Często zadawane pytania dotyczące prognozowania w rozwiązaniu AutoML
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Ten artykuł zawiera odpowiedzi na często zadawane pytania dotyczące prognozowania w automatycznym uczeniu maszynowym (AutoML). Aby uzyskać ogólne informacje na temat metodologii prognozowania w rozwiązaniu AutoML, zobacz artykuł Omówienie metod prognozowania w rozwiązaniu AutoML .
Jak mogę rozpocząć tworzenie modeli prognozowania w rozwiązaniu AutoML?
Możesz zacząć od przeczytania artykułu Konfigurowanie automatycznego uczenia maszynowego w celu wytrenowania modelu prognozowania szeregów czasowych. Przykłady praktyczne można również znaleźć w kilku notesach Jupyter:
- Przykład udostępniania roweru
- Prognozowanie przy użyciu uczenia głębokiego
- Wiele modeli — rozwiązanie
- Przepisy prognozowania
- Zaawansowane scenariusze prognozowania
Dlaczego automl działa wolno na moich danych?
Zawsze pracujemy nad szybszym i bardziej skalowalnym rozwiązaniem AutoML. Aby pracować jako ogólna platforma prognozowania, rozwiązanie AutoML wykonuje obszerne walidacje danych i złożoną inżynierię cech i wyszukuje dużą przestrzeń modelu. Ta złożoność może wymagać dużo czasu, w zależności od danych i konfiguracji.
Jednym z typowych źródeł powolnego środowiska uruchomieniowego jest trenowanie automatycznego uczenia maszynowego z domyślnymi ustawieniami danych, które zawierają wiele szeregów czasowych. Koszt wielu metod prognozowania jest skalowany z liczbą serii. Na przykład metody, takie jak Exponential Smoothing i Prophet , trenują model dla każdego szeregu czasowego w danych treningowych.
Funkcja Wiele modeli automatycznego uczenia maszynowego jest skalowana do tych scenariuszy przez dystrybucję zadań szkoleniowych w klastrze obliczeniowym. Pomyślnie zastosowano je do danych z milionami szeregów czasowych. Aby uzyskać więcej informacji, zobacz sekcję artykułu wiele modeli . Możesz również przeczytać o sukcesie wielu modeli w zestawie danych konkurencji o wysokim profilu.
Jak przyspieszyć korzystanie z rozwiązania AutoML?
Zobacz Dlaczego automl działa wolno na moich danych? odpowiedź, aby dowiedzieć się, dlaczego rozwiązanie AutoML może być powolne w Twoim przypadku.
Rozważ następujące zmiany konfiguracji, które mogą przyspieszyć zadanie:
- Blokuj modele szeregów czasowych, takie jak ARIMA i Prorok.
- Wyłącz funkcje look-back, takie jak opóźnienia i okna stopniowe.
- Zmniejszyć:
- Liczba prób/iteracji.
- Limit czasu wersji próbnej/iteracji.
- Limit czasu eksperymentu.
- Liczba składanych krzyżowych poprawek.
- Upewnij się, że jest włączone wczesne zakończenie.
Jakiej konfiguracji modelowania należy używać?
Prognozowanie rozwiązania AutoML obsługuje cztery podstawowe konfiguracje:
| Konfigurowanie | Scenariusz | Plusy | Minusy |
|---|---|---|---|
| Domyślny automl | Zalecane, jeśli zestaw danych ma niewielką liczbę szeregów czasowych, które mają mniej więcej podobne zachowanie historyczne. | — Proste konfigurowanie z poziomu kodu/zestawu SDK lub usługi Azure Machine Learning Studio. — Rozwiązanie AutoML może uczyć się w różnych szeregach czasowych, ponieważ modele regresji łączą wszystkie serie w ramach trenowania. Aby uzyskać więcej informacji, zobacz Grupowanie modeli. |
— Modele regresji mogą być mniej dokładne, jeśli szeregi czasowe w danych treningowych mają rozbieżne zachowanie. — Trenowanie modeli szeregów czasowych może zająć dużo czasu, jeśli dane treningowe mają dużą liczbę serii. Aby uzyskać więcej informacji, zobacz odpowiedź Dlaczego autoML działa wolno na moich danych? |
| AutoML z uczeniem głębokim | Zalecane w przypadku zestawów danych z ponad 1000 obserwacjami i potencjalnie wieloma szeregami czasowymi, które wykazują złożone wzorce. Po włączeniu rozwiązanie AutoML przeprowadzi zamiatanie modeli czasowych splotowych sieci neuronowych (TCN) podczas trenowania. Aby uzyskać więcej informacji, zobacz Włączanie uczenia głębokiego. | — Proste konfigurowanie z poziomu kodu/zestawu SDK lub usługi Azure Machine Learning Studio. - Możliwości uczenia krzyżowego, ponieważ dane pul TCN są przesyłane przez całą serię. - Potencjalnie wyższa dokładność ze względu na dużą pojemność modeli głębokiej sieci neuronowej (DNN). Aby uzyskać więcej informacji, zobacz Modele prognozowania w rozwiązaniu AutoML. |
- Trenowanie może trwać znacznie dłużej ze względu na złożoność modeli DNN. - Seria z małą ilością historii jest mało prawdopodobne, aby skorzystać z tych modeli. |
| Wiele modeli | Zalecane, jeśli musisz trenować i zarządzać dużą liczbą modeli prognozowania w sposób skalowalny. Aby uzyskać więcej informacji, zobacz sekcję artykułu wiele modeli . | -Skalowalne. - Potencjalnie wyższa dokładność, gdy szeregi czasowe mają rozbieżne zachowanie ze sobą. |
- Brak uczenia się w szeregach czasowych. — Nie można skonfigurować ani uruchomić wielu zadań modeli z usługi Azure Machine Learning Studio. Obecnie jest dostępne tylko środowisko kodu/zestawu SDK. |
| Hierarchiczny szereg czasowy (HTS) | Zalecane, jeśli seria w danych ma zagnieżdżona, hierarchiczną strukturę i musisz wytrenować lub utworzyć prognozy na zagregowanych poziomach hierarchii. Aby uzyskać więcej informacji, zobacz sekcję artykułu dotyczącego prognozowania szeregów czasowych hierarchicznych. | - Trenowanie na zagregowanych poziomach może zmniejszyć szum w szeregach czasowych węzłów liścia i potencjalnie prowadzić do modeli o wyższej dokładności. — Prognozy dla dowolnego poziomu hierarchii można pobrać, agregując lub agregując prognozy z poziomu szkolenia. |
— Należy podać poziom agregacji na potrzeby trenowania. Rozwiązanie AutoML nie ma obecnie algorytmu do znalezienia optymalnego poziomu. |
Uwaga
Zalecamy używanie węzłów obliczeniowych z procesorami GPU, gdy uczenie głębokie jest włączone, aby jak najlepiej wykorzystać wysoką pojemność sieci rozproszonej. Czas trenowania może być znacznie szybszy w porównaniu z węzłami tylko z procesorami CPU. Aby uzyskać więcej informacji, zobacz artykuł Dotyczący rozmiarów maszyn wirtualnych zoptymalizowanych pod kątem procesora GPU.
Uwaga
FUNKCJA HTS jest przeznaczona dla zadań, w których trenowanie lub przewidywanie jest wymagane na zagregowanych poziomach w hierarchii. W przypadku danych hierarchicznych, które wymagają tylko trenowania i przewidywania węzła liścia, należy użyć wielu modeli .
Jak mogę zapobiec nadmiernemu dopasowaniu i wyciekowi danych?
Rozwiązanie AutoML używa najlepszych rozwiązań dotyczących uczenia maszynowego, takich jak wybór modelu z walidacją krzyżową, które elimują wiele problemów z nadmiernym dopasowaniem. Istnieją jednak inne potencjalne źródła nadmiernego dopasowania:
Dane wejściowe zawierają kolumny funkcji pochodzące z obiektu docelowego z prostą formułą. Na przykład funkcja, która jest dokładną wielokrotną wartością docelową, może spowodować niemal doskonały wynik trenowania. Jednak model prawdopodobnie nie uogólni danych poza próbkami. Zalecamy eksplorowanie danych przed trenowanie modelu i usuwanie kolumn, które "wyciekają" informacje docelowe.
Dane szkoleniowe używają funkcji, które nie są znane w przyszłości, aż do horyzontu prognozy. Modele regresji rozwiązania AutoML obecnie zakładają, że wszystkie funkcje są znane z horyzontu prognozy. Przed rozpoczęciem trenowania i usuwania kolumn funkcji, które są znane tylko historycznie, zalecamy eksplorowanie danych.
Istnieją znaczące różnice strukturalne (zmiany schematu) między częściami danych trenowania, walidacji lub testowania. Rozważmy na przykład wpływ pandemii COVID-19 na popyt na prawie wszystkie dobre elementy w 2020 i 2021 roku. Jest to klasyczny przykład zmiany reżimu. Nadmierne dopasowanie ze względu na zmianę systemu jest najtrudniejszym problemem do rozwiązania, ponieważ jest on zależny od wysoce scenariusza i może wymagać głębokiej wiedzy w celu zidentyfikowania.
Jako pierwsza linia obrony spróbuj zarezerwować od 10 do 20 procent całkowitej historii dla danych walidacji lub danych krzyżowych walidacji. Nie zawsze można zarezerwować tę ilość danych weryfikacji, jeśli historia trenowania jest krótka, ale jest to najlepsze rozwiązanie. Aby uzyskać więcej informacji, zobacz Trenowanie i walidacja danych.
Co to znaczy, jeśli moja praca szkoleniowa osiągnie doskonałe wyniki walidacji?
Istnieje możliwość wyświetlenia doskonałych wyników podczas wyświetlania metryk walidacji z zadania trenowania. Doskonały wynik oznacza, że prognoza i wartości rzeczywiste w zestawie weryfikacji są takie same lub prawie takie same. Na przykład masz błąd średniokwadratowy równy 0,0 lub wynik R2 równy 1,0.
Doskonały wynik weryfikacji zwykle wskazuje, że model jest poważnie nadmiernie dopasowany, prawdopodobnie z powodu wycieku danych. Najlepszym sposobem działania jest sprawdzenie danych pod kątem wycieków i usunięcie kolumn powodujących wyciek.
Co zrobić, jeśli moje dane szeregów czasowych nie mają regularnie rozmieszczonych obserwacji?
Modele prognozowania rozwiązania AutoML wymagają, aby dane szkoleniowe regularnie przestrzeń obserwacji w odniesieniu do kalendarza. To wymaganie obejmuje przypadki, takie jak obserwacje miesięczne lub roczne, w których liczba dni między obserwacjami może się różnić. Dane zależne od czasu mogą nie spełniać tego wymagania w dwóch przypadkach:
Dane mają dobrze zdefiniowaną częstotliwość, ale brakujące obserwacje tworzą luki w serii. W takim przypadku rozwiązanie AutoML spróbuje wykryć częstotliwość, wypełnić nowe obserwacje luk i uzupełnić brakujące wartości docelowe i cechowe. Opcjonalnie użytkownik może skonfigurować metody imputacji za pomocą ustawień zestawu SDK lub za pośrednictwem internetowego interfejsu użytkownika. Aby uzyskać więcej informacji, zobacz Niestandardowe cechowanie.
Dane nie mają dobrze zdefiniowanej częstotliwości. Oznacza to, że czas trwania między obserwacjami nie ma zauważalnego wzorca. Dane transakcyjne, takie jak z systemu punkt-sprzedaży, są jednym z przykładów. W takim przypadku możesz ustawić opcję AutoML, aby agregować dane do wybranej częstotliwości. Możesz wybrać częstotliwość regularną, która najlepiej odpowiada danym i celom modelowania. Aby uzyskać więcej informacji, zobacz Agregacja danych.
Jak mogę wybrać metryki podstawowej?
Podstawowa metryka jest ważna, ponieważ jej wartość danych walidacji określa najlepszy model podczas zamiatania i wybierania. Znormalizowany błąd średniokwadratowy (NRMSE) i znormalizowany średni błąd bezwzględny (NMAE) to zazwyczaj najlepsze opcje dla podstawowej metryki w zadaniach prognozowania.
Aby wybrać między nimi, należy pamiętać, że NRMSE karze wartości odstające w danych treningowych więcej niż NMAE, ponieważ używa kwadratu błędu. NmAE może być lepszym wyborem, jeśli chcesz, aby model był mniej wrażliwy na wartości odstające. Aby uzyskać więcej informacji, zobacz Regression and forecasting metrics (Metryki regresji i prognozowania).
Uwaga
Nie zalecamy używania wyniku R2 lub R2 jako podstawowej metryki do prognozowania.
Uwaga
Rozwiązanie AutoML nie obsługuje niestandardowych ani udostępnianych przez użytkownika funkcji podstawowej metryki. Musisz wybrać jedną ze wstępnie zdefiniowanych podstawowych metryk, które obsługuje rozwiązanie AutoML.
Jak mogę poprawić dokładność modelu?
- Upewnij się, że konfigurujesz rozwiązanie AutoML w najlepszy sposób dla danych. Aby uzyskać więcej informacji, zobacz Odpowiedź Jakiej konfiguracji modelowania należy używać?
- Zapoznaj się z notesem z przepisami prognozowania, aby zapoznać się z przewodnikami krok po kroku dotyczącymi tworzenia i ulepszania modeli prognoz.
- Oceń model przy użyciu testów wstecznych w kilku cyklach prognozowania. Ta procedura zapewnia bardziej niezawodne oszacowanie błędu prognozowania i daje punkt odniesienia do mierzenia ulepszeń. Przykład można znaleźć w notesie testowania wstecznego.
- Jeśli dane są hałaśliwe, rozważ agregowanie ich do częstotliwości grubszej, aby zwiększyć współczynnik sygnału do szumu. Aby uzyskać więcej informacji, zobacz Częstotliwość i agregacja danych docelowych.
- Dodaj nowe funkcje, które mogą pomóc przewidzieć cel. Wiedza specjalistyczna może znacznie pomóc podczas wybierania danych szkoleniowych.
- Porównaj wartości metryk sprawdzania poprawności i testowania oraz ustal, czy wybrany model jest niedopasowy, czy zbyt dopasowany do danych. Ta wiedza może poprowadzić Cię do lepszej konfiguracji trenowania. Na przykład można określić, że konieczne jest użycie większej liczby składanych krzyżowych walidacji w odpowiedzi na nadmierne dopasowanie.
Czy rozwiązanie AutoML zawsze wybiera ten sam najlepszy model z tych samych danych treningowych i konfiguracji?
Proces wyszukiwania modelu automatycznego uczenia maszynowego nie jest deterministyczny, dlatego nie zawsze wybiera ten sam model z tych samych danych i konfiguracji.
Jak mogę naprawić błąd braku pamięci?
Istnieją dwa typy błędów pamięci:
- Brak pamięci RAM
- Brak pamięci dysku
Najpierw upewnij się, że konfigurujesz rozwiązanie AutoML w najlepszy sposób dla danych. Aby uzyskać więcej informacji, zobacz Odpowiedź Jakiej konfiguracji modelowania należy używać?
W przypadku domyślnych ustawień automatycznego uczenia maszynowego można naprawić błędy braku pamięci RAM przy użyciu węzłów obliczeniowych z większą ilością pamięci RAM. Ogólna zasada polega na tym, że ilość wolnej pamięci RAM powinna być co najmniej 10 razy większa niż rozmiar nieprzetworzonych danych do uruchomienia rozwiązania AutoML z ustawieniami domyślnymi.
Błędy braku pamięci dysku można rozwiązać, usuwając klaster obliczeniowy i tworząc nowy.
Jakie zaawansowane scenariusze prognozowania obsługuje rozwiązanie AutoML?
Rozwiązanie AutoML obsługuje następujące zaawansowane scenariusze przewidywania:
- Prognozy kwantylu
- Niezawodna ocena modelu za pomocą prognoz stopniowych
- Prognozowanie poza horyzont prognozy
- Prognozowanie, gdy między okresami trenowania i prognozowania występuje luka w czasie
Aby uzyskać przykłady i szczegółowe informacje, zobacz notes dla zaawansowanych scenariuszy prognozowania.
Jak mogę wyświetlać metryki z prognozowania zadań szkoleniowych?
Aby znaleźć wartości metryk trenowania i walidacji, zobacz Wyświetlanie informacji o zadaniach lub uruchomieniach w programie Studio. Metryki dla dowolnego modelu prognozowania wytrenowanego w rozwiązaniu AutoML można wyświetlić, przechodząc do modelu z poziomu interfejsu użytkownika zadania automatycznego uczenia maszynowego w studio i wybierając kartę Metryki .
Jak mogę błędy debugowania z prognozowaniem zadań szkoleniowych?
Jeśli zadanie prognozowania automatycznego uczenia maszynowego zakończy się niepowodzeniem, w interfejsie użytkownika programu Studio może pomóc zdiagnozować i rozwiązać problem. Najlepszym źródłem informacji o awarii poza komunikatem o błędzie jest dziennik sterowników dla zadania. Aby uzyskać instrukcje dotyczące znajdowania dzienników sterowników, zobacz Wyświetlanie informacji o zadaniach/uruchomieniach za pomocą biblioteki MLflow.
Uwaga
W przypadku wielu modeli lub zadania HTS trenowanie odbywa się zwykle w klastrach obliczeniowych z wieloma węzłami. Dzienniki dla tych zadań są obecne dla każdego adresu IP węzła. W takim przypadku należy wyszukać dzienniki błędów w każdym węźle. Dzienniki błędów wraz z dziennikami sterowników znajdują się w folderze user_logs dla każdego adresu IP węzła.
Jak mogę wdrożyć model z prognozowania zadań szkoleniowych?
Model można wdrożyć na podstawie zadań trenowania prognozowania na jeden z następujących sposobów:
- Punkt końcowy online: sprawdź plik oceniania używany we wdrożeniu lub wybierz kartę Test na stronie punktu końcowego w studio, aby zrozumieć strukturę danych wejściowych, których oczekuje wdrożenie. Zobacz ten notes , aby zapoznać się z przykładem. Aby uzyskać więcej informacji na temat wdrażania online, zobacz Deploy an AutoML model to an online endpoint (Wdrażanie modelu automatycznego uczenia maszynowego w punkcie końcowym online).
- Punkt końcowy usługi Batch: ta metoda wdrażania wymaga utworzenia niestandardowego skryptu oceniania. Zapoznaj się z tym notesem , aby zapoznać się z przykładem. Aby uzyskać więcej informacji na temat wdrażania wsadowego, zobacz Używanie punktów końcowych wsadowych do oceniania wsadowego.
W przypadku wdrożeń interfejsu użytkownika zachęcamy do korzystania z jednej z następujących opcji:
- Punkt końcowy w czasie rzeczywistym
- Punkt końcowy usługi Batch
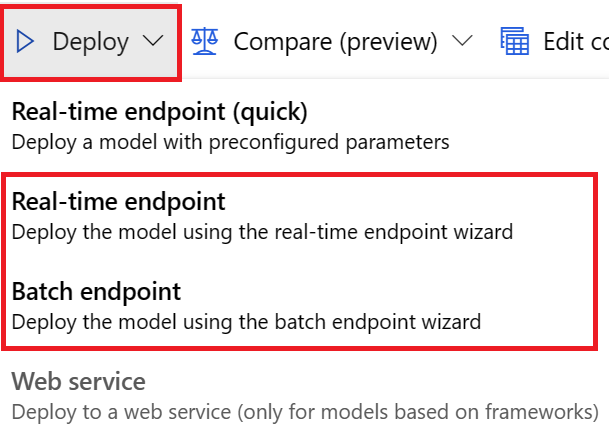
Nie używaj pierwszej opcji punktu końcowego w czasie rzeczywistym (szybki).
Uwaga
Od tej pory nie obsługujemy wdrażania modelu MLflow z prognozowania zadań szkoleniowych za pomocą zestawu SDK, interfejsu wiersza polecenia lub interfejsu użytkownika. Jeśli spróbujesz, wystąpią błędy.
Co to jest obszar roboczy, środowisko, eksperyment, wystąpienie obliczeniowe lub docelowy obiekt obliczeniowy?
Jeśli nie znasz pojęć związanych z usługą Azure Machine Learning, zacznij od artykułu Co to jest usługa Azure Machine Learning? i co to jest obszar roboczy usługi Azure Machine Learning?
Następne kroki
- Dowiedz się więcej o sposobie konfigurowania rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych.
- Dowiedz się więcej o funkcjach kalendarza na potrzeby prognozowania szeregów czasowych w rozwiązaniu AutoML.
- Dowiedz się, jak rozwiązanie AutoML używa uczenia maszynowego do tworzenia modeli prognozowania.
- Dowiedz się więcej na temat prognozowania automatycznego uczenia maszynowego dla funkcji opóźnionych.