Zamiatanie modeli i wybór prognozowania w rozwiązaniu AutoML
W tym artykule opisano, jak zautomatyzowane uczenie maszynowe (AutoML) w usłudze Azure Machine Learning wyszukuje modele prognozowania i wybiera je. Jeśli chcesz dowiedzieć się więcej na temat metodologii prognozowania w rozwiązaniu AutoML, zobacz Omówienie metod prognozowania w rozwiązaniu AutoML. Aby zapoznać się z przykładami trenowania modeli prognozowania w rozwiązaniu AutoML, zobacz Konfigurowanie rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych przy użyciu zestawu SDK i interfejsu wiersza polecenia.
Zamiatanie modeli w rozwiązaniu AutoML
Centralnym zadaniem rozwiązania AutoML jest trenowanie i ocenianie kilku modeli oraz wybór najlepszego w odniesieniu do danej metryki podstawowej. Słowo "model" w tym przypadku odnosi się zarówno do klasy modelu, jak ARIMA lub Random Forest, oraz określonych ustawień hiperparametrów, które odróżniają modele w klasie. Na przykład ARIMA odnosi się do klasy modeli, które współdzielą szablon matematyczny i zestaw założeń statystycznych. Trenowanie lub dopasowywanie modelu ARIMA wymaga listy dodatnich liczb całkowitych określających dokładną formę matematyczną modelu. Te wartości są hiperparami. Modele ARIMA(1, 0, 1) i ARIMA(2, 1, 2) mają tę samą klasę, ale różne parametry hyper-parameters. Te definicje mogą być oddzielnie dopasowane do danych treningowych i oceniane nawzajem. Wyszukiwanie automatycznego uczenia maszynowego lub zamiatanie w różnych klasach modelu i w klasach przez zmianę parametrów hiperparatek.
Metody zamiatania hiperparametrów
W poniższej tabeli przedstawiono różne metody zamiatania hiperparametrów używane przez rozwiązanie AutoML dla różnych klas modeli:
| Grupa klas modelu | Typ modelu | Metoda zamiatania hiperparametrów |
|---|---|---|
| Naiwny, sezonowy naiwny, średnia sezonowa, sezonowa średnia | Szeregi czasowe | Brak zamiatania w klasie ze względu na prostotę modelu |
| Smoothing wykładniczy, ARIMA(X) | Szeregi czasowe | Wyszukiwanie siatki pod kątem zamiatania wewnątrz klasy |
| Prorok | Regresja | Brak zamiatania w klasie |
| Linear SGD, LARS LASSO, Elastic Net, K najbliższych sąsiadów, drzewo decyzyjne, las losowy, bardzo losowe drzewa, gradient wzmocnione drzewa, LightGBM, XGBoost | Regresja | Usługa rekomendacji modelu rozwiązania AutoML dynamicznie eksploruje przestrzenie hiperparametrów |
| ForecastTCN | Regresja | Statyczna lista modeli, po których następuje losowe wyszukiwanie za pośrednictwem rozmiaru sieci, współczynnika dropout i współczynnika uczenia |
Opis różnych typów modeli można znaleźć w sekcji Modele prognozowania w rozwiązaniu AutoML w artykule Omówienie metod prognozowania.
Ilość zamiatania według rozwiązania AutoML zależy od konfiguracji zadania prognozowania. Kryteria zatrzymywania można określić jako limit czasu lub limit liczby prób lub równoważną liczbę modeli. Logika wczesnego zakończenia może być używana w obu przypadkach, aby zatrzymać zamiatanie, jeśli podstawowa metryka nie poprawia się.
Wybór modelu w rozwiązaniu AutoML
Rozwiązanie AutoML jest zgodne z trzyfazowym procesem wyszukiwania i wybierania modeli prognozowania:
Faza 1. Zamiatanie modeli szeregów czasowych i wybieranie najlepszego modelu z każdej klasy przy użyciu maksymalnych metod szacowania prawdopodobieństwa.
Faza 2: Zamiataj modele regresji i klasyfikuj je wraz z najlepszymi modelami szeregów czasowych z fazy 1 zgodnie z ich podstawowymi wartościami metryk z zestawów walidacji.
Faza 3. Tworzenie modelu zespołowego z najlepiej sklasyfikowanych modeli, obliczanie metryki walidacji i klasyfikowanie go przy użyciu innych modeli.
Model z najwyżej sklasyfikowaną wartością metryki na końcu fazy 3 jest wyznaczony jako najlepszy model.
Ważne
W fazie 3 rozwiązanie AutoML zawsze oblicza metryki na przykładowych danych, które nie są używane do dopasowania modeli. Takie podejście pomaga chronić przed nadmiernym dopasowaniem.
Konfiguracje walidacji
Rozwiązanie AutoML ma dwie konfiguracje walidacji: krzyżowe sprawdzanie poprawności i jawne dane weryfikacji.
W przypadku krzyżowego sprawdzania poprawności rozwiązanie AutoML używa konfiguracji danych wejściowych do tworzenia podziałów danych na fałdy trenowania i walidacji. Kolejność czasu musi być zachowana w tych podziałach. Rozwiązanie AutoML używa tak zwanej weryfikacji krzyżowej kroczącego źródła, która dzieli serię na dane trenowania i walidacji przy użyciu punktu czasu pochodzenia. Przesuwanie źródła w czasie generuje fałdy krzyżowej weryfikacji. Każda fałsz weryfikacji zawiera następny horyzont obserwacji bezpośrednio po położeniu źródła dla danej fałdy. Ta strategia zachowuje integralność danych szeregów czasowych i ogranicza ryzyko wycieku informacji.
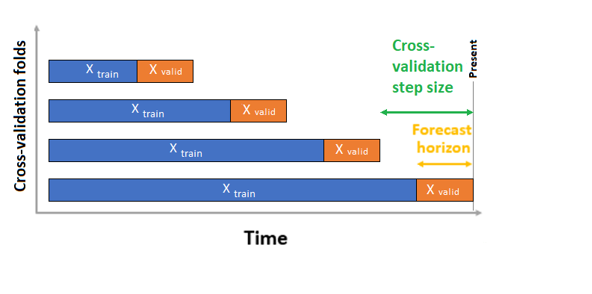
Rozwiązanie AutoML jest zgodne ze zwykłą procedurą krzyżową, trenowanie oddzielnego modelu na każdym fałszowaniu i średniej metryki weryfikacji ze wszystkich składań.
Krzyżowe sprawdzanie poprawności zadań prognozowania jest konfigurowane przez ustawienie liczby fałdów krzyżowej weryfikacji i opcjonalnie liczbę okresów między dwoma kolejnymi fałdami krzyżowymi weryfikacji. Aby uzyskać więcej informacji i przykład konfigurowania krzyżowego sprawdzania poprawności na potrzeby prognozowania, zobacz Niestandardowe ustawienia krzyżowego sprawdzania poprawności.
Możesz również przynieść własne dane weryfikacji. Aby uzyskać więcej informacji, zobacz Configure training, validation, cross-validation, and test data in AutoML (SDK v1)( Konfigurowanie trenowania, walidacji, krzyżowania i testowania danych w zestawie AutoML (SDK w wersji 1).