Operacje zarządzania w usłudze Azure Managed Instance for Apache Cassandra
Azure Managed Instance for Apache Cassandra to w pełni zarządzana usługa dla czystych klastrów Apache Cassandra typu open source. Usługa umożliwia również zastępowanie konfiguracji w zależności od konkretnych potrzeb każdego obciążenia, co pozwala na maksymalną elastyczność i kontrolę w razie potrzeby. W tym artykule zdefiniowano operacje zarządzania i funkcje udostępniane przez usługę. Wyjaśniono również rozdzielenie obowiązków między zespołem pomoc techniczna platformy Azure a klientami podczas utrzymywania klastrów hybrydowych.
Zagęszczania
- Istnieją różne typy kompaktowania. Obecnie przeprowadzamy niewielkie kompaktowanie za pomocą naprawy (zobacz Konserwacja). To wykonuje kompaktowanie drzewa Merkle, który jest specjalnym rodzajem kompaktowania.
- W zależności od strategii kompaktowania, która została ustawiona w tabeli przy użyciu języka CQL (na przykład
WITH compaction = { 'class' : 'LeveledCompactionStrategy' }), system Cassandra automatycznie kompaktuje się, gdy tabela osiągnie określony rozmiar. Zalecamy dokładne wybranie strategii kompaktowania obciążenia i nie należy wykonywać żadnych ręcznych kompaktowania poza strategią.
Stosowanie poprawek
Poprawki na poziomie systemu operacyjnego są wykonywane automatycznie w około 2-tygodniowym tempie.
Poprawki na poziomie oprogramowania Apache Cassandra są wykonywane po zidentyfikowaniu luk w zabezpieczeniach. Cykl stosowania poprawek może się różnić.
Podczas stosowania poprawek maszyny są ponownie uruchamiane po jednym stojaku naraz. Nie należy doświadczać żadnego pogorszenia po stronie aplikacji, o ile nie jest używane ustawienie kworum ALL, a współczynnik replikacji wynosi 3 lub więcej.
Wersja w systemie Apache Cassandra ma format
X.Y.Z. Wdrożenie wersji głównych (X) i pomocniczych (Y) można kontrolować ręcznie za pomocą narzędzi usługi. Podczas gdy poprawki cassandra (Z), które mogą być wymagane dla tej kombinacji wersji głównej/pomocniczej, są wykonywane automatycznie.
Uwaga
Usługa obsługuje obecnie systemy Cassandra w wersji 3.11 i 4.0. Obie wersje są ogólnie dostępne. Zobacz nasz przewodnik Szybki start interfejsu wiersza polecenia platformy Azure (krok 5), aby określić wersję rozwiązania Cassandra podczas wdrażania klastra.
Konserwacja
Naprawa narzędzia Nodetool jest automatycznie uruchamiana przez usługę przy użyciu narzędzia reaper. To narzędzie jest uruchamiane co tydzień. Jeśli używasz własnej usługi do wdrożenia hybrydowego, możesz go wyłączyć.
Monitorowanie kondycji węzła składa się z następujących elementów:
- Aktywne monitorowanie członkostwa każdego węzła w pierścieniu Cassandra.
- Autodetecting i automitigating problemów z infrastrukturą, takich jak maszyna wirtualna, sieć, magazyn, linux i obsługa błędów oprogramowania.
- Aktywne monitorowanie procesora CPU, dysku, utraty kworum i innych problemów z zasobami.
- Automatyczne ustawianie węzłów, które zakończyły się niepowodzeniem, jeśli jest to możliwe, i ręczne ustawianie węzłów w odpowiedzi na ostrzeżenia generowane automatycznie.
Pomoc techniczna
Usługa Azure Managed Instance for Apache Cassandra zapewnia umowę SLA dotyczącą dostępności centrów danych w klastrze zarządzanym. Jeśli wystąpią jakiekolwiek problemy z używaniem usługi, prześlij wniosek o pomoc techniczną w witrynie Azure Portal.
Nasze korzyści z pomocy technicznej obejmują:
- Pojedynczy punkt kontaktu dotyczący problemów z infrastrukturą Cassandra — nie trzeba zgłaszać zgłoszeń do pomocy technicznej w zespołach IaaS (dysk, obliczenia, sieć).
- Pro-active doradzać za pośrednictwem poczty e-mail na szyi butelek wydajności, rozmiaru i innych problemów z ograniczeniem zasobów.
- Pokrycie pomocy technicznej 24x7, w tym zdarzenia generowane automatycznie w przypadku poważnych problemów z awarią.
- Obsługa poprawek zatwierdzonych przez społeczność (zobacz Stosowanie poprawek).
- Wewnętrzne wsparcie zespołu inżynierów java JDK/JVM.
- Obsługa systemu operacyjnego Linux z zabezpieczeniami łańcucha dostaw oprogramowania.
Ważne
Zbadamy i zdiagnozujemy wszelkie zgłoszone problemy za pośrednictwem zgłoszenia do pomocy technicznej oraz rozwiążemy lub rozwiążemy je, jeśli to możliwe. Jednak użytkownik jest ostatecznie odpowiedzialny za użycie na poziomie konfiguracji apache Cassandra, co powoduje problemy z procesorem CPU, dyskiem lub siecią.
Przykłady takich problemów obejmują:
- Nieefektywne operacje zapytań.
- Przepływność, która przekracza pojemność.
- Pozyskiwanie danych przekraczających pojemność magazynu.
- Nieprawidłowe ustawienia konfiguracji przestrzeni kluczy.
- Słaba strategia modelu danych lub klucza partycji.
W przypadku zbadania zgłoszenia do pomocy technicznej i wykrycia, że główną przyczyną problemu jest poziom konfiguracji apache Cassandra (a nie jakiekolwiek podstawowe aspekty na poziomie platformy, które utrzymujemy), nadal przedstawimy zalecenia i wskazówki dotyczące korygowania lub ograniczania ryzyka (jeśli to możliwe), przed zamknięciem sprawy.
Zalecamy włączenie metryk i/lub zapoznanie się z integracją usługi Azure Monitor, aby zapobiec typowym problemom na poziomie aplikacji/konfiguracji w systemie Apache Cassandra, takim jak powyższe.
Ostrzeżenie
Usługa Azure Managed Instance dla systemu Apache Cassandra umożliwia również uruchamianie nodetool poleceń i sstable rutynowe administrowanie bazą danych — zobacz artykuł tutaj. Niektóre z tych poleceń mogą zdestabilizować klaster cassandra i powinny być uruchamiane dokładnie i po przetestowaniu w środowiskach nieprodukcyjnych. W miarę --dry-run możliwości należy najpierw wdrożyć opcję. Firma Microsoft nie może zaoferować żadnej umowy SLA ani pomocy technicznej w przypadku problemów z uruchamianiem poleceń, które zmieniają domyślną konfigurację bazy danych i/lub tabele.
Tworzenie kopii zapasowej i przywracanie
Kopie zapasowe migawek są domyślnie włączone i wykonywane co 24 godziny. Kopie zapasowe są przechowywane na wewnętrznym koncie usługi Azure Blob Storage i są przechowywane przez maksymalnie 2 dni (48 godzin). Nie ma kosztów dla pierwszych 2 kopii zapasowych. Dodatkowe kopie zapasowe są naliczane, zobacz cennik. Aby zmienić interwał kopii zapasowej lub okres przechowywania, możesz edytować zasady w portalu:

Aby przywrócić z istniejącej kopii zapasowej, utwórz wniosek o pomoc techniczną w witrynie Azure Portal. W przypadku zgłoszenia zgłoszenia do pomocy technicznej należy wykonać następujące elementy:
Podaj identyfikator kopii zapasowej z portalu dla kopii zapasowej, którą chcesz przywrócić. Można to znaleźć w portalu:
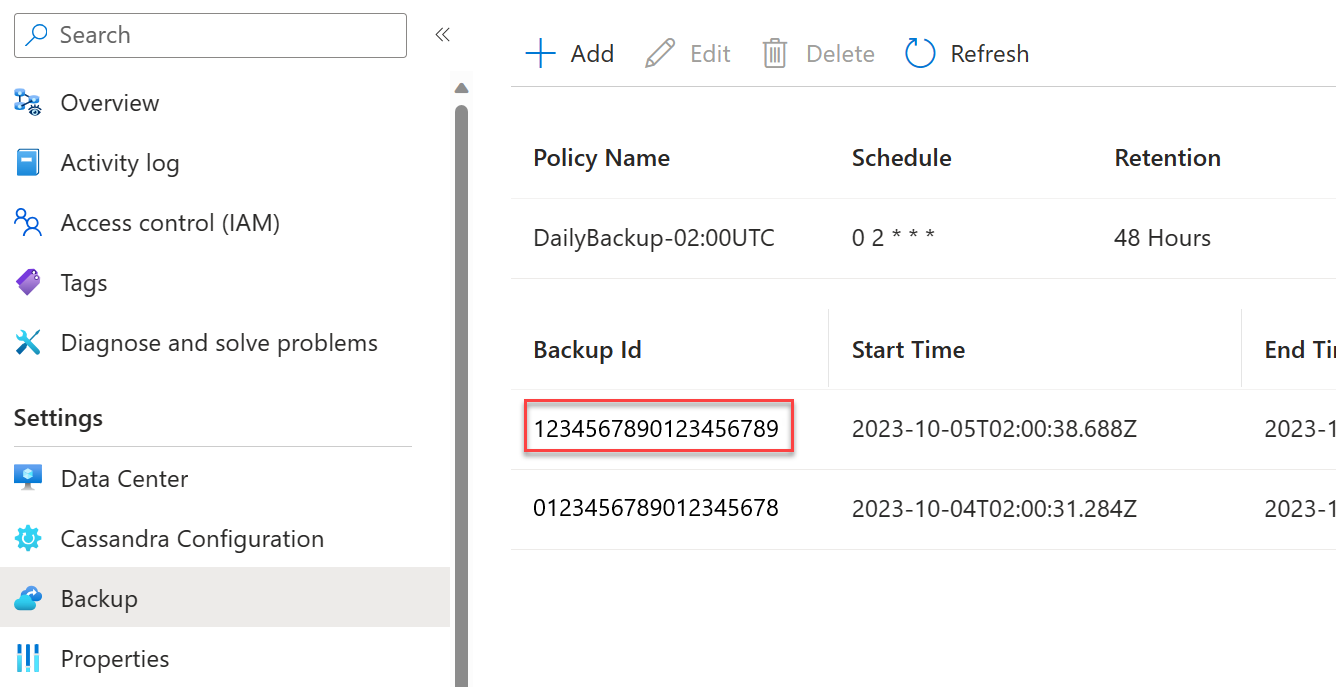
Poinformuj nas, czy źródłowe centrum danych zostało usunięte. Będzie to ważne, aby zidentyfikować prawidłowe konto kopii zapasowej do przywrócenia.
Jeśli przywracanie całego klastra nie jest wymagane, podaj przestrzeń kluczy i tabelę (jeśli ma to zastosowanie), które należy przywrócić.
Sprawdź, czy chcesz przywrócić kopię zapasową w istniejącym klastrze, czy w nowym klastrze.
Jeśli chcesz przywrócić do nowego klastra, musisz najpierw utworzyć nowy klaster. Upewnij się, że klaster docelowy jest zgodny z klastrem źródłowym pod względem liczby centrów danych i że odpowiednie centrum danych ma taką samą liczbę węzłów. Możesz również zdecydować, czy poświadczenia (nazwa użytkownika/hasło) mają być zachowywane w nowym klastrze docelowym, czy też zezwalać na przywracanie w celu zastąpienia nazwy użytkownika/hasła przy użyciu tego, co zostało pierwotnie utworzone.
Możesz również zdecydować, czy zachować
system_authprzestrzeń kluczy w nowym klastrze docelowym, czy zezwolić na zastąpienie jej danymi z kopii zapasowej.system_authPrzestrzeń kluczy w systemie Cassandra zawiera dane autoryzacji i uwierzytelniania wewnętrznego, w tym role, uprawnienia roli i hasła. Pamiętaj, że nasz domyślny proces przywracania zastępujesystem_authprzestrzeń kluczy.

Uwaga
Czas potrzebny na udzielenie odpowiedzi na żądanie przywrócenia z kopii zapasowej zależy zarówno od ważności zgłoszenia do pomocy technicznej (i odpowiedniej umowy SLA na czas odpowiedzi) oraz ilości danych do przywrócenia. Nie udostępniamy jednak umowy SLA na czas ukończenia przywracania, ponieważ jest to bardzo zależne od ilości przywracanych danych.
Ostrzeżenie
Kopie zapasowe są przeznaczone do scenariuszy przypadkowego usunięcia i nie są geograficznie nadmiarowe. W związku z tym nie są one zalecane do użycia jako strategia odzyskiwania po awarii (DR) w przypadku całkowitej awarii regionalnej. Aby zapewnić ochronę przed awariami w całym regionie, zalecamy wdrożenie w wielu regionach. Zapoznaj się z naszym przewodnikiem Szybki start dla wdrożeń w wielu regionach.
Zabezpieczenia
Usługa Azure Managed Instance for Apache Cassandra udostępnia wiele wbudowanych jawnych mechanizmów kontroli zabezpieczeń i funkcji:
- Wzmocnione obrazy maszyn wirtualnych z systemem Linux z kontrolowanym łańcuchem dostaw.
- Typowe monitorowanie luk w zabezpieczeniach i ekspozycji (CVE) na poziomie systemu operacyjnego.
- Rotacja certyfikatów zarówno dla oprogramowania Apache Cassandra, jak i Prometheus hostowanego na zarządzanych maszynach wirtualnych.
- Aktywne skanowanie luk w zabezpieczeniach.
- Aktywne skanowanie wirusów.
- Bezpieczne praktyki kodowania.
Aby uzyskać więcej informacji na temat funkcji zabezpieczeń, zobacz nasz artykuł tutaj.
Obsługa hybrydowa
Po skonfigurowaniu klastra hybrydowego automatyczne operacje ponownego uruchamiania w usłudze są korzystne dla całego klastra. Obejmuje to centra danych, które nie są aprowidowane przez usługę. Poza tym twoim zadaniem jest utrzymanie lokalnego lub zewnętrznie hostowanego centrum danych.
Następne kroki
Rozpocznij pracę z jednym z naszych przewodników Szybki start: