Przygotowywanie danych do zadań przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Ważne
Obsługa trenowania modeli przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning to eksperymentalna funkcja publicznej wersji zapoznawczej. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Z tego artykułu dowiesz się, jak przygotować dane obrazu do trenowania modeli przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning. Aby wygenerować modele dla zadań przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego, należy wprowadzić dane z etykietami obrazów jako dane wejściowe na potrzeby trenowania modelu w postaci MLTableelementu .
Możesz utworzyć element MLTable na podstawie danych treningowych oznaczonych etykietą w formacie JSONL. Jeśli dane treningowe oznaczone etykietą mają inny format, taki jak Pascal Visual Object Classes (VOC) lub COCO, możesz użyć skryptu konwersji, aby przekonwertować je na format JSONL, a następnie utworzyć element MLTable. Alternatywnie możesz użyć narzędzia do etykietowania danych usługi Azure Machine Learning do ręcznego etykietowania obrazów. Następnie wyeksportuj dane oznaczone etykietami do użycia na potrzeby trenowania modelu rozwiązania AutoML.
Wymagania wstępne
- Zapoznaj się z akceptowanymi schematami dla plików JSONL dla eksperymentów przetwarzania obrazów automl.
Pobieranie danych oznaczonych etykietami
Aby wytrenować modele przetwarzania obrazów przy użyciu rozwiązania AutoML, musisz uzyskać etykiety danych treningowych. Obrazy muszą zostać przekazane do chmury. Adnotacje etykiet muszą być w formacie JSONL. Możesz użyć narzędzia Azure Machine Learning Data Labeling do etykietowania danych lub zacząć od wstępnie oznaczonych danych obrazów.
Używanie narzędzia do etykietowania danych usługi Azure Machine Learning w celu etykietowania danych treningowych
Jeśli nie masz wstępnie oznaczonych danych, możesz użyć narzędzia do etykietowania danych usługi Azure Machine Learning w celu ręcznego etykietowania obrazów. To narzędzie automatycznie generuje dane wymagane do trenowania w akceptowanym formacie. Aby uzyskać więcej informacji, zobacz Konfigurowanie projektu etykietowania obrazów.
Narzędzie ułatwia tworzenie i monitorowanie zadań etykietowania danych oraz zarządzanie nimi w następujących zadaniach:
- Klasyfikacja obrazów (wiele klas i wiele etykiet)
- Wykrywanie obiektów (pole ograniczenia)
- Segmentacja wystąpień (wielokąt)
Jeśli masz już etykiety danych do użycia, wyeksportuj te dane oznaczone jako zestaw danych usługi Azure Machine Learning i uzyskaj dostęp do zestawu danych na karcie Zestawy danych w usłudze Azure Machine Learning Studio. Ten wyeksportowany zestaw danych można przekazać jako dane wejściowe przy użyciu azureml:<tabulardataset_name>:<version> formatu. Aby uzyskać więcej informacji, zobacz Eksportowanie etykiet.
Oto przykład przekazywania istniejącego zestawu danych jako danych wejściowych do trenowania modeli przetwarzania obrazów.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Używanie wstępnie oznakowanych danych treningowych z komputera lokalnego
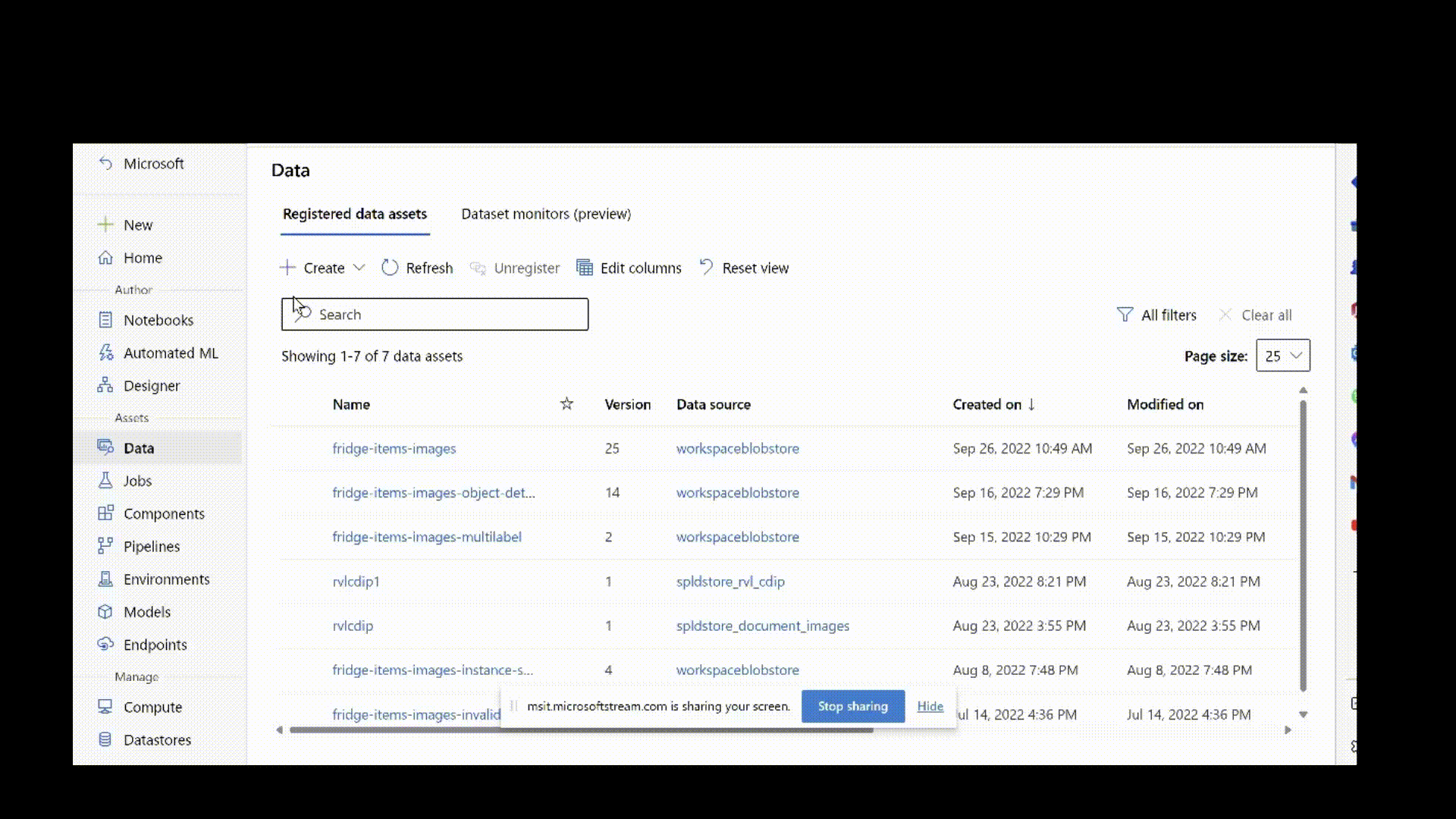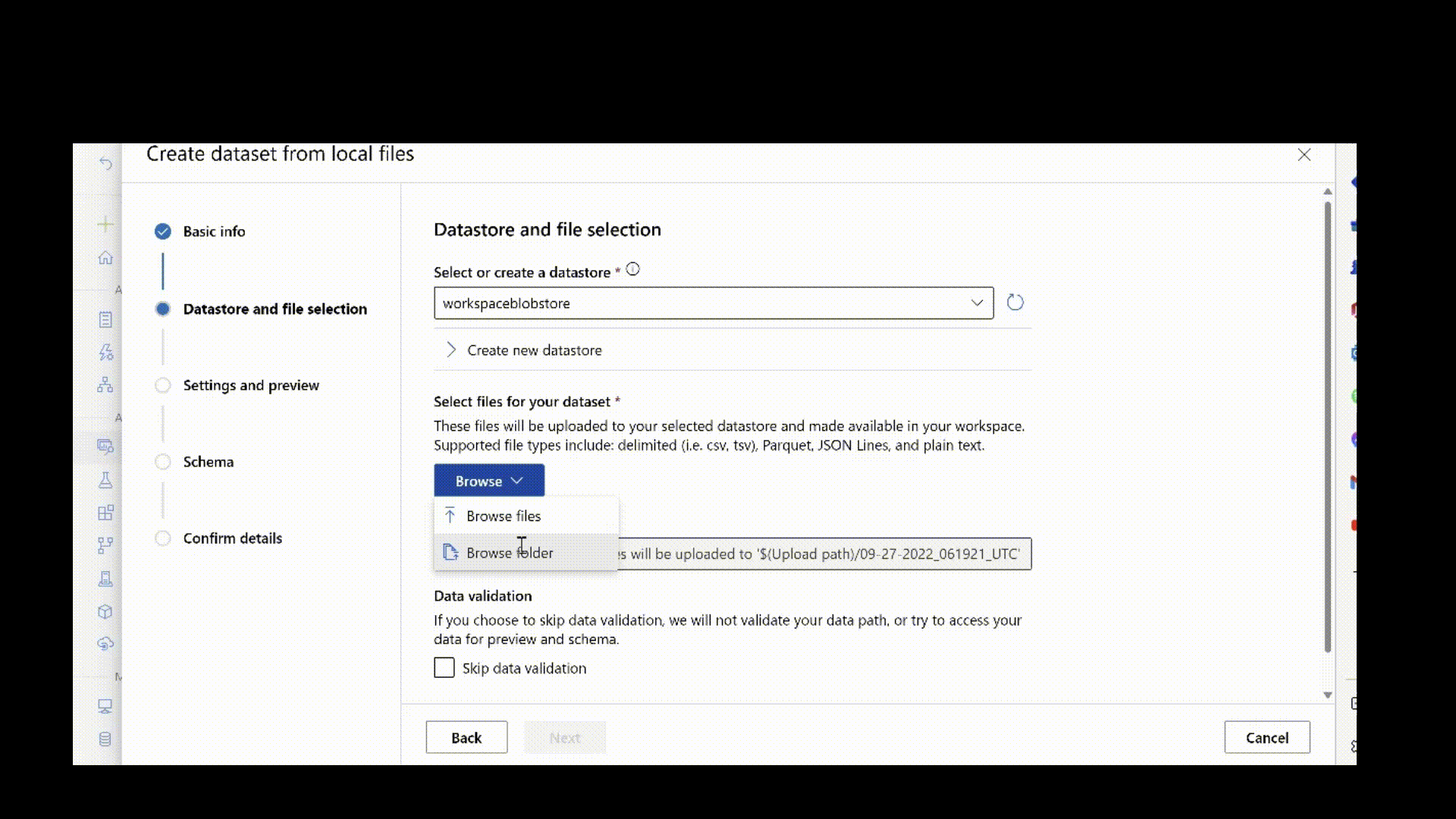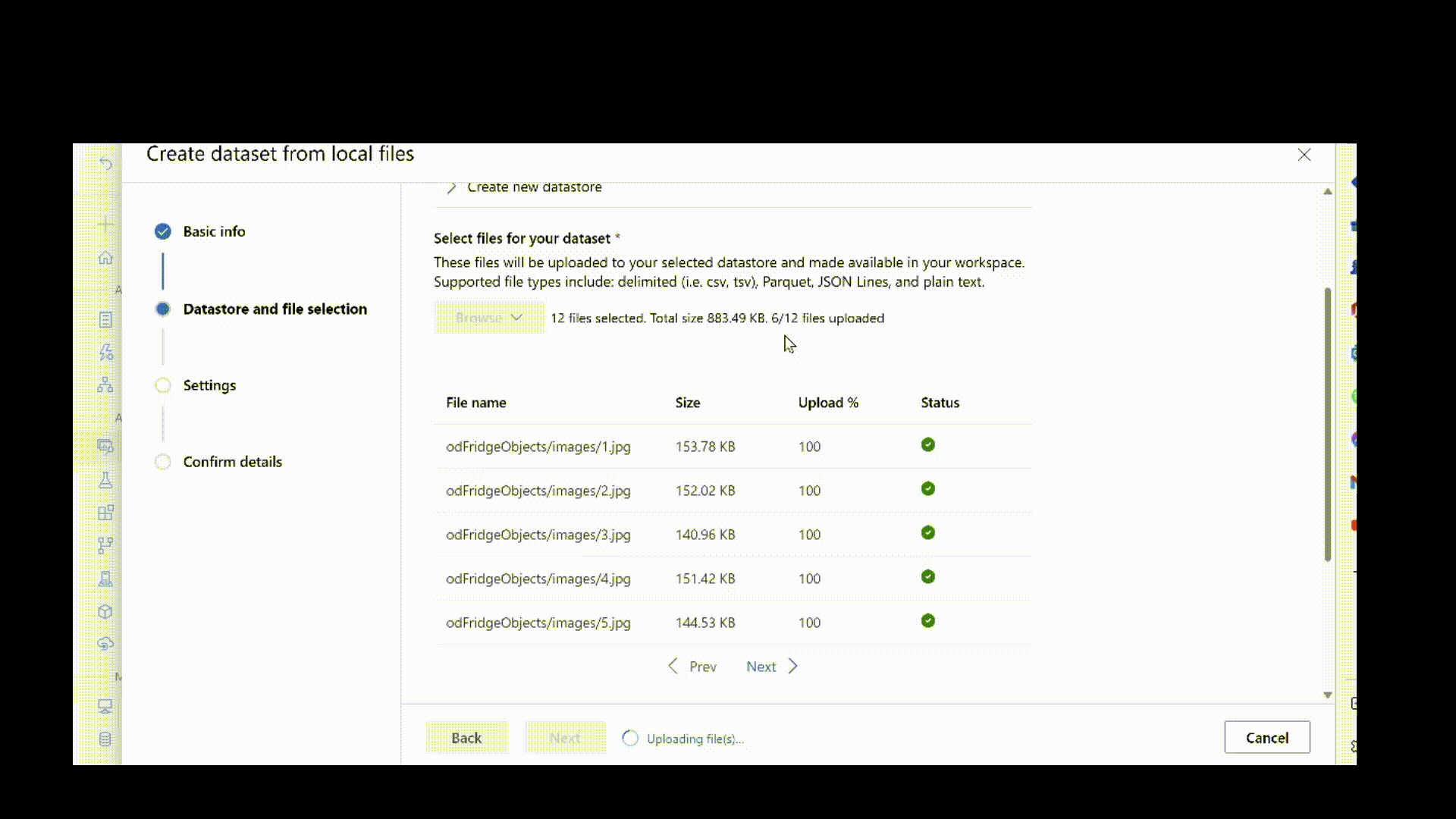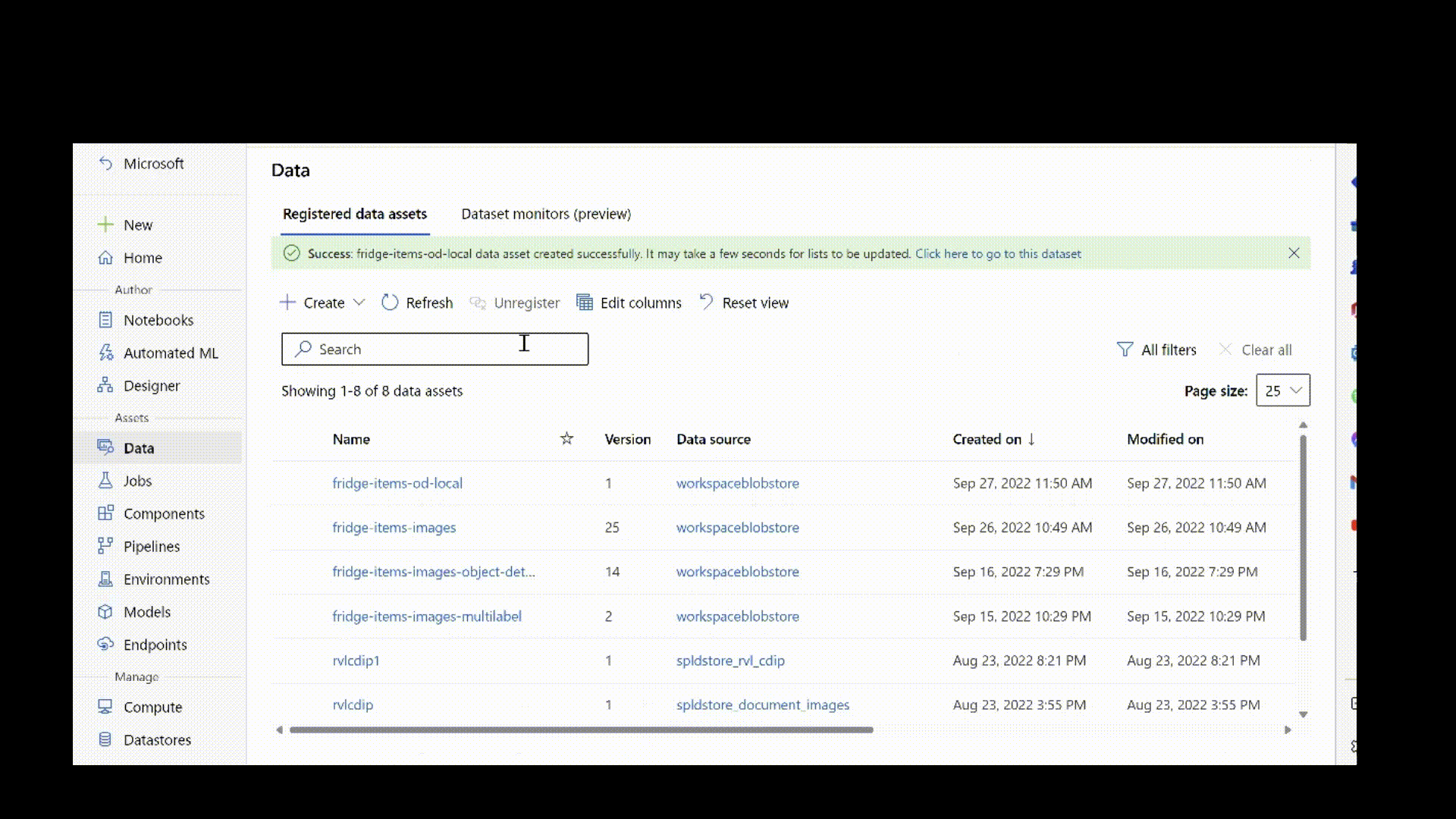
Jeśli masz oznaczone etykietami dane, których chcesz użyć do trenowania modelu, przekaż obrazy na platformę Azure. Obrazy można przekazać do domyślnej usługi Azure Blob Storage w obszarze roboczym usługi Azure Machine Learning. Zarejestruj go jako zasób danych. Aby uzyskać więcej informacji, zobacz Tworzenie zasobów danych i zarządzanie nimi.
Poniższy skrypt przekazuje dane obrazu na komputerze lokalnym w ścieżce ./data/odFridgeObjects do magazynu danych w usłudze Azure Blob Storage. Następnie tworzy nowy zasób danych o nazwie fridge-items-images-object-detection w obszarze roboczym usługi Azure Machine Learning.
Jeśli istnieje już zasób danych o nazwie fridge-items-images-object-detection w obszarze roboczym usługi Azure Machine Learning, kod aktualizuje numer wersji zasobu danych i wskazuje go na nową lokalizację, w której przekazano dane obrazu.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Utwórz plik .yml z następującą konfiguracją.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Aby przekazać obrazy jako zasób danych, uruchom następujące polecenie interfejsu wiersza polecenia w wersji 2 ze ścieżką do pliku .yml , nazwy obszaru roboczego, grupy zasobów i identyfikatora subskrypcji.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Jeśli masz już dane w istniejącym magazynie danych, możesz utworzyć z niego zasób danych. Podaj ścieżkę do danych w magazynie danych zamiast ścieżki komputera lokalnego. Zaktualizuj poprzedni kod przy użyciu następującego fragmentu kodu.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Utwórz plik .yml z następującą konfiguracją.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
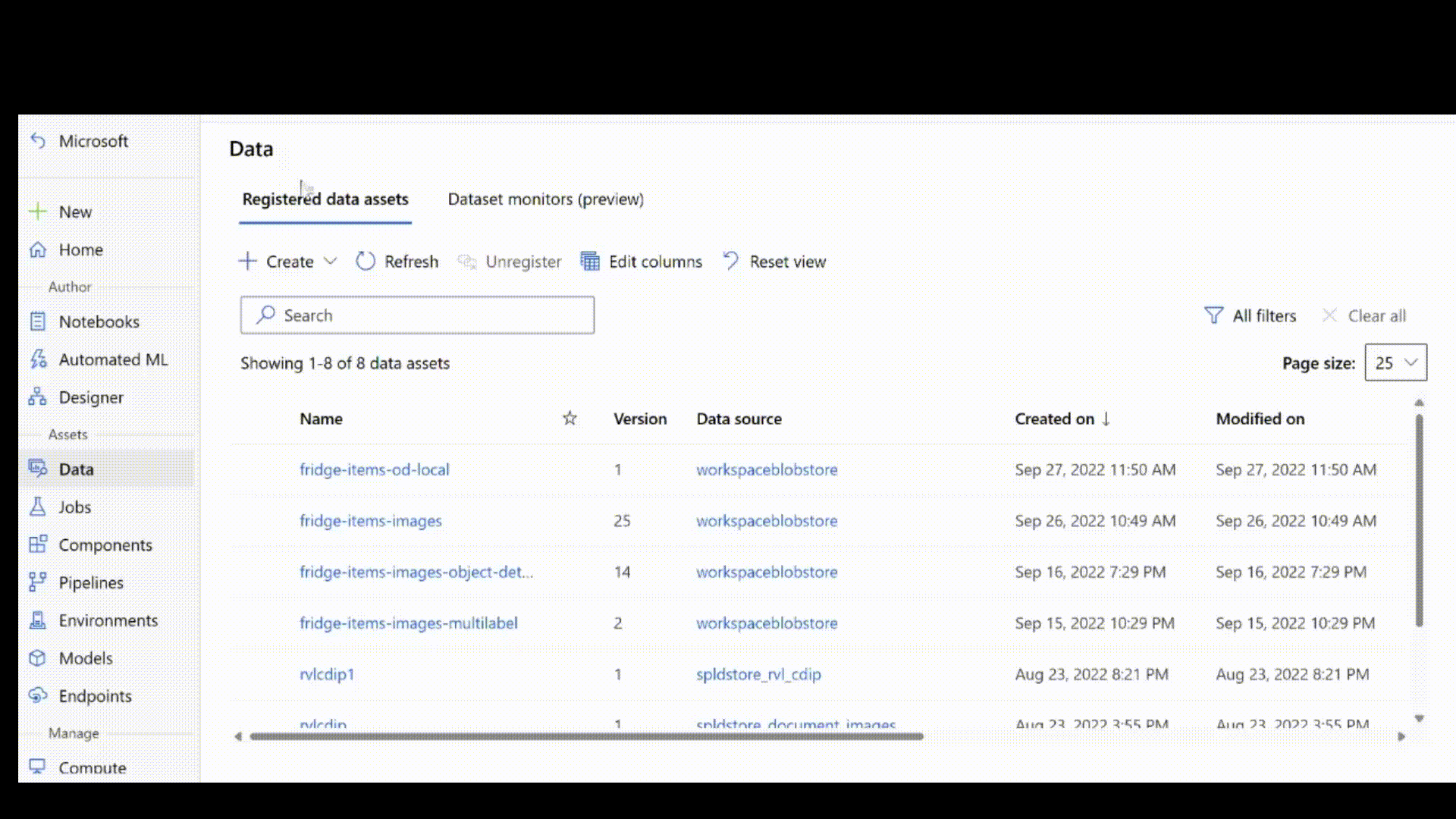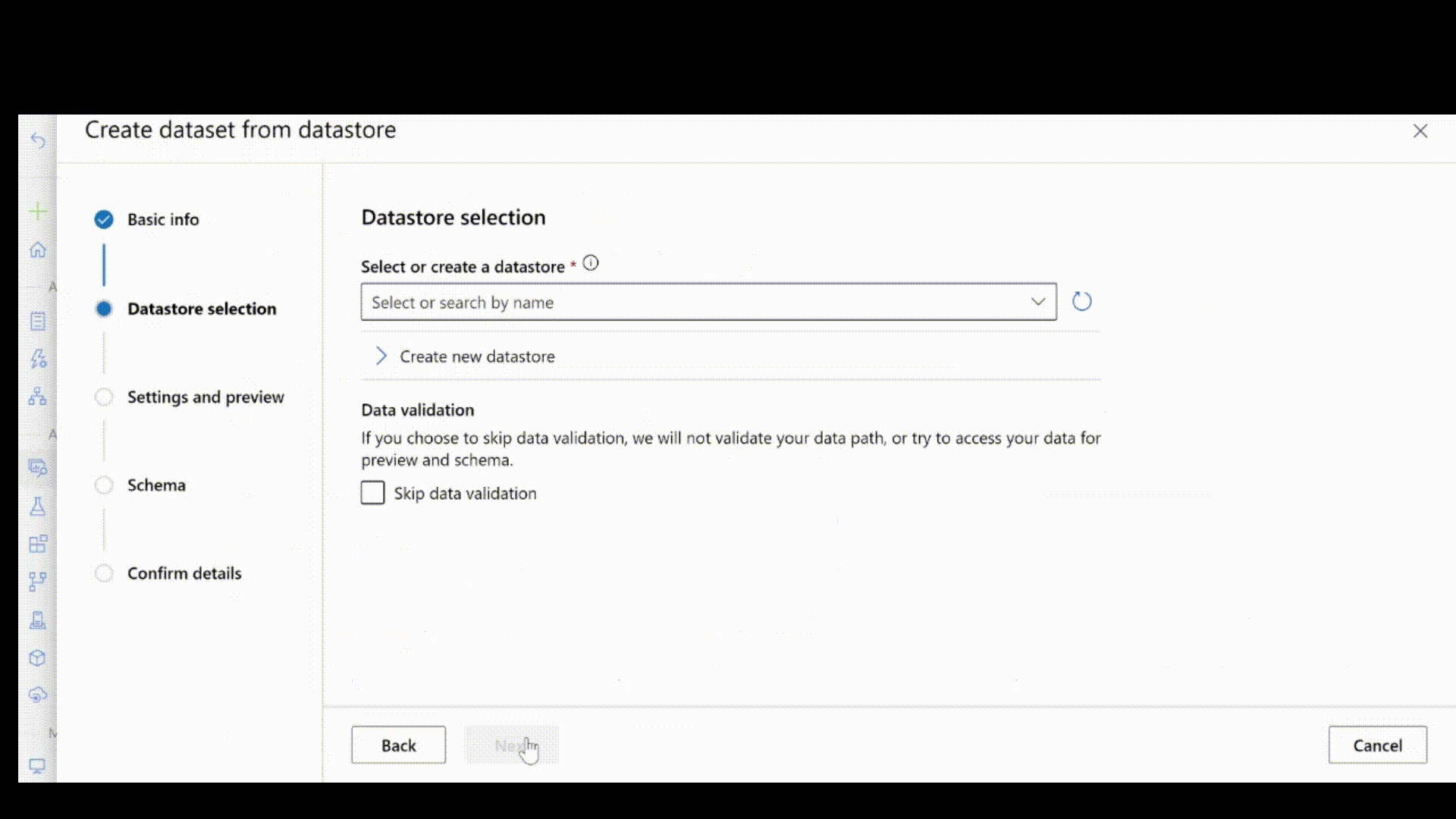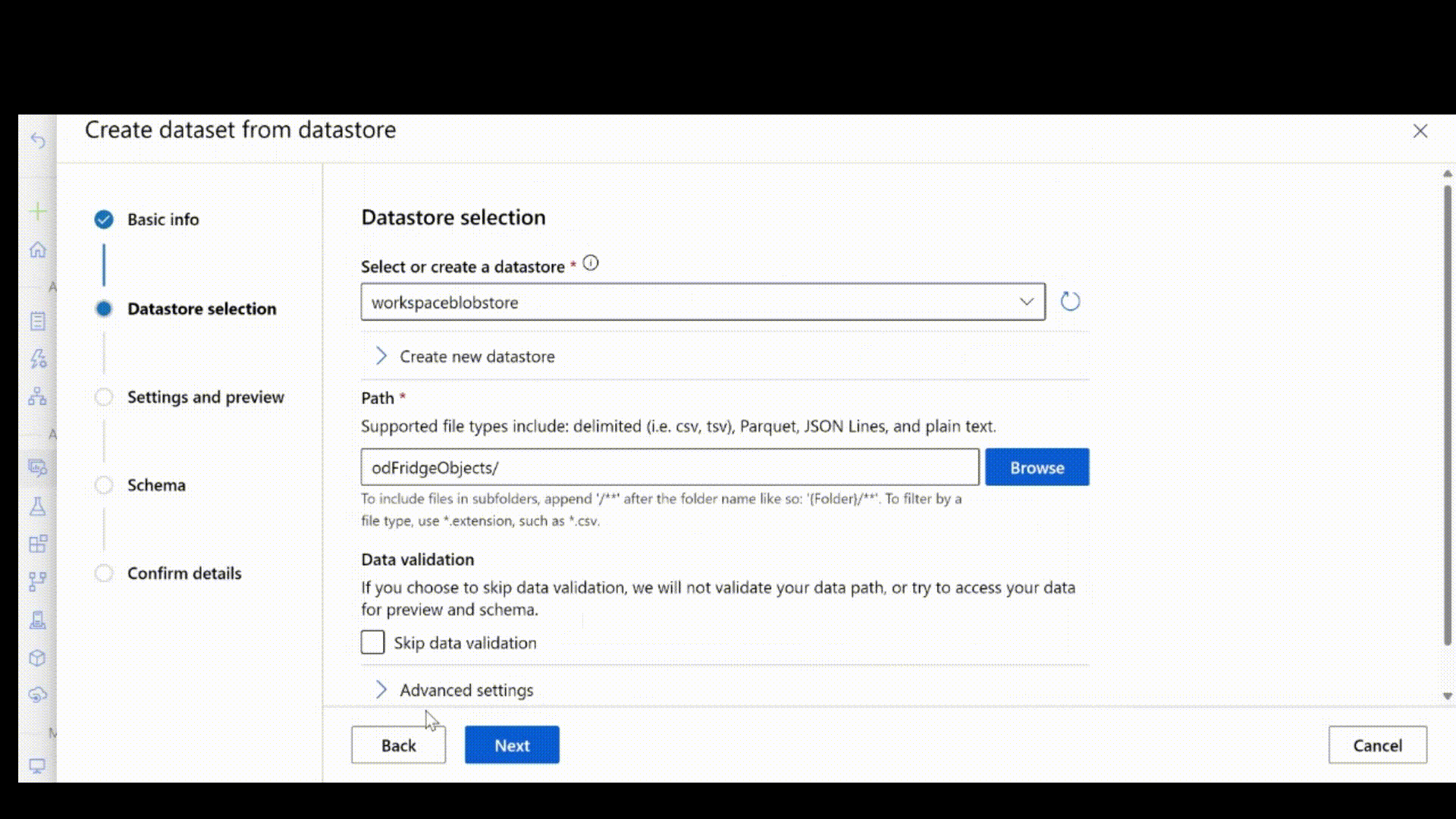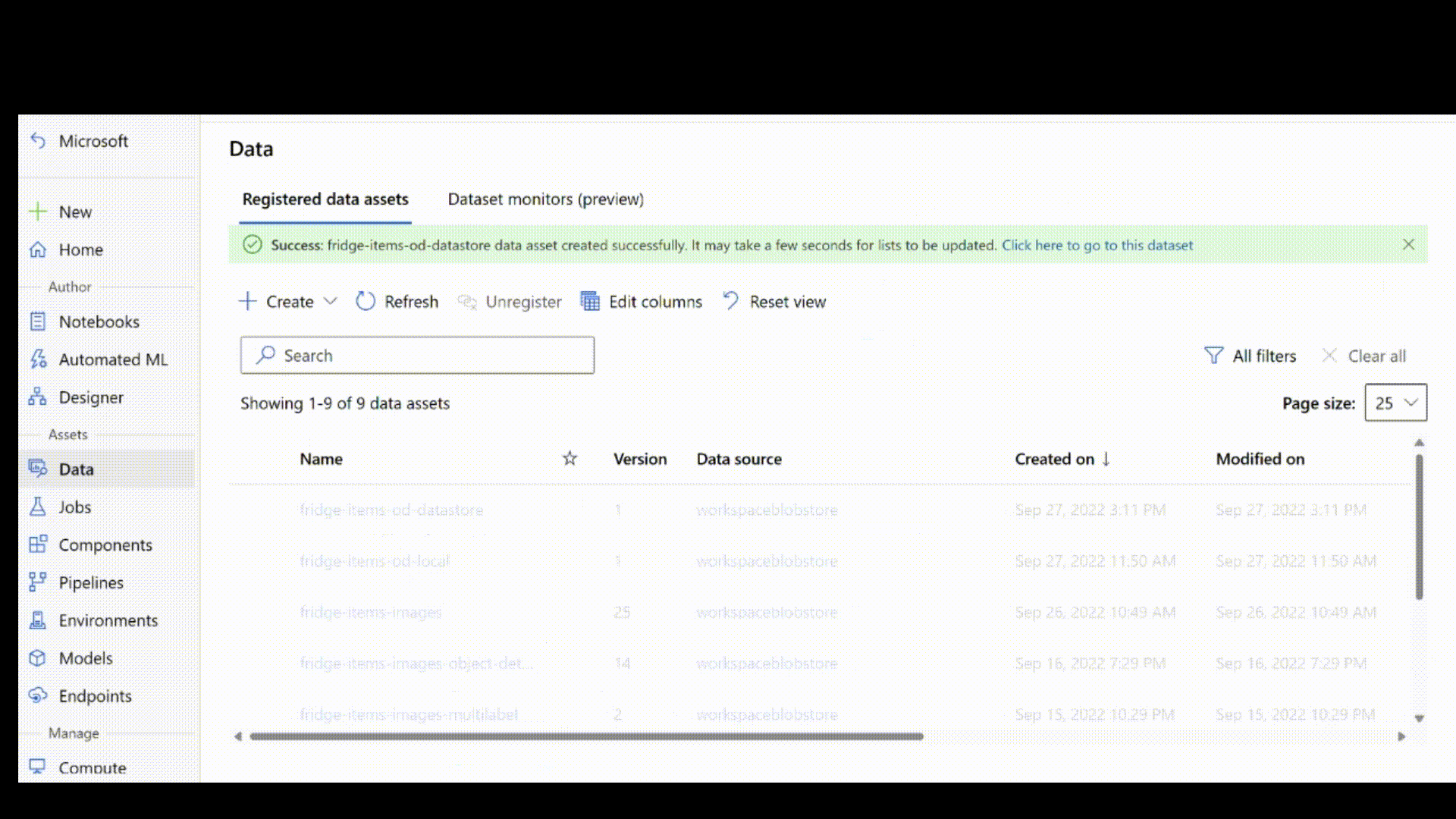
Następnie pobierz adnotacje etykiet w formacie JSONL. Schemat oznaczonych danymi zależy od zadania przetwarzania obrazów. Aby dowiedzieć się więcej o wymaganym schemacie JSONL dla każdego typu zadania, zobacz Schematy danych służące do trenowania modeli przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego.
Jeśli dane treningowe są w innym formacie, na przykład pascal VOC lub COCO, skrypty pomocnika mogą konwertować dane na format JSONL. Skrypty są dostępne w przykładach notesów.
Po utworzeniu pliku jsonl możesz zarejestrować go jako zasób danych przy użyciu interfejsu użytkownika. Upewnij się, że wybrano stream typ w sekcji schematu, jak pokazano w tej animacji.
Korzystanie ze wstępnie oznakowanych danych treningowych z usługi Azure Blob Storage
Jeśli dane szkoleniowe oznaczone etykietą znajdują się w kontenerze w usłudze Azure Blob Storage, możesz uzyskać do niego bezpośredni dostęp. Utwórz magazyn danych w tym kontenerze. Aby uzyskać więcej informacji, zobacz Tworzenie zasobów danych i zarządzanie nimi.
Tworzenie tabeli MLTable
Gdy dane oznaczone etykietą mają format JSONL, można go użyć do utworzenia MLTable , jak pokazano w tym fragmencie kodu yaml. Rozwiązanie MLtable pakuje dane do obiektu eksploatacyjnego na potrzeby trenowania.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Następnie możesz przekazać MLTable dane wejściowe jako dane dla zadania trenowania rozwiązania AutoML. Aby uzyskać więcej informacji, zobacz Konfigurowanie rozwiązania AutoML do trenowania modeli przetwarzania obrazów.