Przesyłanie przebiegu wsadowego w celu oceny przepływu
Uruchomienie wsadowe wykonuje przepływ monitu z dużym zestawem danych i generuje dane wyjściowe dla każdego wiersza danych. Aby ocenić, jak dobrze działa przepływ monitów z dużym zestawem danych, możesz przesłać przebieg wsadowy i użyć metod oceny w celu wygenerowania wyników wydajności i metryk.
Po zakończeniu przepływu wsadowego metody oceny są wykonywane automatycznie w celu obliczenia wyników i metryk. Metryki oceny umożliwiają ocenę danych wyjściowych przepływu względem kryteriów wydajności i celów.
W tym artykule opisano sposób przesyłania przebiegu wsadowego i używania metody oceny do mierzenia jakości danych wyjściowych przepływu. Dowiesz się, jak wyświetlić wynik oceny i metryki oraz jak rozpocząć nową rundę oceny przy użyciu innej metody lub podzestawu wariantów.
Wymagania wstępne
Aby uruchomić przepływ wsadowy z metodą oceny, potrzebne są następujące składniki:
Działający przepływ monitu usługi Azure Machine Learning, dla którego chcesz przetestować wydajność.
Testowy zestaw danych do użycia na potrzeby przebiegu wsadowego.
Testowy zestaw danych musi być w formacie CSV, TSV lub JSONL i powinien zawierać nagłówki zgodne z nazwami wejściowymi przepływu. Można jednak mapować różne kolumny zestawu danych na kolumny wejściowe podczas procesu instalacji przebiegu oceny.
Tworzenie i przesyłanie przebiegu wsadowego oceny
Aby przesłać przebieg wsadowy, należy wybrać zestaw danych, za pomocą którego chcesz przetestować przepływ. Możesz również wybrać metodę oceny, aby obliczyć metryki dla danych wyjściowych przepływu. Jeśli nie chcesz używać metody oceny, możesz pominąć kroki oceny i uruchomić przebieg wsadowy bez obliczania metryk. Możesz również uruchomić rundę oceny później.
Aby rozpocząć uruchamianie wsadowe z oceną lub bez tej oceny, wybierz pozycję Oceń w górnej części strony przepływu monitu.
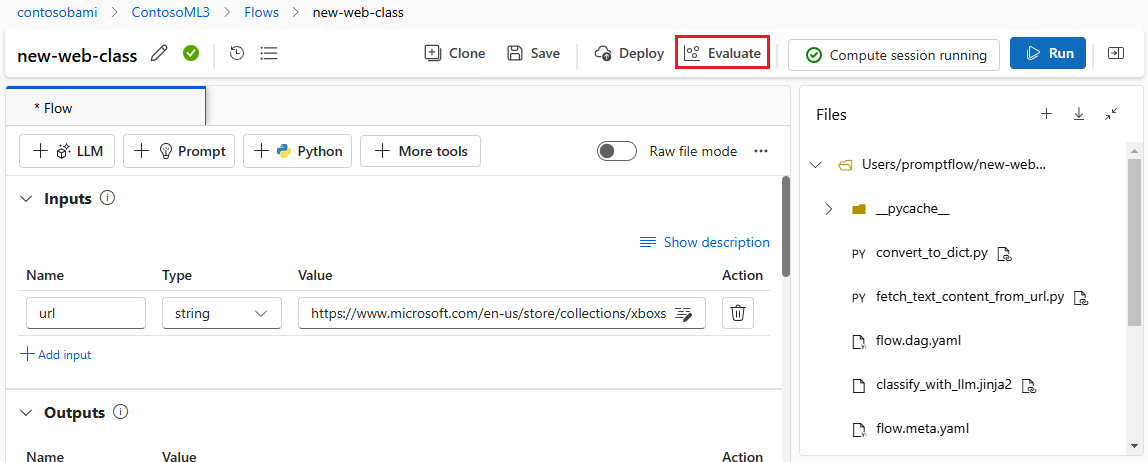
Na stronie Ustawienia podstawowe kreatora Uruchom i oceń usługę Batch dostosuj w razie potrzeby nazwę wyświetlaną Uruchom i opcjonalnie podaj opis przebiegu i tagi. Wybierz Dalej.
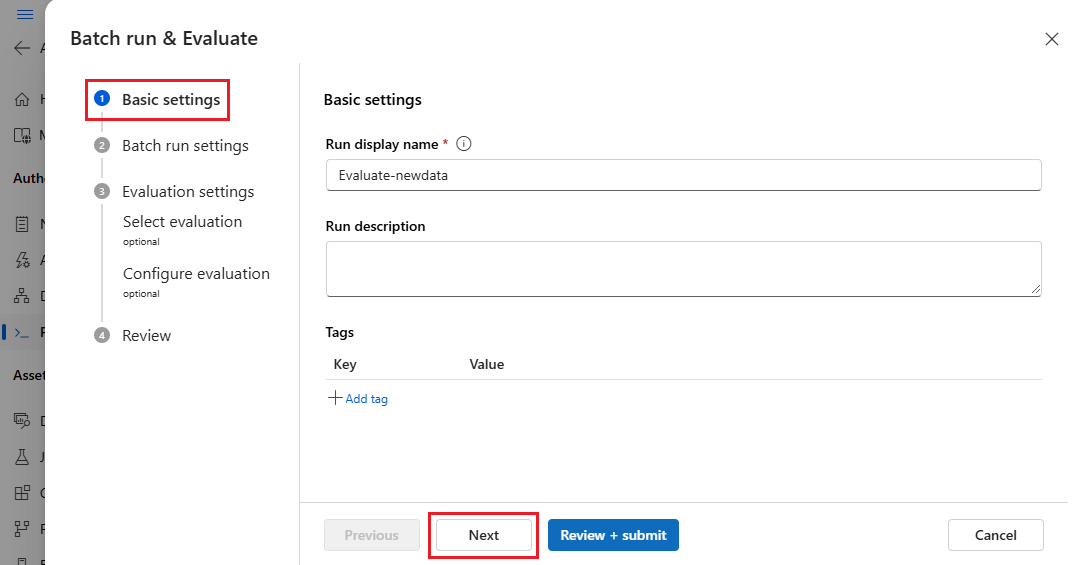
Na stronie Ustawienia uruchamiania usługi Batch wybierz zestaw danych do użycia i skonfiguruj mapowanie danych wejściowych.
Przepływ monitów obsługuje mapowanie danych wejściowych przepływu na określoną kolumnę danych w zestawie danych. Kolumnę zestawu danych można przypisać do określonych danych wejściowych przy użyciu polecenia
${data.<column>}. Jeśli chcesz przypisać stałą wartość do danych wejściowych, możesz wprowadzić wartość bezpośrednio.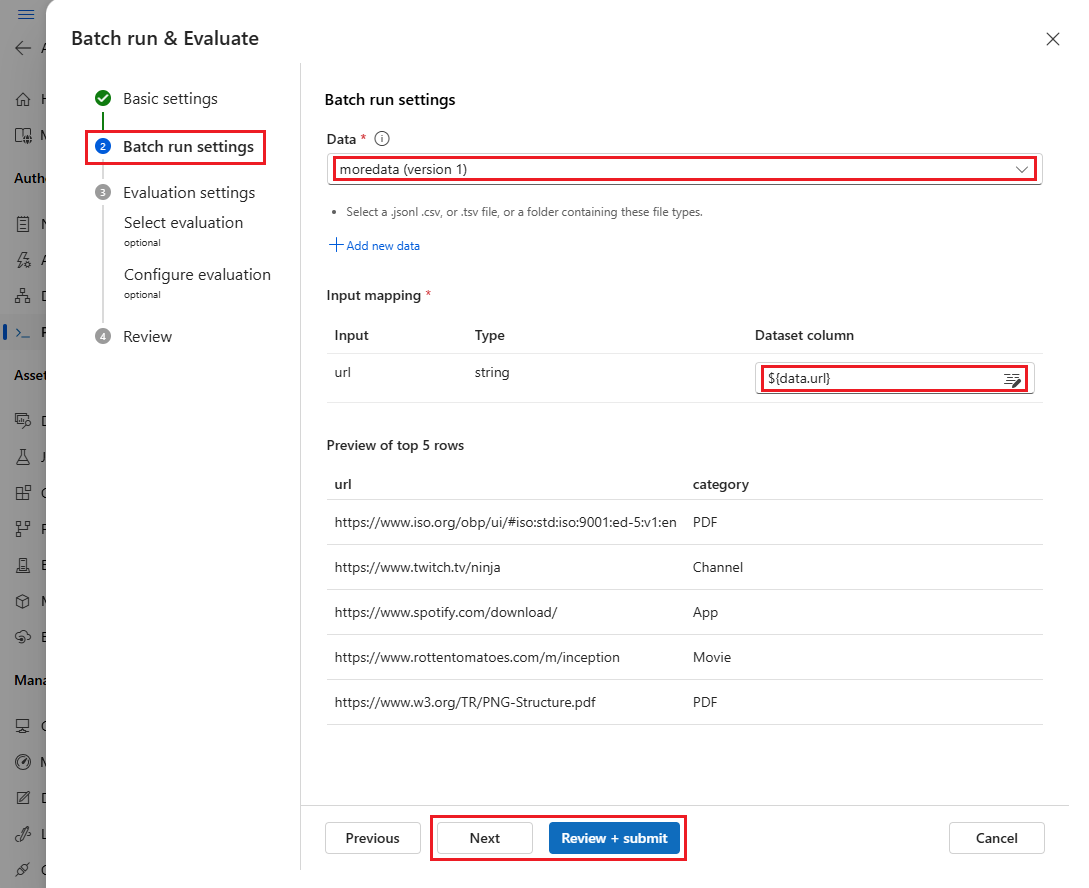
W tym momencie możesz wybrać pozycję Przejrzyj i prześlij , aby pominąć kroki oceny i uruchomić przebieg wsadowy bez użycia żadnej metody oceny. Następnie uruchomienie wsadowe generuje poszczególne dane wyjściowe dla każdego elementu w zestawie danych. Możesz ręcznie sprawdzić dane wyjściowe lub wyeksportować je w celu dalszej analizy.
W przeciwnym razie, aby użyć metody oceny w celu zweryfikowania wydajności tego przebiegu, wybierz przycisk Dalej. Można również dodać nową rundę oceny do ukończonego przebiegu wsadowego.
Na stronie Wybieranie oceny wybierz co najmniej jedną niestandardową lub wbudowaną ocenę do uruchomienia. Możesz wybrać przycisk Wyświetl szczegóły , aby wyświetlić więcej informacji o metodzie oceny, takich jak generowane metryki i wymagane połączenia i dane wejściowe.
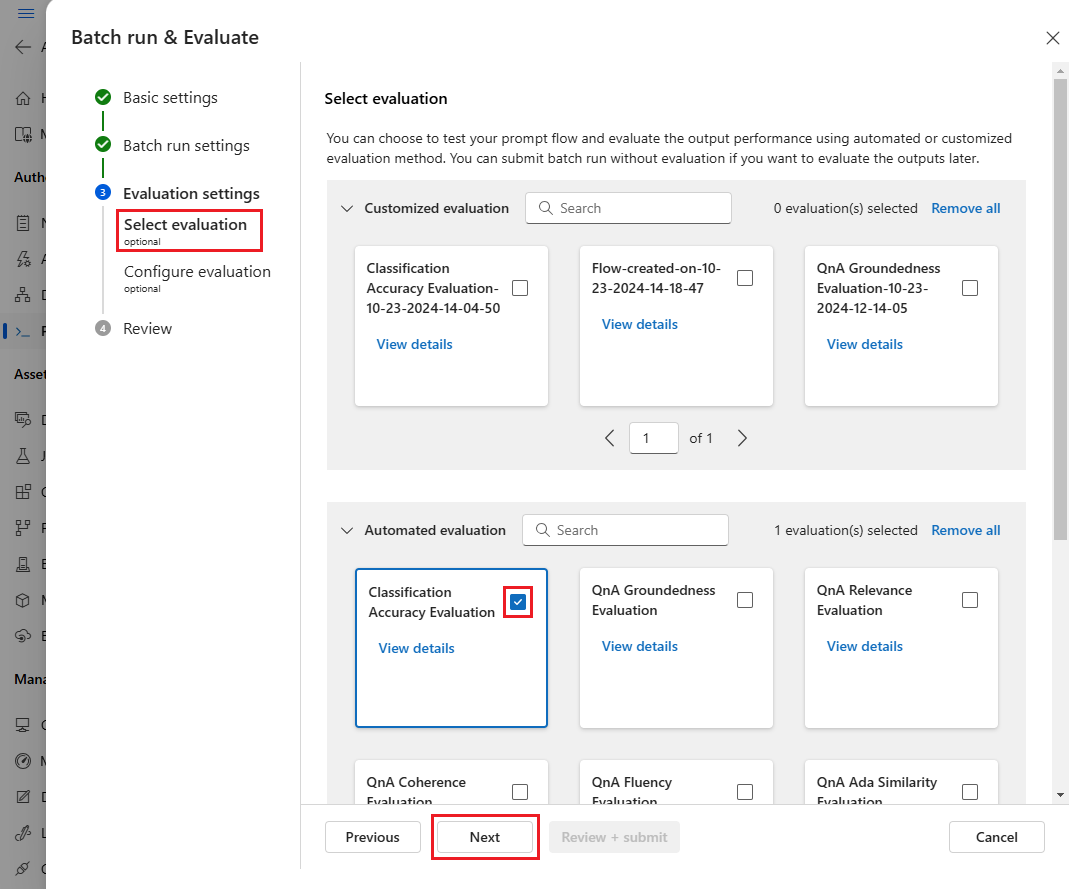
Następnie na ekranie Konfigurowanie oceny określ źródła wymaganych danych wejściowych do oceny. Na przykład kolumna podstawowej prawdy może pochodzić z zestawu danych. Domyślnie ocena używa tego samego zestawu danych co ogólny przebieg wsadowy. Jeśli jednak odpowiednie etykiety lub docelowe wartości prawdy naziemnej znajdują się w innym zestawie danych, możesz użyć tego zestawu danych.
Uwaga
Jeśli metoda oceny nie wymaga danych z zestawu danych, wybór zestawu danych jest opcjonalną konfiguracją, która nie ma wpływu na wyniki oceny. Nie musisz wybierać zestawu danych ani odwoływać się do żadnych kolumn zestawu danych w sekcji mapowania danych wejściowych.
W sekcji Mapowanie danych wejściowych oceny wskaż źródła wymaganych danych wejściowych do oceny.
- Jeśli dane pochodzą z testowego zestawu danych, ustaw źródło jako
${data.[ColumnName]}. - Jeśli dane pochodzą z danych wyjściowych przebiegu, ustaw źródło jako
${run.outputs.[OutputName]}.
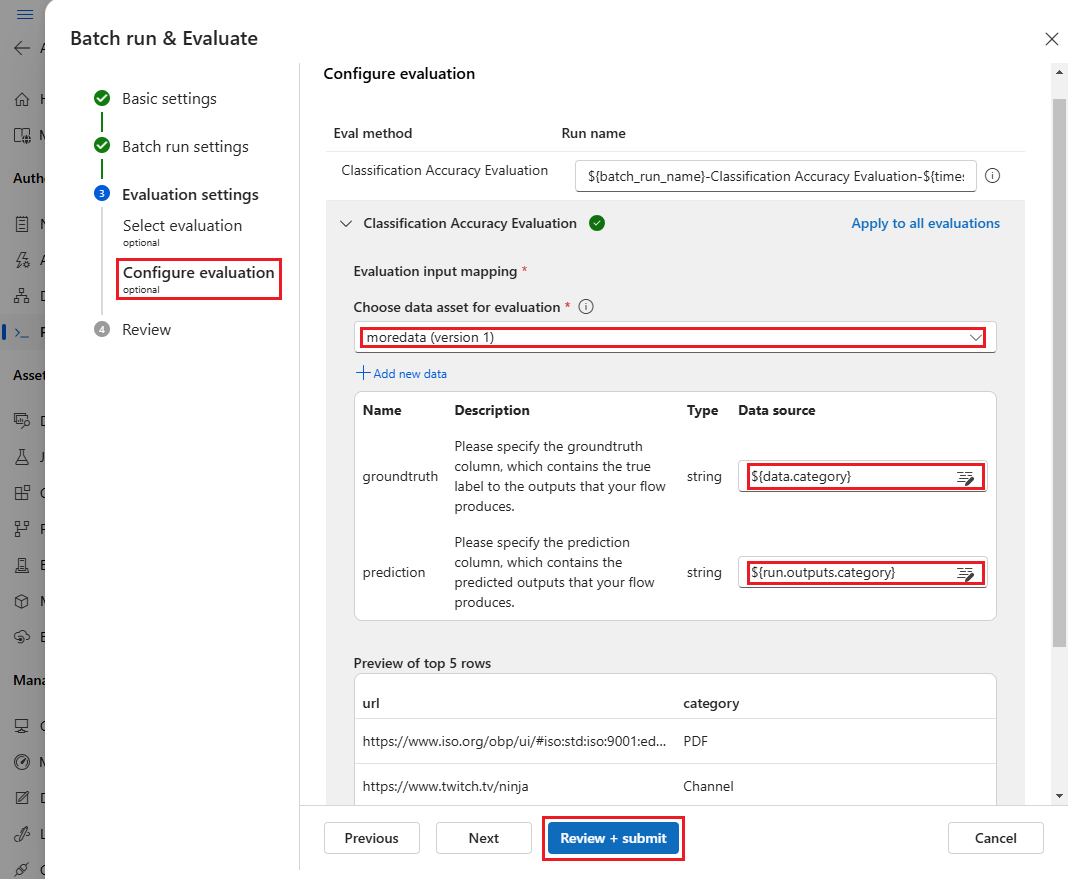
- Jeśli dane pochodzą z testowego zestawu danych, ustaw źródło jako
Niektóre metody oceny wymagają dużych modeli językowych(LLM), takich jak GPT-4 lub GPT-3, lub wymagają innych połączeń do korzystania z poświadczeń lub kluczy. W przypadku tych metod należy wprowadzić dane połączenia w sekcji Połączenie w dolnej części tego ekranu, aby móc korzystać z przepływu oceny. Aby uzyskać więcej informacji, zobacz Konfigurowanie połączenia.
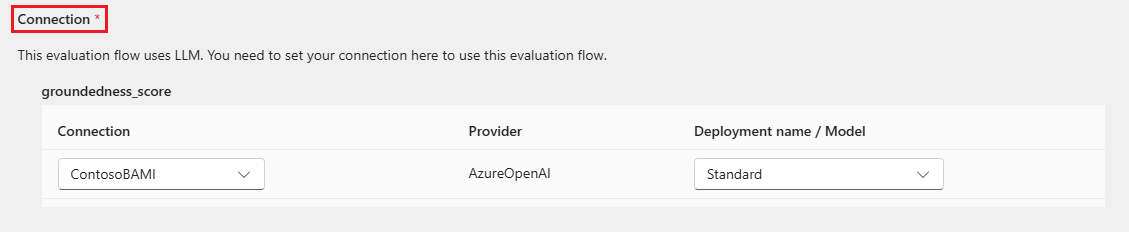
Wybierz pozycję Przejrzyj i prześlij , aby przejrzeć ustawienia, a następnie wybierz pozycję Prześlij , aby rozpocząć uruchamianie wsadowe z oceną.






Uwaga
- Niektóre procesy oceny używają wielu tokenów, dlatego zaleca się użycie modelu, który może obsługiwać >tokeny =16 tys.
- Przebiegi wsadowe mają maksymalny czas trwania 10 godzin. Jeśli przebieg wsadowy przekroczy ten limit, zostanie zakończony i będzie wyświetlany jako niepowodzenie. Monitoruj pojemność usługi LLM, aby uniknąć ograniczania przepustowości. W razie potrzeby rozważ zmniejszenie rozmiaru danych. Jeśli nadal masz problemy, prześlij formularz opinii lub wniosek o pomoc techniczną.
Wyświetlanie wyników i metryk oceny
Listę przesłanych uruchomień wsadowych można znaleźć na karcie Uruchomienia na stronie Przepływ monitu usługi Azure Machine Learning Studio.
Aby sprawdzić wyniki przebiegu wsadowego, wybierz przebieg, a następnie wybierz pozycję Visualize outputs (Wizualizuj dane wyjściowe).
Na ekranie Wizualizacja danych wyjściowych sekcja Uruchomienia i metryki zawiera ogólne wyniki dla przebiegu wsadowego i przebiegu oceny. W sekcji Dane wyjściowe przedstawiono wiersze uruchomień wejściowych według wierszy w tabeli wyników, która zawiera również metryki wierszy: Identyfikator wiersza, Uruchamianie, Stan i System.
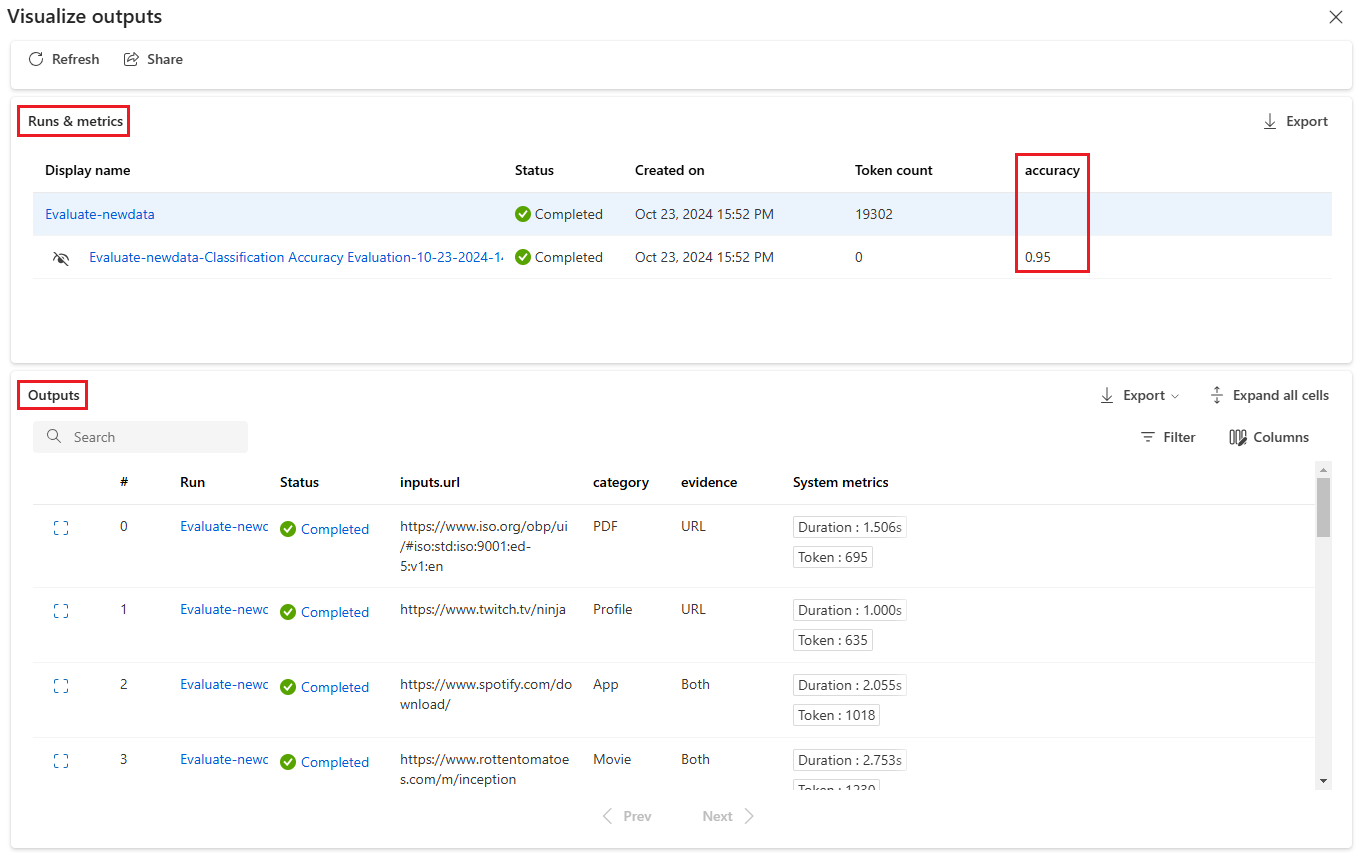
Jeśli włączysz ikonę Widok obok przebiegu oceny w sekcji Uruchomienia i metryki , w tabeli Dane wyjściowe zostanie również wyświetlony wynik oceny lub ocena dla każdego wiersza.
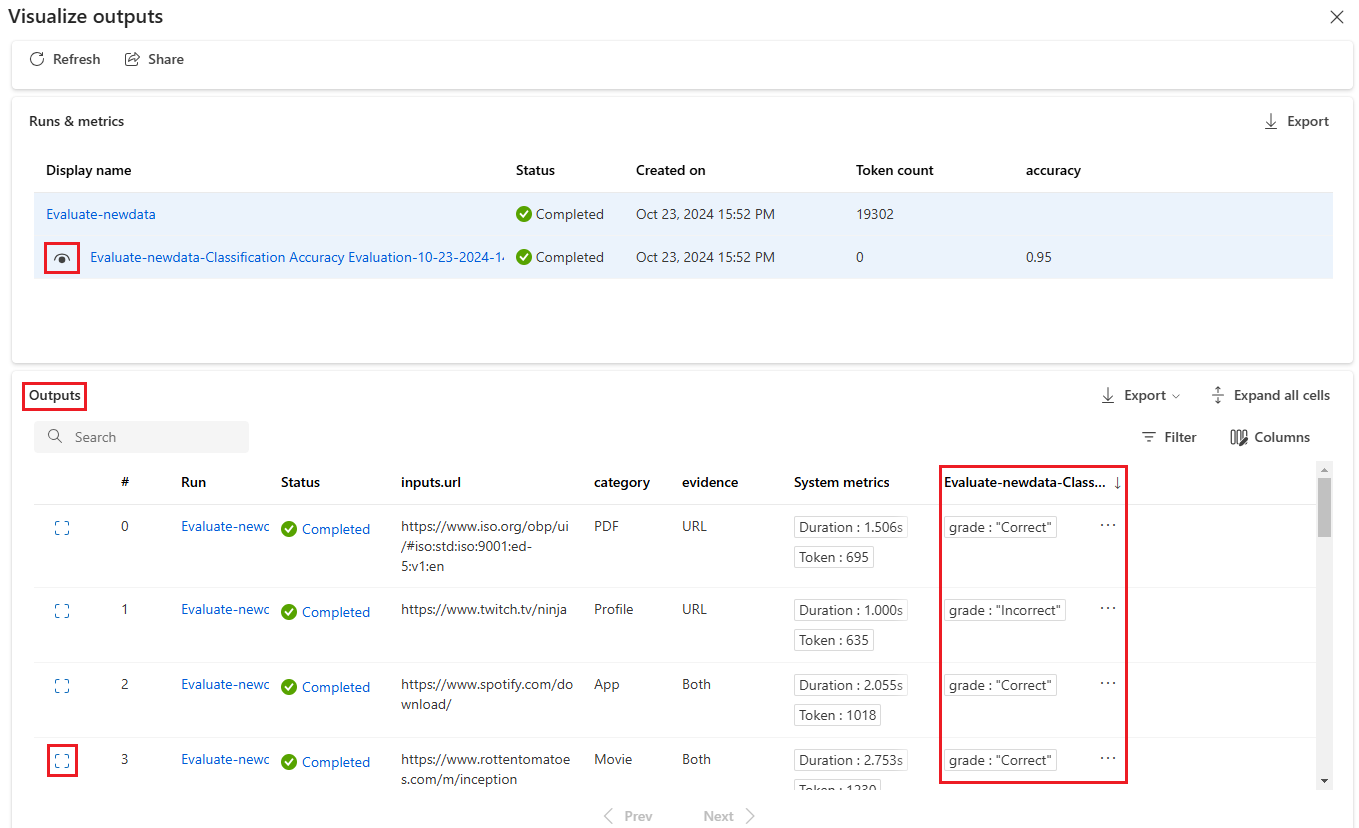
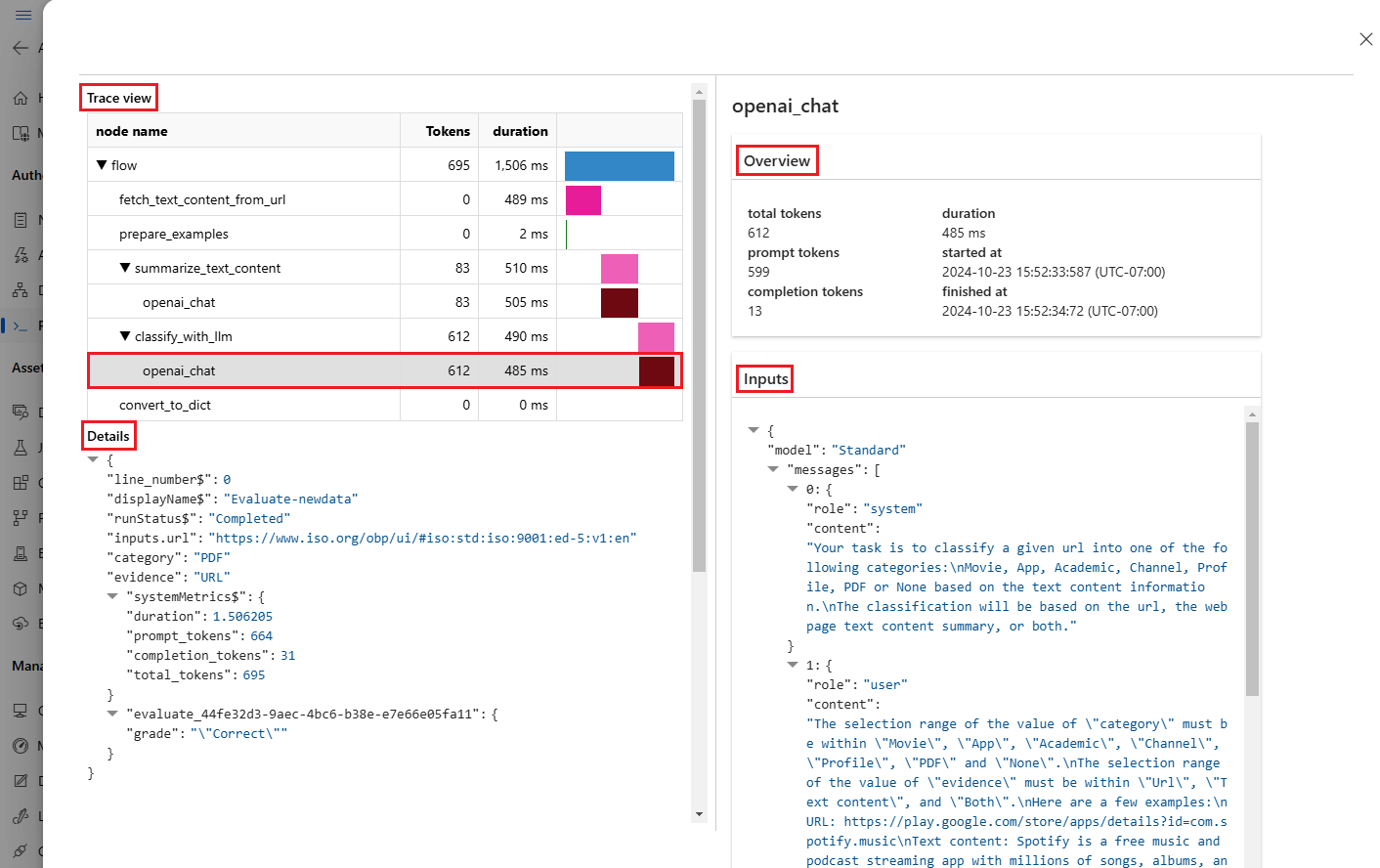
Wybierz ikonę Wyświetl szczegóły obok każdego wiersza w tabeli Dane wyjściowe , aby obserwować i debugować widok Ślad i Szczegóły dla tego przypadku testowego. Widok Ślad zawiera informacje, takie jak liczba tokenów i czas trwania dla tego przypadku. Rozwiń i wybierz dowolny krok, aby wyświetlić przegląd i dane wejściowe dla tego kroku.




Możesz również wyświetlić wyniki przebiegu oceny z poziomu przetestowanego przepływu monitu. W obszarze Wyświetl uruchomienia wsadowe wybierz pozycję Wyświetl uruchomienia wsadowe, aby wyświetlić listę uruchomień wsadowych dla przepływu, lub wybierz pozycję Wyświetl najnowsze dane wyjściowe uruchomienia wsadowego, aby wyświetlić dane wyjściowe dla najnowszego przebiegu.

Na liście uruchomień wsadowych wybierz nazwę przebiegu wsadowego, aby otworzyć stronę przepływu dla tego przebiegu.
Na stronie przepływu przebiegu oceny wybierz pozycję Wyświetl dane wyjściowe lub Szczegóły , aby wyświetlić szczegóły przepływu. Możesz również sklonować przepływ, aby utworzyć nowy przepływ lub wdrożyć go jako punkt końcowy online.

Na ekranie Szczegóły :
Karta Przegląd zawiera kompleksowe informacje o przebiegu, w tym właściwości przebiegu, wejściowy zestaw danych, wyjściowy zestaw danych, tagi i opis.
Karta Dane wyjściowe zawiera podsumowanie wyników w górnej części strony, a następnie tabelę wyników uruchamiania wsadowego . Jeśli wybierzesz przebieg oceny obok pozycji Dołącz powiązane wyniki, w tabeli będą również wyświetlane wyniki przebiegu oceny.
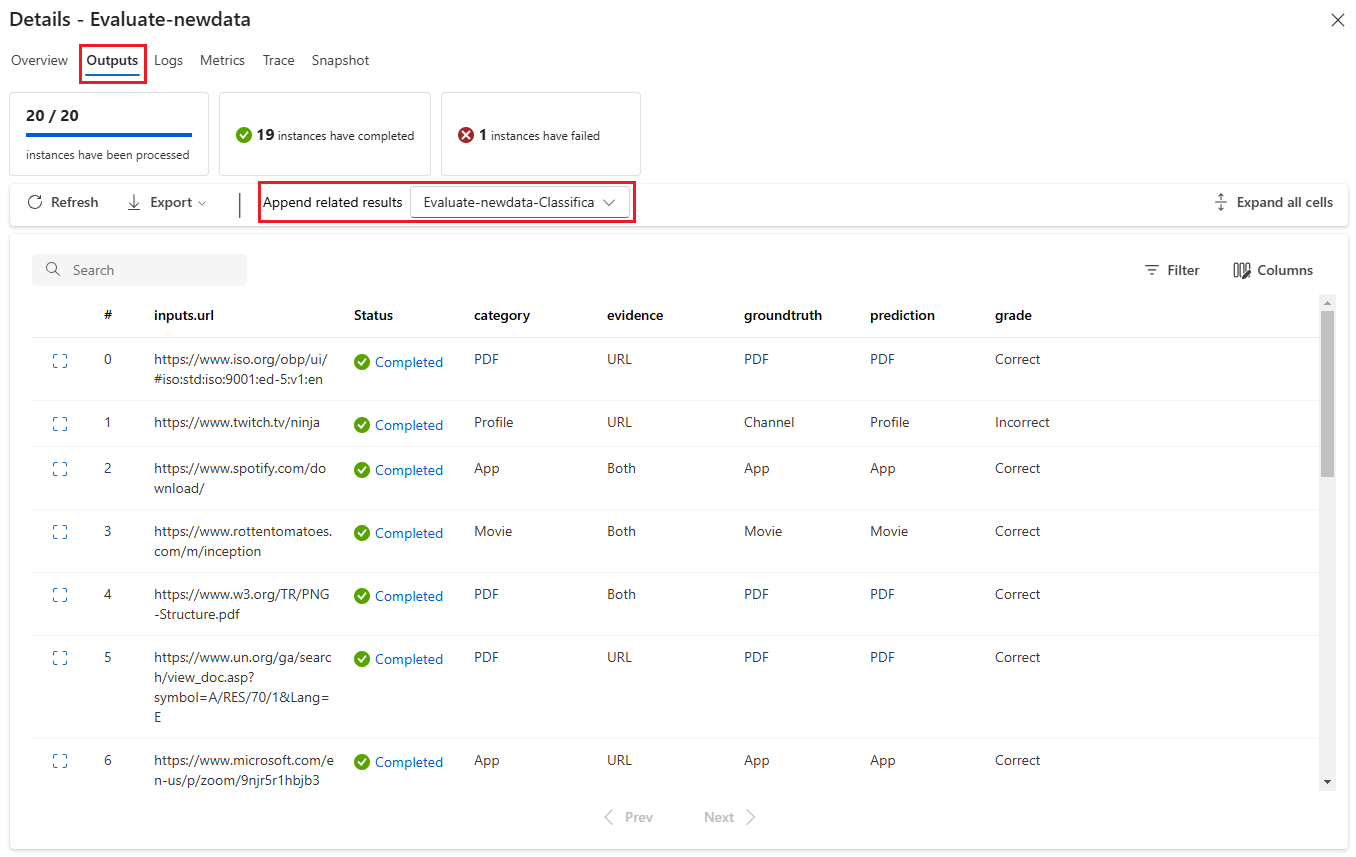
Na karcie Dzienniki są wyświetlane dzienniki uruchamiania, które mogą być przydatne do szczegółowego debugowania błędów wykonywania. Możesz pobrać pliki dziennika.
Karta Metryki zawiera link do metryk przebiegu.
Karta Śledzenie zawiera szczegółowe informacje, takie jak liczba tokenów i czas trwania każdego przypadku testowego. Rozwiń i wybierz dowolny krok, aby wyświetlić przegląd i dane wejściowe dla tego kroku.
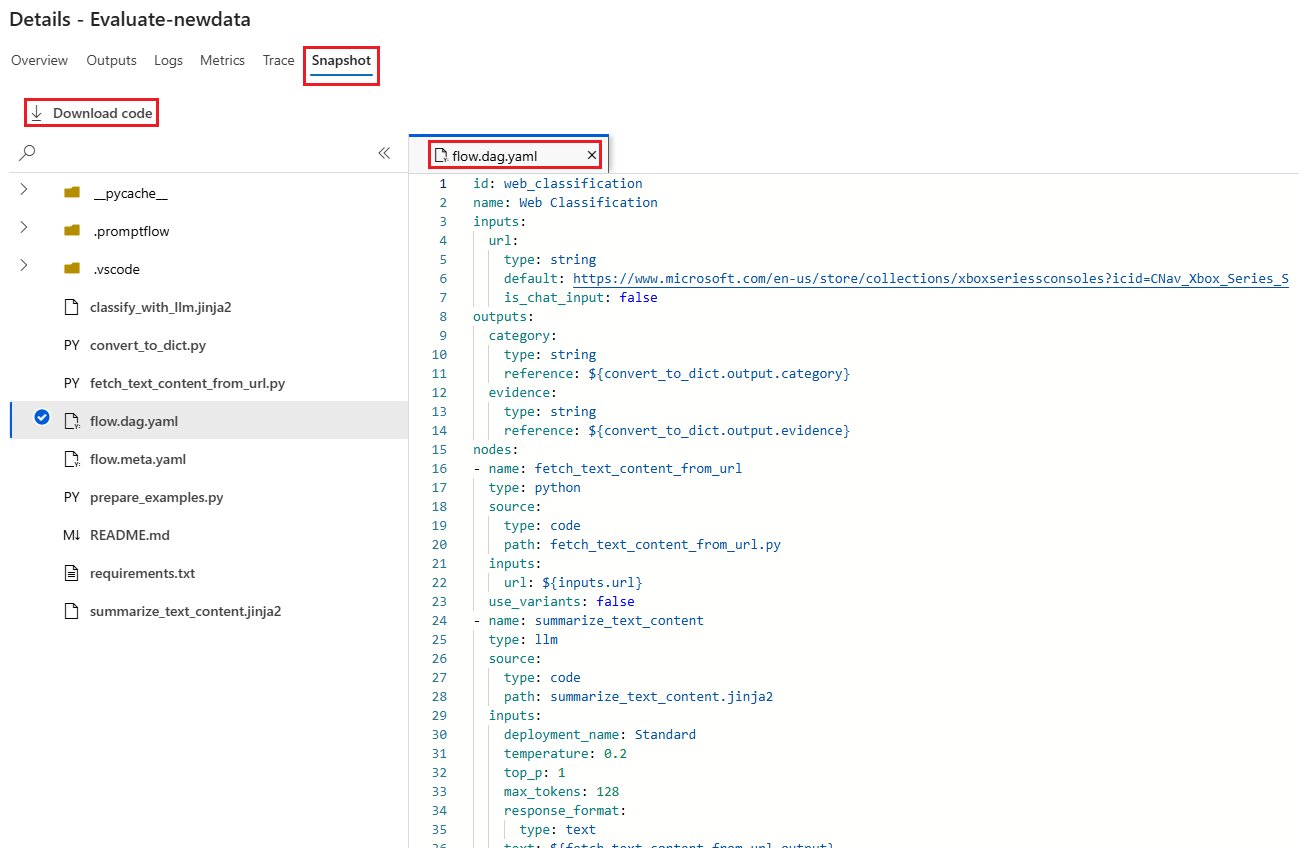
Na karcie Migawka są wyświetlane pliki i kod z przebiegu. Możesz wyświetlić definicję przepływu flow.dag.yaml i pobrać dowolne pliki.


Uruchom nową rundę oceny dla tego samego przebiegu
Możesz uruchomić nową rundę oceny, aby obliczyć metryki dla ukończonego przebiegu wsadowego bez ponownego uruchomienia przepływu. Ten proces pozwala zaoszczędzić koszt ponownego uruchamiania przepływu i jest przydatny w następujących scenariuszach:
- Nie wybrano metody oceny podczas przesyłania przebiegu wsadowego, a teraz chcesz ocenić wydajność uruchamiania.
- Użyto metody oceny do obliczenia określonej metryki, a teraz chcesz obliczyć inną metrykę.
- Poprzedni przebieg oceny zakończył się niepowodzeniem, ale przebieg wsadowy pomyślnie wygenerował dane wyjściowe i chcesz ponowić próbę oceny.
Aby rozpocząć kolejną rundę oceny, wybierz pozycję Oceń w górnej części strony przepływu przebiegu wsadowego. Zostanie otwarty kreator Nowa ocena na ekranie Wybieranie oceny . Ukończ instalację i prześlij nowy przebieg oceny.
Nowy przebieg zostanie wyświetlony na liście Przebieg przepływu monitu i można wybrać więcej niż jeden wiersz na liście, a następnie wybrać pozycję Visualize outputs (Wizualizacja danych wyjściowych), aby porównać dane wyjściowe i metryki.
Porównanie historii i metryk przebiegu oceny
Jeśli zmodyfikujesz przepływ w celu zwiększenia wydajności, możesz przesłać wiele przebiegów wsadowych w celu porównania wydajności różnych wersji przepływu. Możesz również porównać metryki obliczane przez różne metody oceny, aby zobaczyć, która metoda jest bardziej odpowiednia dla przepływu.
Aby sprawdzić historię przebiegów wsadowych przepływu, wybierz pozycję Wyświetl uruchomienia wsadowe w górnej części strony przepływu. Możesz wybrać każdy przebieg, aby sprawdzić szczegóły. Możesz również wybrać wiele przebiegów i wybrać pozycję Wizualizuj dane wyjściowe, aby porównać metryki i dane wyjściowe tych przebiegów.

Omówienie wbudowanych metryk oceny
Przepływ monitów usługi Azure Machine Learning udostępnia kilka wbudowanych metod oceny, które ułatwiają mierzenie wydajności danych wyjściowych przepływu. Każda metoda oceny oblicza różne metryki. W poniższej tabeli opisano dostępne wbudowane metody oceny.
| Metoda oceny | Metryczne | opis | Wymagane połączenie? | Wymagane dane wejściowe | Ocenianie wartości |
|---|---|---|---|---|---|
| Ocena dokładności klasyfikacji | Dokładność | Mierzy wydajność systemu klasyfikacji, porównując swoje dane wyjściowe z prawem do podstawy | Nie. | przewidywanie, prawda naziemna | W zakresie [0, 1] |
| Ocena podstaw pytań i odpowiedzi | Uziemienie | Mierzy sposób uziemienia przewidywanych odpowiedzi modelu w źródle wejściowym. Nawet jeśli odpowiedzi LLM są dokładne, są one nieprzyziemne, jeśli nie są weryfikowalne względem źródła. | Tak | pytanie, odpowiedź, kontekst (bez prawdy podstawowej) | od 1 do 5, z 1 = najgorsze i 5 = najlepsze |
| Ocena podobieństwa QnA GPT | Podobieństwo GPT | Mierzy podobieństwo między odpowiedziami podstaw dostarczonymi przez użytkownika a przewidywaną odpowiedzią modelu GPT | Tak | pytanie, odpowiedź, prawda naziemna (kontekst nie jest potrzebny) | od 1 do 5, z 1 = najgorsze i 5 = najlepsze |
| Ocena istotności pytań i oceny | Stopień zgodności | Mierzy, jak istotne są przewidywane odpowiedzi modelu na pytania zadawane | Tak | pytanie, odpowiedź, kontekst (bez prawdy podstawowej) | od 1 do 5, z 1 = najgorsze i 5 = najlepsze |
| Ocena spójności usługi QnA | Spójności | Mierzy jakość wszystkich zdań w przewidywanej odpowiedzi modelu i sposób ich dopasowania naturalnie | Tak | pytanie, odpowiedź (bez podstawowej prawdy lub kontekstu) | od 1 do 5, z 1 = najgorsze i 5 = najlepsze |
| Ocena fluency QnA | Płynność | Mierzy poprawność gramatyczną i językową przewidywanej odpowiedzi modelu | Tak | pytanie, odpowiedź (bez podstawowej prawdy lub kontekstu) | od 1 do 5, z 1 = najgorsze i 5 = najlepsze |
| Ocena wyników QnA F1 | Wynik F1 | Mierzy stosunek liczby wspólnych wyrazów między przewidywaniem modelu a prawem do podstawy | Nie. | pytanie, odpowiedź, prawda naziemna (kontekst nie jest potrzebny) | W zakresie [0, 1] |
| Ocena podobieństwa QnA Ada | Podobieństwo Ada | Obliczenia osadzania na poziomie zdania (dokumentu) przy użyciu interfejsu API osadzania Ada na potrzeby zarówno prawdy podstawowej, jak i przewidywania, a następnie oblicza podobieństwo cosinus między nimi (jedna liczba zmiennoprzecinkowa) | Tak | pytanie, odpowiedź, prawda naziemna (kontekst nie jest potrzebny) | W zakresie [0, 1] |
Zwiększanie wydajności przepływu
Jeśli przebieg zakończy się niepowodzeniem, sprawdź dane wyjściowe i dane dziennika oraz debuguj wszelkie błędy przepływu. Aby naprawić przepływ lub poprawić wydajność, spróbuj zmodyfikować wiersz przepływu, komunikat systemowy, parametry przepływu lub logikę przepływu.
Inżynieria poleceń
Budowa monitów może być trudna. Aby dowiedzieć się więcej o pojęciach związanych z tworzeniem monitów, zobacz Omówienie monitów. Aby dowiedzieć się, jak utworzyć monit, który może pomóc w osiągnięciu celów, zobacz Monituj techniki inżynieryjne.
Komunikat systemowy
Można użyć komunikatu systemowego, czasami określanego jako metaprompt lub monit systemowy, aby kierować zachowaniem systemu sztucznej inteligencji i poprawić wydajność systemu. Aby dowiedzieć się, jak poprawić wydajność przepływu za pomocą komunikatów systemowych, zobacz Tworzenie komunikatów systemowych krok po kroku.
Złote zestawy danych
Tworzenie copilot, który używa llMs zwykle obejmuje uziemienie modelu w rzeczywistości przy użyciu źródłowych zestawów danych. Złoty zestaw danych pomaga zapewnić, że moduły LLM zapewniają najbardziej dokładne i przydatne odpowiedzi na zapytania klientów.
Złoty zestaw danych to zbiór realistycznych pytań klientów i fachowo spreparowane odpowiedzi, które służą jako narzędzie do zapewniania jakości dla llMs używanych przez policjantów. Złote zestawy danych nie są używane do trenowania modułu LLM ani wstrzykiwania kontekstu do monitu LLM, ale do oceny jakości odpowiedzi generowanych przez moduł LLM.
Jeśli twój scenariusz obejmuje copilot lub tworzysz własny copilot, zobacz Tworzenie złotych zestawów danych, aby uzyskać szczegółowe wskazówki i najlepsze rozwiązania.