Rozszerzenia programu PostgreSQL w usłudze Azure Database for PostgreSQL — serwer elastyczny
DOTYCZY:  Azure Database for PostgreSQL — serwer elastyczny
Azure Database for PostgreSQL — serwer elastyczny
Elastyczny serwer usługi Azure Database for PostgreSQL umożliwia rozszerzanie funkcjonalności bazy danych przy użyciu rozszerzeń. Rozszerzenia łączą wiele powiązanych obiektów SQL w jednym pakiecie, który można załadować lub usunąć z bazy danych za pomocą polecenia . Po załadowaniu do bazy danych rozszerzenia działają jak wbudowane funkcje.
Jak używać rozszerzeń PostgreSQL
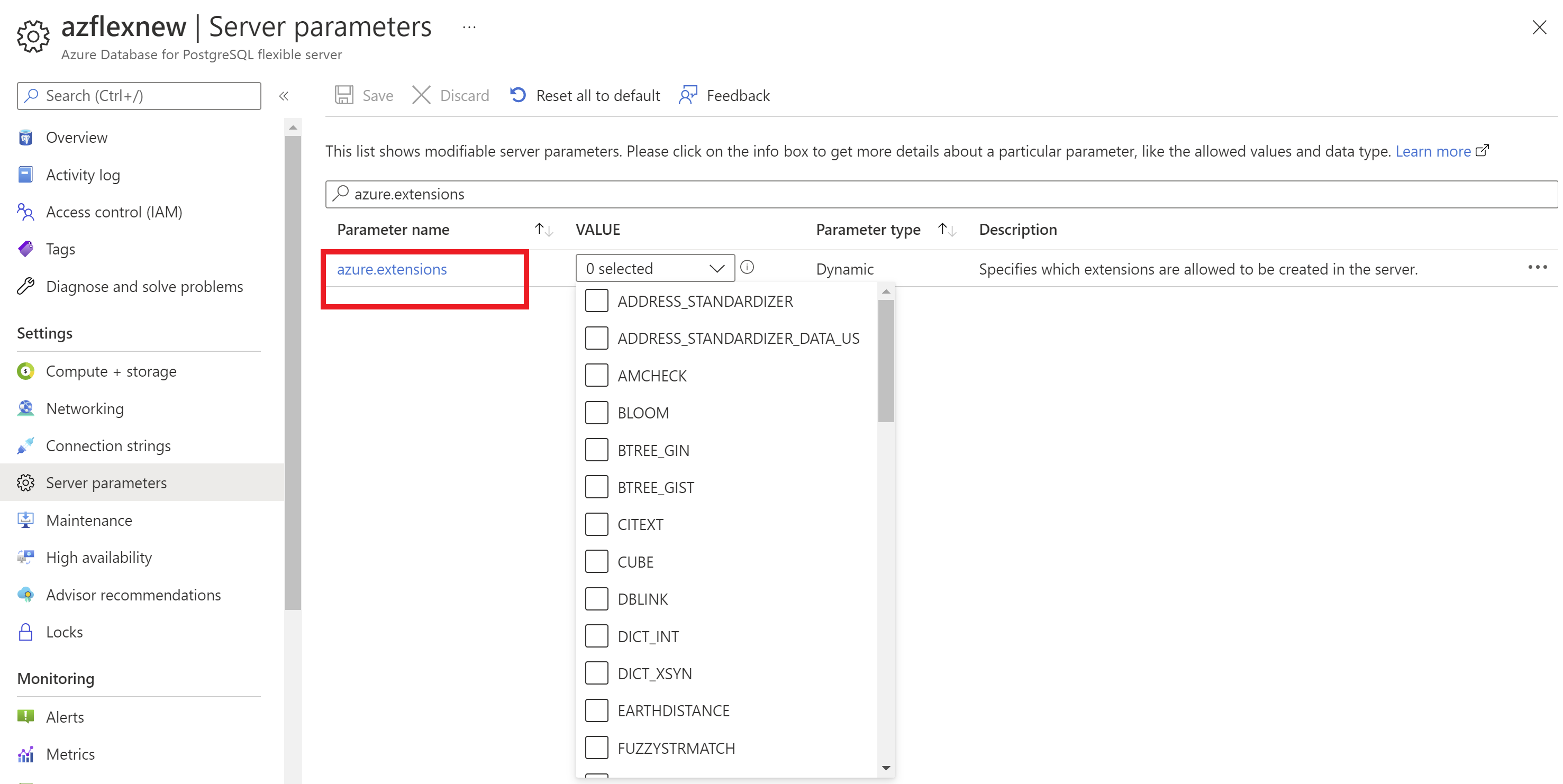
Przed zainstalowaniem rozszerzeń na serwerze elastycznym usługi Azure Database for PostgreSQL należy zezwolić na listę tych rozszerzeń do użycia.
Korzystanie z witryny Azure Portal:
- Wybierz wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL.
- W menu zasobów w sekcji Ustawienia wybierz pozycję Parametry serwera.
azure.extensionsWyszukaj parametr .- Wybierz rozszerzenia, które chcesz zezwolić na listę.

Korzystanie z interfejsu wiersza polecenia platformy Azure:
Rozszerzenia listy dozwolonych można uzyskać za pomocą polecenia zestawu parametrów interfejsu wiersza polecenia.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
Przy użyciu szablonu usługi ARM: następujące przykładowe rozszerzenia allowlists dblink, dict_xsynpg_buffercache na serwerze, którego nazwa to postgres-test-server:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries to parametr konfiguracji serwera, który określa, które biblioteki należy załadować po uruchomieniu serwera elastycznego usługi Azure Database for PostgreSQL. Wszystkie biblioteki korzystające z pamięci udostępnionej muszą zostać załadowane za pomocą tego parametru. Jeśli rozszerzenie musi zostać dodane do udostępnionych bibliotek wstępnego ładowania, wykonaj następujące kroki:
Korzystanie z witryny Azure Portal:
- Wybierz wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL.
- W menu zasobów w sekcji Ustawienia wybierz pozycję Parametry serwera.
shared_preload_librariesWyszukaj parametr .- Wybierz biblioteki, które chcesz dodać.
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Tworzenie rozszerzenia
Po zainstalowaniu i załadowaniu rozszerzeń należy je zainstalować w każdej bazie danych, na której planujesz ich używać.
- Aby utworzyć rozszerzenie, użytkownik musi być członkiem
azure_pg_adminroli.azure_pg_adminCzłonek roli może przyznać innym użytkownikom uprawnienia do tworzenia rozszerzeń. - Aby zainstalować określone rozszerzenie, należy uruchomić polecenie CREATE EXTENSION . To polecenie ładuje spakowane obiekty do bazy danych.
Uwaga
Rozszerzenia innych firm oferowane na serwerze elastycznym usługi Azure Database for PostgreSQL to kod licencjonowany na oprogramowanie open source. Obecnie nie oferujemy żadnych rozszerzeń ani wersji rozszerzeń innych firm z modelami licencjonowania w warstwie Premium ani zastrzeżonymi.
Wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL obsługuje podzestaw rozszerzeń kluczy PostgreSQL, jak pokazano w poniższej tabeli. Te informacje są również dostępne, uruchamiając polecenie SHOW azure.extensions;. Rozszerzenia, które nie są wymienione w tym dokumencie, nie są obsługiwane na serwerze elastycznym usługi Azure Database for PostgreSQL. Nie można utworzyć ani załadować własnego rozszerzenia na serwerze elastycznym usługi Azure Database for PostgreSQL.
Wersje rozszerzeń
Następujące rozszerzenia są dostępne na serwerze elastycznym usługi Azure Database for PostgreSQL:
Uwaga
Rozszerzenia w poniższej tabeli z oznaczeniem ✔️ wymagają włączenia odpowiednich bibliotek w parametrze shared_preload_libraries serwera.
| Nazwa rozszerzenia | Opis | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | Służy do analizowania adresu do elementów składowych. Zwykle służy do obsługi kroku normalizacji adresów geokodowania. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Przykład zestawu danych Address Standardizer US | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| wiek (wersja zapoznawcza) | Udostępnia możliwości grafowej bazy danych | Nie dotyczy | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | Brak | Brak |
| amcheck | Funkcje do weryfikowania integralności relacji | 1.4 | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| anon (wersja zapoznawcza) | Narzędzia do anonimizacji danych | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | Integracja usług Azure AI i ML dla bazy danych PostgreSQL | Nie dotyczy | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | Nie dotyczy |
| azure_storage | Integracja platformy Azure dla bazy danych PostgreSQL | Nie dotyczy | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | Nie dotyczy |
| kwitnąć | Metoda dostępu Bloom — indeks oparty na pliku podpisu | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Obsługa indeksowania typowych typów danych w gin | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Obsługa indeksowania typowych typów danych w giST | 1,7 | 1,7 | 1,7 | 1.6 | 1.5 | 1.5 | 1.5 |
| tekst citext | Typ danych dla ciągów znaków bez uwzględniania wielkości liter | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| sześcian | Typ danych dla modułów wielowymiarowych | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Nawiązywanie połączenia z innymi bazami danych PostgreSQL z poziomu bazy danych | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Szablon słownika wyszukiwania tekstu dla liczb całkowitych | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Szablon słownika wyszukiwania tekstu na potrzeby rozszerzonego przetwarzania synonimów | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Obliczanie odległości wielkich okręgów na powierzchni Ziemi | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| rozmycie rozmyte | Określanie podobieństw i odległości między ciągami | 1.2 | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| hstore | Typ danych do przechowywania zestawów par (klucz, wartość) | 1.8 | 1.8 | 1.8 | 1.8 | 1,7 | 1.6 | 1.5 |
| niedopgania | Hipotetyczne indeksy dla bazy danych PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Agregator liczb całkowitych i moduł wyliczający (przestarzałe) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | Funkcje, operatory i obsługa indeksów dla tablic 1-W liczb całkowitych | 1.5 | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| Isn | Typy danych dla międzynarodowych standardów numerowania produktów | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| Lo | Konserwacja dużych obiektów | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| login_hook | Login_hook — punkt zaczepienia w celu wykonania login_hook.login() w czasie logowania | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Typ danych dla struktur przypominających drzewa hierarchicznego | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1.1 |
| oracle_fdw | Obca otoka danych dla baz danych Oracle | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | Nie dotyczy |
| orafce | Funkcje i operatory emulujące podzestaw funkcji i pakietów z programu Oracle RDBMS | 4.9 | 4.4 | 3.24 | 3,18 | 3,18 | 3,18 | 3.7 |
| pageinspect | Sprawdzanie zawartości stron bazy danych na niskim poziomie | 1.12 | 1.12 | 1.11 | 1,9 | 1.8 | 1,7 | 1,7 |
| pgaudit | Udostępnia funkcje inspekcji | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Badanie udostępnionej pamięci podręcznej buforu | 1.5 | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Harmonogram zadań dla bazy danych PostgreSQL | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Funkcje kryptograficzne | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_freespacemap | Sprawdzanie mapy wolnego miejsca (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Umożliwia dostosowanie planów wykonywania bazy danych PostgreSQL przy użyciu tak zwanych wskazówek w komentarzach SQL. | 1.7.0 ✔️ | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Replikacja logiczna bazy danych PostgreSQL | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Rozszerzenie do zarządzania tabelami partycjonowanych według czasu lub identyfikatora | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Wstępne dane relacyjne | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Reorganizuj tabele w bazach danych PostgreSQL z minimalnymi blokadami | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | Rozszerzenie PgRouting | Brak | Brak | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Pokaż informacje o blokowaniu na poziomie wiersza | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | Narzędzie do usuwania nieużywanego miejsca z relacji. | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Śledzenie statystyk wykonywania wszystkich wykonanych instrukcji SQL | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Pokaż statystyki na poziomie krotki | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Pomiar podobieństwa tekstu i wyszukiwanie indeksów na podstawie trigramów | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Zapoznaj się z mapą widoczności (VM) i informacjami o widoczności na poziomie strony | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | Język proceduralny PL/pgSQL | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | Zaufany język proceduralny PL/JavaScript (wersja 8) | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| pogis | Geometria i geografia pogis — typy przestrzenne i funkcje | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | Typy i funkcje rastrowe PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | Funkcje PostGIS SFCGAL | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | Geokoder tygrysa PostGIS i odwrotny geokoder | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | Funkcje i typy przestrzenne topologii postGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Otoka danych obcych dla zdalnych serwerów PostgreSQL | 1.1 | 1.1 | 1.1 | 1.1 | 1.0 | 1.0 | 1.0 |
| postgres_protobuf | protokołu dla bazy danych PostgreSQL | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | Nie dotyczy |
| semver | Semantyczny typ danych wersji | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable — rejestracja i manipulowanie zmiennymi sesji i stałymi | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Informacje o certyfikatach SSL | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Funkcje, które manipulują całymi tabelami, w tym krzyżowe | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Obca otoka danych do wykonywania zapytań dotyczących bazy danych TDS (Sybase lub Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Umożliwia skalowalne wstawianie i złożone zapytania dotyczące danych szeregów czasowych | Nie dotyczy | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | TABLESAMPLE, metoda, która akceptuje liczbę wierszy jako limit | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | TABLESAMPLE, metoda, która akceptuje czas w milisekundach jako limit | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | Słownik wyszukiwania tekstu, który usuwa akcenty | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| uuid-ossp | Generowanie unikatowych identyfikatorów (UUID) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| wektor | Typ danych wektorów i metody dostępu ivfflat i hnsw | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Uaktualnianie rozszerzeń bazy danych PostgreSQL
Uaktualnienia w miejscu rozszerzeń bazy danych są dozwolone za pomocą prostego polecenia. Ta funkcja umożliwia klientom automatyczne aktualizowanie rozszerzeń innych firm do najnowszych wersji, utrzymywanie bieżących i bezpiecznych systemów bez ręcznego nakładu pracy.
Aktualizowanie rozszerzeń
Aby zaktualizować zainstalowane rozszerzenie do najnowszej dostępnej wersji obsługiwanej przez platformę Azure, użyj następującego polecenia SQL:
ALTER EXTENSION <extension_name> UPDATE;
To polecenie upraszcza zarządzanie rozszerzeniami bazy danych, umożliwiając użytkownikom ręczne uaktualnienie do najnowszej wersji zatwierdzonej przez platformę Azure, zwiększając zgodność i zabezpieczenia.
Ograniczenia
Chociaż aktualizowanie rozszerzeń jest proste, istnieją pewne ograniczenia:
- Wybór określonej wersji: polecenie nie obsługuje aktualizacji do wersji pośrednich rozszerzenia. Zawsze jest aktualizowana do najnowszej dostępnej wersji.
- Obniżanie poziomu: nie obsługuje obniżania poziomu rozszerzenia do poprzedniej wersji. Jeśli konieczna jest obniżenie poziomu, może to wymagać pomocy technicznej i zależy od dostępności poprzedniej wersji.
Zainstalowane rozszerzenia
Aby wyświetlić listę rozszerzeń aktualnie zainstalowanych w bazie danych, użyj następującego polecenia SQL:
SELECT * FROM pg_extension;
Dostępne rozszerzenia i ich wersje
Aby sprawdzić, które wersje rozszerzenia są dostępne dla bieżącej instalacji bazy danych, wykonaj zapytanie dotyczące pg_available_extensions widoku wykazu systemu. Aby na przykład określić wersję dostępną azure_aidla rozszerzenia, wykonaj następujące polecenie:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Te polecenia zapewniają niezbędny wgląd w konfiguracje rozszerzeń bazy danych, pomagając wydajnie i bezpiecznie obsługiwać systemy. Dzięki włączeniu łatwych aktualizacji do najnowszych wersji rozszerzeń usługa Azure Database for PostgreSQL nadal obsługuje niezawodne, bezpieczne i wydajne zarządzanie aplikacjami bazy danych.
Zagadnienia dotyczące serwera elastycznego usługi Azure Database for PostgreSQL
Poniżej znajduje się lista obsługiwanych rozszerzeń, które wymagają pewnych konkretnych zagadnień w przypadku użycia w usłudze serwera elastycznego usługi Azure Database for PostgreSQL. Lista jest sortowana alfabetycznie.
dblink
Usługa dblink umożliwia nawiązywanie połączenia z jednego wystąpienia serwera elastycznego usługi Azure Database for PostgreSQL z innym lub z inną bazą danych na tym samym serwerze. Serwer elastyczny usługi Azure Database for PostgreSQL obsługuje zarówno połączenia przychodzące, jak i wychodzące z dowolnym serwerem PostgreSQL. Serwer wysyłający musi zezwalać na połączenia wychodzące z serwerem odbierający. Podobnie serwer odbierający musi zezwalać na połączenia z serwera wysyłającego.
Zalecamy wdrożenie serwerów z integracją sieci wirtualnej, jeśli planujesz używać tego rozszerzenia. Domyślnie integracja sieci wirtualnej umożliwia nawiązywanie połączeń między serwerami w sieci wirtualnej. Możesz również użyć sieci wirtualnej sieciowych grup zabezpieczeń w celu dostosowania dostępu.
pg_buffercache
pg_buffercache umożliwia badanie zawartości shared_buffers. Korzystając z tego rozszerzenia , można określić, czy określona relacja jest buforowana, czy nie (w pliku shared_buffers). To rozszerzenie może pomóc w rozwiązywaniu problemów z wydajnością (problemy z wydajnością związane z buforowaniem).
To rozszerzenie jest zintegrowane z podstawową instalacją bazy danych PostgreSQL i jest łatwe do zainstalowania.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron jest prostym, opartym na cron harmonogramie zadań dla bazy danych PostgreSQL, który działa wewnątrz bazy danych jako rozszerzenie. Rozszerzenie pg_cron może służyć do uruchamiania zaplanowanych zadań konserwacji w bazie danych PostgreSQL. Można na przykład uruchomić okresowe opróżnienie tabeli lub usunąć stare zadania danych.
pg_cron program może uruchamiać wiele zadań równolegle, ale jednocześnie uruchamia co najwyżej jedno wystąpienie zadania. Jeśli drugi przebieg ma rozpoczynać się przed pierwszym zakończeniem, drugi przebieg jest kolejkowany i uruchamiany natychmiast po zakończeniu pierwszego przebiegu. W taki sposób zapewnia się, że zadania są uruchamiane dokładnie tyle razy, ile zaplanowano i nie są uruchamiane współbieżnie z samymi sobą.
Kilka przykładów:
Aby usunąć stare dane w sobotę o 3:30 (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Aby codziennie uruchamiać próżnię o godzinie 10:00 (GMT) w domyślnej bazie danych postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Aby cofnąć wszystkie zadania z programu pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Aby wyświetlić wszystkie zadania aktualnie zaplanowane za pomocą pg_cronpolecenia .
SELECT * FROM cron.job;
Aby codziennie uruchamiać próżnię o godzinie 10:00 (GMT) w bazie danych "testcron" na koncie roli azure_pg_admin.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Uwaga
rozszerzenie pg_cron jest wstępnie shared_preload_libraries ładowane dla każdego wystąpienia serwera elastycznego usługi Azure Database for PostgreSQL wewnątrz bazy danych postgres, aby zapewnić możliwość planowania zadań do uruchamiania w innych bazach danych w ramach wystąpienia elastycznej bazy danych serwera usługi Azure Database for PostgreSQL bez naruszania zabezpieczeń. Jednak ze względów bezpieczeństwa nadal trzeba zezwolić na rozszerzenie listy pg_cron i zainstalować je przy użyciu polecenia CREATE EXTENSION .
pg_cron Począwszy od wersji 1.4, możesz użyć cron.schedule_in_database funkcji icron.alter_job, aby zaplanować zadanie w określonej bazie danych i zaktualizować istniejący harmonogram odpowiednio.
Kilka przykładów:
Aby usunąć stare dane w sobotę o 3:30 (GMT) w bazie danych DBName.
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Uwaga
cron_schedule_in_database funkcja umożliwia określenie nazwy użytkownika jako parametru opcjonalnego. Ustawienie nazwy użytkownika na wartość inną niż null wymaga uprawnień administratora postgreSQL i nie jest obsługiwane na serwerze elastycznym usługi Azure Database for PostgreSQL. W poprzednich przykładach pokazano uruchamianie tej funkcji z opcjonalnym parametrem nazwy użytkownika pominiętym lub ustawionym na wartość null, która uruchamia zadanie w kontekście planowania zadania przez użytkownika, które powinno mieć azure_pg_admin uprawnienia roli.
Aby zaktualizować lub zmienić nazwę bazy danych dla istniejącego harmonogramu
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
Rozszerzenie PG Failover Slots rozszerza serwer elastyczny usługi Azure Database for PostgreSQL podczas pracy z replikacją logiczną i serwerami z włączoną wysoką dostępnością. Skutecznie rozwiązuje to wyzwanie w ramach standardowego aparatu PostgreSQL, który nie zachowuje miejsc replikacji logicznej po przejściu w tryb failover. Utrzymanie tych miejsc ma kluczowe znaczenie, aby zapobiec wstrzymaniu replikacji lub niezgodności danych podczas zmian roli serwera podstawowego, zapewniając ciągłość działania i integralność danych.
Rozszerzenie usprawnia proces pracy w trybie failover, zarządzając niezbędnym transferem, oczyszczaniem i synchronizacją miejsc replikacji, zapewniając w ten sposób bezproblemowe przejście podczas zmian roli serwera. Rozszerzenie jest obsługiwane w przypadku bazy danych PostgreSQL w wersji od 11 do 16.
Więcej informacji i sposobu korzystania z rozszerzenia PG Failover Slots można znaleźć na swojej stronie usługi GitHub.
Włączanie pg_failover_slots
Aby włączyć rozszerzenie PG Failover Slots dla wystąpienia serwera elastycznego usługi Azure Database for PostgreSQL, należy zmodyfikować konfigurację serwera, włączając rozszerzenie w udostępnionych bibliotekach wstępnego ładowania serwera i dostosowując określony parametr serwera. Proces jest następujący:
- Dodaj
pg_failover_slotsdo udostępnionych bibliotek wstępnego ładowania serwera, aktualizującshared_preload_librariesparametr . - Zmień parametr
hot_standby_feedbackserwera naon.
Wszelkie zmiany parametru shared_preload_libraries wymagają ponownego uruchomienia serwera, aby zaczęły obowiązywać.
Korzystanie z witryny Azure Portal:
- Wybierz wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL.
- W menu zasobów w sekcji Ustawienia wybierz pozycję Parametry serwera.
- Wyszukaj parametr i zmodyfikuj
shared_preload_librariesjego wartość, aby uwzględnićpg_failover_slotswartość . hot_standby_feedbackWyszukaj parametr i ustaw jego wartość naon.- Wybierz pozycję Zapisz , aby zachować zmiany. Teraz masz możliwość zapisywania i ponownego uruchamiania. Wybierz tę opcję, aby upewnić się, że zmiany zostaną wprowadzone, ponieważ modyfikacja
shared_preload_librarieswymaga ponownego uruchomienia serwera.
Po wybraniu pozycji Zapisz i uruchom ponownie serwer automatycznie uruchomi ponownie, stosując właśnie wprowadzone zmiany. Gdy serwer wróci do trybu online, rozszerzenie PG Failover Slots jest włączone i działa w podstawowym wystąpieniu serwera elastycznego usługi Azure Database for PostgreSQL, gotowe do obsługi miejsc replikacji logicznej podczas pracy w trybie failover.
pg_hint_plan
pg_hint_plan umożliwia dostosowanie planów wykonywania bazy danych PostgreSQL przy użyciu tak zwanych "wskazówek" w komentarzach SQL, takich jak:
/*+ SeqScan(a) */
pg_hint_plan odczytuje frazy sugerujące w komentarzu specjalnego formularza podanego przy użyciu docelowej instrukcji SQL. Formularz specjalny zaczyna się od sekwencji znaków "/*+" i kończy się znakiem "*/". Frazy wskazówek składają się z nazwy wskazówek i następujących parametrów ujętych w nawiasy i rozdzielonych spacjami. Nowe wiersze umożliwiające czytelność mogą rozdzielać poszczególne frazy wskazówek.
Przykład:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
Poprzedni przykład powoduje, że planista używa wyników seq scan tabeli a do połączenia z tabelą b jako .hash join
Aby zainstalować pg_hint_plan, oprócz tego, aby zezwolić na jego wyświetlanie, jak pokazano w temacie korzystania z rozszerzeń PostgreSQL, należy uwzględnić je w udostępnionych bibliotekach wstępnego ładowania serwera. Zmiana parametru shared_preload_libraries bazy danych Postgres wymaga , aby ponowne uruchomienie serwera miało zastosowanie. Parametry można zmienić przy użyciu witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Korzystanie z witryny Azure Portal:
- Wybierz wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL.
- W menu zasobów w sekcji Ustawienia wybierz pozycję Parametry serwera.
- Wyszukaj parametr i zmodyfikuj
shared_preload_librariesjego wartość, aby uwzględnićpg_hint_planwartość . - Wybierz pozycję Zapisz , aby zachować zmiany. Teraz masz możliwość zapisywania i ponownego uruchamiania. Wybierz tę opcję, aby upewnić się, że zmiany zostaną wprowadzone, ponieważ modyfikacja
shared_preload_librarieswymaga ponownego uruchomienia serwera. Teraz możesz włączyć pg_hint_plan elastycznej bazy danych serwera usługi Azure Database for PostgreSQL. Połącz się z bazą danych i wydaj następujące polecenie:
CREATE EXTENSION pg_hint_plan;
pg_prewarm
Rozszerzenie pg_prewarm ładuje dane relacyjne do pamięci podręcznej. Wstępne tworzenie pamięci podręcznych oznacza, że zapytania mają lepsze czasy odpowiedzi podczas pierwszego uruchomienia po ponownym uruchomieniu. Funkcja automatycznego warmu nie jest obecnie dostępna na serwerze elastycznym usługi Azure Database for PostgreSQL.
pg_repack
Typowym pytaniem, które zadają ludzie podczas pierwszej próby użycia tego rozszerzenia, jest: czy pg_repack rozszerzenie, czy plik wykonywalny po stronie klienta, taki jak psql czy pg_dump?
Odpowiedź na to polega na tym, że jest to rzeczywiście oba. pg_repack/lib przechowuje kod rozszerzenia, w tym schemat i artefakty SQL, które tworzy, oraz bibliotekę C implementujących kod kilku z tych funkcji. Z drugiej strony pg_repack/bin przechowuje kod aplikacji klienckiej, który wie, jak wchodzić w interakcje z artefaktami programowalności utworzonymi przez rozszerzenie. Ta aplikacja kliencka ma na celu złagodzenie złożoności interakcji z różnymi interfejsami, które są udostępniane przez rozszerzenie po stronie serwera, oferując użytkownikowi niektóre opcje wiersza polecenia, które są łatwiejsze do zrozumienia. Aplikacja kliencka bez rozszerzenia utworzonego w bazie danych, do której jest wskazywana, jest bezużyteczna. Rozszerzenie po stronie serwera samo w sobie byłoby w pełni funkcjonalne, ale wymagałoby od użytkownika zrozumienia skomplikowanego wzorca interakcji składającego się z wykonywania zapytań w celu pobrania danych używanych jako dane wejściowe do funkcji implementowanych przez rozszerzenie.
Odmowa uprawnień do ponownego pakowywania schematu
Od tej pory ze względu na sposób, w jaki udzielamy uprawnień do schematu ponownegopakowania utworzonego przez to rozszerzenie, jest obsługiwane tylko uruchamianie funkcji pg_repack z kontekstu azure_pg_adminprogramu .
Możesz zauważyć, że jeśli właściciel tabeli, który nie azure_pg_adminjest , próbuje uruchomić pg_repack, w końcu otrzymuje błąd podobny do następującego:
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
Aby uniknąć tego błędu, upewnij się, że uruchamiasz pg_repack z kontekstu .azure_pg_admin
pg_stat_statements
Rozszerzenie pg_stat_statements udostępnia widok wszystkich zapytań uruchomionych w bazie danych. Jest to przydatne, aby zrozumieć, jak wygląda wydajność obciążenia zapytań w systemie produkcyjnym.
Rozszerzenie pg_stat_statements jest wstępnie ładowane w shared_preload_libraries każdym wystąpieniu serwera elastycznego usługi Azure Database for PostgreSQL, aby zapewnić możliwość śledzenia statystyk wykonywania instrukcji SQL.
Jednak ze względów bezpieczeństwa nadal musisz zezwolić na listę pg_stat_statements rozszerzenia i zainstalować je przy użyciu polecenia CREATE EXTENSION .
Ustawienie pg_stat_statements.track, które kontroluje, które instrukcje są liczone przez rozszerzenie, domyślnie ma wartość , co oznacza, że wszystkie instrukcje topwydane bezpośrednio przez klientów są śledzone. Dwa pozostałe poziomy śledzenia to none i all. To ustawienie można skonfigurować jako parametr serwera.
Istnieje związek między informacjami o wykonywaniu zapytań dostarczanymi przez rozszerzenie pg_stat_statements a wpływem na wydajność serwera, ponieważ to rozszerzenie rejestruje każdą instrukcję SQL. Jeśli nie korzystasz aktywnie z pg_stat_statements rozszerzenia, zalecamy ustawienie wartości pg_stat_statements.track none. Niektóre usługi monitorowania innych firm mogą polegać na pg_stat_statements dostarczaniu szczegółowych informacji o wydajności zapytań, dlatego upewnij się, czy tak jest dla Ciebie, czy nie.
postgres_fdw
postgres_fdw umożliwia nawiązywanie połączenia z jednego wystąpienia serwera elastycznego usługi Azure Database for PostgreSQL do innego lub z inną bazą danych na tym samym serwerze. Serwer elastyczny usługi Azure Database for PostgreSQL obsługuje zarówno połączenia przychodzące, jak i wychodzące z dowolnym serwerem PostgreSQL. Serwer wysyłający musi zezwalać na połączenia wychodzące z serwerem odbierający. Podobnie serwer odbierający musi zezwalać na połączenia z serwera wysyłającego.
Zalecamy wdrożenie serwerów z integracją sieci wirtualnej, jeśli planujesz używać tego rozszerzenia. Domyślnie integracja sieci wirtualnej umożliwia nawiązywanie połączeń między serwerami w sieci wirtualnej. Możesz również użyć sieci wirtualnej sieciowych grup zabezpieczeń w celu dostosowania dostępu.
pgstattuple
W przypadku używania rozszerzenia "pgstattuple" do próby uzyskania statystyk krotki z obiektów przechowywanych w pg_toast schemacie w wersjach postgres od 11 do 13 zostanie wyświetlony błąd "odmowa uprawnień dla schematu pg_toast".
Odmowa uprawnień dla pg_toast schematu
Klienci korzystający z bazy danych PostgreSQL w wersji od 11 do 13 w usłudze Azure Database for Flexible Server nie mogą używać pgstattuple rozszerzenia w obiektach w schemacie pg_toast .
W przypadku bazy danych PostgreSQL 16 i 17 pg_read_all_data rola jest automatycznie udzielana funkcji azure_pg_admin, co pozwala pgstattuple na poprawne działanie. W programie PostgreSQL 14 i 15 klienci mogą ręcznie udzielić pg_read_all_data roli, aby azure_pg_admin osiągnąć ten sam wynik. Jednak w programie PostgreSQL od 11 do 13 pg_read_all_data rola nie istnieje.
Klienci nie mogą bezpośrednio udzielać niezbędnych uprawnień. Jeśli musisz mieć możliwość uruchomienia pgstattuple w celu uzyskania dostępu do obiektów w schemaciepg_toast, przejdź do utworzenia żądania pomoc techniczna platformy Azure.
Baza danych TimescaleDB
TimescaleDB to baza danych szeregów czasowych spakowana jako rozszerzenie dla bazy danych PostgreSQL. Baza danych TimescaleDB zapewnia funkcje analityczne, optymalizacje i skalowanie bazy danych Postgres dla obciążeń szeregów czasowych. Dowiedz się więcej na temat bazy danych TimescaleDB, zarejestrowanego znaku towarowego Timescale, Inc. Elastycznego serwera usługi Azure Database for PostgreSQL, który udostępnia wersję Apache-2 bazy danych TimescaleDB.
Instalowanie bazy danych TimescaleDB
Aby zainstalować bazę danych TimescaleDB, oprócz tego, aby zezwolić na jej wyświetlenie, jak pokazano powyżej, należy uwzględnić ją w udostępnionych bibliotekach wstępnego ładowania serwera. Zmiana parametru shared_preload_libraries bazy danych Postgres wymaga , aby ponowne uruchomienie serwera miało zastosowanie. Parametry można zmienić przy użyciu witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure.
Korzystanie z witryny Azure Portal:
- Wybierz wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL.
- W menu zasobów w sekcji Ustawienia wybierz pozycję Parametry serwera.
- Wyszukaj parametr i zmodyfikuj
shared_preload_librariesjego wartość, aby uwzględnićTimescaleDBwartość . - Wybierz pozycję Zapisz , aby zachować zmiany. Teraz masz możliwość zapisywania i ponownego uruchamiania. Wybierz tę opcję, aby upewnić się, że zmiany zostaną wprowadzone, ponieważ modyfikacja
shared_preload_librarieswymaga ponownego uruchomienia serwera. Teraz możesz włączyć bazę danych TimescaleDB w elastycznej bazie danych serwera usługi Azure Database for PostgreSQL. Połącz się z bazą danych i wydaj następujące polecenie:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Napiwek
Jeśli zostanie wyświetlony błąd, upewnij się, że serwer został uruchomiony ponownie po zapisaniu shared_preload_libraries.
Teraz możesz utworzyć hipertable bazy danych TimescaleDB od podstaw lub zmigrować istniejące dane szeregów czasowych w usłudze PostgreSQL.
Przywracanie bazy danych skali czasu przy użyciu pg_dump i pg_restore
Aby przywrócić bazę danych skali czasu przy użyciu pg_dump i pg_restore, należy uruchomić dwie procedury pomocnicze w docelowej bazie danych: timescaledb_pre_restore() i timescaledb_post restore().
Najpierw przygotuj docelową bazę danych:
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Teraz możesz uruchomić pg_dump w oryginalnej bazie danych, a następnie wykonać pg_restore. Po przywróceniu pamiętaj, aby uruchomić następujące polecenie w przywróconej bazie danych:
SELECT timescaledb_post_restore();
Aby uzyskać więcej informacji na temat metody przywracania z włączoną bazą danych w skali czasu, zobacz dokumentację skali czasu.
Przywracanie bazy danych w skali czasu przy użyciu kopii zapasowej bazy danych timescaledb
Podczas uruchamiania SELECT timescaledb_post_restore() procedury wymienionej powyżej możesz uzyskać błąd odmowy uprawnień podczas aktualizowania flagi timescaledb.restoring. Jest to spowodowane ograniczonymi uprawnieniami ALTER DATABASE w usługach baz danych PaaS w chmurze. W takim przypadku możesz wykonać alternatywną metodę przy użyciu timescaledb-backup narzędzia do tworzenia kopii zapasowych i przywracania bazy danych w skali czasu. Kopia zapasowa bazy danych Timescaledb to program umożliwiający zrzucanie i przywracanie bazy danych TimescaleDB prostsze, mniej podatne na błędy i bardziej wydajne.
W tym celu należy wykonać następujące czynności:
- Zainstaluj narzędzia zgodnie z opisem w tym miejscu
- Tworzenie docelowego wystąpienia serwera elastycznego i bazy danych usługi Azure Database for PostgreSQL
- Włącz rozszerzenie skali czasu, jak pokazano powyżej
- Udzielanie
azure_pg_adminroli użytkownikowi, który będzie używany przez funkcję ts-restore - Uruchamianie funkcji ts-restore w celu przywrócenia bazy danych
Więcej informacji na temat tych narzędzi można znaleźć tutaj.
Rozszerzenia i uaktualnienie wersji głównej
Serwer elastyczny usługi Azure Database for PostgreSQL wprowadził funkcję uaktualniania wersji głównej, która wykonuje uaktualnienie w miejscu wystąpienia elastycznego serwera usługi Azure Database for PostgreSQL za pomocą zaledwie jednego kliknięcia. Uaktualnienie wersji głównej w miejscu upraszcza proces uaktualniania serwera elastycznego usługi Azure Database for PostgreSQL, minimalizując zakłócenia dla użytkowników i aplikacji, które uzyskują dostęp do serwera. Uaktualnienie wersji głównej w miejscu nie obsługuje określonych rozszerzeń i istnieją pewne ograniczenia dotyczące uaktualniania niektórych rozszerzeń. Rozszerzenia anon, Apache AGE, dblink, orafce, pgaudit, postgres_fdw i Timescaledb nie są obsługiwane dla wszystkich elastycznych wersji serwera usługi Azure Database for PostgreSQL w przypadku korzystania z funkcji aktualizacji wersji głównej w miejscu.