Konfigurowanie projektu etykietowania obrazów
Dowiedz się, jak tworzyć i uruchamiać projekty etykietowania danych w celu etykietowania obrazów w usłudze Azure Machine Learning. Użyj etykietowania danych wspomaganych przez uczenie maszynowe (ML) lub etykietowania w pętli człowieka, aby pomóc w zadaniu.
Konfigurowanie etykiet na potrzeby klasyfikacji, wykrywania obiektów (pola ograniczenia), segmentacji wystąpień (wielokąta) lub segmentacji semantycznej (wersja zapoznawcza).
Możesz również użyć narzędzia do etykietowania danych w usłudze Azure Machine Learning, aby utworzyć projekt etykietowania tekstu.
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie jest zalecana w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Możliwości etykietowania obrazów
Etykietowanie danych usługi Azure Machine Learning to narzędzie, za pomocą którego można tworzyć projekty etykietowania danych, zarządzać nimi i monitorować je. Jego zastosowania to:
- Koordynowanie danych, etykiet i członków zespołu w celu wydajnego zarządzania zadaniami etykietowania.
- Śledzenie postępu i utrzymywanie kolejki niekompletnych zadań etykietowania.
- Uruchom i zatrzymaj projekt i kontroluj postęp etykietowania.
- Przejrzyj i wyeksportuj oznaczone dane jako zestaw danych usługi Azure Machine Learning.
Ważne
Obrazy danych, z których pracujesz w narzędziu do etykietowania danych usługi Azure Machine Learning, muszą być dostępne w magazynie danych usługi Azure Blob Storage. Jeśli nie masz istniejącego magazynu danych, możesz przekazać pliki danych do nowego magazynu danych podczas tworzenia projektu.
Dane obrazu mogą być dowolnym plikiem, który ma jedno z następujących rozszerzeń plików:
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
Każdy plik jest elementem, który ma być oznaczony etykietą.
Zasób danych można również użyć MLTable jako danych wejściowych do projektu etykietowania obrazów, o ile obrazy w tabeli są jednym z powyższych formatów. Aby uzyskać więcej informacji, zobacz How to use data assets (Jak używać MLTable zasobów danych).
Wymagania wstępne
Te elementy służą do konfigurowania etykietowania obrazów w usłudze Azure Machine Learning:
- Dane, które chcesz oznaczyć, w plikach lokalnych lub w usłudze Azure Blob Storage.
- Zestaw etykiet, które chcesz zastosować.
- Instrukcje dotyczące etykietowania.
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Obszar roboczy usługi Azure Machine Learning. Zobacz Tworzenie obszaru roboczego usługi Azure Machine Learning.
Tworzenie projektu etykietowania obrazów
Projekty etykietowania są administrowane w usłudze Azure Machine Learning. Użyj strony Etykietowanie danych w usłudze Machine Learning, aby zarządzać projektami.
Jeśli dane są już w usłudze Azure Blob Storage, przed utworzeniem projektu etykietowania upewnij się, że są one dostępne jako magazyn danych.
Aby utworzyć projekt, wybierz pozycję Dodaj projekt.
W polu Nazwa projektu wprowadź nazwę projektu.
Nie można ponownie użyć nazwy projektu, nawet jeśli projekt zostanie usunięty.
Aby utworzyć projekt etykietowania obrazów, w polu Typ nośnika wybierz pozycję Obraz.
W polu Typ zadania Etykietowanie wybierz opcję dla danego scenariusza:
- Aby zastosować tylko pojedynczą etykietę do obrazu z zestawu etykiet, wybierz wieloklasową klasyfikację obrazów.
- Aby zastosować co najmniej jedną etykietę do obrazu z zestawu etykiet, wybierz pozycję Multi-label klasyfikacji obrazów. Na przykład zdjęcie psa może być oznaczone etykietą zarówno dla psa, jak i dnia.
- Aby przypisać etykietę do każdego obiektu na obrazie i dodać pola ograniczenia, wybierz pozycję Identyfikacja obiektu (pole ograniczenia).
- Aby przypisać etykietę do każdego obiektu na obrazie i narysować wielokąt wokół każdego obiektu, wybierz pozycję Wielokąt (segmentacja wystąpienia).
- Aby narysować maski na obrazie i przypisać klasę etykiet na poziomie pikseli, wybierz pozycję Semantyczna segmentacja (wersja zapoznawcza).
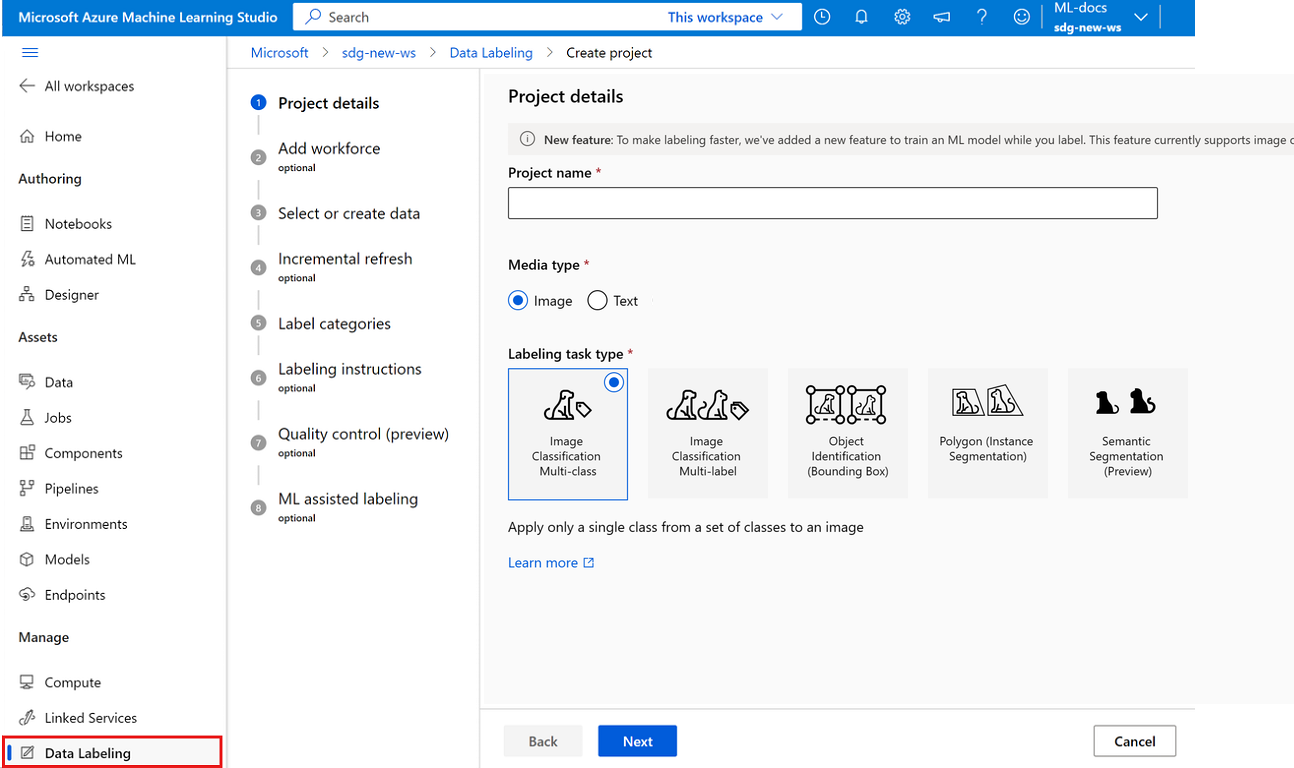
Wybierz przycisk Dalej, aby kontynuować.
Dodawanie pracowników (opcjonalnie)
Wybierz pozycję Użyj firmy etykietowania dostawcy z witryny Azure Marketplace tylko wtedy, gdy zaangażujesz firmę do etykietowania danych z witryny Azure Marketplace. Następnie wybierz dostawcę. Jeśli dostawca nie pojawi się na liście, wyczyść tę opcję.
Upewnij się, że najpierw skontaktujesz się z dostawcą i podpiszesz umowę. Aby uzyskać więcej informacji, zobacz Praca z firmą dostawcy etykiet danych (wersja zapoznawcza).
Wybierz przycisk Dalej, aby kontynuować.
Określanie danych do etykiety
Jeśli zestaw danych zawierający dane został już utworzony, wybierz zestaw danych z listy rozwijanej Wybierz istniejący zestaw danych .
Możesz również wybrać pozycję Utwórz zestaw danych , aby użyć istniejącego magazynu danych platformy Azure lub przekazać pliki lokalne.
Uwaga
Projekt nie może zawierać więcej niż 500 000 plików. Jeśli zestaw danych przekracza tę liczbę plików, ładowane są tylko pierwsze 500 000 plików.
Mapowanie kolumn danych (wersja zapoznawcza)
Jeśli wybierzesz zasób danych w formie tabeli MLTable, zostanie wyświetlony kolejny krok Mapowanie kolumny danych, który zawiera adresy URL obrazu.
Musisz określić kolumnę, która jest mapowana na pole Obraz . Możesz również opcjonalnie mapować inne kolumny, które znajdują się w danych. Jeśli na przykład dane zawierają kolumnę Etykieta , możesz je zamapować na pole Kategoria . Jeśli dane zawierają kolumnę Ufność, możesz je zamapować na pole Ufność.
Jeśli importujesz etykiety z poprzedniego projektu, etykiety muszą być w tym samym formacie co tworzone etykiety. Jeśli na przykład tworzysz etykiety pól ograniczenia, importowane etykiety muszą być również etykietami pól ograniczenia.
Opcje importu (wersja zapoznawcza)
W przypadku uwzględnienia kolumny Kategoria w kroku Mapowanie kolumny danych użyj opcji importu, aby określić sposób traktowania danych oznaczonych etykietami.
Musisz określić kolumnę, która jest mapowana na pole Obraz . Możesz również opcjonalnie mapować inne kolumny, które znajdują się w danych. Jeśli na przykład dane zawierają kolumnę Etykieta , możesz je zamapować na pole Kategoria . Jeśli dane zawierają kolumnę Ufność, możesz je zamapować na pole Ufność.
Jeśli importujesz etykiety z poprzedniego projektu, etykiety muszą być w tym samym formacie co tworzone etykiety. Jeśli na przykład tworzysz etykiety pól ograniczenia, importowane etykiety muszą być również etykietami pól ograniczenia.
Tworzenie zestawu danych na podstawie magazynu danych platformy Azure
W wielu przypadkach można przekazać pliki lokalne. Jednak Eksplorator usługi Azure Storage zapewnia szybszy i bardziej niezawodny sposób transferu dużej ilości danych. Zalecamy Eksplorator usługi Storage jako domyślny sposób przenoszenia plików.
Aby utworzyć zestaw danych na podstawie danych, które są już przechowywane w usłudze Blob Storage:
- Wybierz pozycję Utwórz.
- W polu Nazwa wprowadź nazwę zestawu danych. Możesz również wprowadzić opis.
- Upewnij się, że typ zestawu danych jest ustawiony na Wartość Plik. Tylko typy zestawów danych plików są obsługiwane w przypadku obrazów.
- Wybierz Dalej.
- Wybierz pozycję Z usługi Azure Storage, a następnie wybierz pozycję Dalej.
- Wybierz magazyn danych, a następnie wybierz pozycję Dalej.
- Jeśli dane są w podfolderze w usłudze Blob Storage, wybierz pozycję Przeglądaj , aby wybrać ścieżkę.
- Aby dołączyć wszystkie pliki do podfolderów wybranej ścieżki, dołącz
/**do ścieżki. - Aby uwzględnić wszystkie dane w bieżącym kontenerze i jego podfolderach, dołącz
**/*.*do ścieżki.
- Aby dołączyć wszystkie pliki do podfolderów wybranej ścieżki, dołącz
- Wybierz pozycję Utwórz.
- Wybierz utworzony zasób danych.
Tworzenie zestawu danych na podstawie przekazanych danych
Aby bezpośrednio przekazać dane:
- Wybierz pozycję Utwórz.
- W polu Nazwa wprowadź nazwę zestawu danych. Możesz również wprowadzić opis.
- Upewnij się, że typ zestawu danych jest ustawiony na Wartość Plik. Tylko typy zestawów danych plików są obsługiwane w przypadku obrazów.
- Wybierz Dalej.
- Wybierz pozycję Z plików lokalnych, a następnie wybierz pozycję Dalej.
- (Opcjonalnie) Wybierz magazyn danych. Możesz również pozostawić wartość domyślną do przekazania do domyślnego magazynu obiektów blob (workspaceblobstore) dla obszaru roboczego usługi Machine Learning.
- Wybierz Dalej.
- Wybierz pozycję Przekaż pliki lub Przekaż>>folder Przekaż, aby wybrać lokalne pliki lub foldery do przekazania.
- W oknie przeglądarki znajdź pliki lub foldery, a następnie wybierz pozycję Otwórz.
- Wybierz pozycję Przekaż , dopóki nie określisz wszystkich plików i folderów.
- Opcjonalnie możesz wybrać pole wyboru Zastąp , jeśli już istnieje . Sprawdź listę plików i folderów.
- Wybierz Dalej.
- Potwierdź szczegóły. Wybierz pozycję Wstecz , aby zmodyfikować ustawienia, lub wybierz pozycję Utwórz , aby utworzyć zestaw danych.
- Na koniec wybierz utworzony zasób danych.
Konfigurowanie odświeżania przyrostowego
Jeśli planujesz dodać nowe pliki danych do zestawu danych, użyj odświeżania przyrostowego, aby dodać pliki do projektu.
Po ustawieniu opcji Włącz odświeżanie przyrostowe w regularnych odstępach czasu zestaw danych jest okresowo sprawdzany pod kątem dodawania nowych plików do projektu na podstawie współczynnika uzupełniania etykiet. Sprawdzanie nowych danych zatrzymuje się, gdy projekt zawiera maksymalnie 500 000 plików.
Wybierz pozycję Włącz odświeżanie przyrostowe w regularnych odstępach czasu, gdy projekt ma stale monitorować nowe dane w magazynie danych.
Wyczyść zaznaczenie, jeśli nie chcesz, aby nowe pliki w magazynie danych zostały automatycznie dodane do projektu.
Ważne
Po włączeniu odświeżania przyrostowego nie twórz nowej wersji dla zestawu danych, który chcesz zaktualizować. W przeciwnym razie aktualizacje nie będą widoczne, ponieważ projekt etykietowania danych jest przypięty do wersji początkowej. Zamiast tego użyj Eksplorator usługi Azure Storage, aby zmodyfikować dane w odpowiednim folderze w usłudze Blob Storage.
Ponadto nie usuwaj danych. Usunięcie danych z zestawu danych używanego przez projekt powoduje błąd w projekcie.
Po utworzeniu projektu użyj karty Szczegóły , aby zmienić odświeżanie przyrostowe, wyświetlić sygnaturę czasową ostatniego odświeżenia i zażądać natychmiastowego odświeżenia danych.
Określanie klas etykiet
Na stronie Kategorie etykiet określ zestaw klas do kategoryzowania danych.
Dokładność i szybkość etykiet mają wpływ na ich zdolność do wyboru między klasami. Na przykład, zamiast określać pełny rodzaj i gatunki roślin lub zwierząt, należy użyć kodu pola lub skrócić rodzaj.
Możesz użyć płaskiej listy lub utworzyć grupy etykiet.
Aby utworzyć płaską listę, wybierz pozycję Dodaj kategorię etykiet, aby utworzyć każdą etykietę.
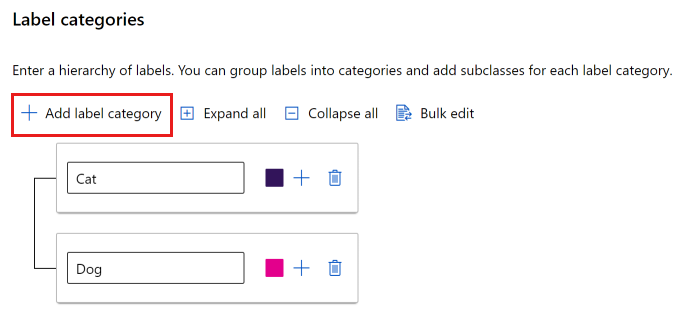
Aby utworzyć etykiety w różnych grupach, wybierz pozycję Dodaj kategorię etykiet, aby utworzyć etykiety najwyższego poziomu. Następnie wybierz znak plus (+) poniżej każdego najwyższego poziomu, aby utworzyć następny poziom etykiet dla tej kategorii. Dla każdego grupowania można utworzyć maksymalnie sześć poziomów.
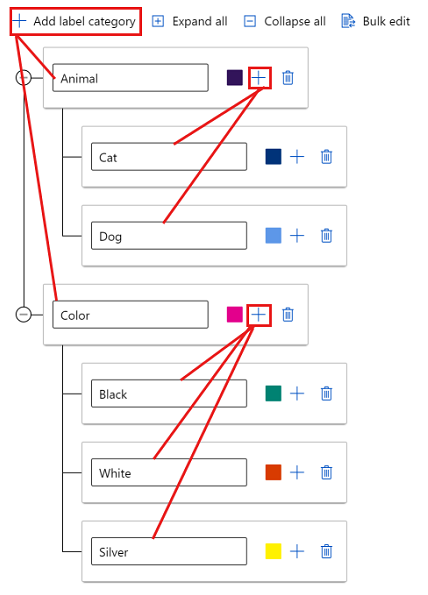
Etykiety można wybrać na dowolnym poziomie podczas procesu tagowania. Na przykład etykiety Animal, , Animal/CatAnimal/Dog, ColorColor/Black, , Color/Whitei Color/Silver są dostępne dla etykiety. W projekcie z wieloma etykietami nie ma potrzeby wybierania jednej z każdej kategorii. Jeśli jest to Twoja intencja, pamiętaj, aby uwzględnić te informacje w instrukcjach.
Opis zadania etykietowania obrazów
Ważne jest, aby jasno wyjaśnić zadanie etykietowania. Na stronie Instrukcje etykietowania możesz dodać link do witryny zewnętrznej zawierającej instrukcje etykietowania lub podać instrukcje w polu edycji na stronie. Zachowaj instrukcje zorientowane na zadania i odpowiednie dla odbiorców. Weź pod uwagę następujące pytania:
- Jakie etykiety będą widoczne i jak będą wybierane spośród nich? Czy istnieje tekst referencyjny do odwoływania się do?
- Co należy zrobić, jeśli etykieta nie wydaje się odpowiednia?
- Co należy zrobić, jeśli wiele etykiet wydaje się odpowiednie?
- Jaki próg ufności należy zastosować do etykiety? Czy chcesz, aby etykietka najlepiej odgadła, jeśli nie są pewne?
- Co należy zrobić z częściowo okludium lub nakładającymi się obiektami zainteresowania?
- Co należy zrobić, jeśli obiekt zainteresowania jest przycięty przez krawędź obrazu?
- Co powinni zrobić, jeśli uważają, że popełnili błąd po przesłaniu etykiety?
- Co należy zrobić, jeśli odkryją problemy z jakością obrazu, w tym słabe warunki oświetlenia, odbicia, utratę ostrości, niepożądane tło zawarte, nietypowe kąty aparatu itd.?
- Co należy zrobić, jeśli wielu recenzentów ma różne opinie dotyczące stosowania etykiety?
W przypadku pól ograniczenia ważne pytania obejmują:
- Jak zdefiniowano pole ograniczenia dla tego zadania? Czy powinien pozostać całkowicie na środku obiektu lub powinien znajdować się na zewnątrz? Czy powinno być przycięte tak ściśle, jak to możliwe, lub czy jakiś prześwit jest akceptowalny?
- Jakiego poziomu opieki i spójności oczekujesz, że etykiety mają być stosowane podczas definiowania pól ograniczenia?
- Jaka jest definicja wizualizacji każdej klasy etykiet? Czy można podać listę normalnych, brzegowych i liczników przypadków dla każdej klasy?
- Co należy zrobić, jeśli obiekt jest mały? Czy powinien być oznaczony jako obiekt lub czy powinien ignorować ten obiekt jako tło?
- Jak etykiety powinny obsługiwać obiekt, który jest wyświetlany tylko częściowo na obrazie?
- Jak etykietowanie powinny obsługiwać obiekt częściowo pokryty innym obiektem?
- Jak etykiety powinny obsługiwać obiekt, który nie ma jasnej granicy?
- Jak etykiety powinny obsługiwać obiekt, który nie jest klasą obiektów zainteresowań, ale ma wizualne podobieństwa do odpowiedniego typu obiektu?
Uwaga
Etykiety mogą wybierać pierwsze dziewięć etykiet przy użyciu kluczy liczbowych od 1 do 9. Te informacje mogą być uwzględniane w instrukcjach.
Kontrola jakości (wersja zapoznawcza)
Aby uzyskać dokładniejsze etykiety, użyj strony Kontrola jakości , aby wysłać każdy element do wielu etykiet.
Ważne
Etykietowanie konsensusu jest obecnie dostępne w publicznej wersji zapoznawczej.
Wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie jest zalecana w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Aby każdy element był wysyłany do wielu etykiet, wybierz pozycję Włącz etykietowanie konsensusu (wersja zapoznawcza). Następnie ustaw wartości dla elementów Minimum labelers i Maximum labelers , aby określić liczbę etykiet do użycia. Upewnij się, że masz dowolną liczbę etykiet dostępnych jako maksymalną liczbę. Nie można zmienić tych ustawień po rozpoczęciu projektu.
Jeśli osiągnięto konsensus z minimalnej liczby etykiet, element jest oznaczony etykietą. Jeśli porozumienie nie zostanie osiągnięte, element zostanie wysłany do większej liczby etykietek. Jeśli nie ma konsensusu po przejściu elementu do maksymalnej liczby etykiet, jego stan to Przegląd potrzeb, a właściciel projektu jest odpowiedzialny za etykietowanie elementu.
Uwaga
Projekty segmentacji wystąpień nie mogą używać etykietowania konsensusu.
Używanie etykietowania danych wspomaganych przez uczenie maszynowe
Aby przyspieszyć zadania etykietowania, na stronie etykietowania wspomaganego uczenia maszynowego można wyzwalać automatyczne modele uczenia maszynowego. Obrazy medyczne (pliki z .dcm rozszerzeniem) nie są uwzględniane w etykietowaniu wspomaganym. Jeśli typ projektu to Segmentacja semantyczna (wersja zapoznawcza), etykietowanie wspomagane przez uczenie maszynowe nie jest dostępne.
Na początku projektu etykietowania elementy są potasowane w losową kolejność w celu zmniejszenia potencjalnych stronniczości. Jednak wytrenowany model odzwierciedla wszelkie uprzedzenia, które znajdują się w zestawie danych. Jeśli na przykład 80 procent elementów jest jedną klasą, wówczas około 80 procent danych używanych do trenowania modelu ląduje w tej klasie.
Aby włączyć etykietowanie wspomagane, wybierz pozycję Włącz etykietowanie wspomagane przez uczenie maszynowe i określ procesor GPU. Jeśli nie masz procesora GPU w obszarze roboczym, zostanie utworzony klaster procesora GPU (nazwa zasobu: DefLabelNC6v3, vmsize: Standard_NC6s_v3) i dodany do obszaru roboczego. Klaster jest tworzony przy użyciu co najmniej zera węzłów, co oznacza, że nie kosztuje nic, gdy nie jest używany.
Etykietowanie wspomagane przez uczenie maszynowe składa się z dwóch faz:
- Klastrowanie
- Wstępne etykietowanie
Liczba elementów danych oznaczonych etykietami, która jest wymagana do rozpoczęcia etykietowania asystowanego, nie jest określoną liczbą. Ta liczba może się znacznie różnić w zależności od jednego projektu etykietowania do innego. W przypadku niektórych projektów czasami można zobaczyć wstępne oznaczenie lub zadania klastra po ręcznym oznaczeniu 300 elementami. Etykietowanie wspomagane przez uczenie maszynowe wykorzystuje technikę nazywaną uczeniem transferowym. Uczenie transferowe używa wstępnie wytrenowanego modelu, aby szybko rozpocząć proces trenowania. Jeśli klasy zestawu danych przypominają klasy w wstępnie wytrenowanego modelu, prelabels mogą stać się dostępne po zaledwie kilkuset ręcznie oznaczonych elementami. Jeśli zestaw danych znacznie różni się od danych używanych do wstępnego trenowania modelu, proces może zająć więcej czasu.
W przypadku używania etykietowania konsensusu etykieta konsensusu jest używana do trenowania.
Ponieważ etykiety końcowe nadal opierają się na danych wejściowych z labelera, ta technologia jest czasami nazywana etykietowaniem typu human-in-the-loop .
Uwaga
Etykietowanie danych wspomaganych przez uczenie maszynowe nie obsługuje domyślnych kont magazynu zabezpieczonych za siecią wirtualną. Do etykietowania danych wspomaganych przez uczenie maszynowe należy użyć konta magazynu innego niż domyślne. Konto magazynu innego niż domyślne można zabezpieczyć za siecią wirtualną.
Klastrowanie
Po przesłaniu niektórych etykiet model klasyfikacji zacznie grupować podobne elementy. Te podobne obrazy są prezentowane etykietom na tej samej stronie, aby ułatwić wydajniejsze ręczne tagowanie. Klastrowanie jest szczególnie przydatne, gdy etykietka wyświetla siatkę czterech, sześciu lub dziewięciu obrazów.
Po wytrenowanym modelu uczenia maszynowego na ręcznie oznaczonych danych model zostanie obcięty z ostatnią w pełni połączoną warstwą. Obrazy bez etykiet są następnie przekazywane przez obcinany model w procesie nazywanym osadzaniem lub cechowaniem. Ten proces osadza każdy obraz w przestrzeni wielowymiarowej zdefiniowanej przez warstwę modelu. Inne obrazy w przestrzeni, które znajdują się najbliżej obrazu, są używane do zadań klastrowania.
Faza klastrowania nie jest wyświetlana dla modeli wykrywania obiektów ani klasyfikacji tekstu.
Wstępne etykietowanie
Po przesłaniu wystarczającej liczby etykiet do trenowania model klasyfikacji przewiduje tagi lub model wykrywania obiektów przewiduje pola ograniczenia. Program labeler widzi teraz strony zawierające przewidywane etykiety już obecne w każdym elemencie. W przypadku wykrywania obiektów wyświetlane są również przewidywane pola. Zadanie polega na przejrzeniu tych przewidywań i skorygowaniu niepoprawnie oznaczonych obrazami przed przesłaniem strony.
Po wytrenowanym modelu uczenia maszynowego na ręcznie oznaczonych danych model jest oceniany na zestawie testowym ręcznie oznaczonych elementami. Ocena pomaga określić dokładność modelu przy różnych progach ufności. Proces oceny określa próg ufności, po którym model jest wystarczająco dokładny, aby pokazać prelabels. Następnie model jest oceniany pod kątem danych bez etykiet. Elementy z przewidywaniami, które są bardziej pewne niż próg, są używane do wstępnego etykietowania.
Inicjowanie projektu etykietowania obrazów
Po zainicjowaniu projektu etykietowania niektóre aspekty projektu są niezmienne. Nie można zmienić typu zadania ani zestawu danych. Można modyfikować etykiety i adres URL opisu zadania. Dokładnie przejrzyj ustawienia przed utworzeniem projektu. Po przesłaniu projektu wróć do strony przeglądu Etykietowanie danych, która pokazuje projekt jako Inicjowanie.
Uwaga
Strona przeglądu może nie zostać automatycznie odświeżona. Po wstrzymaniu ręcznie odśwież stronę, aby wyświetlić stan projektu jako Utworzono.
Rozwiązywanie problemów
Aby uzyskać informacje o problemach z tworzeniem projektu lub uzyskiwaniem dostępu do danych, zobacz Rozwiązywanie problemów z etykietowaniem danych.