Debugowanie zadań i monitorowanie postępu trenowania
Trenowanie modelu uczenia maszynowego jest procesem iteracyjnym i wymaga znacznego eksperymentowania. Korzystając z interaktywnego środowiska pracy usługi Azure Machine Learning, analitycy danych mogą używać zestawu SDK języka Python usługi Azure Machine Learning, interfejsu wiersza polecenia usługi Azure Machine Learning lub usługi Azure Studio, aby uzyskać dostęp do kontenera, w którym działa ich zadanie. Po uzyskaniu dostępu do kontenera zadań użytkownicy mogą iterować skrypty trenowania, monitorować postęp trenowania lub debugować zadanie zdalnie, tak jak zwykle odbywa się na maszynach lokalnych. Zadania można wchodzić w interakcje za pośrednictwem różnych aplikacji szkoleniowych, takich jak JupyterLab, TensorBoard, VS Code lub łącząc się z kontenerem zadań bezpośrednio za pośrednictwem protokołu SSH.
Trenowanie interakcyjne jest obsługiwane w klastrach obliczeniowych usługi Azure Machine Learning i klastrze Kubernetes z obsługą usługi Azure Arc.
Wymagania wstępne
- Zapoznaj się z wprowadzeniem do szkolenia w usłudze Azure Machine Learning.
- Aby uzyskać więcej informacji, zobacz ten link dla programu VS Code , aby skonfigurować rozszerzenie usługi Azure Machine Learning.
- Upewnij się, że środowisko pracy ma
openssh-serverzainstalowane pakiety iipykernel ~=6.0(wszystkie środowiska szkoleniowe usługi Azure Machine Learning mają te pakiety zainstalowane domyślnie). - Nie można włączyć aplikacji interaktywnych w ramach przebiegów trenowania rozproszonego, w których typ dystrybucji jest inny niż PyTorch, TensorFlow lub MPI. Niestandardowa konfiguracja trenowania rozproszonego (konfigurowanie trenowania z wieloma węzłami bez korzystania z powyższych struktur dystrybucji) nie jest obecnie obsługiwana.
- Do korzystania z protokołu SSH potrzebna jest para kluczy SSH. Możesz użyć
ssh-keygen -f "<filepath>"polecenia , aby wygenerować parę kluczy publicznych i prywatnych.
Interakcja z kontenerem zadań
Określając aplikacje interaktywne podczas tworzenia zadania, można połączyć się bezpośrednio z kontenerem w węźle obliczeniowym, w którym jest uruchomione zadanie. Gdy masz dostęp do kontenera zadań, możesz przetestować lub debugować zadanie w dokładnie tym samym środowisku, w którym zostanie uruchomione. Możesz również użyć programu VS Code do dołączenia do uruchomionego procesu i debugowania, tak jak w środowisku lokalnym.
Włączanie podczas przesyłania zadania
- Azure Machine Learning Studio
- Zestaw SDK dla języka Python
- Interfejs wiersza polecenia platformy Azure
Utwórz nowe zadanie w okienku nawigacji po lewej stronie w portalu studio.
Wybierz klaster obliczeniowy lub dołączone zasoby obliczeniowe (Kubernetes) jako typ obliczeniowy, wybierz docelowy obiekt obliczeniowy i określ liczbę potrzebnych węzłów w elemecie
Instance count.
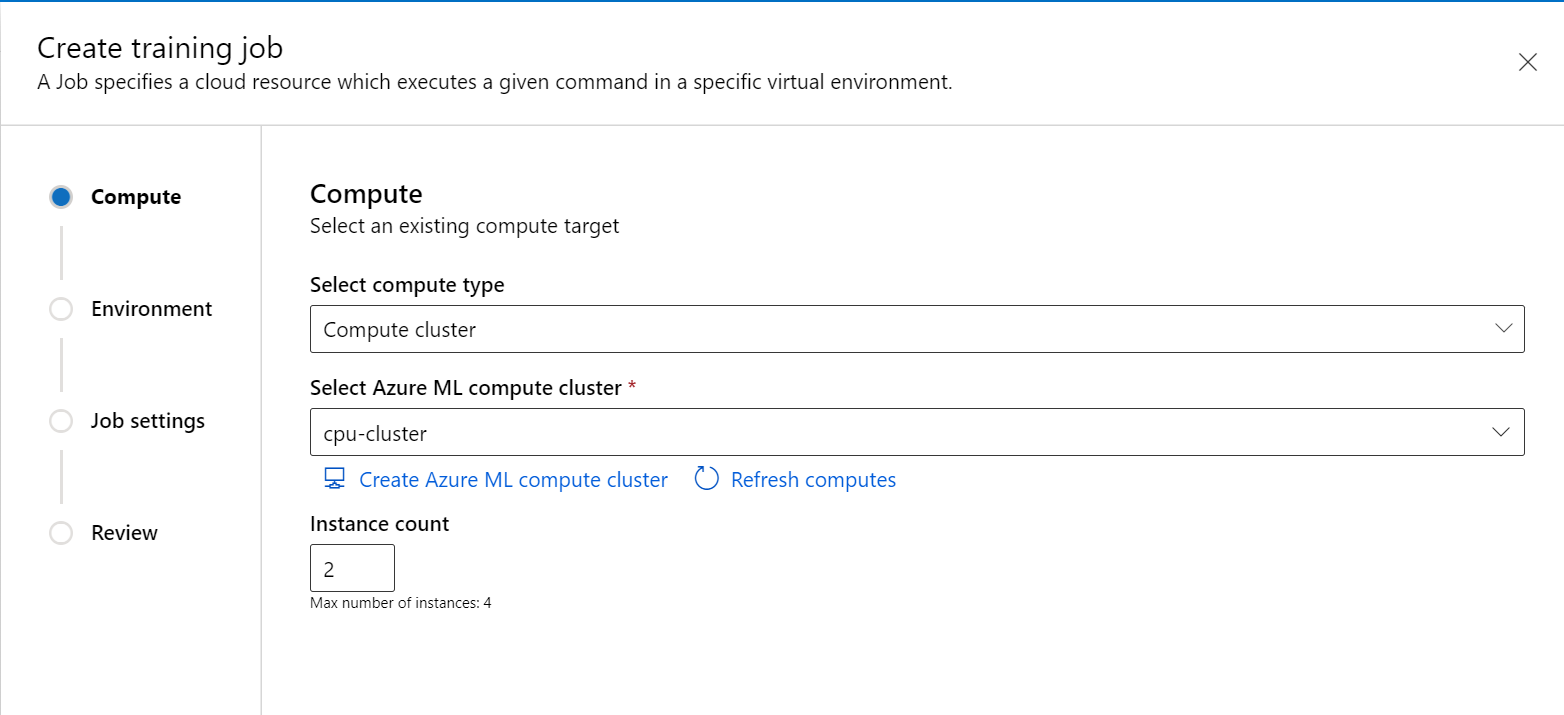
Postępuj zgodnie z instrukcjami kreatora, aby wybrać środowisko, w którym chcesz uruchomić zadanie.
W kroku Skrypt trenowania dodaj kod trenowania (i dane wejściowe/wyjściowe) i odwołaj się do niego w poleceniu, aby upewnić się, że jest on zainstalowany w zadaniu.
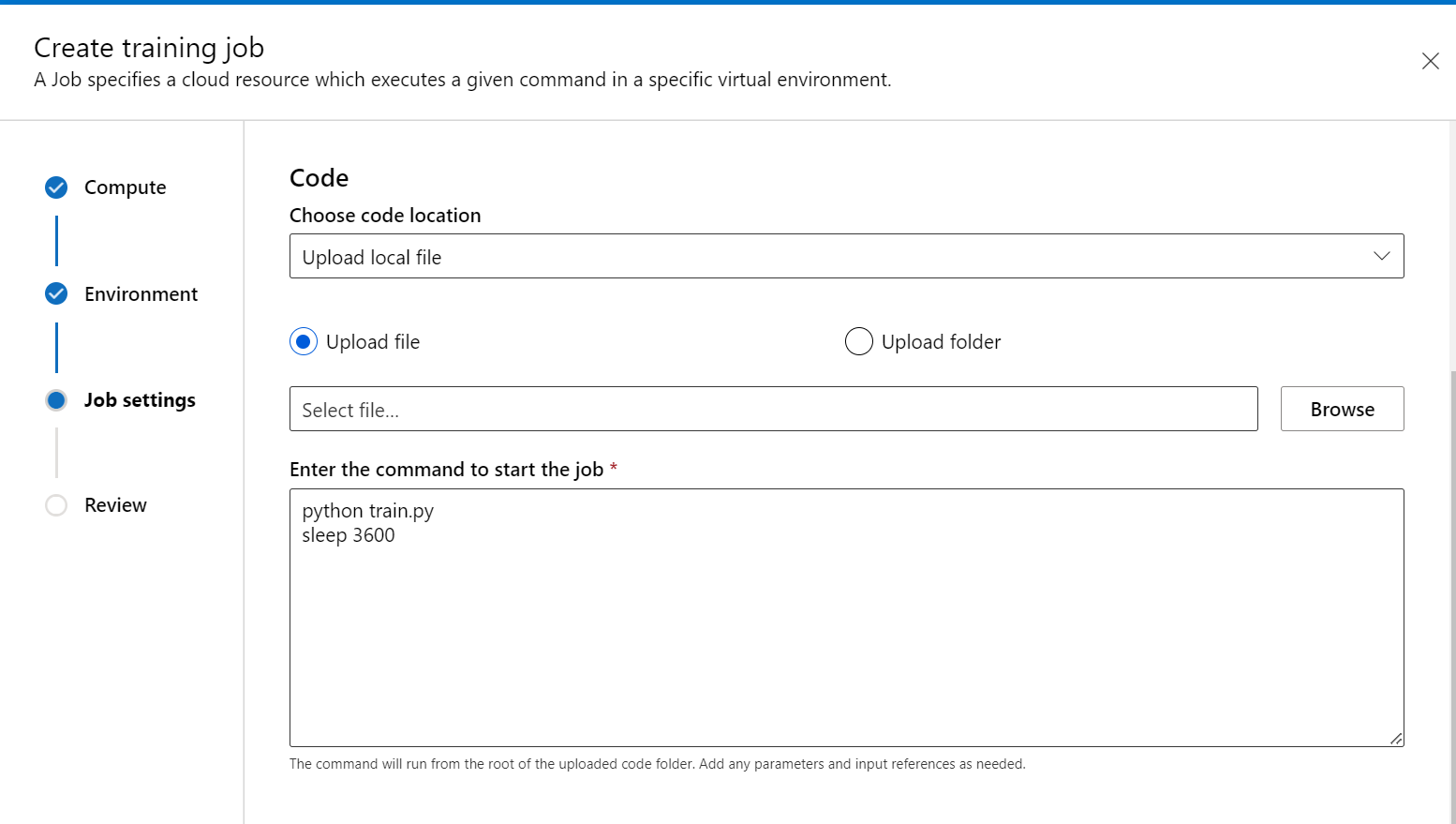
Możesz umieścić sleep <specific time> na końcu polecenia, aby określić ilość czasu, który chcesz zarezerwować zasób obliczeniowy. Format jest następujący:
- sen 1s
- sen 1 m
- sen 1h
- sen 1d
Możesz również użyć sleep infinity polecenia , które zachowałoby żywą pracę na czas nieokreślony.
Uwaga
Jeśli używasz sleep infinitymetody , musisz ręcznie anulować zadanie , aby puścić zasób obliczeniowy (i zatrzymać rozliczenia).
- W obszarze Ustawienia obliczeniowe rozwiń opcję Trenowanie aplikacji. Wybierz co najmniej jedną aplikację szkoleniową, której chcesz użyć do interakcji z zadaniem. Jeśli nie wybierzesz aplikacji, funkcja debugowania nie będzie dostępna.
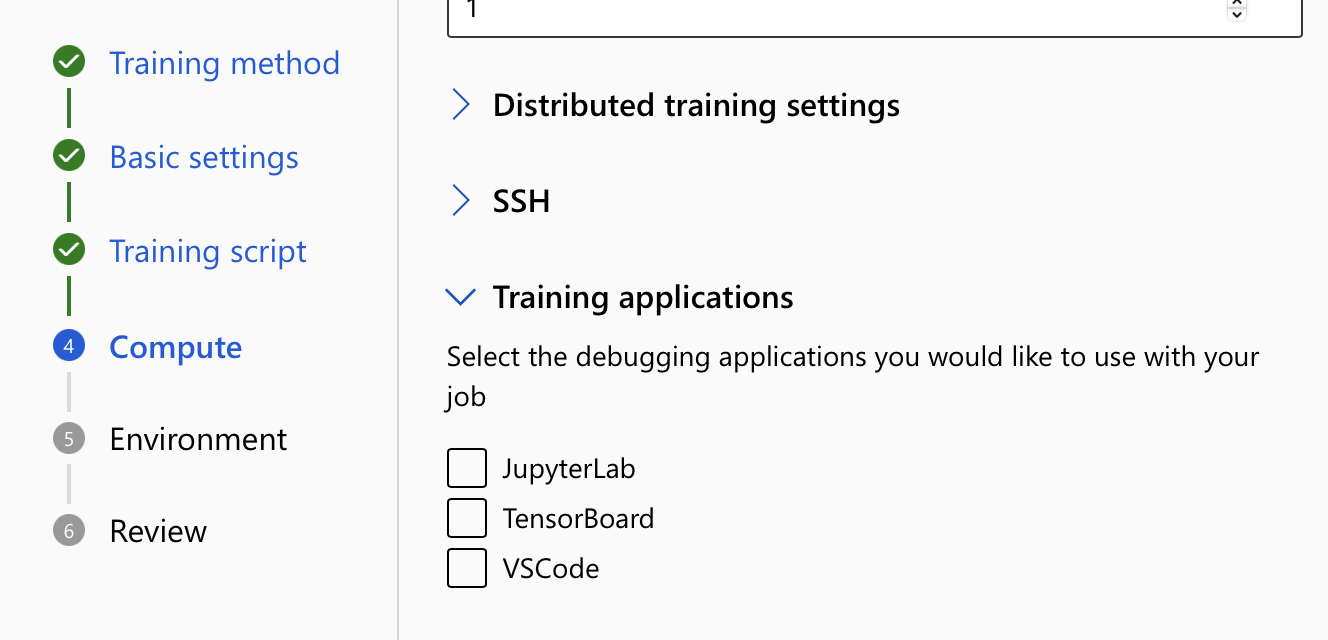
- Przejrzyj i utwórz zadanie.
Nawiązywanie połączenia z punktami końcowymi
- Azure Machine Learning Studio
- Zestaw SDK dla języka Python
- Interfejs wiersza polecenia platformy Azure
Aby wchodzić w interakcje z uruchomionym zadaniem, wybierz przycisk Debuguj i monitoruj na stronie szczegółów zadania.
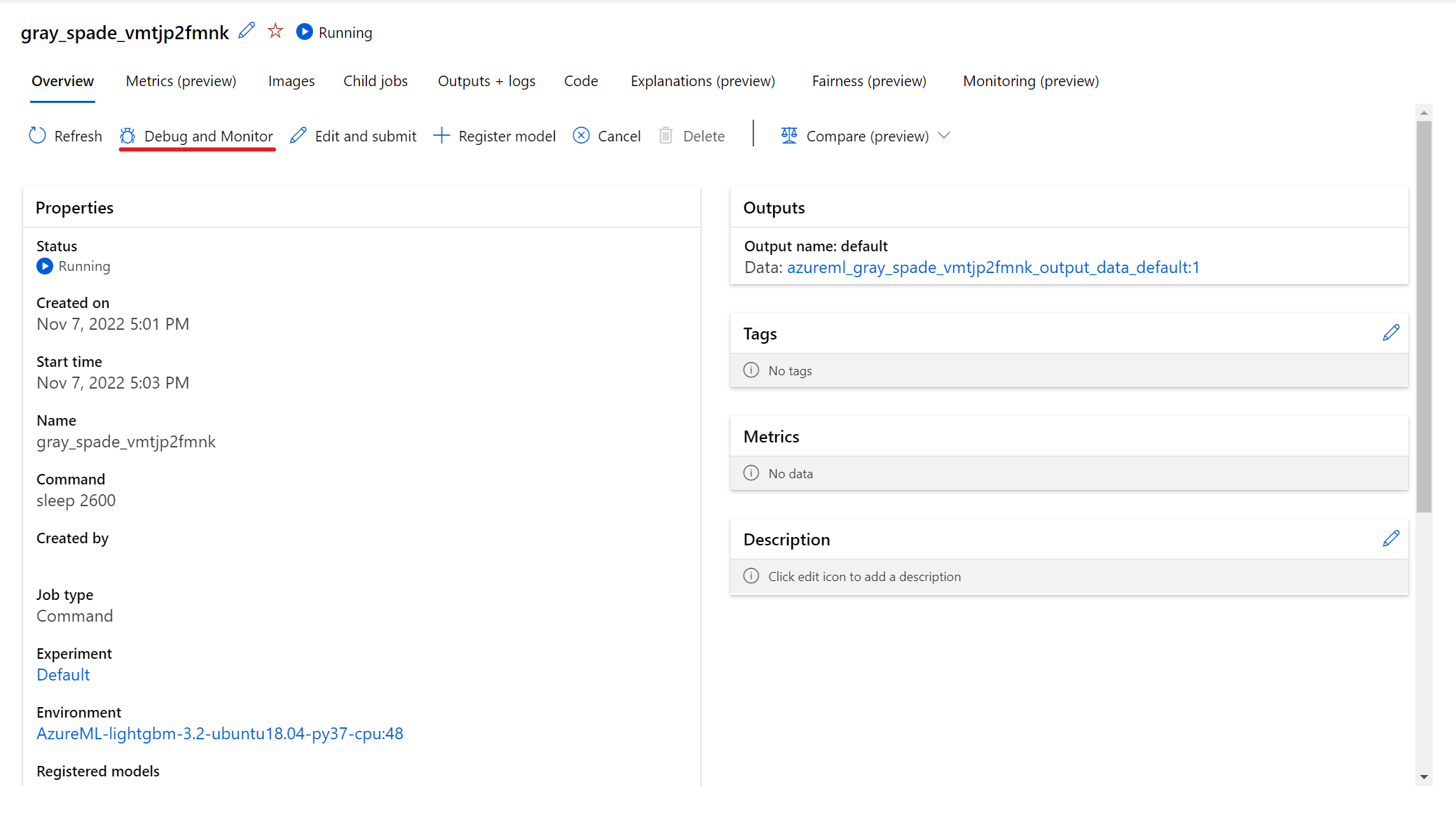
Kliknięcie aplikacji w panelu powoduje otwarcie nowej karty dla aplikacji. Dostęp do aplikacji można uzyskać tylko wtedy, gdy są w stanie Uruchomiono , a tylko właściciel zadania jest autoryzowany do uzyskiwania dostępu do aplikacji. Jeśli trenujesz na wielu węzłach, możesz wybrać konkretny węzeł, z którym chcesz korzystać.
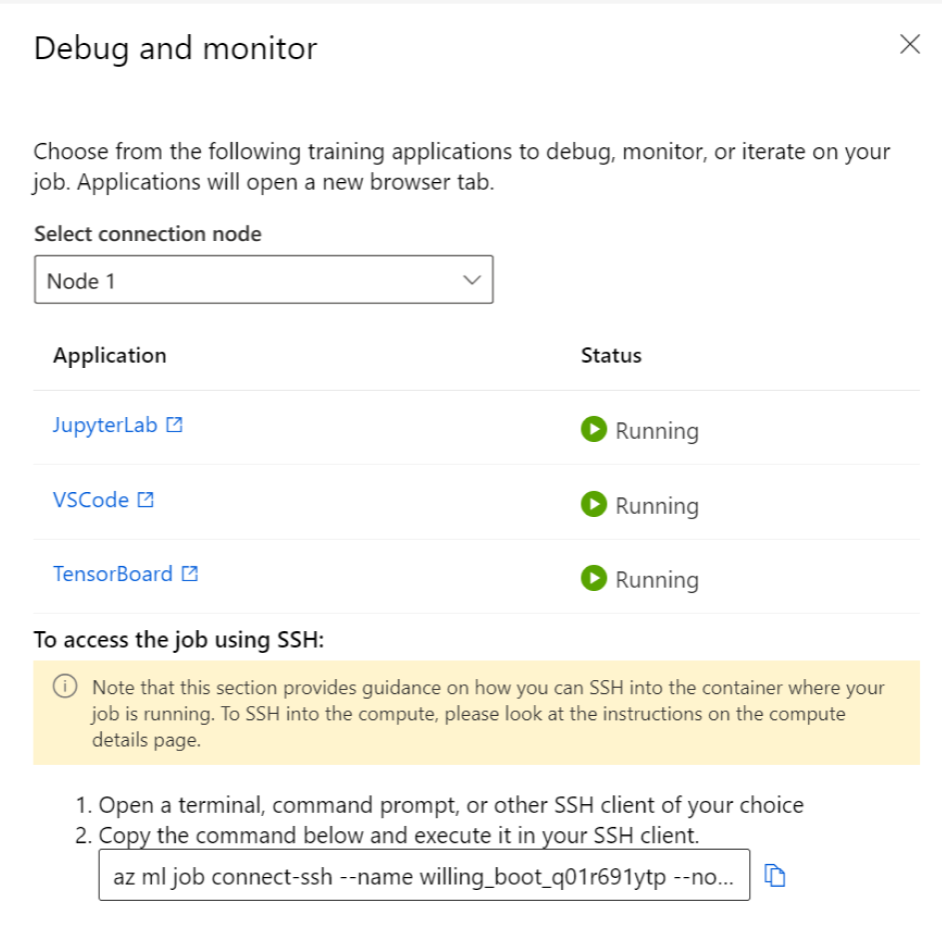
Uruchomienie zadania i aplikacji szkoleniowych określonych podczas tworzenia zadania może potrwać kilka minut.
Interakcja z aplikacjami
Po wybraniu punktów końcowych do interakcji podczas wykonywania zadania zostaniesz przeniesiony do kontenera użytkownika w katalogu roboczym, w którym możesz uzyskać dostęp do kodu, danych wejściowych, danych wyjściowych i dzienników. Jeśli wystąpią problemy podczas nawiązywania połączenia z aplikacjami, interaktywne dzienniki funkcji i aplikacji można znaleźć na karcie Dane wyjściowe i dzienniki aplikacji system_logs-interactive_capability.>
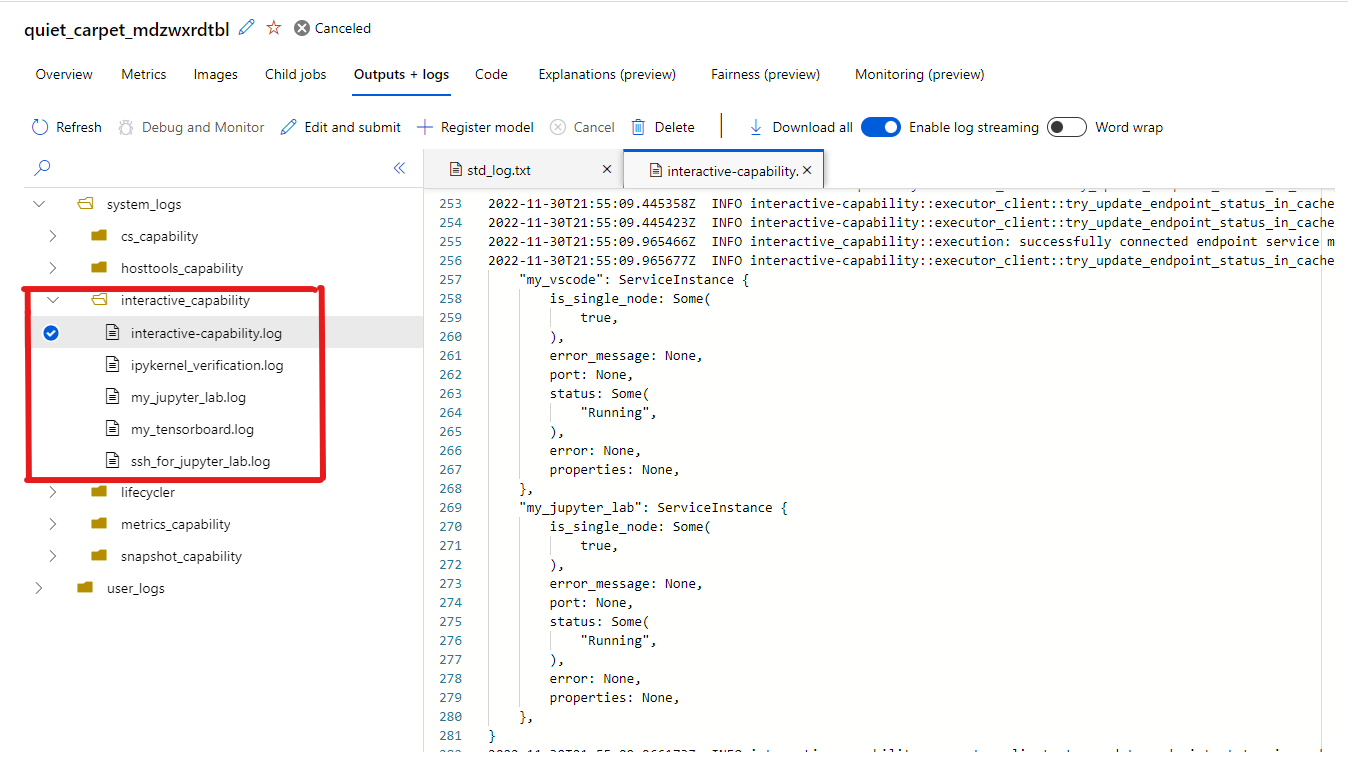
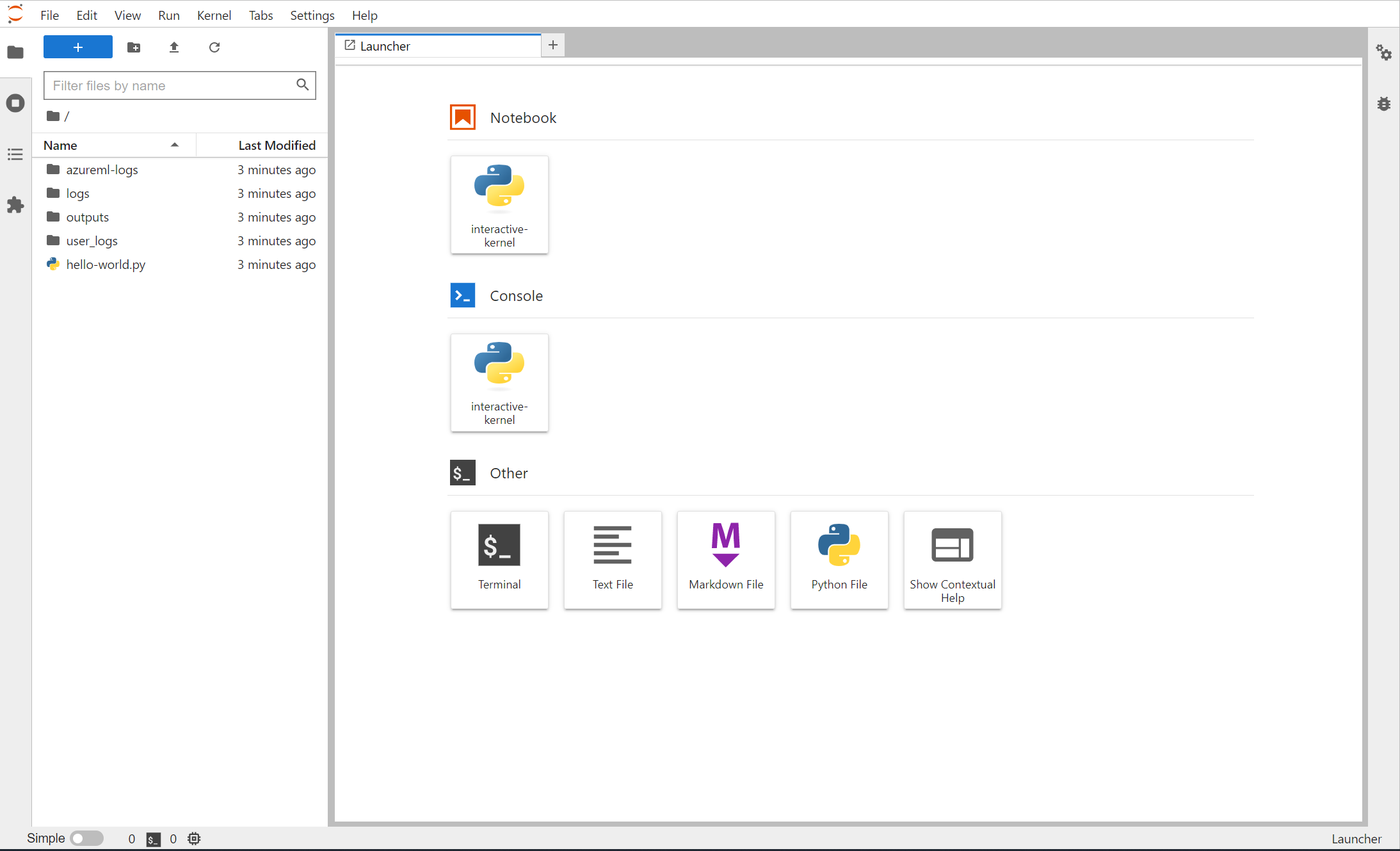
Możesz otworzyć terminal z poziomu laboratorium Jupyter Lab i rozpocząć interakcję w kontenerze zadań. Możesz również bezpośrednio wykonać iterowanie skryptu szkoleniowego za pomocą laboratorium Jupyter Lab.
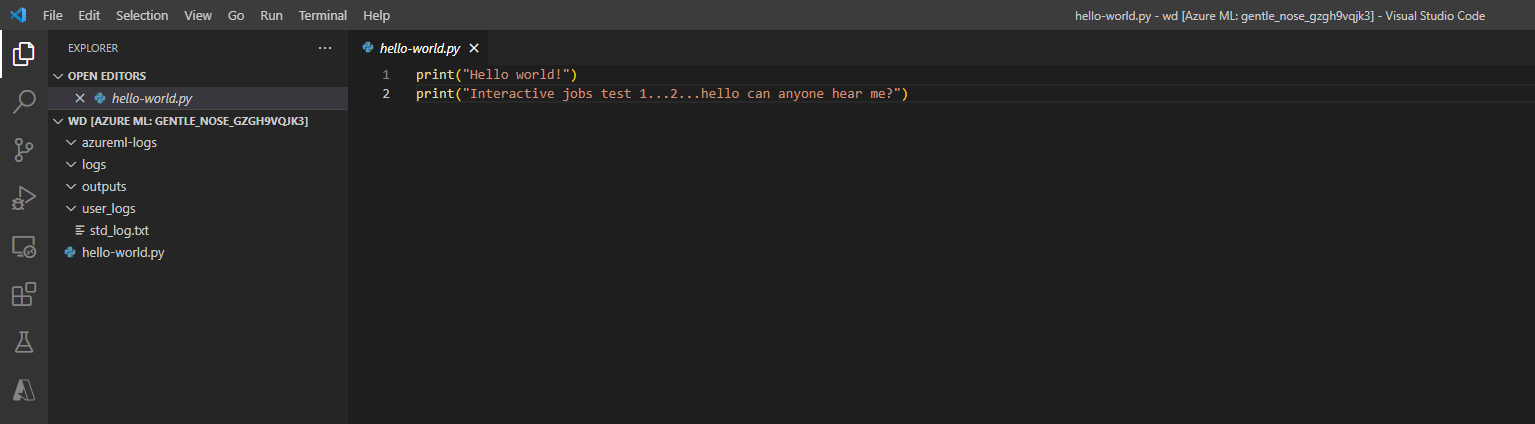
Możesz również wchodzić w interakcje z kontenerem zadań w programie VS Code. Aby dołączyć debuger do zadania podczas przesyłania zadania i wstrzymać wykonywanie, przejdź tutaj.
Uwaga
Obszary robocze z obsługą łącza prywatnego nie są obecnie obsługiwane podczas interakcji z kontenerem zadań za pomocą programu VS Code.
Jeśli zarejestrowano zdarzenia tensorflow dla zadania, możesz użyć narzędzia TensorBoard do monitorowania metryk po uruchomieniu zadania.
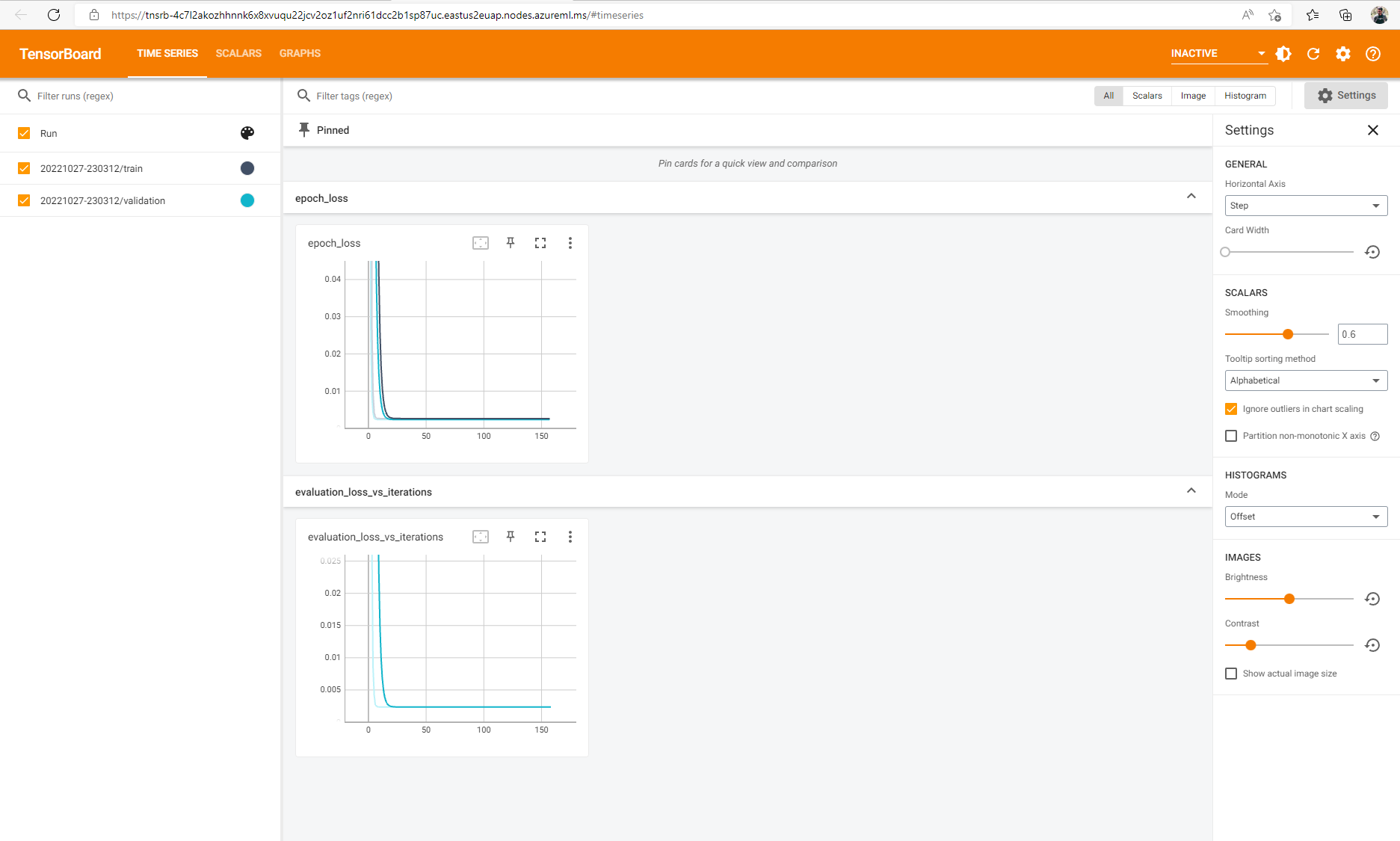
Zakończenie zadania
Po zakończeniu trenowania interaktywnego możesz również przejść do strony szczegółów zadania, aby anulować zadanie, co spowoduje zwolnienie zasobu obliczeniowego. Alternatywnie należy użyć az ml job cancel -n <your job name> w interfejsie wiersza polecenia lub ml_client.job.cancel("<job name>") w zestawie SDK.

Dołączanie debugera do zadania
Aby przesłać zadanie z dołączonym debugerem i wstrzymane wykonywanie, możesz użyć debugowania i programu VS Code (debugpy musi być zainstalowany w środowisku zadania).
Uwaga
Obszary robocze z obsługą łącza prywatnego nie są obecnie obsługiwane podczas dołączania debugera do zadania w programie VS Code.
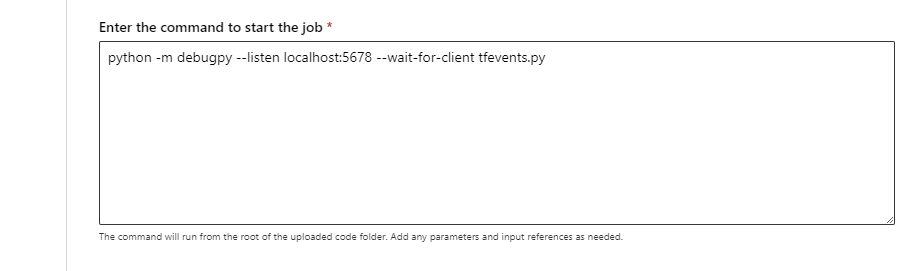
- Podczas przesyłania zadania (za pośrednictwem interfejsu użytkownika interfejs wiersza polecenia lub zestawu SDK) użyj polecenia debugpy, aby uruchomić skrypt języka Python. Na przykład poniższy zrzut ekranu przedstawia przykładowe polecenie, które używa debugpy do dołączania debugera skryptu tensorflow (
tfevents.pymożna zastąpić nazwą skryptu trenowania).
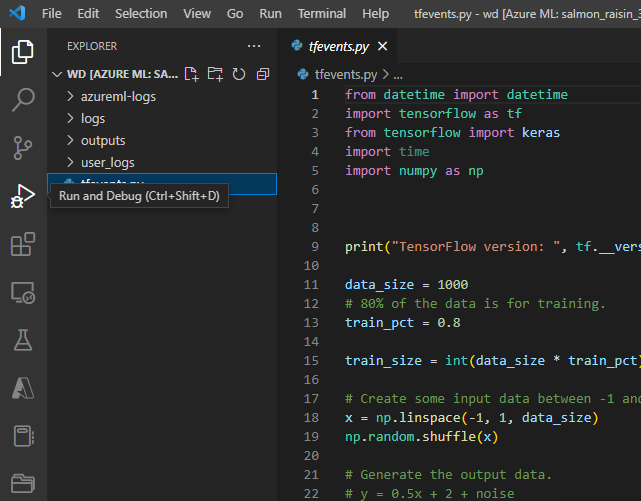
Po przesłaniu zadania połącz się z programem VS Code i wybierz wbudowany debuger.
Użyj konfiguracji debugowania "Dołączanie zdalne", aby dołączyć do przesłanego zadania i przekazać ścieżkę i port skonfigurowany w poleceniu przesyłania zadania. Te informacje można również znaleźć na stronie szczegółów zadania.
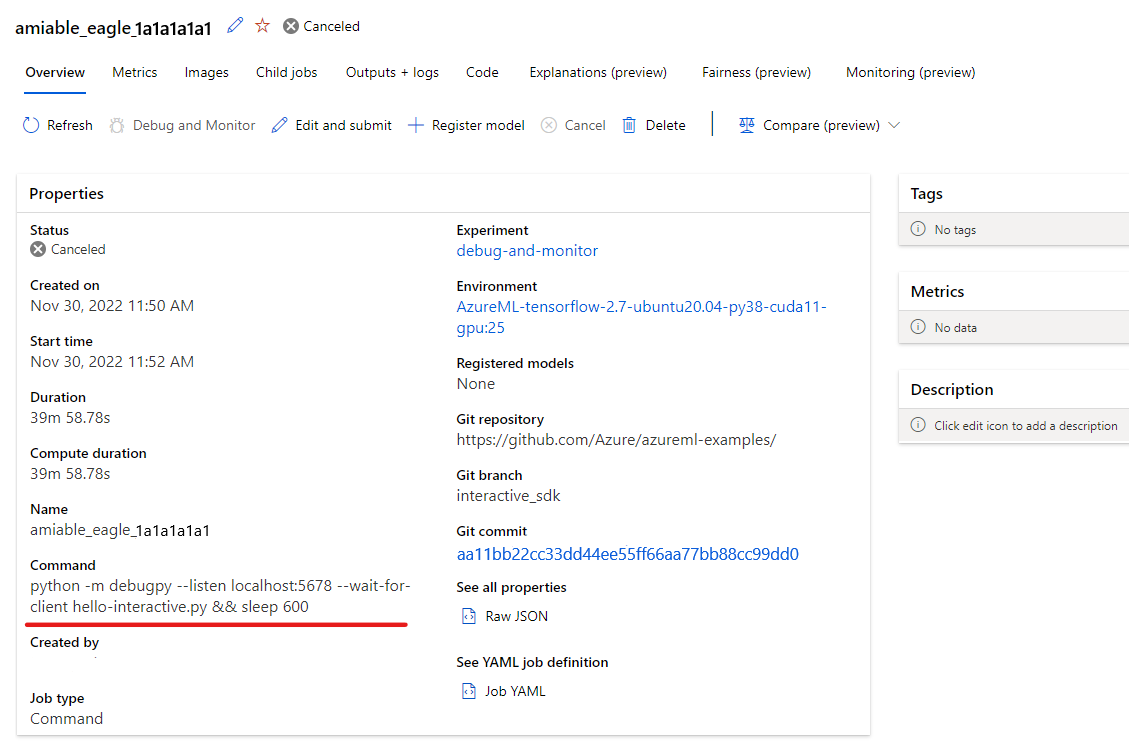
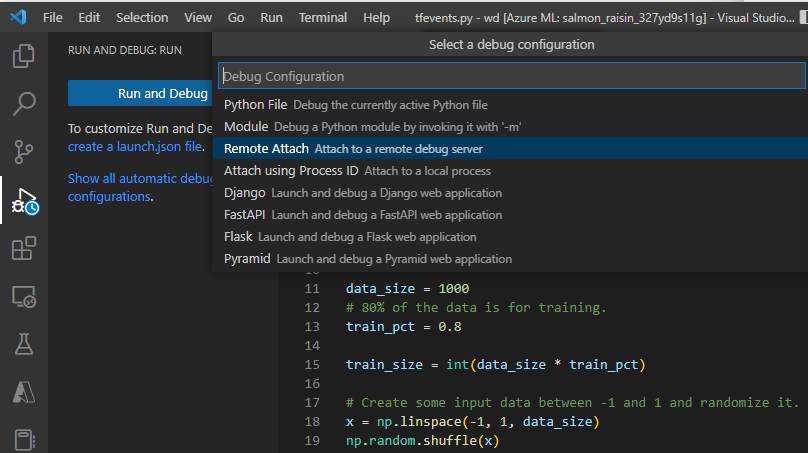
Ustaw punkty przerwania i przejmij wykonywanie zadania tak jak w lokalnym przepływie pracy debugowania.
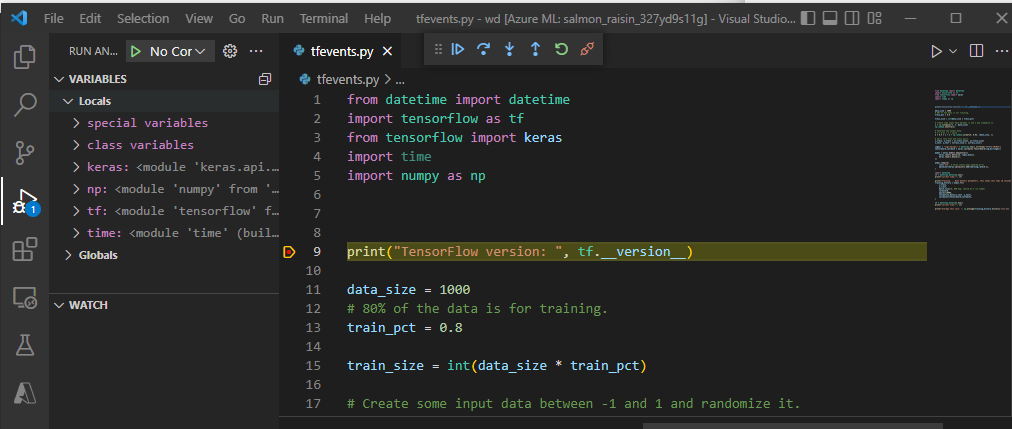
Uwaga
Jeśli używasz debugpy do uruchamiania zadania, zadanie nie zostanie wykonane, chyba że dołączysz debuger w programie VS Code i wykonasz skrypt. Jeśli nie zostanie to zrobione, obliczenia zostaną zarezerwowane do momentu anulowania zadania.
Następne kroki
- Dowiedz się więcej o tym, jak i gdzie wdrożyć model.