Monitorowanie kondycji łączników danych
Aby zapewnić pełne i nieprzerwane pozyskiwanie danych w usłudze Microsoft Sentinel, należy śledzić kondycję, łączność i wydajność łączników danych.
Następujące funkcje umożliwiają wykonanie tego monitorowania z poziomu usługi Microsoft Sentinel:
Skoroszyt monitorowania kondycji zbierania danych: ten skoroszyt zawiera dodatkowe monitory, wykrywa anomalie i zapewnia szczegółowe informacje dotyczące stanu pozyskiwania danych obszaru roboczego. Logika skoroszytu umożliwia monitorowanie ogólnej kondycji pozyskanych danych oraz tworzenie niestandardowych widoków i alertów opartych na regułach.
Tabela danych SentinelHealth (wersja zapoznawcza): Wykonywanie zapytań w tej tabeli zapewnia szczegółowe informacje na temat dryfów kondycji, takich jak najnowsze zdarzenia awarii na łącznik, lub łączniki ze zmianami ze stanów niepowodzenia, których można użyć do tworzenia alertów i innych akcji automatycznych. Tabela danych SentinelHealth jest obecnie obsługiwana tylko dla wybranych łączników danych.
Ważne
Tabela danych SentinelHealth jest obecnie dostępna w wersji ZAPOZNAWCZEJ. Zobacz Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure, aby uzyskać dodatkowe postanowienia prawne dotyczące funkcji platformy Azure, które są dostępne w wersji beta, wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej.
Wyświetl kondycję i stan połączonych systemów SAP: Przejrzyj informacje o kondycji systemów SAP w ramach łącznika danych SAP i użyj szablonu reguły alertu, aby uzyskać informacje o kondycji zbierania danych agenta SAP.
Korzystanie ze skoroszytu monitorowania kondycji
Aby rozpocząć, zainstaluj skoroszyt monitorowania kondycji zbierania danych z centrum zawartości i wyświetl lub utwórz kopię szablonu z sekcji Skoroszyty usługi Microsoft Sentinel.
W przypadku usługi Microsoft Sentinel w witrynie Azure Portal w obszarze Zarządzanie zawartością wybierz pozycję Centrum zawartości.
W przypadku usługi Microsoft Sentinel w portalu usługi Defender wybierz pozycję Centrum zawartości zarządzania zawartością>usługi Microsoft Sentinel.>W centrum zawartości wprowadź kondycję na pasku wyszukiwania i wybierz pozycję Monitorowanie kondycji zbierania danych z poziomu wyników.
Wybierz pozycję Zainstaluj w okienku szczegółów. Po wyświetleniu komunikatu z powiadomieniem, że skoroszyt jest zainstalowany lub jeśli zamiast instalacji zostanie wyświetlony komunikat Konfiguracja, przejdź do następnego kroku.
W usłudze Microsoft Sentinel w obszarze Zarządzanie zagrożeniami wybierz pozycję Skoroszyty.
Na stronie Skoroszyty wybierz kartę Szablony, wprowadź kondycję na pasku wyszukiwania i wybierz pozycję Monitorowanie kondycji zbierania danych z wyników.
Wybierz pozycję Wyświetl szablon, aby użyć skoroszytu w stanie takim, w jakim jest, lub wybierz pozycję Zapisz, aby utworzyć edytowalną kopię skoroszytu. Po utworzeniu kopii wybierz pozycję Wyświetl zapisany skoroszyt.
Po przejściu do skoroszytu najpierw wybierz subskrypcję i obszar roboczy , który chcesz wyświetlić, a następnie zdefiniuj element TimeRange , aby filtrować dane zgodnie z potrzebami. Użyj przełącznika Pokaż pomoc , aby wyświetlić wyjaśnienie w miejscu skoroszytu.
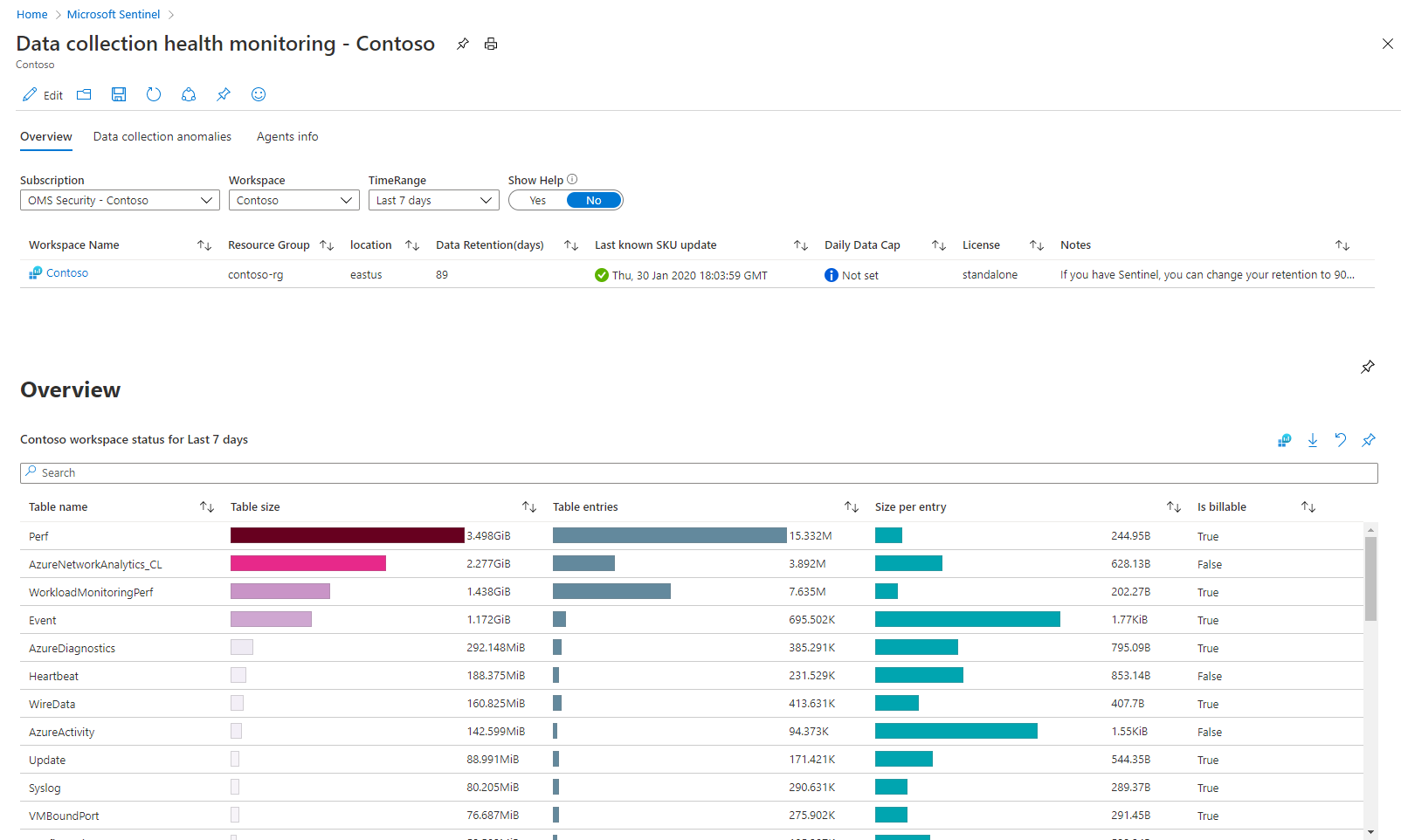

W tym skoroszycie znajdują się trzy sekcje z kartami:
Karta Przegląd przedstawia ogólny stan pozyskiwania danych w wybranym obszarze roboczym: miary woluminu, stawki EPS i czas odebrania ostatniego dziennika.
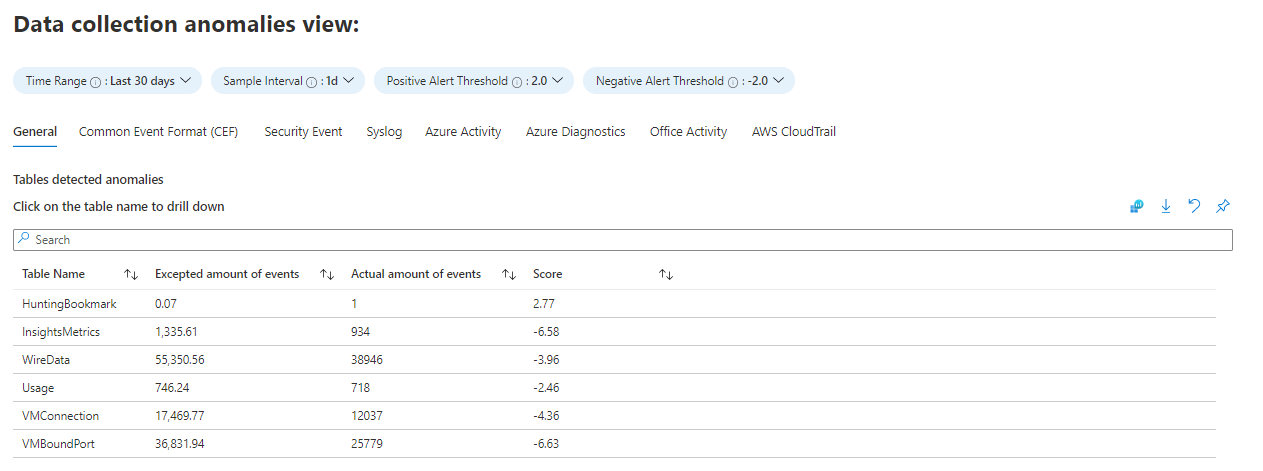
Karta Anomalie zbierania danych ułatwia wykrywanie anomalii w procesie zbierania danych według tabeli i źródła danych. Każda karta przedstawia anomalie dla określonej tabeli ( karta Ogólne zawiera kolekcję tabel). Anomalie są obliczane przy użyciu funkcji series_decompose_anomalies(), która zwraca wynik anomalii. Dowiedz się więcej na temat tej funkcji. Ustaw następujące parametry dla funkcji, aby ocenić:
AnomaliesTimeRange: ten selektor czasu dotyczy tylko widoku anomalii zbierania danych.
SampleInterval: interwał czasu, w którym dane są próbkowane w danym zakresie czasu. Wynik anomalii jest obliczany tylko dla danych ostatniego przedziału.
PositiveAlertThreshold: ta wartość definiuje próg dodatniego wyniku anomalii. Akceptuje wartości dziesiętne.
NegativeAlertThreshold: Ta wartość definiuje ujemny próg wyniku anomalii. Akceptuje wartości dziesiętne.
Karta Informacje o agencie zawiera informacje o kondycji agentów zainstalowanych na różnych maszynach, niezależnie od tego, czy maszyna wirtualna platformy Azure, inna maszyna wirtualna w chmurze, lokalna maszyna wirtualna, czy fizyczna. Monitoruj lokalizację systemową, stan pulsu i opóźnienie, dostępną pamięć i miejsce na dysku oraz operacje agenta.
W tej sekcji musisz wybrać kartę opisjącą środowisko maszyn: wybierz kartę Maszyny zarządzane przez platformę Azure, jeśli chcesz wyświetlić tylko maszyny zarządzane przez usługę Azure Arc. Wybierz kartę Wszystkie maszyny , aby wyświetlić maszyny zarządzane i inne niż platformy Azure z zainstalowanym agentem usługi Azure Monitor.



Korzystanie z tabeli danych SentinelHealth (publiczna wersja zapoznawcza)
Aby uzyskać dane dotyczące kondycji łącznika danych z tabeli danych SentinelHealth , należy najpierw włączyć funkcję kondycji usługi Microsoft Sentinel dla obszaru roboczego. Aby uzyskać więcej informacji, zobacz Włączanie monitorowania kondycji dla usługi Microsoft Sentinel.
Po włączeniu funkcji kondycji tabela danych SentinelHealth zostanie utworzona przy pierwszym zdarzeniu powodzenia lub niepowodzenia wygenerowanych dla łączników danych.
Obsługiwane łączniki danych
Tabela danych SentinelHealth jest obecnie obsługiwana tylko dla następujących łączników danych:
- Amazon Web Services (CloudTrail i S3)
- Dynamics 365
- Office 365
- Usługa Microsoft Defender dla punktu końcowego
- Analiza zagrożeń — TAXII
- Platformy analizy zagrożeń
- Dowolny łącznik oparty na platformie łącznika bez kodu
Opis zdarzeń tabeli SentinelHealth
Następujące typy zdarzeń kondycji są rejestrowane w tabeli SentinelHealth :
Zmiana stanu pobierania danych. Rejestrowane raz na godzinę, o ile stan łącznika danych pozostaje stabilny, z zdarzeniami ciągłego powodzenia lub niepowodzenia. Jeśli stan łącznika danych nie ulegnie zmianie, monitorowanie działa tylko co godzinę, aby zapobiec nadmiarowej inspekcji i zmniejszyć rozmiar tabeli. Jeśli stan łącznika danych ma ciągłe awarie, dodatkowe szczegóły dotyczące awarii znajdują się w kolumnie ExtendedProperties .
Jeśli stan łącznika danych zmieni się z powodzenia na niepowodzenie, od niepowodzenia do powodzenia lub ma zmiany przyczyn niepowodzenia, zdarzenie jest rejestrowane natychmiast, aby umożliwić zespołowi podejmowanie proaktywnych i natychmiastowych działań.
Potencjalnie przejściowe błędy, takie jak ograniczanie przepustowości usługi źródłowej, są rejestrowane dopiero po upływie ponad 60 minut. Te 60 minut umożliwiają usłudze Microsoft Sentinel rozwiązanie przejściowego problemu w zapleczu i nadrobienie zaległości w danych bez konieczności działania użytkownika. Błędy, które na pewno nie są przejściowe, są rejestrowane natychmiast.
Podsumowanie błędu. Rejestrowane raz na godzinę dla łącznika na obszar roboczy z zagregowanym podsumowaniem awarii. Zdarzenia podsumowania błędów są tworzone tylko wtedy, gdy łącznik napotkał błędy sondowania w danej godzinie. Zawierają one wszelkie dodatkowe szczegóły podane w kolumnie ExtendedProperties , takie jak okres, dla którego zapytano platformę źródłową łącznika, oraz odrębną listę błędów napotkanych w danym okresie.
Aby uzyskać więcej informacji, zobacz Schemat kolumn tabeli SentinelHealth.
Uruchamianie zapytań w celu wykrywania dryfów kondycji
Utwórz zapytania w tabeli SentinelHealth , aby ułatwić wykrywanie dryfów kondycji w łącznikach danych. Na przykład:
Wykrywanie najnowszych zdarzeń awarii na łącznik:
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
Wykrywanie łączników ze zmianami ze stanu niepowodzenia do powodzenia:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
Wykryj łączniki ze zmianami z powodzenia do stanu niepowodzenia:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
Więcej informacji na temat następujących elementów używanych w poprzednich przykładach można znaleźć w dokumentacji usługi Kusto:
- let , instrukcja
- operator where
- operator projektu
- operator summarize
- operator sprzężenia
- ago() , funkcja
- funkcja agregacji arg_max()
Aby uzyskać więcej informacji na temat języka KQL, zobacz omówienie język zapytań Kusto (KQL).
Inne zasoby:
Konfigurowanie alertów i akcji automatycznych pod kątem problemów z kondycją
Chociaż możesz użyć reguł analizy usługi Microsoft Sentinel do skonfigurowania automatyzacji w dziennikach usługi Microsoft Sentinel, jeśli chcesz otrzymywać powiadomienia i podejmować natychmiastowe działania na potrzeby dryfu kondycji w łącznikach danych, zalecamy użycie reguł alertów usługi Azure Monitor.
Na przykład:
W regule alertu usługi Azure Monitor wybierz obszar roboczy usługi Microsoft Sentinel jako zakres reguły, a pozycję Niestandardowe wyszukiwanie dzienników jako pierwszy warunek.
Dostosuj logikę alertu zgodnie z potrzebami, taką jak częstotliwość lub czas trwania wyszukiwania, a następnie użyj zapytań , aby wyszukać dryfy kondycji.
W przypadku akcji reguły wybierz istniejącą grupę akcji lub utwórz nową, zgodnie z potrzebami, aby skonfigurować powiadomienia wypychane lub inne zautomatyzowane akcje, takie jak wyzwalanie aplikacji logiki, elementu webhook lub funkcji platformy Azure w systemie.
Aby uzyskać więcej informacji, zobacz Omówienie alertów usługi Azure Monitor i dziennik alertów usługi Azure Monitor.
Następne kroki
- Dowiedz się więcej o inspekcji i monitorowaniu kondycji w usłudze Microsoft Sentinel.
- Włącz inspekcję i monitorowanie kondycji w usłudze Microsoft Sentinel.
- Monitorowanie kondycji reguł automatyzacji i podręczników.
- Monitoruj kondycję i integralność reguł analizy.
- Zobacz więcej informacji na temat schematów tabel SentinelHealth i SentinelAudit.