrzędny. Klaster składa się z węzłów i aplikacji. Aplikacje mają usługi i wdrożone aplikacje. Wdrożone aplikacje mają wdrożone pakiety usług. Usługi mają partycje, a każda partycja ma co najmniej jedną replikę. Istnieje specjalna relacja między węzłami i wdrożonych jednostek. Węzeł w złej kondycji zgłoszony przez składnik systemu urzędu, usługę Menedżera trybu failover, wpływa na wdrożone aplikacje, pakiety usług i repliki wdrożone na nim.
Hierarchia kondycji reprezentuje najnowszy stan systemu na podstawie najnowszych raportów dotyczących kondycji, które są niemal informacjami w czasie rzeczywistym. Wewnętrzne i zewnętrzne watchdogi mogą zgłaszać te same jednostki na podstawie logiki specyficznej dla aplikacji lub niestandardowych monitorowanych warunków. Raporty użytkowników współistnieją z raportami systemowymi.
Zaplanuj inwestowanie w sposób raportowania kondycji i reagowania na nie podczas projektowania dużej usługi w chmurze. Ta inwestycja z góry ułatwia debugowanie, monitorowanie i działanie usługi.
Stany kondycji
Usługa Service Fabric używa trzech stanów kondycji, aby opisać, czy jednostka jest w dobrej kondycji, czy nie: OK, ostrzeżenie i błąd. Każdy raport wysłany do magazynu kondycji musi określać jeden z tych stanów. Wynik oceny kondycji jest jednym z tych stanów.
Możliwe stany zdrowia to:
- OK. Jednostka jest w dobrej kondycji. Nie ma żadnych znanych problemów zgłoszonych na nim lub jego elementów podrzędnych (jeśli ma to zastosowanie).
- Ostrzeżenie. Jednostka ma pewne problemy, ale nadal może działać poprawnie. Na przykład występują opóźnienia, ale nie powodują jeszcze żadnych problemów funkcjonalnych. W niektórych przypadkach warunek ostrzegawczy może zostać naprawiony bez interwencji zewnętrznej. W takich przypadkach raporty dotyczące kondycji zwiększają świadomość i zapewniają wgląd w to, co się dzieje. W innych przypadkach stan ostrzeżenia może ulec pogorszeniu w poważnym problemie bez interwencji użytkownika.
- Błąd. Jednostka jest w złej kondycji. Należy podjąć akcję w celu naprawienia stanu jednostki, ponieważ nie może działać prawidłowo.
- Nieznany. Jednostka nie istnieje w magazynie kondycji. Ten wynik można uzyskać z zapytań rozproszonych, które scalają wyniki z wielu składników. Na przykład zapytanie get node list przechodzi do klasy FailoverManager, ClusterManager i HealthManager. Zapytanie dotyczące listy aplikacji przechodzi do elementu ClusterManager i HealthManager. Te zapytania scalają wyniki z wielu składników systemowych. Jeśli inny składnik systemu zwraca jednostkę, która nie znajduje się w magazynie kondycji, scalony wynik ma nieznany stan kondycji. Jednostka nie jest w magazynie, ponieważ raporty o kondycji nie zostały jeszcze przetworzone lub jednostka została wyczyszczona po usunięciu.
Zasady dotyczące kondycji
Magazyn kondycji stosuje zasady kondycji, aby określić, czy jednostka jest w dobrej kondycji na podstawie raportów i jej elementów podrzędnych.
Uwaga
Zasady kondycji można określić w manifeście klastra (na potrzeby oceny kondycji klastra i węzła) lub w manifeście aplikacji (na potrzeby oceny aplikacji i dowolnej z jej elementów podrzędnych). Żądania oceny kondycji mogą również przekazywać niestandardowe zasady oceny kondycji, które są używane tylko do tej oceny.
Domyślnie usługa Service Fabric stosuje ścisłe reguły (wszystko musi być w dobrej kondycji) dla relacji hierarchicznej nadrzędny-podrzędny. Jeśli nawet jeden z elementów podrzędnych ma jedno zdarzenie w złej kondycji, element nadrzędny jest uznawany za w złej kondycji.
Zasady kondycji klastra
Zasady kondycji klastra są używane do oceny stanu kondycji klastra i stanu kondycji węzła. Zasady można zdefiniować w manifeście klastra. Jeśli nie jest obecny, są używane domyślne zasady (zero tolerowanych awarii).
Zasady kondycji klastra zawierają:
RozważwarningAsError. Określa, czy raport kondycji ostrzeżenia ma być traktowany jako błędy podczas oceny kondycji. Wartość domyślna: false.
MaxPercentUnhealthyApplications. Określa maksymalny tolerowany procent aplikacji, które mogą być w złej kondycji, zanim klaster zostanie uznany za błąd.
MaxPercentUnhealthyNodes. Określa maksymalny tolerowany procent węzłów, które mogą być w złej kondycji, zanim klaster zostanie uznany za błąd. W dużych klastrach niektóre węzły są zawsze wyłączone lub wyłączone w celu naprawy, więc ta wartość procentowa powinna być skonfigurowana tak, aby to tolerowała.
ApplicationTypeHealthPolicyMap. Mapa zasad kondycji typu aplikacji może być używana podczas oceny kondycji klastra w celu opisania specjalnych typów aplikacji. Domyślnie wszystkie aplikacje są umieszczane w puli i oceniane za pomocą polecenia MaxPercentUnhealthyApplications. Jeśli niektóre typy aplikacji powinny być traktowane inaczej, można je wyjąć z puli globalnej. Zamiast tego są one oceniane względem wartości procentowych skojarzonych z nazwą typu aplikacji na mapie. Na przykład w klastrze istnieją tysiące aplikacji różnych typów i kilka wystąpień aplikacji sterujących specjalnego typu aplikacji. Aplikacje sterujące nigdy nie powinny być błędne. Można określić globalną wartość MaxPercentUnhealthyApplications na 20%, aby tolerować niektóre błędy, ale dla typu aplikacji "ControlApplicationType" ustaw wartość MaxPercentUnhealthyApplications na 0. W ten sposób, jeśli niektóre z wielu aplikacji są w złej kondycji, ale poniżej globalnej wartości procentowej złej kondycji, klaster zostanie oceniony na Ostrzeżenie. Stan kondycji ostrzeżenia nie ma wpływu na uaktualnianie klastra ani inne monitorowanie wyzwalane przez stan kondycji błędu. Jednak nawet jedna aplikacja kontrolna w błędzie spowoduje, że klaster jest w złej kondycji, co wyzwala wycofanie lub wstrzymuje uaktualnienie klastra, w zależności od konfiguracji uaktualnienia. W przypadku typów aplikacji zdefiniowanych na mapie wszystkie wystąpienia aplikacji są pobierane z globalnej puli aplikacji. Są one oceniane na podstawie całkowitej liczby aplikacji typu aplikacji przy użyciu określonej wartości MaxPercentUnhealthyApplications z mapy. Wszystkie pozostałe aplikacje pozostają w puli globalnej i są oceniane za pomocą elementu MaxPercentUnhealthyApplications.
Poniższy przykład to fragment manifestu klastra. Aby zdefiniować wpisy na mapie typu aplikacji, prefiks nazwy parametru o nazwie "ApplicationTypeMaxPercentUnhealthyApplications-", a następnie nazwie typu aplikacji.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Mapa zasad kondycji typu węzła może być używana podczas oceny kondycji klastra w celu opisania specjalnych typów węzłów. Typy węzłów są oceniane względem wartości procentowych skojarzonych z nazwą typu węzła na mapie. Ustawienie tej wartości nie ma wpływu na globalną pulę węzłów używanych dla programuMaxPercentUnhealthyNodes. Na przykład klaster ma setki węzłów różnych typów i kilka typów węzłów hostujących ważną pracę. Węzły tego typu nie powinny być wyłączone. Można określić wartość globalnąMaxPercentUnhealthyNodesna 20%, aby tolerować niektóre błędy dla wszystkich węzłów, ale dla typuSpecialNodeTypewęzłaMaxPercentUnhealthyNodesustaw wartość 0. W ten sposób, jeśli niektóre z wielu węzłów są w złej kondycji, ale poniżej globalnej wartości procentowej złej kondycji, klaster zostanie oceniony jako w stanie Kondycja ostrzeżenia. Stan kondycji ostrzeżenia nie ma wpływu na uaktualnianie klastra ani inne monitorowanie wyzwalane przez stan kondycji błędu. Jednak nawet jeden węzeł typuSpecialNodeTypew stanie Kondycja błędu sprawi, że klaster będzie w złej kondycji i wyzwoli wycofanie lub wstrzyma uaktualnienie klastra, w zależności od konfiguracji uaktualnienia. Z drugiej strony ustawienie wartości globalnejMaxPercentUnhealthyNodesna 0 i ustawienie maksymalnegoSpecialNodeTypeprocentu złej kondycji węzłów na 100 z jednym węzłem typuSpecialNodeTypew stanie błędu nadal spowoduje umieszczenie klastra w stanie błędu, ponieważ ograniczenie globalne jest bardziej rygorystyczne w tym przypadku.Poniższy przykład to fragment manifestu klastra. Aby zdefiniować wpisy na mapie typu węzła, prefiks nazwy parametru o nazwie "NodeTypeMaxPercentUnhealthyNodes-", a następnie nazwie typu węzła.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Zasady kondycji aplikacji
Zasady kondycji aplikacji opisują sposób oceny zdarzeń i agregacji stanów podrzędnych dla aplikacji i ich elementów podrzędnych. Można go zdefiniować w manifeście aplikacji, ApplicationManifest.xml, w pakiecie aplikacji. Jeśli nie określono żadnych zasad, usługa Service Fabric zakłada, że jednostka jest w złej kondycji, jeśli ma raport kondycji lub element podrzędny w stanie kondycji ostrzeżenia lub błędu. Konfigurowalne zasady to:
- RozważwarningAsError. Określa, czy raport kondycji ostrzeżenia ma być traktowany jako błędy podczas oceny kondycji. Wartość domyślna: false.
- MaxPercentUnhealthyDeployedApplications. Określa maksymalny tolerowany procent wdrożonych aplikacji, które mogą być w złej kondycji, zanim aplikacja zostanie uznana za błędną. Ta wartość procentowa jest obliczana przez podzielenie liczby wdrożonych aplikacji w złej kondycji na liczbę węzłów, w których aplikacje są obecnie wdrażane w klastrze. Obliczenia są zaokrąglone w górę, aby tolerować jedną awarię na małej liczbie węzłów. Wartość procentowa domyślna: zero.
- DefaultServiceTypeHealthPolicy. Określa domyślne zasady kondycji typu usługi, które zastępują domyślne zasady kondycji dla wszystkich typów usług w aplikacji.
- ServiceTypeHealthPolicyMap. Zawiera mapę zasad kondycji usługi na typ usługi. Te zasady zastępują domyślne zasady kondycji typu usługi dla każdego określonego typu usługi. Jeśli na przykład aplikacja ma typ usługi bramy bezstanowej i typ usługi aparatu stanowego, możesz skonfigurować zasady kondycji dla ich oceny inaczej. Po określeniu zasad na typ usługi można uzyskać bardziej szczegółową kontrolę nad kondycją usługi.
Zasady kondycji typu usługi
Zasady kondycji typu usługi określają sposób oceniania i agregowania usług oraz elementów podrzędnych usług. Zasady zawierają następujące elementy:
- MaxPercentUnhealthyPartitionsPerService. Określa maksymalną tolerowaną wartość procentową partycji w złej kondycji, zanim usługa zostanie uznana za w złej kondycji. Wartość procentowa domyślna: zero.
- MaxPercentUnhealthyReplicasPerPartition. Określa maksymalną tolerowaną wartość procentową replik w złej kondycji, zanim partycja zostanie uznana za w złej kondycji. Wartość procentowa domyślna: zero.
- MaxPercent W złej kondycjiUsługi. Określa maksymalny tolerowany procent usług w złej kondycji przed rozważeniu złej kondycji aplikacji. Wartość procentowa domyślna: zero.
Poniższy przykład to fragment manifestu aplikacji:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Ocena kondycji
Użytkownicy i zautomatyzowane usługi mogą w dowolnym momencie oceniać kondycję dowolnej jednostki. Aby ocenić kondycję jednostki, magazyn kondycji agreguje wszystkie raporty o kondycji jednostki i ocenia wszystkie jej elementy podrzędne (jeśli ma to zastosowanie). Algorytm agregacji kondycji używa zasad kondycji, które określają sposób oceniania raportów kondycji i sposobu agregowania stanów kondycji podrzędnych (jeśli ma to zastosowanie).
Agregacja raportu kondycji
Jedna jednostka może mieć wiele raportów dotyczących kondycji wysyłanych przez różnych reporterów (składniki systemu lub watchdogs) w różnych właściwościach. Agregacja używa skojarzonych zasad kondycji, w szczególności elementu członkowskiego ConsiderWarningAsError zasad kondycji aplikacji lub klastra. ConsiderWarningAsError określa sposób oceniania ostrzeżeń.
Zagregowany stan kondycji jest wyzwalany przez najgorsze raporty dotyczące kondycji jednostki. Jeśli istnieje co najmniej jeden raport kondycji błędu, zagregowany stan kondycji jest błędem.
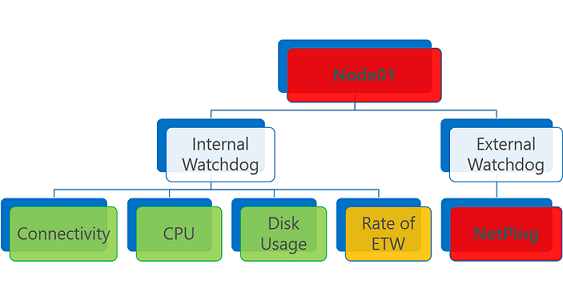
Jednostka kondycji, która ma co najmniej jeden raport kondycji błędów, jest oceniana jako Błąd. To samo dotyczy wygasłego raportu kondycji, niezależnie od stanu kondycji.
Jeśli nie ma raportów o błędach i co najmniej jednego ostrzeżenia, zagregowany stan kondycji to ostrzeżenie lub błąd, w zależności od flagi zasad ConsiderWarningAsError.
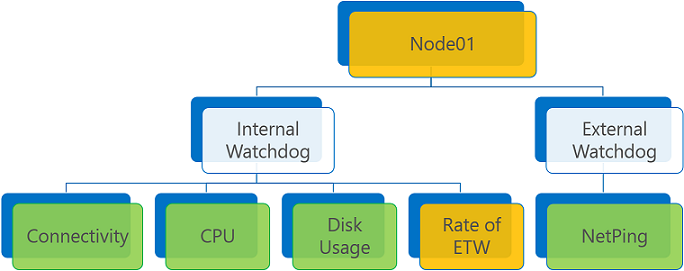
Agregacja raportu kondycji z raportem ostrzegawczym i wartością ConsiderWarningAsError ustawioną na wartość false (wartość domyślna).
Agregacja kondycji podrzędnej
Zagregowany stan kondycji jednostki odzwierciedla stany kondycji podrzędnej (jeśli ma to zastosowanie). Algorytm agregowania stanów kondycji podrzędnej używa zasad kondycji, które mają zastosowanie na podstawie typu jednostki.
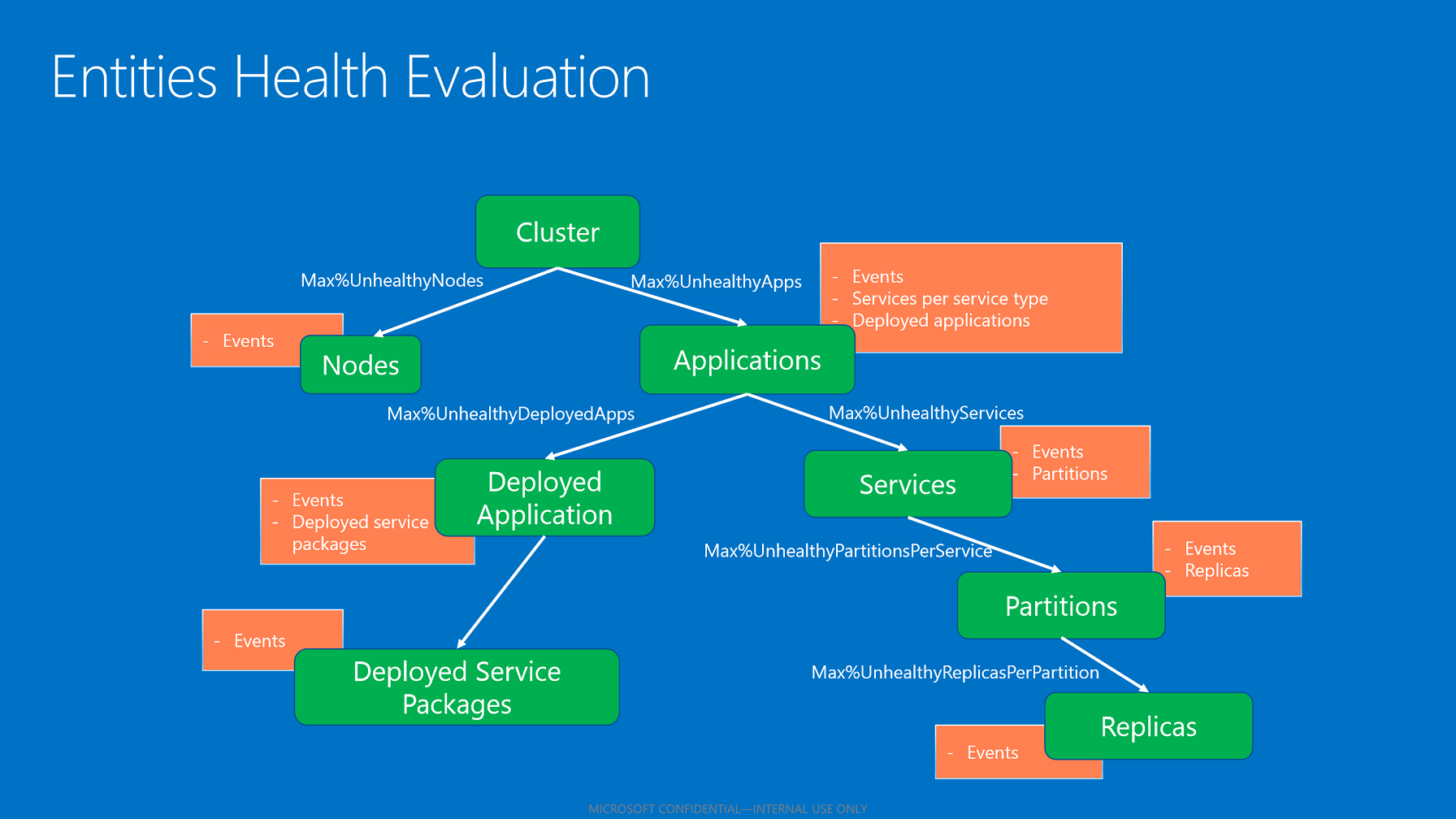
Agregacja podrzędna oparta na zasadach kondycji.
Gdy magazyn kondycji oceni wszystkie dzieci, agreguje ich stany kondycji na podstawie skonfigurowanego maksymalnego procentu dzieci w złej kondycji. Ta wartość procentowa jest pobierana z zasad na podstawie jednostki i typu podrzędnego.
- Jeśli wszystkie dzieci mają stany OK, stan zdrowia zagregowanego elementu podrzędnego to OK.
- Jeśli elementy podrzędne mają zarówno stan OK, jak i ostrzeżenie, stan kondycji zagregowanego elementu podrzędnego jest ostrzegawczy.
- Jeśli istnieją elementy podrzędne ze stanami błędów, które nie przestrzegają maksymalnej dozwolonej wartości procentowej dzieci w złej kondycji, zagregowany stan kondycji nadrzędnej jest błędem.
- Jeśli elementy podrzędne ze stanami błędów przestrzegają maksymalnego dozwolonego procentu dzieci w złej kondycji, zagregowany stan kondycji nadrzędnej jest ostrzegawczy.
Raportowanie kondycji
Składniki systemu, aplikacje systemu Fabric i wewnętrzne/zewnętrzne elementy watchdog mogą zgłaszać jednostki usługi Service Fabric. Reporterzy ustalają lokalną kondycję monitorowanych jednostek na podstawie warunków, które monitorują. Nie muszą patrzeć na żadne globalne dane o stanie ani agregacji. Pożądanym zachowaniem jest posiadanie prostych reporterów, a nie złożonych organizmów, które muszą przyjrzeć się wielu rzeczom, aby wywnioskować, jakie informacje mają być wysyłane.
Aby wysłać dane kondycji do magazynu kondycji, reporter musi zidentyfikować jednostkę, której dotyczy problem, i utworzyć raport kondycji. Aby wysłać raport, użyj interfejsu API FabricClient.HealthClient.ReportHealth , interfejsów API kondycji raportu uwidocznionych na Partition obiektach lub CodePackageActivationContext , poleceniach cmdlet programu PowerShell lub REST.
Raporty o kondycji
Raporty dotyczące kondycji dla każdej jednostki w klastrze zawierają następujące informacje:
SourceId. Ciąg, który jednoznacznie identyfikuje reportera zdarzenia kondycji.
Identyfikator jednostki. Określa jednostkę, w której jest stosowany raport. Różni się on w zależności od typu jednostki:
- Klaster. Brak.
- Węzeł. Nazwa węzła (ciąg).
- Aplikacja. Nazwa aplikacji (URI). Reprezentuje nazwę wystąpienia aplikacji wdrożonego w klastrze.
- Usługa. Nazwa usługi (URI). Reprezentuje nazwę wystąpienia usługi wdrożonego w klastrze.
- Partycja. Identyfikator partycji (GUID). Reprezentuje unikatowy identyfikator partycji.
- Replika. Identyfikator repliki usługi stanowej lub identyfikator wystąpienia usługi bezstanowej (INT64).
- DeployedApplication. Nazwa aplikacji (URI) i nazwa węzła (ciąg).
- DeployedServicePackage. Nazwa aplikacji (URI), nazwa węzła (ciąg) i nazwa manifestu usługi (ciąg).
Właściwość. Ciąg (nie stały wyliczenie), który umożliwia reporterowi kategoryzowanie zdarzenia kondycji dla określonej właściwości jednostki. Na przykład reporter A może zgłosić kondycję właściwości "Storage" node01 i reporter B może zgłosić kondycję właściwości Node01 "Connectivity". W magazynie kondycji te raporty są traktowane jako oddzielne zdarzenia kondycji dla jednostki Node01.
Opis. Ciąg, który umożliwia reporterowi podanie szczegółowych informacji o zdarzeniu kondycji. Parametr SourceId, Property i HealthState powinien w pełni opisać raport. Opis dodaje czytelne dla człowieka informacje o raporcie. Tekst ułatwia administratorom i użytkownikom zrozumienie raportu o kondycji.
HealthState. Wyliczenie opisujące stan kondycji raportu. Zaakceptowane wartości to OK, Ostrzeżenie i Błąd.
TimeToLive. Przedział czasu wskazujący, jak długo raport kondycji jest prawidłowy. W połączeniu z removeWhenExpired pozwala magazynowi kondycji wiedzieć, jak ocenić wygasłe zdarzenia. Domyślnie wartość jest nieskończona, a raport jest prawidłowy na zawsze.
RemoveWhenExpired. Wartość logiczna. Jeśli ustawiono wartość true, wygasły raport kondycji zostanie automatycznie usunięty z magazynu kondycji, a raport nie ma wpływu na ocenę kondycji jednostki. Używany, gdy raport jest ważny tylko przez określony okres, a reporter nie musi jawnie go wyczyścić. Służy również do usuwania raportów z magazynu kondycji (na przykład usługa watchdog jest zmieniana i zatrzymuje wysyłanie raportów z poprzednim źródłem i właściwością). Może wysłać raport z krótkim TimeToLive wraz z RemoveWhenExpired, aby wyczyścić dowolny poprzedni stan ze sklepu kondycji. Jeśli wartość jest ustawiona na false, wygasły raport jest traktowany jako błąd w ocenie kondycji. Wartość false sygnalizuje magazynowi kondycji, że źródło powinno okresowo zgłaszać tę właściwość. Jeśli tak nie jest, to musi być coś złego w watchdog. Kondycja watchdoga jest przechwytywana przez rozważenie zdarzenia jako błędu.
SequenceNumber. Dodatnia liczba całkowita, która musi być coraz większa, reprezentuje kolejność raportów. Jest on używany przez magazyn kondycji do wykrywania nieaktualnych raportów, które są odbierane późno z powodu opóźnień sieci lub innych problemów. Raport jest odrzucany, jeśli numer sekwencji jest mniejszy lub równy ostatnio zastosowanej liczbie dla tej samej jednostki, źródła i właściwości. Jeśli nie zostanie określony, numer sekwencji zostanie wygenerowany automatycznie. Należy umieścić numer sekwencji tylko w przypadku raportowania przejścia stanu. W takiej sytuacji źródło musi pamiętać, które raporty wysłały i zachować informacje dotyczące odzyskiwania w trybie failover.
Te cztery elementy informacji — SourceId, identyfikator jednostki, Właściwość i HealthState — są wymagane dla każdego raportu kondycji. Ciąg SourceId nie może rozpoczynać się od prefiksu "System"., który jest zarezerwowany dla raportów systemowych. W przypadku tej samej jednostki istnieje tylko jeden raport dla tego samego źródła i właściwości. Wiele raportów dla tego samego źródła i właściwości przesłania siebie nawzajem, albo po stronie klienta kondycji (jeśli są one wsadowe) lub po stronie magazynu kondycji. Zamiana jest oparta na numerach sekwencji; nowsze raporty (z wyższymi numerami sekwencji) zastępują starsze raporty.
Zdarzenia kondycji
Wewnętrznie magazyn kondycji przechowuje zdarzenia kondycji, które zawierają wszystkie informacje z raportów i dodatkowe metadane. Metadane obejmują czas, przez który raport został przekazany klientowi kondycji i czas jego modyfikacji po stronie serwera. Zdarzenia kondycji są zwracane przez zapytania dotyczące kondycji.
Dodane metadane zawierają:
- SourceUtcTimestamp. Czas, w jaki raport został przekazany klientowi kondycji (uniwersalny czas koordynowany).
- LastModifiedUtcTimestamp. Czas ostatniej modyfikacji raportu po stronie serwera (uniwersalny czas koordynowany).
- IsExpired. Flaga wskazująca, czy raport wygasł, gdy zapytanie zostało wykonane przez magazyn kondycji. Zdarzenie może być wygasłe tylko wtedy, gdy element RemoveWhenExpired ma wartość false. W przeciwnym razie zdarzenie nie jest zwracane przez zapytanie i jest usuwane ze sklepu.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Ostatni raz przejścia OK/ostrzeżenie/błąd. Te pola zawierają historię przejść stanu kondycji dla zdarzenia.
Pola przejścia stanu mogą służyć do inteligentniejszych alertów lub informacji o zdarzeniach dotyczących kondycji "historycznych". Umożliwiają one scenariusze, takie jak:
- Alert, gdy właściwość była ostrzegawcza/błąd przez więcej niż X minut. Sprawdzanie warunku przez pewien czas pozwala uniknąć alertów dotyczących warunków tymczasowych. Na przykład alert, jeśli stan kondycji został ostrzeżeny przez ponad pięć minut, można przetłumaczyć na (HealthState == Warning and Now — LastWarningTransitionTime > 5 minut).
- Alert tylko w przypadku warunków, które uległy zmianie w ciągu ostatnich X minut. Jeśli raport był już w błędzie przed określonym czasem, można go zignorować, ponieważ został już zasygnalizowany wcześniej.
- Jeśli właściwość przełącza się między ostrzeżeniem a błędem, ustal, jak długo jest w złej kondycji (to nie jest OK). Na przykład alert, jeśli właściwość nie była w dobrej kondycji przez ponad pięć minut, można przetłumaczyć na (HealthState != Ok i Now — LastOkTransitionTime > 5 minut).
Przykład: Zgłaszanie i ocenianie kondycji aplikacji
Poniższy przykład wysyła raport kondycji za pośrednictwem programu PowerShell w sieci szkieletowej aplikacji :/WordCount ze źródła MyWatchdog. Raport kondycji zawiera informacje o właściwości kondycji "dostępność" w stanie kondycji błędu z nieskończoną wartością TimeToLive. Następnie wysyła zapytanie do kondycji aplikacji, która zwraca zagregowane błędy stanu kondycji i zgłoszone zdarzenia kondycji na liście zdarzeń kondycji.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Użycie modelu kondycji
Model kondycji umożliwia skalowanie usług w chmurze i podstawowej platformy usługi Service Fabric, ponieważ funkcje monitorowania i kondycji są dystrybuowane między różne monitory w klastrze. Inne systemy mają pojedynczą scentralizowaną usługę na poziomie klastra, która analizuje wszystkie potencjalnie przydatne informacje emitowane przez usługi. Takie podejście utrudnia ich skalowalność. Nie pozwala również zbierać określonych informacji, aby pomóc zidentyfikować problemy i potencjalne problemy jak najbliżej głównej przyczyny.
Model kondycji jest intensywnie używany do monitorowania i diagnozowania, oceny kondycji klastra i aplikacji oraz monitorowania uaktualnień. Inne usługi używają danych kondycji do przeprowadzania automatycznych napraw, tworzenia historii kondycji klastra i wystawiania alertów w określonych warunkach.
Następne kroki
Wyświetlanie raportów kondycji usługi Service Fabric
Używanie raportów kondycji systemu do rozwiązywania problemów
Jak zgłaszać i sprawdzać kondycję usługi
Dodawanie niestandardowych raportów kondycji usługi Service Fabric