Istotność w wyszukiwaniu słów kluczowych (ocenianie BM25)
W tym artykule wyjaśniono algorytm oceniania istotności BM25 używany do obliczania wyników wyszukiwania w celu wyszukiwania pełnotekstowego. Istotność BM25 jest wyłączna na wyszukiwanie pełnotekstowe. Zapytania filtrów, autouzupełnianie i sugerowane zapytania, wyszukiwanie wieloznaczne i zapytania wyszukiwania rozmytego nie są oceniane ani klasyfikowane pod kątem istotności.
Algorytmy oceniania używane w wyszukiwaniu pełnotekstowym
Usługa Azure AI Search udostępnia następujące algorytmy oceniania na potrzeby wyszukiwania pełnotekstowego:
| Algorytm | Użycie | Zakres |
|---|---|---|
BM25Similarity |
Naprawiono algorytm dla wszystkich usług wyszukiwania utworzonych po lipcu 2020 r. Ten algorytm można skonfigurować, ale nie można przełączyć się na starszy (klasyczny). | Bezgraniczny. |
ClassicSimilarity |
Domyślnie w starszych usługach wyszukiwania, które poprzedzają lipiec 2020 r. W przypadku starszych usług możesz wyrazić zgodę na BM25 i wybrać algorytm BM25 dla poszczególnych indeksów. | 0 < 1.00 |
Zarówno BM25, jak i klasyczne to funkcje pobierania podobne do tf-IDF, które używają częstotliwości pobierania terminów (TF) i odwrotnej częstotliwości dokumentu (IDF) jako zmiennych do obliczania wyników istotności dla każdej pary zapytań dokumentów, która jest następnie używana do klasyfikowania wyników. Chociaż koncepcyjnie podobne do klasycznego, BM25 jest zakorzeniony w probabilistyczne pobieranie informacji, które produkuje bardziej intuicyjne dopasowania, mierzone przez badania użytkowników.
Usługa BM25 oferuje zaawansowane opcje dostosowywania, takie jak umożliwienie użytkownikowi decydowania o sposobie skalowania oceny istotności z terminem częstotliwości dopasowywania terminów.
Jak działa klasyfikacja BM25
Ocenianie istotności odnosi się do obliczania wyniku wyszukiwania (@search.score), który służy jako wskaźnik istotności elementu w kontekście bieżącego zapytania. Zakres jest niezwiązany. Jednak im wyższa ocena, tym bardziej odpowiedni element.
Wynik wyszukiwania jest obliczany na podstawie właściwości statystycznych danych wejściowych ciągu i samego zapytania. Usługa Azure AI Search znajduje dokumenty pasujące do terminów wyszukiwania (niektóre lub wszystkie, w zależności od funkcji searchMode), faworyzując dokumenty zawierające wiele wystąpień terminu wyszukiwania. Wynik wyszukiwania jest jeszcze wyższy, jeśli termin jest rzadki w indeksie danych, ale często spotykany w dokumencie. Podstawą tego podejścia do obliczania istotności jest nazwana TF-IDF lub częstotliwością odwrotnej częstotliwości dokumentu.
Wyniki wyszukiwania można powtórzyć w całym zestawie wyników. Jeśli wiele trafień ma ten sam wynik wyszukiwania, kolejność tych samych ocenianych elementów jest niezdefiniowana i nie jest stabilna. Uruchom ponownie zapytanie i możesz zobaczyć położenie przesunięcia elementów, zwłaszcza jeśli używasz bezpłatnej usługi lub rozliczanej usługi z wieloma replikami. Biorąc pod uwagę dwa elementy o identycznym wyniku, nie ma żadnej gwarancji, że pierwszy zostanie wyświetlony.
Aby przerwać krawat między powtarzającymi się wynikami, możesz dodać klauzulę $orderby do pierwszej kolejności według wyniku, a następnie kolejność według innego pola sortowalnego (na przykład $orderby=search.score() desc,Rating desc).
Do oceniania są używane tylko pola oznaczone jako searchable w indeksie lub searchFields w zapytaniu. Tylko pola oznaczone jako retrievablelub określone w select zapytaniu są zwracane w wynikach wyszukiwania wraz z ich wynikiem wyszukiwania.
Uwaga
Element A @search.score = 1 wskazuje nieoznakowany lub nies rankingowy zestaw wyników. Wynik jest jednolity we wszystkich wynikach. Wyniki nieoznaczone występują, gdy formularz zapytania jest rozmyty, symbol wieloznaczny lub kwerendy regularne albo puste wyszukiwanie (search=*czasami sparowane z filtrami, gdzie filtr jest podstawowym sposobem zwracania dopasowania).
Poniższy segment wideo szybko przekazuje do wyjaśnienia ogólnie dostępnych algorytmów klasyfikacji używanych w usłudze Azure AI Search. Możesz obejrzeć pełny film wideo, aby uzyskać więcej tła.
Wyniki w wynikach tekstowych
Za każdym razem, gdy wyniki są klasyfikowane, @search.score właściwość zawiera wartość używaną do zamawiania wyników.
W poniższej tabeli przedstawiono właściwość oceniania, algorytm i zakres.
| Metoda wyszukiwania | Parametr | Algorytm oceniania | Zakres |
|---|---|---|---|
| wyszukiwanie pełnotekstowe | @search.score |
Algorytm BM25 przy użyciu parametrów określonych w indeksie. | Bezgraniczny. |
Generowanie wyników odmiany
Wyniki wyszukiwania zawierają ogólne poczucie istotności, odzwierciedlając siłę dopasowania względem innych dokumentów w tym samym zestawie wyników. Jednak wyniki nie zawsze są spójne z jednego zapytania do następnego, więc podczas pracy z zapytaniami można zauważyć niewielkie rozbieżności w kolejności porządkowanych dokumentów wyszukiwania. Istnieje kilka wyjaśnień, dlaczego może się to zdarzyć.
| Przyczyna | opis |
|---|---|
| Identyczne wyniki | Jeśli wiele dokumentów ma ten sam wynik, każdy z nich może pojawić się jako pierwszy. |
| Zmienność danych | Zawartość indeksu różni się w miarę dodawania, modyfikowania lub usuwania dokumentów. Częstotliwości terminów zmienią się w miarę przetwarzania aktualizacji indeksu w miarę upływu czasu, co wpływa na wyniki wyszukiwania pasujących dokumentów. |
| Wiele replik | W przypadku usług korzystających z wielu replik zapytania są wystawiane równolegle dla każdej repliki. Statystyki indeksu używane do obliczania wyniku wyszukiwania są obliczane na podstawie repliki z wynikami scalanymi i uporządkowanymi w odpowiedzi zapytania. Repliki są w większości dublowane, ale statystyki mogą się różnić ze względu na małe różnice w stanie. Na przykład jedna replika mogła usunąć dokumenty, które przyczyniły się do ich statystyk, które zostały scalone z innych replik. Zazwyczaj różnice w statystykach poszczególnych replik są bardziej zauważalne w mniejszych indeksach. Poniższa sekcja zawiera więcej informacji na temat tego warunku. |
Wpływ fragmentowania na wyniki zapytania
Fragment jest fragmentem indeksu. Usługa Azure AI Search dzieli indeks na fragmenty , aby proces szybszego dodawania partycji (dzięki przeniesieniu fragmentów do nowych jednostek wyszukiwania). W usłudze wyszukiwania zarządzanie fragmentami jest szczegółem implementacji i niekonfigurowalnym, ale wiedząc, że indeks jest podzielony na fragmenty, pomaga zrozumieć okazjonalne anomalie w klasyfikacji i zachowaniach autouzupełniania:
Anomalie klasyfikacji: najpierw są obliczane wyniki wyszukiwania na poziomie fragmentu, a następnie agregowane w jeden zestaw wyników. W zależności od cech zawartości fragmentów dopasowania z jednego fragmentu mogą być klasyfikowane wyżej niż dopasowania w innej. Jeśli zauważysz intuicyjne rankingi w wynikach wyszukiwania, najprawdopodobniej jest to spowodowane skutkami fragmentowania, zwłaszcza jeśli indeksy są małe. Możesz uniknąć tych anomalii w rankingu, wybierając opcję obliczania wyników globalnie w całym indeksie, ale spowoduje to naliczenie kary za wydajność.
Anomalie autouzupełniania: zapytania autouzupełniania, gdzie dopasowania są wykonywane na pierwszych kilku znakach częściowo wprowadzonego terminu, akceptują parametr rozmyty, który wybacza małe odchylenia pisowni. W przypadku autouzupełniania dopasowywanie rozmyte jest ograniczone do terminów w ramach bieżącego fragmentu. Jeśli na przykład fragment zawiera wartość "Microsoft" i zostanie wprowadzony częściowy termin "mikro", wyszukiwarka będzie zgodna z wartością "Microsoft" w tym fragmentze, ale nie w innych fragmentach, które przechowują pozostałe części indeksu.
Na poniższym diagramie przedstawiono relację między replikami, partycjami, fragmentami i jednostkami wyszukiwania. Przedstawia przykład tego, jak pojedynczy indeks jest podzielony na cztery jednostki wyszukiwania w usłudze z dwiema replikami i dwiema partycjami. Każda z czterech jednostek wyszukiwania przechowuje tylko połowę fragmentów indeksu. Jednostki wyszukiwania w lewej kolumnie przechowują pierwszą połowę fragmentów składające się z pierwszej partycji, podczas gdy te w prawej kolumnie przechowują drugą połowę fragmentów składające się z drugiej partycji. Ponieważ istnieją dwie repliki, istnieją dwie kopie każdego fragmentu indeksu. Jednostki wyszukiwania w górnym wierszu przechowują jedną kopię składającą się z pierwszej repliki, podczas gdy te w dolnym wierszu przechowują inną kopię składającą się z drugiej repliki.
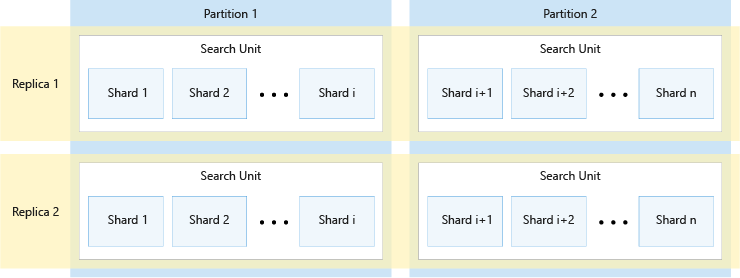
Powyższy diagram jest tylko jednym przykładem. Istnieje możliwość wielu kombinacji partycji i replik, maksymalnie 36 całkowita liczba jednostek wyszukiwania.
Uwaga
Liczba replik i partycji dzieli się równomiernie na 12 (w szczególności 1, 2, 3, 4, 6, 12). Usługa Azure AI Search wstępnie dzieli każdy indeks na 12 fragmentów, dzięki czemu może być rozłożona w równych częściach we wszystkich partycjach. Jeśli na przykład usługa ma trzy partycje i tworzysz indeks, każda partycja będzie zawierać cztery fragmenty indeksu. Jak usługa Azure AI Search fragmentuje indeks, to szczegóły implementacji, które mogą ulec zmianie w przyszłych wersjach. Chociaż liczba wynosi 12 dzisiaj, nie należy oczekiwać, że ta liczba będzie zawsze wynosić 12 w przyszłości.
Statystyki oceniania i sesje sticky
W celu zapewnienia skalowalności usługa Azure AI Search dystrybuuje każdy indeks w poziomie przez proces fragmentowania, co oznacza, że części indeksu są fizycznie oddzielone.
Domyślnie wynik dokumentu jest obliczany na podstawie właściwości statystycznych danych w ramach fragmentu. Takie podejście nie jest zwykle problemem dla dużych korpusów danych i zapewnia lepszą wydajność niż obliczanie wyniku na podstawie informacji we wszystkich fragmentach. Oznacza to, że użycie tej optymalizacji wydajności może spowodować, że dwa bardzo podobne dokumenty (a nawet identyczne dokumenty) kończą się różnymi ocenami istotności, jeśli trafią do różnych fragmentów.
Jeśli wolisz obliczyć wynik na podstawie właściwości statystycznych we wszystkich fragmentach, możesz to zrobić, dodając scoringStatistics=global jako parametr zapytania (lub dodając "scoringStatistics": "global" jako parametr treści żądania zapytania).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Użycie scoringStatistics zapewni, że wszystkie fragmenty w tej samej repliki zapewniają te same wyniki. Oznacza to, że różne repliki mogą się nieco różnić od siebie, ponieważ zawsze są aktualizowane przy użyciu najnowszych zmian w indeksie. W niektórych scenariuszach możesz chcieć, aby użytkownicy uzyskali bardziej spójne wyniki podczas "sesji zapytania". W takich scenariuszach możesz podać element sessionId w ramach zapytań. Jest sessionId to unikatowy ciąg, który można utworzyć w celu odwoływania się do unikatowej sesji użytkownika.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Tak długo, jak to samo sessionId jest używane, podejmowana jest próba ukierunkowana na tę samą replikę, co zwiększa spójność wyników, które będą widoczne dla użytkowników.
Uwaga
Ponowne użycie tych samych sessionId wartości wielokrotnie może zakłócać równoważenie obciążenia żądań między replikami i niekorzystnie wpływać na wydajność usługi wyszukiwania. Wartość używana jako sessionId nie może rozpoczynać się od znaku "_".
Dostrajanie trafności
W usłudze Azure AI Search wyszukaj słowa kluczowe i część tekstową zapytania hybrydowego, możesz skonfigurować parametry algorytmu BM25 oraz dostroić istotność wyszukiwania i zwiększyć wyniki wyszukiwania za pomocą następujących mechanizmów.
| Metoda | Implementacja | opis |
|---|---|---|
| Konfiguracja algorytmu BM25 | Indeks wyszukiwania | Konfigurowanie sposobu, w jaki długość i częstotliwość terminów dokumentu wpływają na ocenę istotności. |
| Profile oceniania | Indeks wyszukiwania | Podaj kryteria zwiększania wyniku wyszukiwania dopasowania na podstawie cech zawartości. Na przykład można zwiększyć dopasowania na podstawie ich potencjału przychodu, podwyższyć poziom nowszych elementów lub zwiększyć elementy, które były w spisie zbyt długo. Profil oceniania jest częścią definicji indeksu składającej się z pól ważonych, funkcji i parametrów. Istniejący indeks można zaktualizować przy użyciu zmian profilu oceniania bez ponoszenia ponownego kompilowania indeksu. |
| Ranking semantyczny | Żądanie zapytania | Stosuje zrozumienie odczytu maszynowego do wyników wyszukiwania, promowanie bardziej semantycznie odpowiednich wyników na górze. |
| featuresMode parametr | Żądanie zapytania | Ten parametr jest najczęściej używany do rozpakowywania oceny w rankingu BM25, ale może być używany w kodzie, który udostępnia niestandardowe rozwiązanie oceniania. |
featuresMode parametr (wersja zapoznawcza)
Żądania wyszukiwania dokumentów obsługują parametr featuresMode, który zawiera bardziej szczegółowe informacje o wyniku istotności BM25 na poziomie pola. Podczas gdy element @searchScore jest obliczany dla dokumentu all-up (jak istotny jest ten dokument w kontekście tego zapytania), featuresMode ujawnia informacje o poszczególnych polach, jak wyrażono w @search.features strukturze. Struktura zawiera wszystkie pola używane w zapytaniu (określone pola za pośrednictwem pól wyszukiwania w zapytaniu lub wszystkie pola przypisywane jako przeszukiwalne w indeksie).
Dla każdego pola @search.features podaj następujące wartości:
- Liczba unikatowych tokenów znalezionych w polu
- Wynik podobieństwa lub miara tego, jak podobna jest zawartość pola względem terminu zapytania
- Częstotliwość terminów lub liczba znalezionych terminów zapytania w polu
W przypadku zapytania przeznaczonego dla pól "description" i "title" odpowiedź @search.features zawierająca może wyglądać następująco:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Możesz użyć tych punktów danych w niestandardowych rozwiązaniach oceniania lub użyć informacji do debugowania problemów ze istotnością wyszukiwania.
Parametr featuresMode nie jest udokumentowany w interfejsach API REST, ale można go używać w podglądzie wywołania interfejsu API REST do wyszukiwania dokumentów wyszukiwania tekstu (słowa kluczowego), które jest klasyfikowane przez BM25.
Liczba sklasyfikowanych wyników w odpowiedzi na zapytanie pełnotekstowe
Jeśli domyślnie nie używasz stronicowania, wyszukiwarka zwraca 50 najlepszych dopasowań klasyfikacji dla wyszukiwania pełnotekstowego. Możesz użyć parametru top , aby zwrócić mniejszą lub większą liczbę elementów (do 1000 w pojedynczej odpowiedzi). Możesz użyć funkcji skip i next do stronicowania wyników. Stronicowanie określa liczbę wyników na każdej stronie logicznej i obsługuje nawigację po zawartości. Aby uzyskać więcej informacji, zobacz Wyniki wyszukiwania kształtów.
Jeśli zapytanie pełnotekstowe jest częścią zapytania hybrydowego, możesz ustawićmaxTextRecallSize, aby zwiększyć lub zmniejszyć liczbę wyników po stronie tekstowej zapytania.
Wyszukiwanie pełnotekstowe podlega maksymalnemu limitowi 1000 dopasowań (zobacz Limity odpowiedzi interfejsu API). Po znalezieniu 1000 dopasowań wyszukiwarka nie szuka już więcej.