Trenowanie modelu PyTorch
W tym artykule opisano sposób używania składnika Train PyTorch Model w projektancie usługi Azure Machine Learning do trenowania modeli PyTorch, takich jak DenseNet. Trenowanie odbywa się po zdefiniowaniu modelu i ustawieniu jego parametrów i wymaga danych oznaczonych etykietą.
Obecnie składnik Train PyTorch Model obsługuje zarówno jeden węzeł, jak i trenowanie rozproszone.
Jak używać trenowania modelu PyTorch
Dodaj składnik DenseNet lub sieć ResNet do wersji roboczej potoku w projektancie.
Dodaj składnik Train PyTorch Model (Trenowanie modelu PyTorch) do potoku. Ten składnik można znaleźć w kategorii Trenowanie modelu. Rozwiń węzeł Train (Trenowanie), a następnie przeciągnij składnik Train PyTorch Model (Trenowanie modelu PyTorch) do potoku.
Uwaga
Trenowanie składnika modelu PyTorch jest lepiej uruchamiane na obliczeniach typu procesora GPU dla dużego zestawu danych, w przeciwnym razie potok zakończy się niepowodzeniem. Możesz wybrać obliczenia dla określonego składnika w okienku po prawej stronie składnika, ustawiając opcję Użyj innego docelowego obiektu obliczeniowego.
Po lewej stronie danych wejściowych dołącz nietrenowany model. Dołącz zestaw danych trenowania i zestaw danych walidacji do środkowych i prawych danych wejściowych trenowania modelu PyTorch.
W przypadku nieuszkodzonego modelu musi to być model PyTorch, taki jak DenseNet; w przeciwnym razie zostanie zgłoszony błąd "InvalidModelDirectoryError".
W przypadku zestawu danych zestaw danych trenowania musi być katalogiem obrazów oznaczonym etykietą. Zapoznaj się z tematem Konwertowanie na katalog obrazów, aby dowiedzieć się, jak uzyskać katalog obrazów z etykietą. Jeśli nie zostanie oznaczona etykietą, zostanie zgłoszony błąd "NotLabeledDatasetError".
Zestaw danych trenowania i zestaw danych weryfikacji mają te same kategorie etykiet. W przeciwnym razie zostanie zgłoszony błąd InvalidDatasetError.
W obszarze Epoki określ liczbę epok, które chcesz trenować. Cały zestaw danych będzie iterowany w każdej epoki, domyślnie 5.
W polu Rozmiar partii określ liczbę wystąpień do trenowania w partii domyślnie 16.
W polu Numer kroku Rozgrzewki określ, ile epok chcesz rozgrzać trenowanie, w przypadku gdy początkowy współczynnik uczenia jest nieco za duży, aby rozpocząć zbieżność, domyślnie 0.
W polu Wskaźnik nauki określ wartość współczynnika nauki, a wartość domyślna to 0,001. Szybkość nauki określa rozmiar kroku, który jest używany w optymalizatorze, takim jak sgd za każdym razem, gdy model jest testowany i poprawiany.
Ustawiając szybkość mniejszą, testujesz model częściej, z ryzykiem, że możesz utknąć w lokalnym płaskowyżu. Ustawiając większy współczynnik, można szybciej zbiegać się z ryzykiem przekroczenia prawdziwej minimy.
Uwaga
Jeśli utrata pociągu staje się nan podczas szkolenia, co może być spowodowane zbyt dużym współczynnikiem uczenia się, zmniejszenie szybkości nauki może pomóc. W trenowaniu rozproszonym, aby zachować stabilność spadku gradientu, rzeczywista szybkość uczenia jest obliczana przez
lr * torch.distributed.get_world_size(), ponieważ rozmiar partii grupy procesów to czasy rozmiaru świata pojedynczego procesu. Stosuje się rozkład szybkości uczenia wielomianowego i może pomóc w lepszej wydajności modelu.W przypadku inicjatora losowego opcjonalnie wpisz wartość całkowitą, która ma być używana jako inicjator. Użycie nasion jest zalecane, jeśli chcesz zapewnić powtarzalność eksperymentu między zadaniami.
W przypadku cierpliwości określ liczbę epok wczesnego zatrzymania trenowania, jeśli utrata walidacji nie spadnie z rzędu. domyślnie 3.
W obszarze Częstotliwość drukowania określ częstotliwość drukowania dziennika trenowania dla iteracji w każdej epoki, domyślnie 10.
Prześlij potok. Jeśli zestaw danych ma większy rozmiar, zalecane jest wykonanie obliczeń procesora GPU.
Szkolenie rozproszone
W rozproszonym trenowaniu obciążenia w celu wytrenowania modelu jest podzielony i współużytkowany między wiele mini procesorów nazywanych węzłami roboczymi. Te węzły robocze działają równolegle, aby przyspieszyć trenowanie modelu. Obecnie projektant obsługuje trenowanie rozproszone dla składnika Train PyTorch Model( Trenowanie modelu PyTorch).
Czas trenowania
Trenowanie rozproszone umożliwia trenowanie na dużym zestawie danych, na przykład ImageNet (1000 klas, 1,2 miliona obrazów) w ciągu zaledwie kilku godzin przez trenowanie modelu PyTorch. W poniższej tabeli przedstawiono czas trenowania i wydajność podczas trenowania 50 epok usługi Resnet50 w sieci ImageNet od podstaw na podstawie różnych urządzeń.
| Urządzenia | Czas trenowania | Przepływność trenowania | Dokładność walidacji top-1 | Dokładność walidacji top-5 |
|---|---|---|---|---|
| 16 procesorów GPU V100 | 6h22min | ~3200 Obrazy na sekundę | 68.83% | 88.84% |
| 8 procesorów GPU V100 | 12h21min | ~1670 Obrazy na sekundę | 68.84% | 88.74% |
Kliknij kartę "Metryki" tego składnika i zobacz wykresy metryk trenowania, takie jak "Trenowanie obrazów na sekundę" i "Dokładność top 1".

Jak włączyć trenowanie rozproszone
Aby włączyć trenowanie rozproszone dla składnika Trenowanie modelu PyTorch, można ustawić w ustawieniach zadania w okienku po prawej stronie składnika. Tylko klaster obliczeniowy AML jest obsługiwany na potrzeby trenowania rozproszonego.
Uwaga
Do aktywowania trenowania rozproszonego wymagane jest wiele procesorów GPU, ponieważ składnik trenowania PyTorch modelu NCCL wymaga cuda.
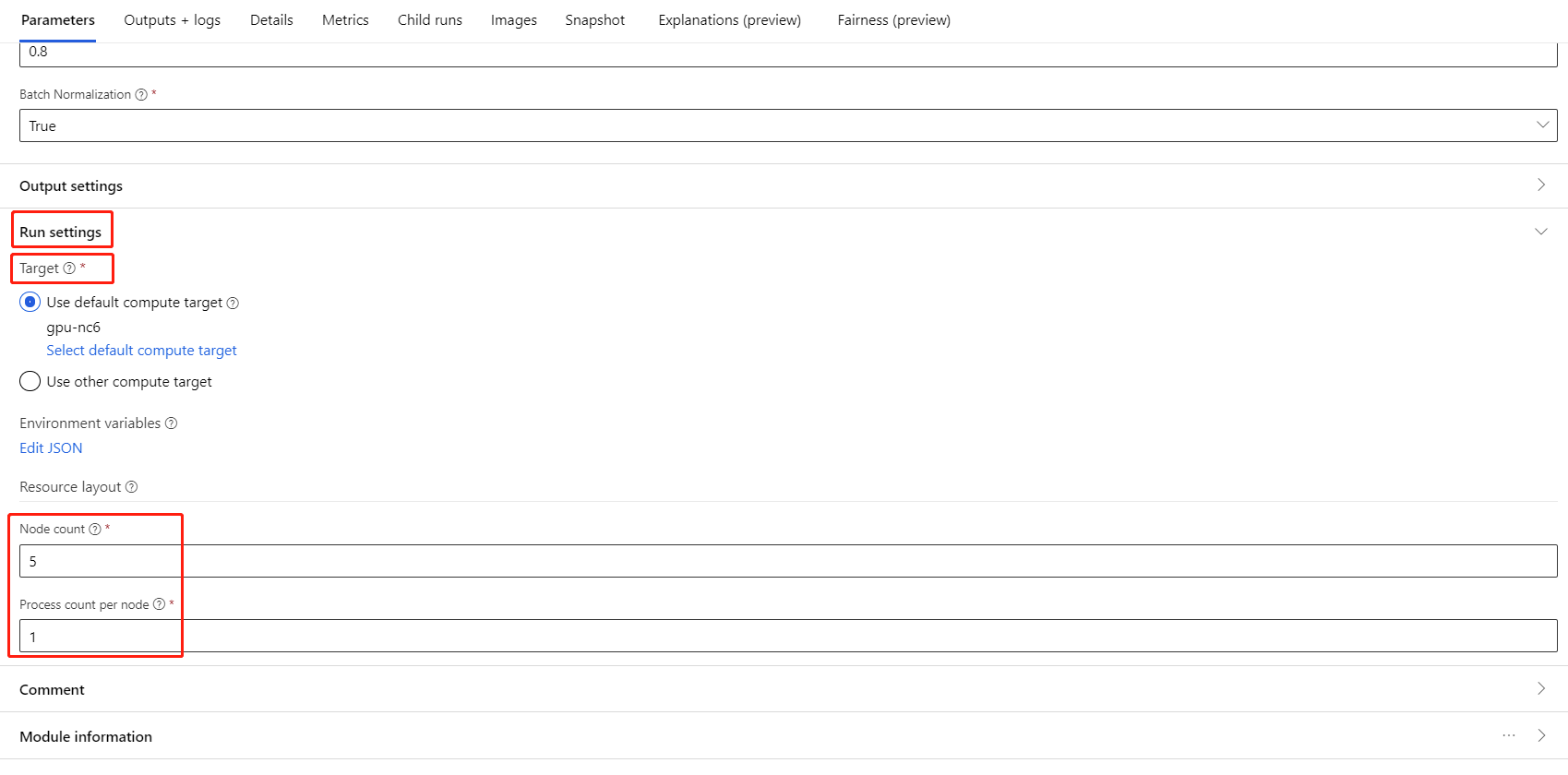
Wybierz składnik i otwórz prawy panel. Rozwiń sekcję Ustawienia zadania.
Upewnij się, że wybrano środowisko obliczeniowe AML dla docelowego obiektu obliczeniowego.
W sekcji Układ zasobu należy ustawić następujące wartości:
Liczba węzłów: liczba węzłów w docelowym obiekcie obliczeniowym używanym do trenowania. Powinna być mniejsza lub równa maksymalnej liczbie węzłów klastra obliczeniowego. Domyślnie jest to 1, co oznacza jednowęźle zadanie.
Liczba procesów na węzeł: liczba procesów wyzwalanych na węzeł. Powinna być mniejsza lub równa jednostce przetwarzania zasobów obliczeniowych. Domyślnie jest to 1, co oznacza jedno zadanie procesu.
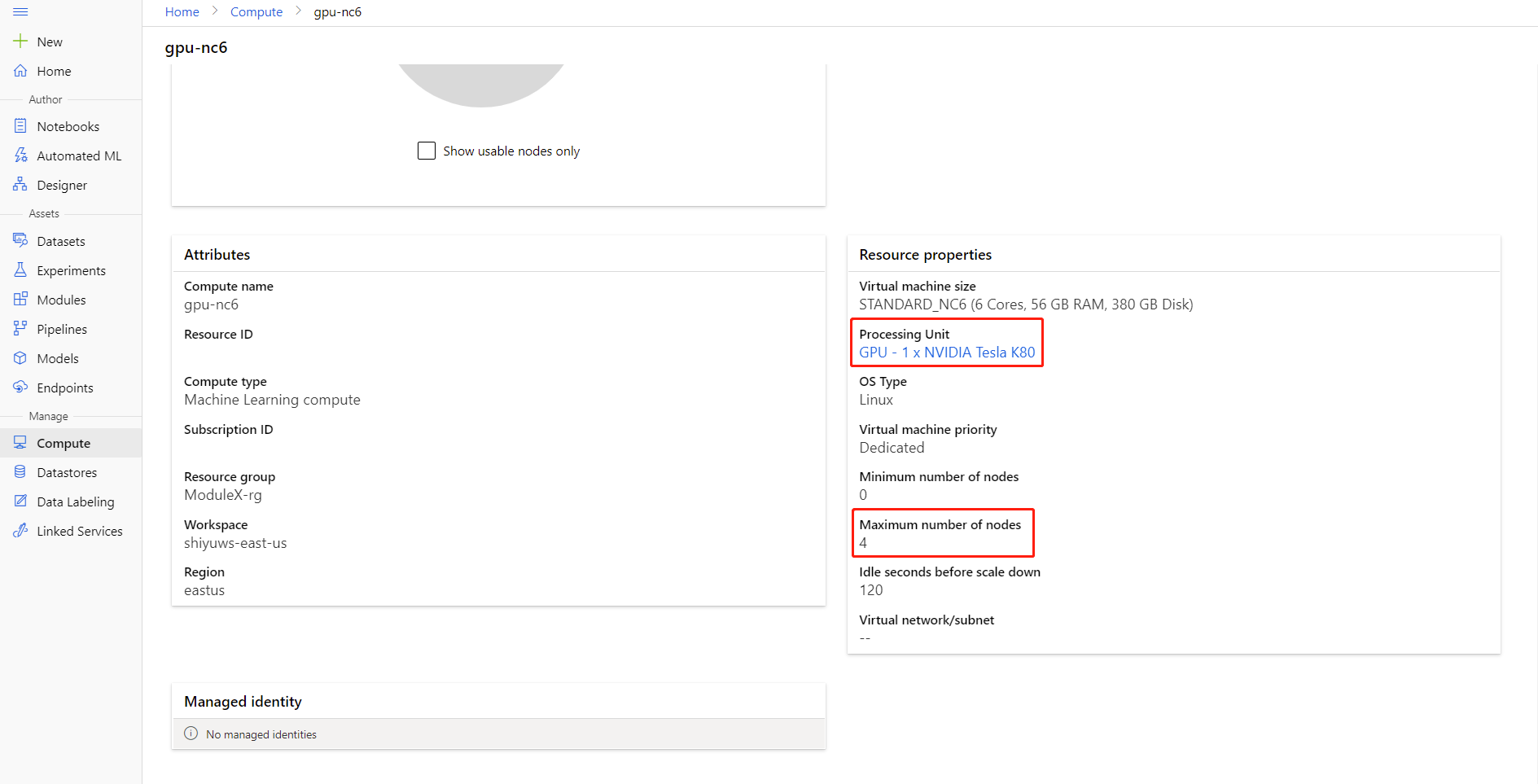
Możesz sprawdzić maksymalną liczbę węzłów i jednostkę przetwarzania zasobów obliczeniowych, klikając nazwę obliczeniową na stronie szczegółów obliczeń.


Więcej informacji na temat trenowania rozproszonego można znaleźć w usłudze Azure Machine Learning tutaj.
Rozwiązywanie problemów z trenowaniem rozproszonym
W przypadku włączenia trenowania rozproszonego dla tego składnika będą dostępne dzienniki sterowników dla każdego procesu. 70_driver_log_0 jest przeznaczony dla procesu głównego. Dzienniki sterowników można sprawdzić pod kątem szczegółów błędów każdego procesu w obszarze Dane wyjściowe i dzienniki kartę w okienku po prawej stronie.

Jeśli trenowanie rozproszone z włączonym składnikiem zakończy się niepowodzeniem bez żadnych 70_driver dzienników, możesz sprawdzić 70_mpi_log szczegóły błędu.
W poniższym przykładzie pokazano typowy błąd, który to liczba procesów na węzeł jest większa niż jednostka przetwarzania obliczeń.

Aby uzyskać więcej informacji na temat rozwiązywania problemów ze składnikami, zapoznaj się z tym artykułem .
Wyniki
Po zakończeniu zadania potoku, aby użyć modelu do oceniania, połącz model Train PyTorch Model (Trenowanie modelu PyTorch) z generowaniem wyników dla modelu obrazu, aby przewidzieć wartości dla nowych przykładów wejściowych.
Uwagi techniczne
Oczekiwane dane wejściowe
| Nazwisko | Pisz | Opis |
|---|---|---|
| Model nieuszkodzony | UntrainedModelDirectory | Nietrenowany model, wymagaj PyTorch |
| Zestaw danych trenowania | ImageDirectory | Zestaw danych trenowania |
| Zestaw danych weryfikacji | ImageDirectory | Zestaw danych weryfikacji do oceny każdej epoki |
Parametry składników
| Nazwisko | Zakres | Typ | Domyślny | opis |
|---|---|---|---|---|
| Epok | >0 | Integer | 5 | Wybierz kolumnę zawierającą etykietę lub kolumnę wyniku |
| Rozmiar partii | >0 | Integer | 16 | Ile wystąpień do trenowania w partii |
| Numer kroku rozgrzewania | >=0 | Integer | 0 | Ile epok rozgrzewa trening |
| Tempo nauki | >=double. Epsilon | Liczba zmiennoprzecinkowa | 0.1 | Wstępny współczynnik uczenia optymalizatora spadku gradientu Stochastic. |
| Inicjator losowy | Dowolne | Integer | 1 | Inicjator dla generatora liczb losowych używanych przez model. |
| Cierpliwość | >0 | Integer | 3 | Ile epok do wczesnego zatrzymania trenowania |
| Częstotliwość drukowania | >0 | Integer | 10 | Częstotliwość drukowania dziennika trenowania na iteracji w każdej epoki |
Dane wyjściowe
| Nazwisko | Pisz | Opis |
|---|---|---|
| Wytrenowany model | ModelDirectory | Wytrenowany model |
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.