Co to jest azure Chaos Studio?
Azure Chaos Studio to zarządzana usługa, która używa inżynierii chaosu w celu ułatwienia mierzenia, zrozumienia i poprawy odporności aplikacji i usług w chmurze. Inżynieria chaosu to metodologia, za pomocą której wprowadzasz do aplikacji rzeczywiste błędy w celu uruchomienia kontrolowanych eksperymentów polegających na wstrzyknięciu błędów.
Odporność to możliwość systemu do obsługi i odzyskiwania po zakłóceniach. Zakłócenia aplikacji mogą powodować błędy i błędy, które mogą negatywnie wpłynąć na twoją firmę lub misję. Niezależnie od tego, czy tworzysz, migrujesz, czy obsługujesz aplikacje platformy Azure, ważne jest, aby zweryfikować i poprawić odporność aplikacji.
Program Chaos Studio pomaga uniknąć negatywnych konsekwencji, sprawdzając, czy aplikacja skutecznie reaguje na zakłócenia i błędy. Za pomocą programu Chaos Studio możesz przetestować odporność na zdarzenia w świecie rzeczywistym, takie jak awarie lub wysokie użycie procesora CPU na maszynach wirtualnych.
Poniższy film wideo zawiera więcej informacji na temat programu Chaos Studio:
Scenariusze programu Chaos Studio
Można użyć inżynierii chaosu w różnych scenariuszach weryfikacji odporności obejmujących cykl życia programowania i operacji usługi. Istnieją dwa typy scenariuszy:
- Shift w prawo: w tych scenariuszach używane jest środowisko produkcyjne lub przedprodukcyjne. Zazwyczaj wykonujesz scenariusze przesunięcia w prawo z rzeczywistym ruchem klientów lub symulowanym obciążeniem.
- Shift w lewo: te scenariusze mogą używać środowiska projektowego lub udostępnionego testu. Możesz wykonywać scenariusze z przesunięciem w lewo bez żadnego rzeczywistego ruchu klientów.
Możesz użyć programu Chaos Studio w następujących typowych scenariuszach inżynierii chaosu:
- Odtwórz zdarzenie, które wpłynęło na aplikację, aby lepiej zrozumieć awarię. Upewnij się, że naprawy po zdarzeniu uniemożliwiają cykliczne zdarzenie.
- Przygotuj się na ważne wydarzenie lub sezon z obciążeniem", skalowaniem, wydajnością i walidacją odporności.
- Wykonywanie próbnych ciągłości działania i odzyskiwania po awarii w celu zapewnienia, że aplikacja może szybko odzyskać i zachować krytyczne dane w przypadku awarii.
- Uruchom próbne wysokiej dostępności, aby przetestować odporność aplikacji na awarie regionów, błędy konfiguracji sieci, zdarzenia o wysokim obciążeniu lub problemy z hałaśliwymi sąsiadami.
- Opracowywanie testów porównawczych wydajności aplikacji.
- Planowanie potrzeb w zakresie pojemności dla środowisk produkcyjnych.
- Uruchamianie testów obciążeniowych lub testów obciążeniowych.
- Upewnij się, że usługi migrowane ze środowiska lokalnego lub innego środowiska w chmurze pozostają odporne na znane awarie.
- Budować zaufanie do usług opartych na architekturach natywnych dla chmury.
- Sprawdź, czy narzędzia witryny na żywo, dane dotyczące obserwacji i procesy wywołania nadal działają w nieoczekiwanych warunkach.
W przypadku wielu z tych scenariuszy najpierw tworzysz odporność przy użyciu eksperymentów chaosu ad hoc. Następnie stale sprawdzasz, czy nowe wdrożenia nie ulegają pogorszeniu odporności. Aby to sprawdzić, uruchamiasz eksperymenty chaosu jako bramy wdrażania w potokach ciągłej integracji/ciągłego wdrażania.
Jak działa program Chaos Studio
Za pomocą programu Chaos Studio można organizować bezpieczne, kontrolowane wstrzykiwanie błędów na zasobach platformy Azure. Eksperymenty chaosu są rdzeniem programu Chaos Studio. Eksperyment chaosu opisuje błędy do uruchomienia i zasoby do uruchomienia. Błędy można organizować równolegle lub sekwencjonować w zależności od potrzeb.
Program Chaos Studio obsługuje dwa typy błędów:
- Usługa bezpośrednia: te błędy są uruchamiane bezpośrednio względem zasobu platformy Azure bez żadnej instalacji ani instrumentacji. Przykłady obejmują ponowne uruchomienie klastra usługi Azure Cache for Redis lub dodanie opóźnienia sieci do zasobników usługi Azure Kubernetes Service.
- Oparte na agencie: te błędy są uruchamiane na maszynach wirtualnych lub w zestawach skalowania maszyn wirtualnych w celu wykonania niepowodzeń gościa. Przykłady obejmują stosowanie ciśnienia pamięci wirtualnej lub zabijanie procesu.
Każda usterka ma określone parametry, które można skonfigurować, na przykład, który proces ma spowodować zabicie lub ilość pamięci do wygenerowania.
Podczas tworzenia eksperymentu chaosu należy zdefiniować jeden lub więcej kroków wykonywanych sekwencyjnie. Każdy krok zawiera co najmniej jedną gałąz , która jest uruchamiana równolegle w kroku. Każda gałąź zawiera jedną lub więcej akcji, takich jak wstrzykiwanie błędu lub oczekiwanie na określony czas trwania.
Cele zasobów można organizować w celu uruchamiania błędów w grupach nazywanych selektorami, dzięki czemu można łatwo odwoływać się do grupy zasobów w każdej akcji.
Na poniższym diagramie przedstawiono układ eksperymentu chaosu w narzędziu Chaos Studio:
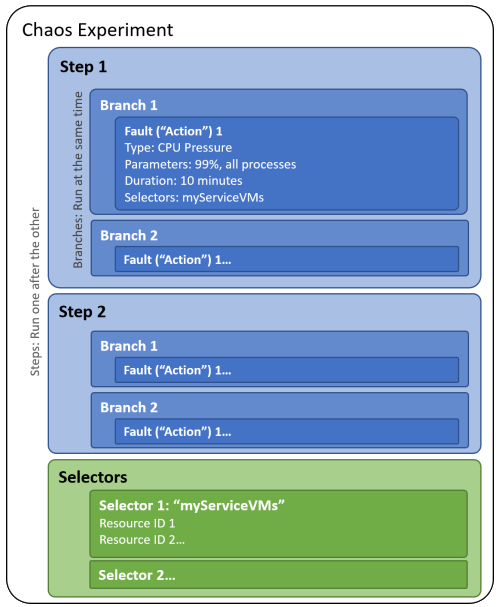
Eksperyment chaosu to zasób platformy Azure w subskrypcji i grupie zasobów. Za pomocą witryny Azure Portal lub interfejsu API REST programu Chaos Studio można tworzyć, aktualizować, uruchamiać, anulować i wyświetlać stan eksperymentów.
Następne kroki
Teraz, gdy już wiesz, jak korzystać z inżynierii chaosu, możesz przystąpić do wykonywania następujących czynności: