Wysoka dostępność (niezawodność) w usłudze Azure Database for PostgreSQL — serwer elastyczny
DOTYCZY: Azure Database for PostgreSQL — serwer elastyczny
Azure Database for PostgreSQL — serwer elastyczny
W tym artykule opisano wysoką dostępność w usłudze Azure Database for PostgreSQL — serwer elastyczny, który obejmuje strefy dostępności i odzyskiwanie między regionami oraz ciągłość działalności biznesowej. Aby uzyskać bardziej szczegółowe omówienie niezawodności na platformie Azure, zobacz Niezawodność platformy Azure.
Usługa Azure Database for PostgreSQL — serwer elastyczny oferuje obsługę wysokiej dostępności przez aprowizowanie fizycznie rozdzielonych replik podstawowych i rezerwowych w tej samej strefie dostępności (strefowo) lub w strefach dostępności (strefowo nadmiarowych). Ten model wysokiej dostępności został zaprojektowany w celu zapewnienia, że zatwierdzone dane nigdy nie zostaną utracone w przypadku awarii. W konfiguracji wysokiej dostępności dane są synchronicznie zatwierdzane zarówno na serwerach podstawowych, jak i rezerwowych. Model został zaprojektowany tak, aby baza danych nie stała się pojedynczym punktem awarii w architekturze oprogramowania. Aby uzyskać więcej informacji na temat obsługi stref wysokiej dostępności i dostępności, zobacz Obsługa stref dostępności.
Obsługa strefy dostępności
Strefy dostępności są fizycznie oddzielnymi grupami centrów danych w każdym regionie świadczenia usługi Azure. Gdy jedna strefa ulegnie awarii, usługi mogą przejść w tryb failover do jednej z pozostałych stref.
Aby uzyskać więcej informacji na temat stref dostępności na platformie Azure, zobacz Co to są strefy dostępności?
Azure Database for PostgreSQL — serwer elastyczny obsługuje zarówno modele strefowo nadmiarowe, jak i strefowe na potrzeby konfiguracji wysokiej dostępności. Obie konfiguracje wysokiej dostępności umożliwiają automatyczne przełączanie w tryb failover z zerową utratą danych zarówno podczas planowanych, jak i nieplanowanych zdarzeń.
Strefowo nadmiarowe. Strefowo nadmiarowa wysoka dostępność wdraża replikę rezerwową w innej strefie z funkcją automatycznego trybu failover. Nadmiarowość strefy zapewnia najwyższy poziom dostępności, ale wymaga skonfigurowania nadmiarowości aplikacji w różnych strefach. Z tego powodu wybierz nadmiarowość strefy, jeśli chcesz zapewnić ochronę przed awariami na poziomie strefy dostępności i gdy opóźnienie w strefach dostępności jest akceptowalne. Chociaż może wystąpić pewien wpływ opóźnienia na zapisy i zatwierdzenia z powodu replikacji synchronicznej, nie ma to wpływu na zapytania odczytu. Ten wpływ jest bardzo specyficzny dla obciążeń, wybranego typu jednostki SKU i regionu.
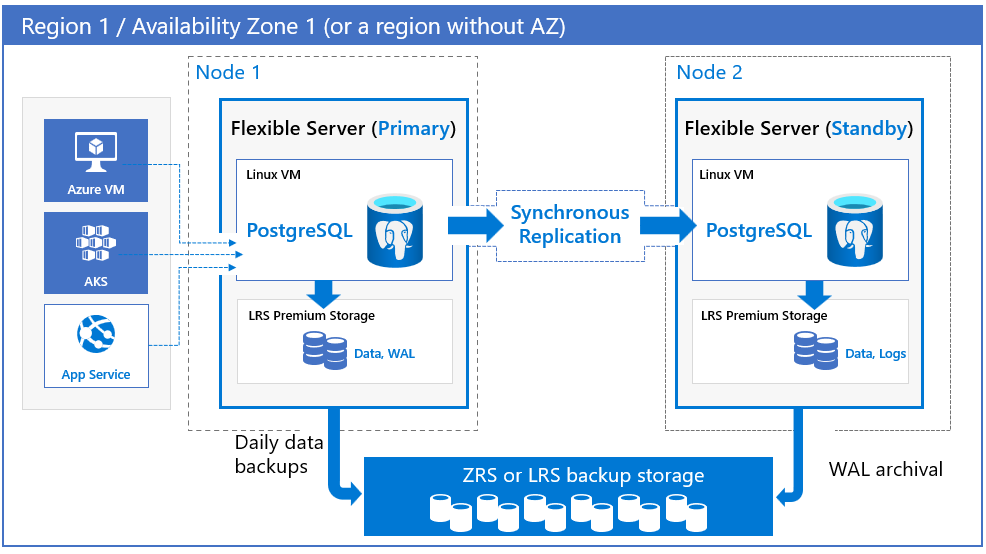
Możesz wybrać region i strefy dostępności zarówno dla serwerów podstawowych, jak i rezerwowych. Serwer repliki rezerwowej jest aprowizowany w wybranej strefie dostępności w tym samym regionie z podobną konfiguracją obliczeniową, magazynową i siecią co serwer podstawowy. Pliki danych i pliki dziennika transakcji (dzienniki zapisu z wyprzedzeniem, np. WAL) są przechowywane w magazynie lokalnie nadmiarowym (LRS) w każdej strefie dostępności, automatycznie przechowując trzy kopie danych. Konfiguracja strefowo nadmiarowa zapewnia fizyczną izolację całego stosu między serwerami podstawowymi i rezerwowymi.

Strefowe. Wybierz wdrożenie strefowe, jeśli chcesz uzyskać najwyższy poziom dostępności w ramach pojedynczej strefy dostępności, ale z najniższym opóźnieniem sieci. Możesz wybrać region i strefę dostępności, aby wdrożyć zarówno podstawowy serwer bazy danych. Serwer repliki rezerwowej jest automatycznie aprowizowany i zarządzany w tej samej strefie dostępności — z podobną konfiguracją obliczeniową, magazynem i siecią — jako serwer podstawowy. Konfiguracja strefowa chroni bazy danych przed awariami na poziomie węzła, a także pomaga zmniejszyć przestoje aplikacji podczas planowanych i nieplanowanych zdarzeń przestojów. Dane z serwera podstawowego są replikowane do repliki rezerwowej w trybie synchronicznym. W przypadku zakłóceń na serwerze podstawowym serwer jest automatycznie przełączony w tryb failover do repliki rezerwowej.


Uwaga
Zarówno modele wdrażania strefowego, jak i strefowo nadmiarowego zachowują się tak samo. Różne dyskusje w poniższych sekcjach mają zastosowanie do obu tych, chyba że zostanie wywołany inaczej.
Wymagania wstępne
Nadmiarowość strefy:
Opcja nadmiarowości strefy jest dostępna tylko w regionach, które obsługują strefy dostępności.
Nadmiarowość strefowa nie jest obsługiwana w następujących celach:
- Azure Database for PostgreSQL — jednostka SKU pojedynczego serwera.
- Warstwa obliczeniowa z możliwością rozszerzenia.
- Regiony z dostępnością w jednej strefie.
Strefowego:
- Opcja wdrożenia strefowego jest dostępna we wszystkich regionach świadczenia usługi Azure, w których można wdrożyć serwer elastyczny.
Funkcje wysokiej dostępności
Replika rezerwowa jest wdrażana w tej samej konfiguracji maszyny wirtualnej — w tym rdzeni wirtualnych, magazynu, ustawień sieciowych — jako serwera podstawowego.
Możesz dodać obsługę strefy dostępności dla istniejącego serwera bazy danych.
Replikę rezerwną można usunąć, wyłączając wysoką dostępność.
Możesz wybrać strefy dostępności dla serwerów podstawowej i rezerwowej bazy danych w celu zapewnienia dostępności strefowo nadmiarowej.
Takie operacje jak zatrzymywanie, uruchamianie i ponowne uruchamianie są wykonywane jednocześnie na podstawowych i rezerwowych serwerach bazy danych.
W modelach strefowo nadmiarowych i strefowych automatyczne kopie zapasowe są wykonywane okresowo z podstawowego serwera bazy danych. Jednocześnie dzienniki transakcji są stale archiwizowane w magazynie kopii zapasowych z repliki rezerwowej. Jeśli region obsługuje strefy dostępności, dane kopii zapasowej są przechowywane w magazynie strefowo nadmiarowym (ZRS). W regionach, które nie obsługują stref dostępności, dane kopii zapasowych są przechowywane w magazynie lokalnie nadmiarowym (LRS).
Klienci zawsze łączą się z końcową nazwą hosta podstawowego serwera bazy danych.
Wszelkie zmiany parametrów serwera są również stosowane do repliki rezerwowej.
Istnieje możliwość ponownego uruchomienia serwera w celu pobrania wszelkich zmian parametrów statycznych serwera.
Okresowe działania konserwacyjne, takie jak uaktualnienia wersji pomocniczej, są wykonywane najpierw w trybie wstrzymania i w celu zmniejszenia przestoju, rezerwa jest promowana do warstwy podstawowej, dzięki czemu obciążenia mogą być nadal włączone, podczas gdy zadania konserwacji są stosowane w pozostałym węźle.
Monitorowanie kondycji wysokiej dostępności
Monitorowanie stanu kondycji wysokiej dostępności (HA) w usłudze Azure Database for PostgreSQL — serwer elastyczny zapewnia ciągłe omówienie kondycji i gotowości wystąpień z włączoną wysoką dostępnością. Ta funkcja monitorowania korzysta z platformy Azure Resource Health Check (RHC) do wykrywania i powiadamiania o wszelkich problemach, które mogą mieć wpływ na gotowość bazy danych do trybu failover lub ogólną dostępność. Oceniając kluczowe metryki, takie jak stan połączenia, stan trybu failover i kondycja replikacji danych, monitorowanie stanu kondycji wysokiej dostępności umożliwia aktywne rozwiązywanie problemów i pomaga zachować czas pracy i wydajność bazy danych.
Klienci mogą używać monitorowania stanu kondycji wysokiej dostępności w celu:
- Uzyskaj wgląd w kondycję replik podstawowych i rezerwowych w czasie rzeczywistym, ze wskaźnikami stanu, które ujawniają potencjalne problemy, takie jak obniżona wydajność lub blokowanie sieci.
- Skonfiguruj alerty dotyczące terminowych powiadomień o wszelkich zmianach stanu wysokiej dostępności, zapewniając natychmiastowe działanie w celu rozwiązania potencjalnych zakłóceń.
- Zoptymalizuj gotowość do trybu failover, identyfikując i rozwiązując problemy, zanim wpłyną one na operacje bazy danych.
Aby uzyskać szczegółowy przewodnik dotyczący konfigurowania i interpretowania stanu kondycji wysokiej dostępności, zapoznaj się z głównym artykułem Monitorowanie stanu kondycji wysokiej dostępności (HA) dla usługi Azure Database for PostgreSQL — serwer elastyczny.
Ograniczenia wysokiej dostępności
Ze względu na synchroniczną replikację do serwera rezerwowego, zwłaszcza w przypadku konfiguracji strefowo nadmiarowej, aplikacje mogą mieć podwyższony poziom opóźnienia zapisu i zatwierdzania.
Repliki rezerwowej nie można używać do wykonywania zapytań odczytu.
W zależności od obciążenia i działania na serwerze podstawowym proces trybu failover może potrwać dłużej niż 120 sekund z powodu odzyskiwania związanego z repliką rezerwową przed podwyższeniem poziomu.
Serwer rezerwowy zwykle odzyskuje pliki WAL o rozmiarze 40 MB/s. W przypadku większych jednostek SKU ta szybkość może wzrosnąć do nawet 200 MB/s. Jeśli obciążenie przekroczy ten limit, możesz napotkać dłuższy czas na ukończenie odzyskiwania podczas pracy w trybie failover lub po ustanowieniu nowej rezerwy.
Ponowne uruchomienie podstawowego serwera bazy danych powoduje również ponowne uruchomienie repliki rezerwowej.
Konfigurowanie dodatkowej rezerwy nie jest obsługiwane.
Nie można zaplanować konfigurowania zadań zarządzania zainicjowanych przez klienta w oknie konserwacji zarządzanej.
Planowane zdarzenia, takie jak skalowanie obliczeń i skalowanie magazynu, są wykonywane najpierw w rezerwie, a następnie na serwerze podstawowym. Obecnie serwer nie jest w trybie failover dla tych planowanych operacji.
Jeśli dekodowanie logiczne lub replikacja logiczna jest skonfigurowana przy użyciu serwera elastycznego skonfigurowanego pod kątem dostępności, w przypadku przejścia w tryb failover na serwer rezerwowy miejsca replikacji logicznej nie są kopiowane do serwera rezerwowego. Aby zachować miejsca replikacji logicznej i zapewnić spójność danych po przejściu w tryb failover, zaleca się użycie rozszerzenia PG Failover Slots. Aby uzyskać więcej informacji na temat włączania tego rozszerzenia, zapoznaj się z dokumentacją.
Konfigurowanie stref dostępności między prywatną siecią wirtualną i dostępem publicznym z prywatnymi punktami końcowymi nie jest obsługiwane. Należy skonfigurować strefy dostępności w sieci wirtualnej (obejmujące wiele stref dostępności w regionie) lub dostęp publiczny z prywatnymi punktami końcowymi.
Strefy dostępności są konfigurowane tylko w jednym regionie. Stref dostępności nie można skonfigurować w różnych regionach.
SLA
Model strefowy oferuje umowę SLA czasu pracy w wysokości 99,95%.
Model nadmiarowości strefy oferuje umowę SLA czasu pracy na 99,99%.
Tworzenie usługi Azure Database for PostgreSQL — serwer elastyczny z włączoną strefą dostępności
Aby dowiedzieć się, jak utworzyć usługę Azure Database for PostgreSQL — serwer elastyczny w celu zapewnienia wysokiej dostępności ze strefami dostępności, zobacz Szybki start: tworzenie usługi Azure Database for PostgreSQL — serwer elastyczny w witrynie Azure Portal.
Ponowne wdrażanie strefy dostępności i migracja
Aby dowiedzieć się, jak włączyć lub wyłączyć konfigurację wysokiej dostępności na serwerze elastycznym w modelach wdrażania strefowo nadmiarowego i strefowego, zobacz Zarządzanie wysoką dostępnością na serwerze elastycznym.
Składniki wysokiej dostępności i przepływ pracy
Uzupełnianie transakcji
Operacje zapisu i zatwierdzenia wyzwalane przez transakcje aplikacji są najpierw rejestrowane w pliku WAL na serwerze podstawowym. Są one następnie przesyłane strumieniowo do serwera rezerwowego przy użyciu protokołu przesyłania strumieniowego Postgres. Gdy dzienniki zostaną utrwalone w magazynie serwera rezerwowego, serwer podstawowy zostanie potwierdzony do ukończenia zapisu. Tylko wtedy aplikacja jest potwierdzana zatwierdzenie jej transakcji. Ta dodatkowa runda zwiększa opóźnienie aplikacji. Procent wpływu zależy od aplikacji. Ten proces potwierdzenia nie czeka na zastosowanie dzienników do serwera rezerwowego. Serwer rezerwowy jest trwale w trybie odzyskiwania, dopóki nie zostanie podwyższony poziom.
Sprawdzanie kondycji
Elastyczne monitorowanie kondycji serwera okresowo sprawdza kondycję podstawową i rezerwową. Po wielu poleceniach ping, jeśli monitorowanie kondycji wykryje, że serwer podstawowy nie jest osiągalny, usługa następnie inicjuje automatyczne przejście w tryb failover na serwer rezerwowy. Algorytm monitorowania kondycji jest oparty na wielu punktach danych, aby uniknąć fałszywie dodatnich sytuacji.
Tryby trybu failover
Serwer elastyczny obsługuje dwa tryby trybu failover, planowany tryb failover i nieplanowany tryb failover. W obu trybach po zerwaniu replikacji serwer rezerwowy uruchamia odzyskiwanie przed podwyższeniem poziomu jako podstawowy i zostanie otwarty dla odczytu/zapisu. Dzięki automatycznym wpisom DNS zaktualizowanym przy użyciu nowego podstawowego punktu końcowego serwera aplikacje mogą łączyć się z serwerem przy użyciu tego samego punktu końcowego. Nowy serwer rezerwowy jest ustanawiany w tle, aby aplikacja mogła zachować łączność.
Stan wysokiej dostępności
Kondycja serwerów podstawowych i rezerwowych jest stale monitorowana, a odpowiednie działania są podejmowane w celu rozwiązania problemów, w tym wyzwolenia trybu failover na serwerze rezerwowym. W poniższej tabeli wymieniono możliwe stany wysokiej dostępności:
| Stan | Opis |
|---|---|
| Inicjowanie | W procesie tworzenia nowego serwera rezerwowego. |
| Replikowanie danych | Po utworzeniu rezerwowego nadrobienie zaległości w podstawowej lekcji. |
| Zdrowy | Replikacja jest w stanie stałym i w dobrej kondycji. |
| Przełączanie w tryb failover | Serwer bazy danych jest w trakcie przechodzenia w tryb failover do trybu wstrzymania. |
| Usuwanie wstrzymania | W procesie usuwania serwera rezerwowego. |
| Nie włączono | Wysoka dostępność nie jest włączona. |
Uwaga
Wysoką dostępność można włączyć podczas tworzenia serwera lub w późniejszym czasie. Jeśli włączasz lub wyłączasz wysoką dostępność podczas etapu po utworzeniu, zaleca się działanie, gdy podstawowa aktywność serwera jest niska.
Operacje w stanie stabilnym
Aplikacje klienckie PostgreSQL są połączone z serwerem podstawowym przy użyciu nazwy serwera BAZY danych. Odczyty aplikacji są obsługiwane bezpośrednio z serwera podstawowego. Jednocześnie zatwierdzenia i zapisy są potwierdzane w aplikacji dopiero po utrwałości danych dziennika zarówno na serwerze podstawowym, jak i w repliki rezerwowej. Ze względu na tę dodatkową rundę aplikacje mogą oczekiwać podwyższonego opóźnienia dla zapisów i zatwierdzeń. Kondycję wysokiej dostępności można monitorować w portalu.
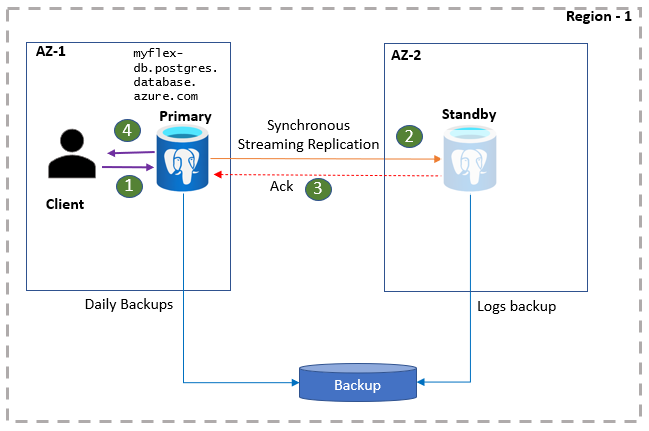
- Klienci łączą się z serwerem elastycznym i wykonują operacje zapisu.
- Zmiany są replikowane do lokacji rezerwowej.
- Element podstawowy otrzymuje potwierdzenie.
- Zapisy/zatwierdzenia są potwierdzane.
Przywracanie do punktu w czasie serwerów o wysokiej dostępności
W przypadku serwerów elastycznych skonfigurowanych z wysoką dostępnością dane dziennika są replikowane w czasie rzeczywistym do serwera rezerwowego. Wszelkie błędy użytkownika na serwerze podstawowym — takie jak przypadkowe usunięcie tabeli lub niepoprawne aktualizacje danych, są replikowane do repliki rezerwowej. W związku z tym nie można użyć trybu wstrzymania w celu odzyskania sprawności po takich błędach logicznych. Aby odzyskać dane po takich błędach, należy wykonać przywracanie do punktu w czasie z kopii zapasowej. Korzystając z funkcji przywracania do punktu w czasie serwera elastycznego, można przywrócić czas przed wystąpieniem błędu. Nowy serwer bazy danych jest przywracany jako serwer elastyczny z jedną strefą z nową nazwą serwera udostępnianego przez użytkownika dla baz danych skonfigurowanych z wysoką dostępnością. Możesz użyć przywróconego serwera w kilku przypadkach użycia:
Przywrócony serwer można użyć do produkcji i opcjonalnie włączyć wysoką dostępność z repliką rezerwową w tej samej strefie lub innej strefie w tym samym regionie.
Jeśli chcesz przywrócić obiekt, wyeksportuj go z przywróconego serwera bazy danych i zaimportuj go do produkcyjnego serwera bazy danych.
Jeśli chcesz sklonować serwer bazy danych na potrzeby testowania i programowania lub przywrócić do innych celów, możesz wykonać przywracanie do punktu w czasie.
Aby dowiedzieć się, jak przeprowadzić przywracanie do punktu w czasie serwera elastycznego, zobacz Przywracanie do punktu w czasie serwera elastycznego.
Obsługa trybu failover
Planowane przejście w tryb failover
Zdarzenia planowanych przestojów obejmują zaplanowane okresowe aktualizacje oprogramowania platformy Azure i uaktualnienia wersji pomocniczej. Możesz również użyć planowanego trybu failover, aby przywrócić serwer podstawowy do preferowanej strefy dostępności. Po skonfigurowaniu wysokiej dostępności te operacje są najpierw stosowane do repliki rezerwowej, podczas gdy aplikacje nadal uzyskują dostęp do serwera podstawowego. Po zaktualizowaniu repliki rezerwowej połączenia serwera podstawowego są opróżniane, a tryb failover zostanie wyzwolony, co aktywuje replikę rezerwową jako podstawową o tej samej nazwie serwera bazy danych. Aplikacje klienckie muszą ponownie łączyć się z tą samą nazwą serwera bazy danych na nowym serwerze podstawowym i mogą wznowić operacje. Nowy serwer rezerwowy jest ustanawiany w tej samej strefie co stary serwer podstawowy.
W przypadku innych operacji inicjowanych przez użytkownika, takich jak skalowanie zasobów obliczeniowych lub skalowanie magazynu, zmiany są najpierw stosowane w rezerwie, a następnie podstawowe. Obecnie usługa nie jest przełączana na pracę awaryjną w trybie rezerwowym, dlatego podczas wykonywania operacji skalowania na serwerze podstawowym występuje krótki przestój w dostępności aplikacji.
Za pomocą tej funkcji można również przejść w tryb failover na serwer rezerwowy z ograniczonym przestojem. Na przykład podstawowa może znajdować się w innej strefie dostępności niż aplikacja po nieplanowanym przejściu w tryb failover. Chcesz przywrócić serwer podstawowy do poprzedniej strefy, aby przenieść lokalizację z aplikacją.
Podczas wykonywania tej funkcji serwer rezerwowy jest najpierw przygotowany, aby upewnić się, że jest dogoniony ostatnich transakcji, dzięki czemu aplikacja może kontynuować wykonywanie operacji odczytu/zapisu. Wstrzymanie jest następnie promowane, a połączenia z podstawowymi są przerywane. Aplikacja może nadal zapisywać dane na serwerze podstawowym, gdy w tle jest ustanawiany nowy serwer rezerwowy. Poniżej przedstawiono kroki związane z zaplanowanym przejściem w tryb failover:
| Step | Opis | Oczekiwano przestoju aplikacji? |
|---|---|---|
| 1 | Poczekaj, aż serwer rezerwowy dogonił serwer podstawowy. | Nie. |
| 2 | Wewnętrzny system monitorowania inicjuje przepływ pracy trybu failover. | Nie. |
| 3 | Zapisy aplikacji są blokowane, gdy serwer rezerwowy znajduje się w pobliżu podstawowego numeru sekwencji dziennika (LSN). | Tak |
| 100 | Serwer rezerwowy jest promowany jako niezależny serwer. | Tak |
| 5 | Rekord DNS jest aktualizowany przy użyciu nowego adresu IP serwera rezerwowego. | Tak |
| 6 | Aplikacja do ponownego nawiązywania połączenia i wznawiania jego odczytu/zapisu przy użyciu nowego podstawowego elementu. | Nie. |
| 7 | Zostanie ustanowiony nowy serwer rezerwowy w innej strefie. | Nie. |
| 8 | Serwer rezerwowy zaczyna odzyskiwać dzienniki (z usługi Azure Blob), których brakowało podczas jego tworzenia. | Nie. |
| 9 | Jest ustanawiany stały stan między serwerem podstawowym a serwerem rezerwowym. | Nie. |
| 10 | Planowany proces trybu failover został ukończony. | Nie. |
Przestój aplikacji rozpoczyna się w kroku 3 i może wznowić operację po kroku 5. Pozostałe kroki są wykonywane w tle bez wpływu na operacje zapisu i zatwierdzeń aplikacji.
Napiwek
Dzięki serwerowi elastycznemu możesz opcjonalnie zaplanować działania konserwacyjne inicjowane przez platformę Azure, wybierając 60-minutowe okno w dniu preferencji, w którym działania w bazach danych powinny być niskie. Zadania konserwacji platformy Azure, takie jak stosowanie poprawek lub uaktualnienia wersji pomocniczej, miały miejsce w tym oknie. Jeśli nie wybierzesz okna niestandardowego, dla serwera zostanie wybrane okno przydzielone 1-godzinne od 11:00 do 7:00 czasu lokalnego. Te działania konserwacji inicjowane przez platformę Azure są również wykonywane w repliki rezerwowej dla serwerów elastycznych skonfigurowanych ze strefami dostępności.
Aby uzyskać listę możliwych zdarzeń planowanych przestojów, zobacz Planowane zdarzenia przestoju.
Nieplanowany tryb failover
Nieplanowane przestoje mogą wystąpić w wyniku nieprzewidzianych zakłóceń, takich jak błędy sprzętowe, problemy z siecią i błędy oprogramowania. Jeśli serwer bazy danych skonfigurowany z wysoką dostępnością niespodziewanie ulegnie awarii, replika rezerwowa zostanie aktywowana, a klienci mogą wznowić operacje. Jeśli nie skonfigurowano wysokiej dostępności, to jeśli próba ponownego uruchomienia zakończy się niepowodzeniem, nowy serwer bazy danych zostanie automatycznie aprowizowany. Chociaż nie można uniknąć nieplanowanego przestoju, serwer elastyczny pomaga zmniejszyć przestój, automatycznie wykonując operacje odzyskiwania bez konieczności interwencji człowieka.
Aby uzyskać informacje na temat nieplanowanych trybów failover i przestojów, w tym możliwych scenariuszy, zobacz Nieplanowane środki zaradcze dotyczące przestojów.
Testy trybu failover (wymuszone przejście w tryb failover)
W przypadku wymuszonego przejścia w tryb failover można symulować nieplanowany scenariusz awarii podczas uruchamiania obciążenia produkcyjnego i obserwować przestoje aplikacji. Możesz również użyć wymuszonego trybu failover, gdy serwer podstawowy przestanie odpowiadać.
Wymuszone przejście w tryb failover powoduje wyłączenie serwera podstawowego i inicjuje przepływ pracy trybu failover, w którym jest wykonywana operacja podwyższania poziomu wstrzymania. Po zakończeniu procesu odzyskiwania do momentu ostatniego zatwierdzonego danych zostanie on podwyższony do poziomu serwera podstawowego. Rekordy DNS są aktualizowane, a aplikacja może nawiązać połączenie z promowanym serwerem podstawowym. Aplikacja może nadal zapisywać dane na serwerze podstawowym, gdy nowy serwer rezerwowy jest ustanowiony w tle, co nie ma wpływu na czas pracy.
Poniżej przedstawiono kroki podczas wymuszonego przejścia w tryb failover:
| Step | Opis | Oczekiwano przestoju aplikacji? |
|---|---|---|
| 1 | Serwer podstawowy jest zatrzymany wkrótce po otrzymaniu żądania trybu failover. | Tak |
| 2 | Aplikacja napotyka przestój, ponieważ serwer podstawowy nie działa. | Tak |
| 3 | Wewnętrzny system monitorowania wykrywa awarię i inicjuje przejście w tryb failover na serwer rezerwowy. | Tak |
| 100 | Serwer rezerwowy przechodzi w tryb odzyskiwania przed pełnym podwyższeniem poziomu jako niezależny serwer. | Tak |
| 5 | Proces trybu failover czeka na zakończenie odzyskiwania rezerwowego. | Tak |
| 6 | Po uruchomieniu serwera rekord DNS jest aktualizowany przy użyciu tej samej nazwy hosta, ale przy użyciu adresu IP rezerwowego. | Tak |
| 7 | Aplikacja może ponownie nawiązać połączenie z nowym serwerem podstawowym i wznowić operację. | Nie. |
| 8 | Jest ustanawiany serwer rezerwowy w preferowanej strefie. | Nie. |
| 9 | Serwer rezerwowy zaczyna odzyskiwać dzienniki (z usługi Azure Blob), których brakowało podczas jego tworzenia. | Nie. |
| 10 | Jest ustanawiany stały stan między serwerem podstawowym a serwerem rezerwowym. | Nie. |
| 11 | Proces wymuszonego przejścia w tryb failover został ukończony. | Nie. |
Oczekuje się, że przestój aplikacji rozpocznie się po kroku 1 i będzie się powtarzać do momentu ukończenia kroku 6. Pozostałe kroki są wykonywane w tle bez wpływu na operacje zapisu i zatwierdzeń aplikacji.
Ważne
Proces kompleksowego trybu failover obejmuje (a) przełączanie w tryb failover na serwer rezerwowy po awarii podstawowej i (b) ustanowienie nowego serwera rezerwowego w stanie stabilnym. Ponieważ aplikacja powoduje przestój do czasu zakończenia trybu failover w trybie failover, zmierz przestój z perspektywy aplikacji/klienta zamiast ogólnego kompleksowego procesu przełączania w tryb failover.
Zagadnienia dotyczące przeprowadzania wymuszonego przejścia w tryb failover
Ogólny czas kompleksowej operacji może być postrzegany jako dłuższy niż rzeczywisty przestój spowodowany przez aplikację.
Ważne
Zawsze obserwuj przestój z perspektywy aplikacji!
Nie wykonuj natychmiastowych operacji powrotu do trybu failover. Poczekaj co najmniej 15–20 minut między trybami failover, umożliwiając pełne ustanowienie nowego serwera rezerwowego.
Zaleca się przeprowadzenie wymuszonego przejścia w tryb failover w okresie niskiej aktywności w celu zmniejszenia przestoju.
Najlepsze rozwiązania dotyczące statystyk postgreSQL po przejściu w tryb failover
Po przejściu w tryb failover bazy danych PostgreSQL podstawowy mechanizm utrzymania optymalnej wydajności bazy danych obejmuje zrozumienie odrębnych ról pg_statistic i tabel pg_stat_* . Tabela pg_statistic zawiera statystyki optymalizatora, które mają kluczowe znaczenie dla planisty zapytań. Te statystyki obejmują dystrybucje danych w tabelach i pozostają nienaruszone po przejściu w tryb failover, zapewniając, że planista zapytań może nadal efektywnie optymalizować wykonywanie zapytań na podstawie dokładnych, historycznych informacji o dystrybucji danych.
pg_stat_* Natomiast tabele, które rejestrują statystyki aktywności, takie jak liczba skanowań, krotki odczytane i aktualizacje, są resetowane po przejściu w tryb failover. Przykładem takiej tabeli jest pg_stat_user_tables, która śledzi aktywność tabel zdefiniowanych przez użytkownika. To resetowanie jest przeznaczone do dokładnego odzwierciedlenia stanu operacyjnego nowego podstawowego, ale także oznacza utratę historycznych metryk aktywności, które mogą informować o procesie automatycznego czyszczenia i innych wydajności operacyjnych.
Biorąc pod uwagę to rozróżnienie, najlepszym rozwiązaniem po przejściu w tryb failover bazy danych PostgreSQL jest uruchomienie polecenia ANALYZE. Ta akcja aktualizuje pg_stat_* tabele, takie jak pg_stat_user_tables, ze świeżymi statystykami aktywności, pomagając procesowi automatycznego czyszczenia i zapewniając, że wydajność bazy danych pozostaje optymalna w nowej roli. Ten proaktywny krok łączy lukę między zachowaniem podstawowych statystyk optymalizatora i odświeżaniem metryk aktywności w celu dostosowania ich do bieżącego stanu bazy danych.
Środowisko strefowe
Strefowe: aby odzyskać sprawność po awarii na poziomie strefy, możesz wykonać przywracanie do punktu w czasie przy użyciu kopii zapasowej. Możesz wybrać niestandardowy punkt przywracania z najnowszym czasem, aby przywrócić najnowsze dane. Nowy serwer elastyczny jest wdrażany w innej strefie, której nie dotyczy problem. Czas potrzebny na przywrócenie zależy od poprzedniej kopii zapasowej i ilości dzienników transakcji do odzyskania.
Aby uzyskać więcej informacji na temat przywracania do punktu w czasie, zobacz Tworzenie kopii zapasowej i przywracanie w usłudze Azure Database for PostgreSQL-Flexible Server.
Strefowo nadmiarowy: serwer elastyczny jest automatycznie przełączony w tryb failover na serwer rezerwowy w ciągu 60–120 sekund z zerową utratą danych.
Konfiguracje bez stref dostępności
Mimo że nie jest to zalecane, można skonfigurować serwer elastyczny bez włączonej wysokiej dostępności. W przypadku serwerów elastycznych skonfigurowanych bez wysokiej dostępności usługa zapewnia magazyn lokalnie nadmiarowy z trzema kopiami danych, strefowo nadmiarową kopią zapasową (w regionach, w których jest obsługiwana) i wbudowaną odporność serwera, aby automatycznie ponownie uruchomić serwer, który uległ awarii i przenieść serwer do innego węzła fizycznego. Umowa SLA czasu pracy w wysokości 99,9% jest oferowana w tej konfiguracji. Jeśli serwer ulegnie awarii podczas planowanych lub nieplanowanych zdarzeń trybu failover, usługa utrzymuje dostępność serwerów przy użyciu następującej procedury zautomatyzowanej:
- Aprowizowana jest nowa maszyna wirtualna obliczeniowa z systemem Linux.
- Magazyn z plikami danych jest mapowany na nową maszynę wirtualną.
- Aparat bazy danych PostgreSQL jest w trybie online na nowej maszynie wirtualnej.
Na poniższej ilustracji przedstawiono przejście między maszyną wirtualną a awarią magazynu.

Odzyskiwanie po awarii między regionami i ciągłość działania
W przypadku awarii obejmującej cały region platforma Azure może zapewnić ochronę przed awariami regionalnymi lub dużymi lokalizacjami geograficznymi z odzyskiwaniem po awarii, korzystając z innego regionu. Aby uzyskać więcej informacji na temat architektury odzyskiwania po awarii platformy Azure, zobacz Architektura odzyskiwania po awarii z platformy Azure do platformy Azure.
Serwer elastyczny udostępnia funkcje, które chronią dane i zmniejszają przestoje baz danych o znaczeniu krytycznym podczas planowanych i nieplanowanych zdarzeń przestojów. Oparta na infrastrukturze platformy Azure, która oferuje niezawodną odporność i dostępność, serwer elastyczny oferuje funkcje ciągłości działania, które zapewniają ochronę przed błędami, spełniają wymagania dotyczące czasu odzyskiwania i zmniejszają narażenie na utratę danych. Podczas tworzenia architektury aplikacji należy wziąć pod uwagę tolerancję przestojów — cel czasu odzyskiwania (RTO) i narażenie na utratę danych — cel punktu odzyskiwania (RPO). Na przykład baza danych o krytycznym znaczeniu dla działania firmy wymaga bardziej rygorystycznego czasu pracy niż testowa baza danych.
Odzyskiwanie po awarii w lokalizacji geograficznej obejmującej wiele regionów
Geograficznie nadmiarowa kopia zapasowa i przywracanie
Geograficznie nadmiarowe tworzenie kopii zapasowych i przywracanie zapewnia możliwość przywrócenia serwera w innym regionie w przypadku awarii. Zapewnia również co najmniej 99,999999999999999999 procent (16 dziewiątek) trwałość obiektów kopii zapasowych w ciągu roku.
Geograficznie nadmiarowa kopia zapasowa można skonfigurować tylko w momencie tworzenia serwera. Po skonfigurowaniu serwera z geograficznie nadmiarową kopią zapasową dane kopii zapasowej i dzienniki transakcji są kopiowane do sparowanego regionu asynchronicznie przez replikację magazynu.
Aby uzyskać więcej informacji na temat geograficznie nadmiarowej kopii zapasowej i przywracania, zobacz geograficznie nadmiarowe kopie zapasowe i przywracanie.
Repliki do odczytu
Repliki odczytu między regionami można wdrożyć w celu ochrony baz danych przed awariami na poziomie regionu. Repliki do odczytu są aktualizowane asynchronicznie przy użyciu technologii replikacji fizycznej bazy danych PostgreSQL i mogą opóźniać technologię replikacji podstawowej. Repliki do odczytu są obsługiwane w warstwach obliczeniowych ogólnego przeznaczenia i zoptymalizowanych pod kątem pamięci.
Aby uzyskać więcej informacji na temat funkcji i zagadnień dotyczących replik do odczytu, zobacz Read replicas (Repliki do odczytu).
Wykrywanie, powiadamianie i zarządzanie awariami
Jeśli serwer jest skonfigurowany z geograficznie nadmiarową kopią zapasową, możesz wykonać przywracanie geograficzne w sparowanym regionie. Nowy serwer jest aprowizowany i przywracany do ostatnich dostępnych danych skopiowanych do tego regionu.
Można również użyć replik do odczytu między regionami. W przypadku awarii regionu można wykonać operację odzyskiwania po awarii, promując replikę do odczytu jako autonomiczny serwer do odczytu i zapisu. Oczekuje się, że cel punktu odzyskiwania będzie do 5 minut (możliwa utrata danych), z wyjątkiem przypadków poważnej awarii regionalnej, gdy cel punktu odzyskiwania może być bliski opóźnienia replikacji w momencie awarii.
Aby uzyskać więcej informacji na temat nieplanowanego ograniczania przestojów i odzyskiwania po regionalnej awarii, zobacz Nieplanowane środki zaradcze dotyczące przestojów.