Dostrajanie monitów przy użyciu wariantów
Tworzenie dobrego monitu jest trudnym zadaniem, które wymaga dużo kreatywności, jasności i istotności. Dobry monit może wywołać żądane dane wyjściowe z wstępnie wytrenowanego modelu językowego, podczas gdy zły monit może prowadzić do niedokładnych, nieistotnych lub niesensownych danych wyjściowych. W związku z tym należy dostosować monity, aby zoptymalizować ich wydajność i niezawodność dla różnych zadań i domen.
Dlatego wprowadzamy koncepcję wariantów , które mogą pomóc w przetestowaniu zachowania modelu w różnych warunkach, takich jak różne sformułowanie, formatowanie, kontekst, temperatura lub top-k, porównanie i znalezienie najlepszego monitu i konfiguracji, które maksymalizuje dokładność, różnorodność lub spójność modelu.
W tym artykule pokażemy, jak używać wariantów do dostosowywania monitów i oceniania wydajności różnych wariantów.
Wymagania wstępne
Przed przeczytaniem tego artykułu lepiej jest przejść przez następujące elementy:
Jak dostroić monity przy użyciu wariantów?
W tym artykule użyjemy przykładowego przepływu klasyfikacji sieci Web.
Otwórz przykładowy przepływ i usuń węzeł prepare_examples jako początek.
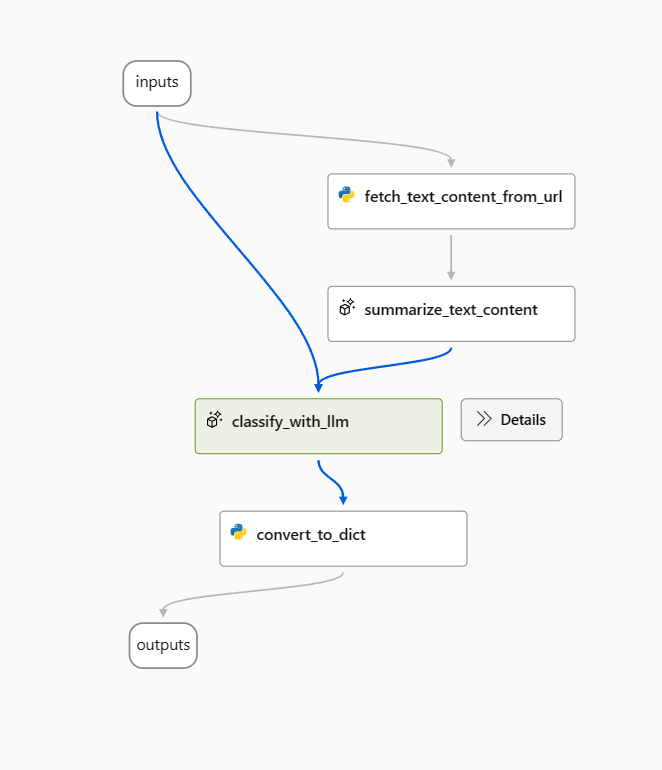
Użyj następującego monitu jako wiersza polecenia punktu odniesienia w węźle classify_with_llm .

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Aby zoptymalizować ten przepływ, może istnieć wiele sposobów, a poniżej przedstawiono dwa kierunki:
Dla classify_with_llm węzła: Nauczyłem się od społeczności i dokumentów, że niższa temperatura daje większą precyzję, ale mniej kreatywności i zaskoczenia, więc niższa temperatura jest odpowiednia dla zadań klasyfikacji, a także kilka strzałów monitujących może zwiększyć wydajność LLM. Dlatego chciałbym przetestować, jak działa mój przepływ, gdy temperatura zmienia się z zakresu od 1 do 0, a gdy jest wyświetlany monit z kilkoma przykładami strzałów.
W przypadku węzła summarize_text_content : Chcę również przetestować zachowanie przepływu, gdy zmieniam podsumowanie z 100 słów na 300, aby sprawdzić, czy więcej zawartości tekstowej może pomóc zwiększyć wydajność.
Tworzenie wariantów
- Wybierz przycisk Pokaż warianty w prawym górnym rogu węzła LLM. Istniejący węzeł LLM jest variant_0 i jest wariantem domyślnym.
- Wybierz przycisk Klonuj w variant_0, aby wygenerować variant_1, a następnie możesz skonfigurować parametry do różnych wartości lub zaktualizować monit przy variant_1.
- Powtórz krok, aby utworzyć więcej wariantów.
- Wybierz pozycję Ukryj warianty , aby przestać dodawać więcej wariantów. Wszystkie warianty są składane. Domyślny wariant jest wyświetlany dla węzła.
W przypadku węzła classify_with_llm na podstawie variant_0:
- Utwórz variant_1, w którym temperatura zmienia się z zakresu od 1 do 0.
- Utwórz variant_2, gdzie temperatura wynosi 0, i możesz użyć następującego monitu, w tym kilka zdjęć przykłady.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
W przypadku węzła summarize_text_content opartego na variant_0 można utworzyć variant_1, gdzie 100 words jest zmieniana na 300 wyrazy w wierszu polecenia.
Teraz przepływ wygląda następująco, 2 warianty dla węzła summarize_text_content i 3 dla węzła classify_with_llm .

Uruchamianie wszystkich wariantów z pojedynczym wierszem danych i sprawdzanie danych wyjściowych
Aby upewnić się, że wszystkie warianty mogą działać pomyślnie i działają zgodnie z oczekiwaniami, możesz uruchomić przepływ z pojedynczym wierszem danych do przetestowania.
Uwaga
Za każdym razem można wybrać tylko jeden węzeł LLM z wariantami do uruchomienia, podczas gdy inne węzły LLM będą używać wariantu domyślnego.
W tym przykładzie konfigurujemy warianty zarówno dla węzła summarize_text_content , jak i węzła classify_with_llm , więc należy uruchomić dwa razy, aby przetestować wszystkie warianty.
- Wybierz przycisk Uruchom w prawym górnym rogu.
- Wybierz węzeł LLM z wariantami. Pozostałe węzły LLM będą używać wariantu domyślnego.
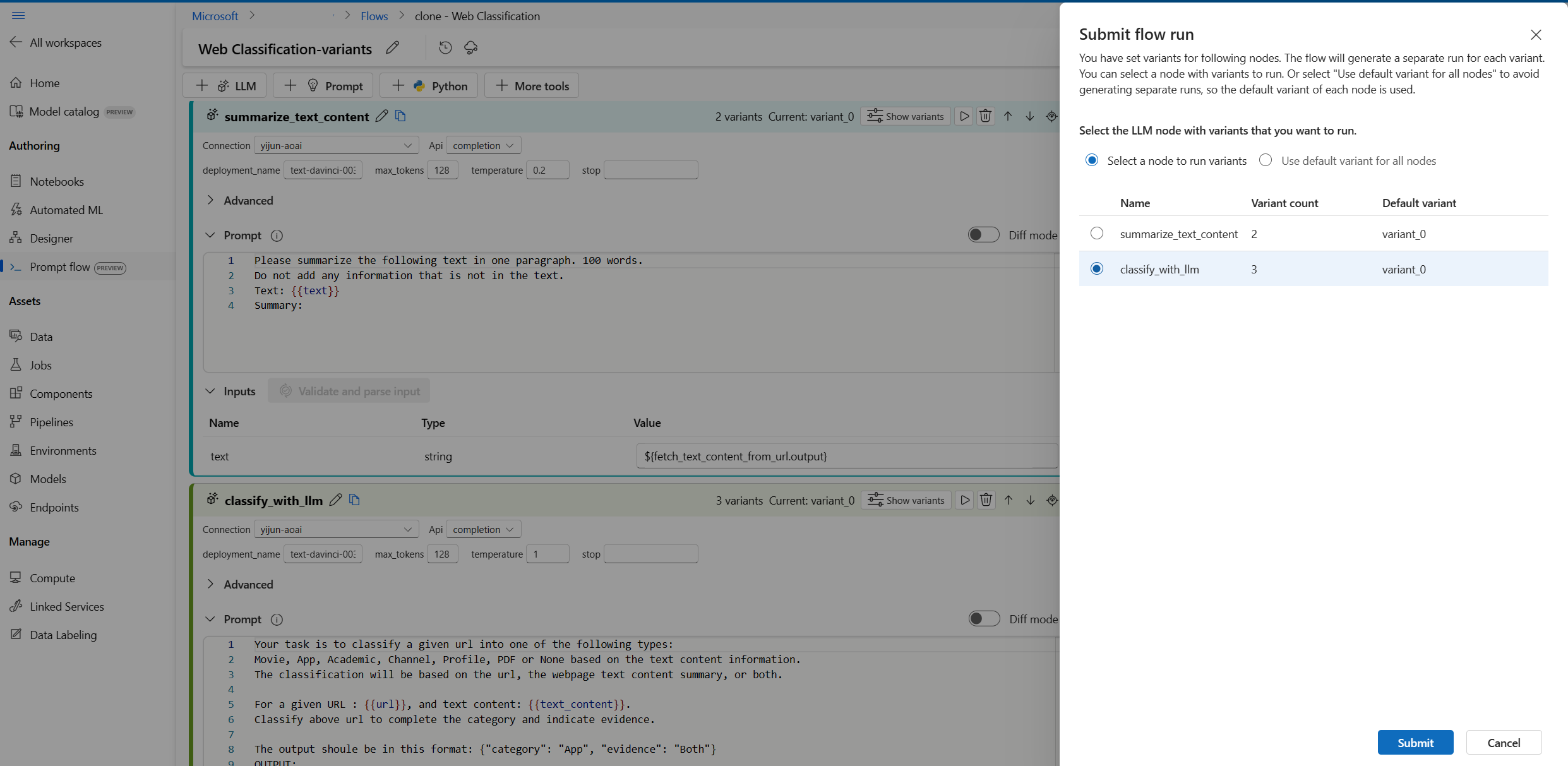
- Prześlij przebieg przepływu.
- Po zakończeniu przebiegu przepływu można sprawdzić odpowiedni wynik dla każdego wariantu.
- Prześlij kolejny przebieg przepływu z innym węzłem LLM z wariantami i sprawdź dane wyjściowe.
- Możesz zmienić inne dane wejściowe (na przykład użyć adresu URL strony Wikipedii) i powtórzyć powyższe kroki, aby przetestować warianty dla różnych danych.

Ocena wariantów
Po uruchomieniu wariantów z kilkoma pojedynczymi fragmentami danych i sprawdzeniu wyników z nagim okiem nie można odzwierciedlić złożoności i różnorodności danych rzeczywistych, w międzyczasie dane wyjściowe nie są wymierne, więc trudno porównać skuteczność różnych wariantów, a następnie wybrać najlepsze.
Możesz przesłać przebieg wsadowy, który pozwala przetestować warianty z dużą ilością danych i ocenić je za pomocą metryk, aby ułatwić znalezienie najlepszego dopasowania.
Najpierw musisz przygotować zestaw danych, który jest reprezentatywny dla rzeczywistego problemu, który chcesz rozwiązać za pomocą przepływu monitu. W tym przykładzie jest to lista adresów URL i ich głównej prawdy klasyfikacji. Użyjemy dokładności, aby ocenić wydajność wariantów.
Wybierz pozycję Oceń w prawym górnym rogu strony.
Występuje kreator uruchamiania i oceny usługi Batch. Pierwszym krokiem jest wybranie węzła w celu uruchomienia wszystkich jego wariantów.
Aby sprawdzić, jak dobrze działają różne warianty dla każdego węzła w przepływie, należy uruchomić uruchomienie wsadowe dla każdego węzła z wariantami po jednym. Pomaga to uniknąć wpływu wariantów innych węzłów i skoncentrować się na wynikach wariantów tego węzła. Jest to zgodne z regułą kontrolowanego eksperymentu, co oznacza, że zmieniasz tylko jedną rzecz jednocześnie i zachowasz wszystko inne w tym samym czasie.
Możesz na przykład wybrać węzeł classify_with_llm , aby uruchomić wszystkie warianty, węzeł summarize_text_content będzie używać jego domyślnego wariantu dla tego przebiegu wsadowego.
Następnie w ustawieniach przebiegu usługi Batch możesz ustawić nazwę przebiegu wsadowego, wybrać środowisko uruchomieniowe, przekazać przygotowane dane.
Następnie w obszarze Ustawienia oceny wybierz metodę oceny.
Ponieważ ten przepływ jest przeznaczony do klasyfikacji, możesz wybrać metodę oceny dokładności klasyfikacji, aby ocenić dokładność.
Dokładność jest obliczana przez porównanie przewidywanych etykiet przypisanych przez przepływ (przewidywanie) z rzeczywistymi etykietami danych (prawda naziemna) i zliczeniem, ile z nich pasuje.
W sekcji Mapowanie danych wejściowych oceny należy określić, czy prawda naziemna pochodzi z kolumny kategorii wejściowego zestawu danych, a przewidywanie pochodzi z jednej z danych wyjściowych przepływu: kategoria.
Po przejrzeniu wszystkich ustawień możesz przesłać przebieg wsadowy.
Po przesłaniu przebiegu wybierz link, przejdź do strony szczegółów przebiegu.
Uwaga
Ukończenie przebiegu może potrwać kilka minut.
Wizualizowanie danych wyjściowych
- Po zakończeniu przebiegu i oceny wsadowej na stronie szczegółów przebiegu wybierz wiele przebiegów wsadowych dla każdego wariantu, a następnie wybierz pozycję Visualize outputs (Wizualizacja danych wyjściowych). Zobaczysz metryki 3 wariantów dla węzła classify_with_llm i przewidywane dane wyjściowe llM dla każdego rekordu danych.
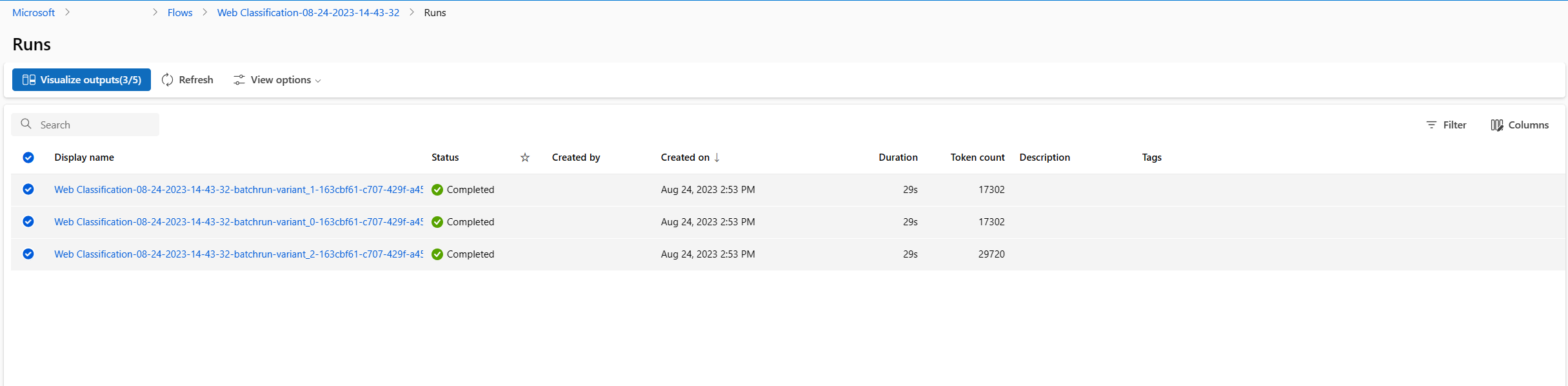
- Po zidentyfikowaniu, który wariant jest najlepszy, możesz wrócić do strony tworzenia przepływu i ustawić ten wariant jako domyślny wariant węzła
- Powyższe kroki można powtórzyć, aby ocenić warianty węzła summarize_text_content .
Teraz zakończono proces dostrajania monitów przy użyciu wariantów. Tę technikę można zastosować do własnego przepływu monitów, aby znaleźć najlepszy wariant dla węzła LLM.