Pojęcia dotyczące zestawu umiejętności w usłudze Azure AI Search
Ten artykuł jest przeznaczony dla deweloperów, którzy potrzebują głębszego zrozumienia kompozycji zestawu umiejętności i zakładają znajomość koncepcji wysokiego poziomu wzbogacania sztucznej inteligencji lub zastosowania sztucznej inteligencji w usłudze Azure AI Search.
Zestaw umiejętności to obiekt wielokrotnego użytku w usłudze Azure AI Search dołączony do indeksatora. Zawiera on co najmniej jedną umiejętności, która wywołuje wbudowaną sztuczną inteligencję lub zewnętrzne przetwarzanie niestandardowe za pośrednictwem dokumentów pobranych z zewnętrznego źródła danych.
Na poniższym diagramie przedstawiono podstawowy przepływ danych wykonywania zestawu umiejętności.
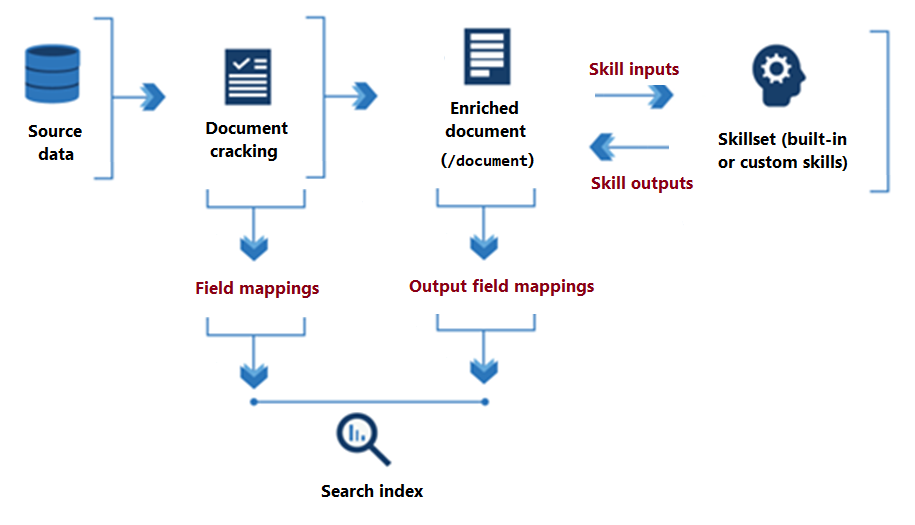
Od początku przetwarzania zestawu umiejętności do jego zakończenia, umiejętności odczytywane i zapisywane w wzbogaconym dokumencie , który istnieje w pamięci. Początkowo wzbogacony dokument to tylko nieprzetworzona zawartość wyodrębniona ze źródła danych (przegubiona "/document" jako węzeł główny). Przy każdym wykonaniu umiejętności wzbogacony dokument zyskuje strukturę i istotę, ponieważ każda umiejętność zapisuje swoje dane wyjściowe jako węzły na grafie.
Po wykonaniu zestawu umiejętności dane wyjściowe wzbogaconego dokumentu znajdują drogę do indeksu za pomocą mapowań pól wyjściowych zdefiniowanych przez użytkownika. Dowolna nieprzetworzona zawartość, która ma zostać przeniesiona bez zmian, ze źródła do indeksu, jest definiowana za pomocą mapowań pól. Z kolei mapowania pól wyjściowych przesyłają zawartość w pamięci (węzły) do indeksu.
Aby skonfigurować zastosowaną sztuczną inteligencję, określ ustawienia w zestawie umiejętności i indeksatorze.
Definicja zestawu umiejętności
Zestaw umiejętności to tablica co najmniej jednego umiejętności , które wykonują wzbogacanie, takie jak tłumaczenie tekstu lub optyczne rozpoznawanie znaków (OCR) w pliku obrazu. Umiejętności mogą być wbudowanymi umiejętnościami firmy Microsoft lub niestandardowymi umiejętnościami dotyczącymi logiki przetwarzania hostowanych zewnętrznie. Zestaw umiejętności tworzy wzbogacone dokumenty, które są używane podczas indeksowania lub przewidywane do magazynu wiedzy.
Umiejętności mają kontekst, dane wejściowe i wyjściowe:
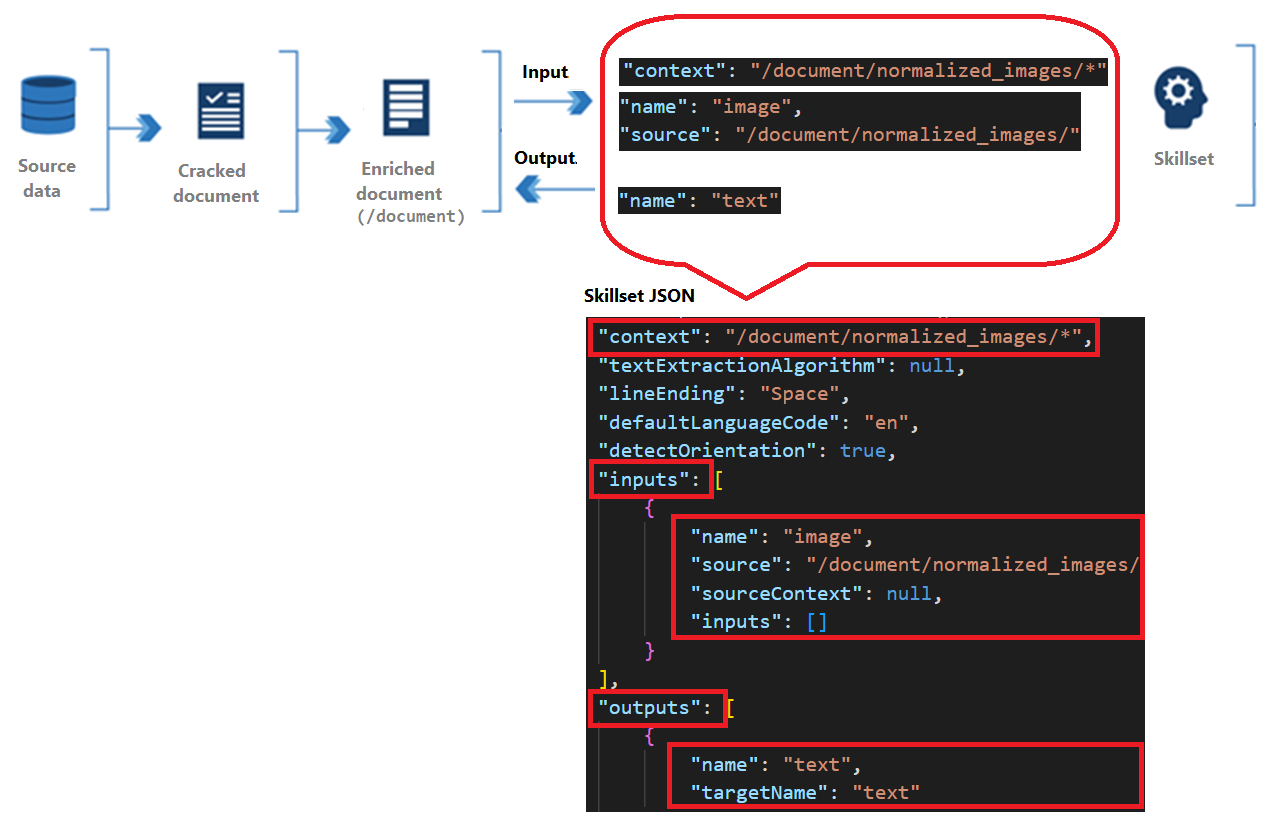
Kontekst odwołuje się do zakresu operacji, która może być raz na dokument lub raz dla każdego elementu w kolekcji.
Dane wejściowe pochodzą z węzłów w wzbogaconym dokumencie, gdzie "źródło" i "nazwa" identyfikują dany węzeł.
Dane wyjściowe są wysyłane z powrotem do wzbogaconego dokumentu jako nowego węzła. Wartości to "nazwa" węzła i zawartość węzła. Jeśli nazwa węzła jest zduplikowana, możesz ustawić nazwę docelową dla uściślania.
Kontekst umiejętności
Każda umiejętność ma kontekst, który może być całym dokumentem (/document) lub węzłem niższym w drzewie (/document/countries/*).
Kontekst określa:
Liczba wykonań umiejętności przez pojedynczą wartość (raz na pole, na dokument) lub w kolekcji, w której dodanie
/*wyników wywołania umiejętności dla każdego wystąpienia w kolekcji.Deklaracja wyjściowa lub gdzie w drzewie wzbogacania dodawane są dane wyjściowe umiejętności. Dane wyjściowe są zawsze dodawane do drzewa jako elementy podrzędne węzła kontekstu.
Kształt danych wejściowych. W przypadku kolekcji wielo poziomów ustawienie kontekstu kolekcji nadrzędnej wpływa na kształt danych wejściowych dla umiejętności. Jeśli na przykład masz drzewo wzbogacania z listą krajów/regionów, każda wzbogacona listą stanów zawierających listę kodów POCZTOWYch, sposób ustawiania kontekstu określa sposób interpretowania danych wejściowych.
Kontekst Dane wejściowe Kształt danych wejściowych Wywołanie umiejętności /document/countries/*/document/countries/*/states/*/zipcodes/*Lista wszystkich kodów pocztowych w kraju/regionie Raz na kraj/region /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Lista kodów pocztowych w stanie Raz na kombinację kraju/regionu i stanu
Zależności umiejętności
Umiejętności mogą być wykonywane niezależnie i równolegle lub sekwencyjnie, jeśli przekażesz dane wyjściowe jednej umiejętności do innej umiejętności. W poniższym przykładzie pokazano dwa wbudowane umiejętności , które są wykonywane w sekwencji:
Umiejętność #1 to umiejętność dzielenia tekstu, która akceptuje zawartość pola źródłowego "reviews_text" jako dane wejściowe i dzieli tę zawartość na "strony" z 5000 znaków jako dane wyjściowe. Dzielenie dużego tekstu na mniejsze fragmenty może generować lepsze wyniki dla umiejętności, takich jak wykrywanie tonacji.
Umiejętność #2 to umiejętność wykrywania tonacji akceptuje "strony" jako dane wejściowe i tworzy nowe pole o nazwie "Tonacja" jako dane wyjściowe zawierające wyniki analizy tonacji.
Zwróć uwagę, że dane wyjściowe pierwszej umiejętności ("pages") są używane w analizie tonacji, gdzie "/document/reviews_text/pages/*" jest zarówno kontekstem, jak i danymi wejściowymi. Aby uzyskać więcej informacji na temat formułowania ścieżki, zobacz Jak odwoływać się do wzbogacenia.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Drzewo wzbogacania
Wzbogacony dokument to tymczasowa, podobna do drzewa struktura danych utworzona podczas wykonywania zestawu umiejętności, która zbiera wszystkie zmiany wprowadzone za pomocą umiejętności. Zbiorczo wzbogacania są reprezentowane jako hierarchia węzłów do adresowania. Węzły obejmują również wszystkie niezachwytywane pola, które są przekazywane dosłownie z zewnętrznego źródła danych.
Wzbogacony dokument istnieje na czas trwania wykonywania zestawu umiejętności, ale można go buforować lub wysyłać do magazynu wiedzy.
Początkowo wzbogacony dokument jest po prostu zawartością wyodrębnianą ze źródła danych podczas pękania dokumentu, gdzie tekst i obrazy są wyodrębniane ze źródła i udostępniane do analizy języka lub obrazu.
Początkowa zawartość to metadane i węzeł główny (document/content). Węzeł główny jest zwykle całym dokumentem lub znormalizowanym obrazem wyodrębnionym ze źródła danych podczas pękania dokumentu. Sposób, w jaki jest on opisany w drzewie wzbogacania, różni się w zależności od typu źródła danych. W poniższej tabeli przedstawiono stan dokumentu wchodzącego w potok wzbogacania dla kilku obsługiwanych źródeł danych:
| Źródło danych\Tryb analizowania | Wartość domyślna | JSON, linie JSON i CSV |
|---|---|---|
| Blob Storage | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
Nie dotyczy |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
Nie dotyczy |
W miarę wykonywania umiejętności dane wyjściowe są dodawane do drzewa wzbogacania jako nowe węzły. Jeśli wykonywanie umiejętności odbywa się w całym dokumencie, węzły są dodawane na pierwszym poziomie w katalogu głównym.
Węzły mogą być używane jako dane wejściowe dla umiejętności podrzędnych. Na przykład umiejętności tworzące zawartość, takie jak przetłumaczone ciągi, mogą stać się danymi wejściowymi umiejętności, które rozpoznają jednostki lub wyodrębnią kluczowe frazy.
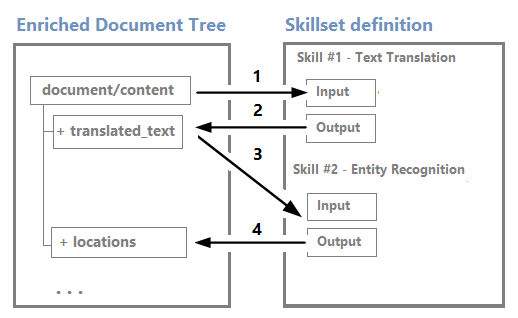
Mimo że można wizualizować drzewo wzbogacania i pracować z nim za pomocą edytora wizualizacji Sesje debugowania, jest to głównie struktura wewnętrzna.
Wzbogacenia są niezmienne: po utworzeniu węzły nie mogą być edytowane. Gdy zestawy umiejętności staną się bardziej złożone, tak samo jak drzewo wzbogacania, ale nie wszystkie węzły w drzewie wzbogacania muszą sprawić, że zostanie on dołączony do indeksu lub magazynu wiedzy.
Można selektywnie utrwalać tylko podzbiór danych wyjściowych wzbogacania, aby zachować tylko to, co zamierzasz użyć. Mapowania pól wyjściowych w definicji indeksatora określają, jaka zawartość jest pozyskiwana w indeksie wyszukiwania. Podobnie, jeśli tworzysz magazyn wiedzy, możesz mapować dane wyjściowe na kształty przypisane do projekcji.
Uwaga
Format drzewa wzbogacania umożliwia potokowi wzbogacania dołączanie metadanych do nawet pierwotnych typów danych. Metadane nie będą prawidłowym obiektem JSON, ale mogą być projektowane w prawidłowym formacie JSON w definicjach projekcji w magazynie wiedzy. Aby uzyskać więcej informacji, zobacz Umiejętności kształtowania.
Definicja indeksatora
Indeksator ma właściwości i parametry używane do konfigurowania wykonywania indeksatora. Wśród tych właściwości są mapowania, które ustawiają ścieżkę danych na pola w indeksie wyszukiwania.

Istnieją dwa zestawy mapowań:
"fieldMappings" mapuje pole źródłowe na pole wyszukiwania.
"outputFieldMappings" mapuje węzeł w wzbogaconym dokumencie na pole wyszukiwania.
Właściwość "sourceFieldName" określa pole w źródle danych lub w węźle w drzewie wzbogacania. Właściwość "targetFieldName" określa pole wyszukiwania w indeksie, który odbiera zawartość.
Przykład wzbogacania
Korzystając z zestawu umiejętności w hotelu jako punktu odniesienia, w tym przykładzie wyjaśniono, jak drzewo wzbogacania ewoluuje poprzez wykonywanie umiejętności przy użyciu diagramów koncepcyjnych.
W tym przykładzie pokazano również:
- Jak działa kontekst i dane wejściowe umiejętności, aby określić, ile razy wykonywana jest umiejętność
- Jaki kształt danych wejściowych jest oparty na kontekście
W tym przykładzie pola źródłowe z pliku CSV obejmują recenzje klientów dotyczące hoteli ("reviews_text") i ocen ("reviews_rating"). Indeksator dodaje pola metadanych z usługi Blob Storage, a umiejętności dodają przetłumaczony tekst, wyniki tonacji i wykrywanie kluczowych fraz.
W przykładzie recenzji hotelowych "dokument" w procesie wzbogacania reprezentuje pojedynczy przegląd hotelu.
Napiwek
Możesz utworzyć indeks wyszukiwania i magazyn wiedzy dla tych danych w witrynie Azure Portal lub interfejsach API REST. Możesz również użyć sesji debugowania, aby uzyskać wgląd w skład zestawu umiejętności, zależności i wpływ na drzewo wzbogacania. Obrazy w tym artykule są pobierane z sesji debugowania.
Koncepcyjnie początkowe drzewo wzbogacania wygląda następująco:

Węzeł główny dla wszystkich wzbogacenia to "/document". Podczas pracy z indeksatorami "/document" obiektów blob węzeł ma węzły podrzędne i "/document/content""/document/normalized_images". Gdy dane są woluminami CSV, jak w tym przykładzie, nazwy kolumn są mapowe na węzły poniżej "/document".
Umiejętność nr 1: Dzielenie umiejętności
Gdy zawartość źródłowa składa się z dużych fragmentów tekstu, warto podzielić ją na mniejsze składniki w celu zintegrowanej wektoryzacji lub większą dokładność języka, tonacji i wykrywania kluczowych fraz. Dostępne są dwa ziarna: strony i zdania. Strona składa się z około 5000 znaków.
Alternatywą dla fragmentowania z umiejętnością Split jest umiejętność układ dokumentu, ale ta umiejętność jest poza zakresem tego artykułu.
Gdy fragmentowanie jest wymagane, umiejętność Dzielenia jest zazwyczaj pierwszą w zestawie umiejętności.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Z kontekstem "/document/reviews_text"umiejętności , dzielenie umiejętności wykonuje raz dla reviews_text. Dane wyjściowe umiejętności to lista zawierająca reviews_text fragmenty do 5000 segmentów znaków. Dane wyjściowe z umiejętności podziału mają nazwę pages i są dodawane do drzewa wzbogacania. Funkcja targetName umożliwia zmianę nazwy danych wyjściowych umiejętności przed dodaniu do drzewa wzbogacania.
Drzewo wzbogacania ma teraz nowy węzeł umieszczony w kontekście umiejętności. Ten węzeł jest dostępny dla dowolnych umiejętności, projekcji lub mapowania pól wyjściowych.

Aby uzyskać dostęp do dowolnych wzbogacenia dodanych do węzła przez umiejętności, wymagana jest pełna ścieżka wzbogacania. Jeśli na przykład chcesz użyć tekstu z węzła pages jako danych wejściowych do innej umiejętności, określ go jako "/document/reviews_text/pages/*". Aby uzyskać więcej informacji na temat ścieżek, zobacz Temat Wzbogacanie odwołań.
Umiejętność #2 Wykrywanie języka
Dokumenty dotyczące przeglądu hotelu obejmują opinie klientów wyrażone w wielu językach. Umiejętność wykrywania języka określa, który język jest używany. Wynik zostanie następnie przekazany do wyodrębniania kluczowych fraz i wykrywania tonacji (nie pokazano), biorąc pod uwagę język podczas wykrywania tonacji i fraz.
Podczas gdy umiejętność wykrywania języka to trzecia (umiejętność 3) zdefiniowana w zestawie umiejętności, następną umiejętnością do wykonania. Nie wymaga żadnych danych wejściowych, więc wykonuje je równolegle z poprzednią umiejętnością. Podobnie jak wcześniejsza umiejętność dzielenia, umiejętność wykrywania języka jest również wywoływana raz dla każdego dokumentu. Drzewo wzbogacania ma teraz nowy węzeł języka.

Umiejętności #3 i #4 (analiza tonacji i wykrywanie kluczowych fraz)
Opinie klientów odzwierciedlają szereg pozytywnych i negatywnych środowisk. Umiejętność analizy tonacji analizuje opinie i przypisuje wynik wraz z kontinuum ujemnym do dodatnich liczb lub neutralne, jeśli tonacja jest niezdefiniowana. Równolegle do analizy tonacji wykrywanie fraz kluczowych identyfikuje i wyodrębnia wyrazy i krótkie frazy, które pojawiają się w wyniku.
Biorąc pod uwagę kontekst /document/reviews_text/pages/*, zarówno analiza tonacji, jak i kluczowe umiejętności fraz są wywoływane raz dla każdego elementu w pages kolekcji. Dane wyjściowe z umiejętności będą węzłem w ramach skojarzonego elementu strony.
Teraz powinno być w stanie przyjrzeć się pozostałym umiejętnościom w zestawie umiejętności i zwizualizować, jak drzewo wzbogacania rośnie wraz z wykonywaniem każdej umiejętności. Niektóre umiejętności, takie jak umiejętność scalania i umiejętność kształtowania, również tworzą nowe węzły, ale używają tylko danych z istniejących węzłów i nie tworzą nowych wzbogacenia netto.

Kolory łączników w drzewie powyżej wskazują, że wzbogacenia zostały utworzone przez różne umiejętności, a węzły muszą zostać rozwiązane indywidualnie i nie będą częścią obiektu zwróconego podczas wybierania węzła nadrzędnego.
Umiejętność #5 Umiejętność kształtowania
Jeśli dane wyjściowe zawierają magazyn wiedzy, dodaj umiejętność kształtowania jako ostatni krok. Umiejętność kształtowania tworzy kształty danych z węzłów w drzewie wzbogacania. Na przykład można skonsolidować wiele węzłów w jeden kształt. Następnie można projektować ten kształt jako tabelę (węzły stają się kolumnami w tabeli), przekazując kształt według nazwy do projekcji tabeli.
Umiejętność kształtowania jest łatwa do pracy, ponieważ koncentruje się na kształtowaniu w ramach jednej umiejętności. Alternatywnie można zdecydować się na kształtowanie w linii w ramach poszczególnych projekcji. Umiejętność kształtowania nie dodaje ani nie odejmuje od drzewa wzbogacania, więc nie jest wizualizowany. Zamiast tego możesz traktować umiejętności kształtowania jako środki, za pomocą których zmieniasz już drzewo wzbogacania. Koncepcyjnie jest to podobne do tworzenia widoków poza tabelami w bazie danych.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Następne kroki
Korzystając z wprowadzenia i przykładu, spróbuj utworzyć swój pierwszy zestaw umiejętności przy użyciu wbudowanych umiejętności.