Obsługa błędów i wyjątków w usłudze Azure Logic Apps
Dotyczy: Azure Logic Apps (Zużycie + Standardowa)
Sposób, w jaki każda architektura integracji odpowiednio obsługuje przestoje lub problemy spowodowane przez systemy zależne, może stanowić wyzwanie. Aby ułatwić tworzenie niezawodnych i odpornych integracji, które bezpiecznie obsługują problemy i błędy, usługa Azure Logic Apps zapewnia najwyższej klasy środowisko obsługi błędów i wyjątków.
Zasady ponawiania prób
W przypadku najbardziej podstawowych wyjątków i obsługi błędów można użyć zasad ponawiania, gdy są obsługiwane w wyzwalaczu lub akcji, takiej jak akcja HTTP. Jeśli limit czasu oryginalnego żądania lub akcji wyzwalacza lub akcji zakończy się niepowodzeniem, co spowoduje odpowiedź 408, 429 lub 5xx, zasady ponawiania próby określają, że wyzwalacz lub akcja ponownie wyślij żądanie dla ustawień zasad.
Limity zasad ponawiania prób
Aby uzyskać więcej informacji na temat zasad ponawiania prób, ustawień, limitów i innych opcji, zapoznaj się z tematem Retry policy limits (Limity zasad ponawiania prób).
Typy zasad ponawiania prób
Operacje łącznika, które obsługują zasady ponawiania prób, używają zasad domyślnych , chyba że wybierzesz inne zasady ponawiania.
| Zasady ponawiania | opis |
|---|---|
| Wartość domyślna | W przypadku większości operacji domyślne zasady ponawiania to zasada interwału wykładniczego, która wysyła do 4 ponownych prób w interwałach wykładniczo rosnących . Te interwały są skalowane o 7,5 sekundy, ale są ograniczone do zakresu od 5 do 45 sekund. Kilka operacji używa innych domyślnych zasad ponawiania, takich jak zasady o stałym interwale. Aby uzyskać więcej informacji, zapoznaj się z domyślnym typem zasad ponawiania. |
| Brak | Nie wysyłaj ponownie żądania. Aby uzyskać więcej informacji, zobacz Brak — brak zasad ponawiania prób. |
| Interwał wykładniczy | Ta zasada czeka losowy interwał, który jest wybierany z wykładniczo rosnącego zakresu przed wysłaniem następnego żądania. Aby uzyskać więcej informacji, zapoznaj się z typem zasad interwału wykładniczego. |
| Stały interwał | Te zasady czekają określony interwał przed wysłaniem następnego żądania. Aby uzyskać więcej informacji, zapoznaj się z typem zasad o stałym interwale. |
Zmień typ zasad ponawiania próby w projektancie
W witrynie Azure Portal otwórz przepływ pracy aplikacji logiki w projektancie.
W zależności od tego, czy pracujesz nad przepływem pracy Zużycie, czy Standardowy, otwórz wyzwalacz lub akcję Ustawienia.
Zużycie: W kształcie akcji otwórz menu wielokropka (...) i wybierz pozycję Ustawienia.
Standardowa: w projektancie wybierz akcję. W okienku szczegółów wybierz pozycję Ustawienia.
Jeśli wyzwalacz lub akcja obsługuje zasady ponawiania prób, w obszarze Zasady ponawiania wybierz odpowiedni typ zasad.
Zmień typ zasad ponawiania próby w edytorze widoku kodu
W razie potrzeby sprawdź, czy wyzwalacz lub akcja obsługuje zasady ponawiania, wykonując wcześniejsze kroki w projektancie.
Otwórz przepływ pracy aplikacji logiki w edytorze widoku kodu.
W definicji wyzwalacza lub akcji dodaj
retryPolicyobiekt JSON do tego obiektu wyzwalacza lub akcjiinputs. W przeciwnym razie, jeśli żaden obiekt nieretryPolicyistnieje, wyzwalacz lub akcja używadefaultzasad ponawiania."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Wymagane
Właściwości Wartość Type Opis type< retry-policy-type> String Typ zasad ponawiania do użycia: default, ,nonefixedlubexponentialcount< ponawianie prób> Integer W przypadku fixedtypów zasad iexponentialliczba ponownych prób, czyli wartość od 1 do 90. Aby uzyskać więcej informacji, zapoznaj się z interwałem stałym i interwałem wykładniczym.interval< interwał ponawiania prób> String W przypadku fixedtypów zasad iexponentialwartość interwału ponawiania prób w formacie ISO 8601. W przypadkuexponentialzasad można również określić opcjonalne interwały maksymalne i minimalne. Aby uzyskać więcej informacji, zapoznaj się z interwałem stałym i interwałem wykładniczym.
Zużycie: 5 sekund (PT5S) do 1 dnia (P1D).
Standardowa: w przypadku stanowych przepływów pracy od 5 sekund (PT5S) do 1 dnia (P1D). W przypadku bezstanowych przepływów pracy od 1 sekundy (PT1S) do 1 minuty (PT1M).Opcjonalne
Właściwości Wartość Type Opis maximumInterval< maksymalny interwał> String W przypadku exponentialzasad największy interwał dla losowo wybranego interwału w formacie ISO 8601. Wartość domyślna to 1 dzień (P1D). Aby uzyskać więcej informacji, zapoznaj się z interwałem wykładniczym.minimumInterval< minimalny interwał> String W przypadku exponentialzasad najmniejszy interwał dla losowo wybranego interwału w formacie ISO 8601. Wartość domyślna to 5 sekund (PT5S). Aby uzyskać więcej informacji, zapoznaj się z interwałem wykładniczym.
Domyślna polityka ponawiania
Operacje łącznika, które obsługują zasady ponawiania prób, używają zasad domyślnych , chyba że wybierzesz inne zasady ponawiania. W przypadku większości operacji domyślne zasady ponawiania to zasada interwału wykładniczego, która wysyła do 4 ponownych prób w interwałach wykładniczo rosnących . Te interwały są skalowane o 7,5 sekundy, ale są ograniczone do zakresu od 5 do 45 sekund. Kilka operacji używa innych domyślnych zasad ponawiania, takich jak zasady o stałym interwale.
W definicji przepływu pracy definicja wyzwalacza lub akcji nie definiuje jawnie zasad domyślnych, ale w poniższym przykładzie pokazano, jak działają domyślne zasady ponawiania dla akcji HTTP:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Brak — brak zasad ponawiania prób
Aby określić, że akcja lub wyzwalacz nie ponawia próby nieudanych żądań, ustaw <typ> zasad ponawiania na nonewartość .
Zasady ponawiania stałych interwałów
Aby określić, że akcja lub wyzwalacz czeka określony interwał przed wysłaniem następnego żądania, ustaw <wartość retry-policy-type> na fixed.
Przykład
Te zasady ponawiania próby pobrania najnowszych wiadomości jeszcze dwa razy po pierwszym niepomyślnym żądaniu z 30-sekundowym opóźnieniem między poszczególnymi próbami:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Zasady ponawiania interwałów wykładniczych
Zasady ponawiania interwałów wykładniczych określają, że wyzwalacz lub akcja czeka losowy interwał przed wysłaniem następnego żądania. Ten losowy interwał jest wybierany z wykładniczo rosnącego zakresu. Opcjonalnie można zastąpić domyślne minimalne i maksymalne interwały, określając własne minimalne i maksymalne interwały na podstawie tego, czy masz przepływ pracy aplikacji logiki Zużycie, czy Standardowa.
| Nazwisko | Limit użycia | Limit standardowy | Uwagi |
|---|---|---|---|
| Maksymalne opóźnienie | Ustawienie domyślne: 1 dzień | Ustawienie domyślne: 1 godzina | Aby zmienić domyślny limit w przepływie pracy aplikacji logiki Zużycie, użyj parametru zasad ponawiania. Aby zmienić limit domyślny w przepływie pracy aplikacji logiki w warstwie Standardowa, zapoznaj się z artykułem Edytowanie ustawień hosta i aplikacji dla aplikacji logiki w usłudze Azure Logic Apps z jedną dzierżawą. |
| Minimalne opóźnienie | Ustawienie domyślne: 5 s | Ustawienie domyślne: 5 s | Aby zmienić domyślny limit w przepływie pracy aplikacji logiki Zużycie, użyj parametru zasad ponawiania. Aby zmienić limit domyślny w przepływie pracy aplikacji logiki w warstwie Standardowa, zapoznaj się z artykułem Edytowanie ustawień hosta i aplikacji dla aplikacji logiki w usłudze Azure Logic Apps z jedną dzierżawą. |
Zakresy zmiennych losowych
W przypadku zasad ponawiania interwałów wykładniczych w poniższej tabeli przedstawiono ogólny algorytm używany przez usługę Azure Logic Apps do generowania jednolitej zmiennej losowej w określonym zakresie dla każdego ponawiania próby. Określony zakres może zawierać maksymalnie liczbę ponownych prób.
| Numer ponawiania próby | Minimalny interwał | Maksymalny interwał |
|---|---|---|
| 1 | max(0, <minimalny interwał>) | min(interwał, <maksymalny interwał>) |
| 2 | max(interwał, <minimalny interwał>) | min(2 * interwał, <maksymalny interwał>) |
| 3 | max(2 * interwał, <minimalny interwał>) | min(4 * interwał, <maksymalny interwał>) |
| 100 | max(4 * interwał, <minimalny interwał>) | min(8 * interwał, <maksymalny interwał>) |
| .... | .... | .... |
Zarządzanie zachowaniem "uruchom po"
Podczas dodawania akcji w projektancie przepływu pracy niejawnie deklarujesz kolejność użycia do uruchamiania tych akcji. Po zakończeniu działania akcja ta jest oznaczona stanem, takim jak Powodzenie, Niepowodzenie, Pominięte lub Przekroczenie limitu czasu. Domyślnie akcja dodana w projektancie jest uruchamiana dopiero po zakończeniu poprzedniego działania ze stanem Powodzenie . W definicji bazowej akcji właściwość określa, że poprzednia akcja, runAfter która musi się najpierw zakończyć, a stany dozwolone dla tego poprzednika przed uruchomieniem akcji następnika.
Gdy akcja zgłasza nieobsługiwany błąd lub wyjątek, akcja jest oznaczona jako Niepowodzenie, a każda akcja następnika jest oznaczona jako Pominięta. Jeśli to zachowanie ma miejsce w przypadku akcji zawierającej gałęzie równoległe, aparat usługi Azure Logic Apps jest zgodny z innymi gałęziami w celu określenia ich stanu ukończenia. Jeśli na przykład gałąź kończy się akcją Pominięto , stan ukończenia tej gałęzi zależy od stanu poprzednika tej akcji. Po zakończeniu przebiegu przepływu pracy aparat określa stan całego przebiegu, oceniając wszystkie stany gałęzi. Jeśli jakakolwiek gałąź zakończy się niepowodzeniem, cały przebieg przepływu pracy zostanie oznaczony jako Niepowodzenie.
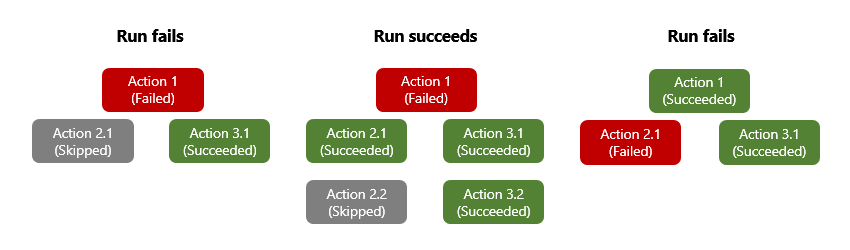
Aby upewnić się, że akcja może nadal działać pomimo stanu poprzednika, możesz zmienić zachowanie "uruchom po" akcji, aby obsłużyć nieudane stany poprzednika. W ten sposób akcja jest uruchamiana, gdy stan poprzednika to Powodzenie, Niepowodzenie, Pominięto, Limit czasu lub wszystkie te stany.
Aby na przykład uruchomić akcję Wyślij wiadomość e-mail w usłudze Office 365 Outlook po dodaniu wiersza do poprzedniej akcji tabeli, zamiast powodzenia, zmień zachowanie "Uruchom po" przy użyciu projektanta lub edytora widoku kodu.
Uwaga
W projektancie ustawienie "Uruchom po" nie ma zastosowania do akcji, która natychmiast następuje po wyzwalaczu, ponieważ wyzwalacz musi zostać uruchomiony pomyślnie, zanim będzie można uruchomić pierwszą akcję.
Zmiana zachowania "Uruchom po" w projektancie
W witrynie Azure Portal otwórz przepływ pracy aplikacji logiki w projektancie.
W projektancie wybierz kształt akcji. W okienku szczegółów wybierz pozycję Ustawienia.
W sekcji Uruchom po w okienku Ustawienia jest wyświetlana akcja poprzednika dla aktualnie wybranej akcji.
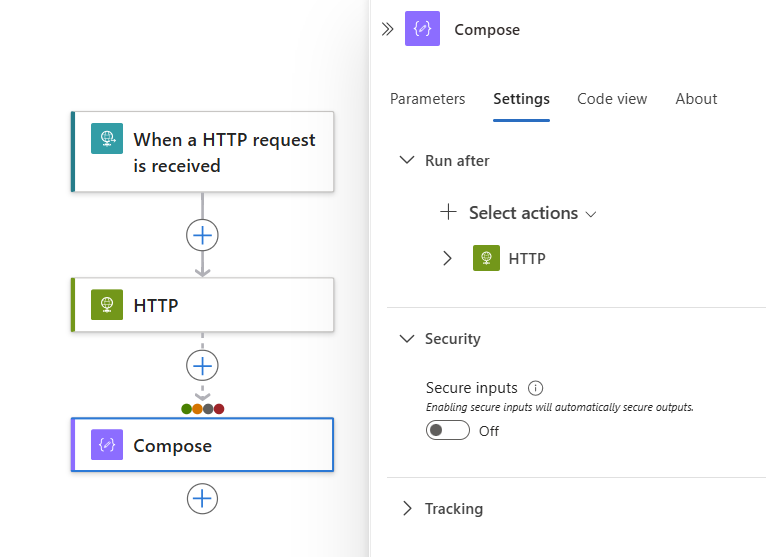
Rozwiń akcję poprzednika, aby wyświetlić wszystkie możliwe stany poprzedników.
Domyślnie stan "Uruchom po" jest ustawiony na Wartość Jest pomyślna. Dlatego poprzednia akcja musi zakończyć się pomyślnie przed uruchomieniem aktualnie wybranej akcji.
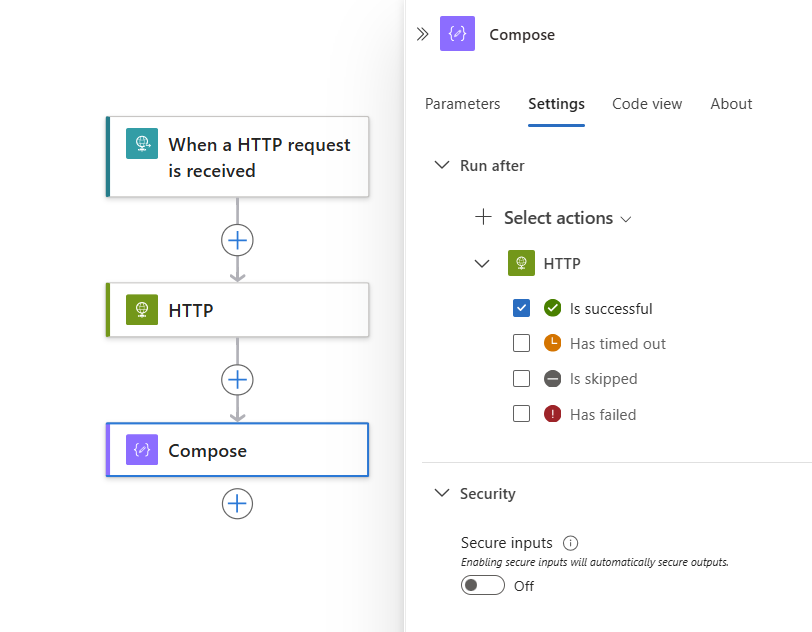
Aby zmienić zachowanie "Uruchom po" na żądane stany, wybierz te stany. Przed wyczyszczeniem opcji domyślnej należy najpierw wybrać opcję. Zawsze musisz mieć wybraną co najmniej jedną opcję.
W poniższym przykładzie wybrano pozycję Nie powiodło się.
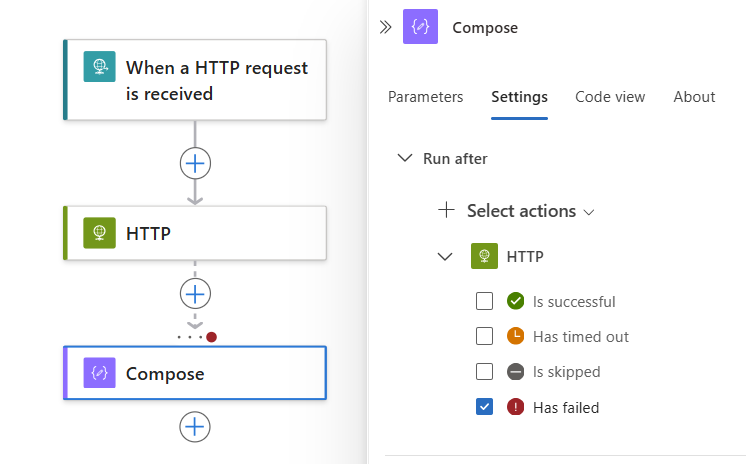
Aby określić, że bieżąca akcja jest uruchamiana, gdy poprzednia akcja zakończy się z stanem Niepowodzenie, Pominięte lub Limit czasu, wybierz te stany.
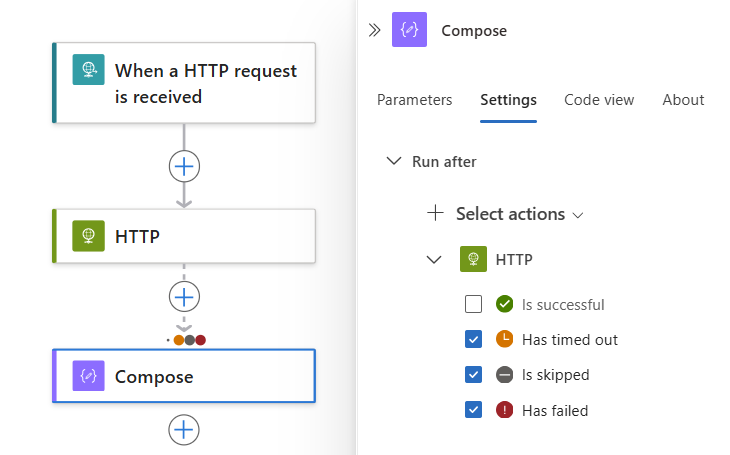
Aby wymagać uruchomienia więcej niż jednej akcji poprzednika, każdy z ich własnymi stanami "uruchom po", rozwiń listę Wybierz akcje . Wybierz żądane akcje poprzednika i określ wymagane stany "uruchom po".
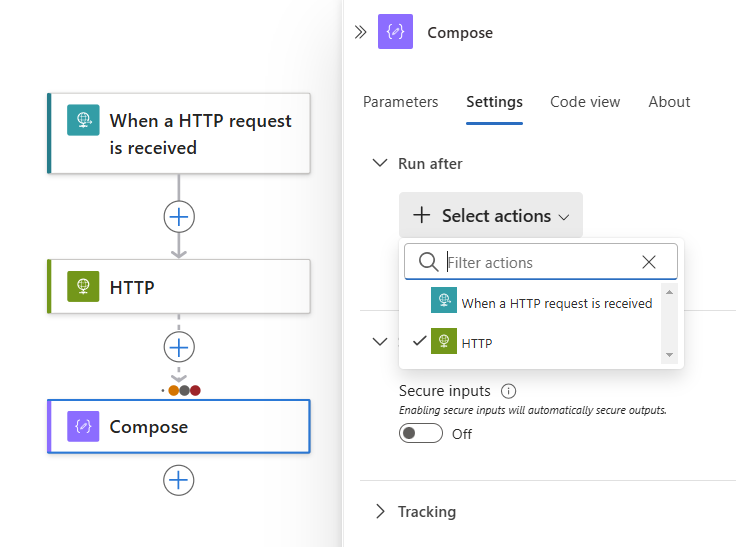
Gdy wszystko będzie gotowe, wybierz pozycję Gotowe.
Zmiana zachowania "Uruchom po" w edytorze widoku kodu
W witrynie Azure Portal otwórz przepływ pracy aplikacji logiki w edytorze widoku kodu.
W definicji JSON akcji zmodyfikuj
runAfterwłaściwość, która ma następującą składnię:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }W tym przykładzie
runAfterzmień właściwość zSucceedednaFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Aby określić, czy akcja jest uruchamiana, czy poprzednia akcja jest oznaczona jako
Failed,SkippedlubTimedOut, dodaj inne stany:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Ocenianie akcji przy użyciu zakresów i ich wyników
Podobnie jak w przypadku uruchamiania kroków po poszczególnych akcjach z ustawieniem "Uruchom po", można grupować akcje w zakresie. Zakresy można używać, gdy chcesz logicznie grupować akcje, oceniać stan agregacji zakresu i wykonywać akcje na podstawie tego stanu. Po zakończeniu działania wszystkich akcji w zakresie sam zakres uzyskuje własny stan.
Aby sprawdzić stan zakresu, możesz użyć tych samych kryteriów, które są używane do sprawdzania stanu uruchomienia przepływu pracy, takich jak Powodzenie, Niepowodzenie itd.
Domyślnie po pomyślnym pomyślnym zakończeniu wszystkich akcji zakresu stan zakresu jest oznaczony jako Powodzenie. Jeśli ostateczna akcja w zakresie jest oznaczona jako Niepowodzenie lub Przerwana, stan zakresu zostanie oznaczony jako Niepowodzenie.
Aby przechwycić wyjątki w zakresie Niepowodzenie i uruchomić akcje obsługujące te błędy, możesz użyć ustawienia "Uruchom po", które ma zakres Niepowodzenie . W ten sposób, jeśli jakiekolwiek akcje w zakresie kończą się niepowodzeniem i używasz ustawienia "Uruchom po" dla tego zakresu, możesz utworzyć jedną akcję w celu przechwycenia błędów.
Aby uzyskać informacje o limitach w zakresach, zobacz Limity i konfiguracja.
Konfigurowanie zakresu z funkcją "Uruchom po" na potrzeby obsługi wyjątków
W witrynie Azure Portal otwórz przepływ pracy aplikacji logiki w projektancie.
Przepływ pracy musi już mieć wyzwalacz, który uruchamia przepływ pracy.
W projektancie wykonaj te ogólne kroki, aby dodać akcję Kontrolkao nazwie Zakres do przepływu pracy.
W akcji Zakres wykonaj następujące ogólne kroki, aby dodać akcje do uruchomienia, na przykład:
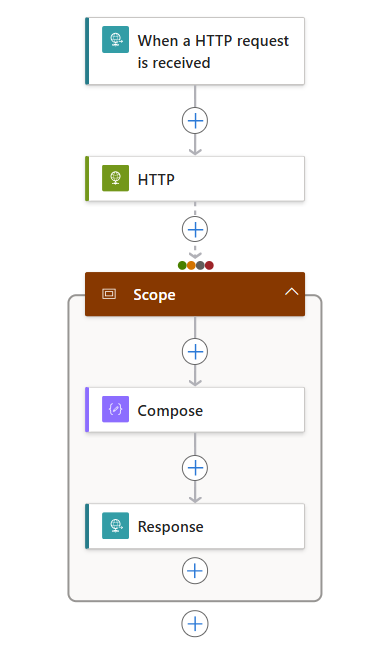
Na poniższej liście przedstawiono przykładowe akcje, które można uwzględnić w akcji Zakres :
- Pobieranie danych z interfejsu API.
- Przetwarzanie danych.
- Zapisz dane w bazie danych.
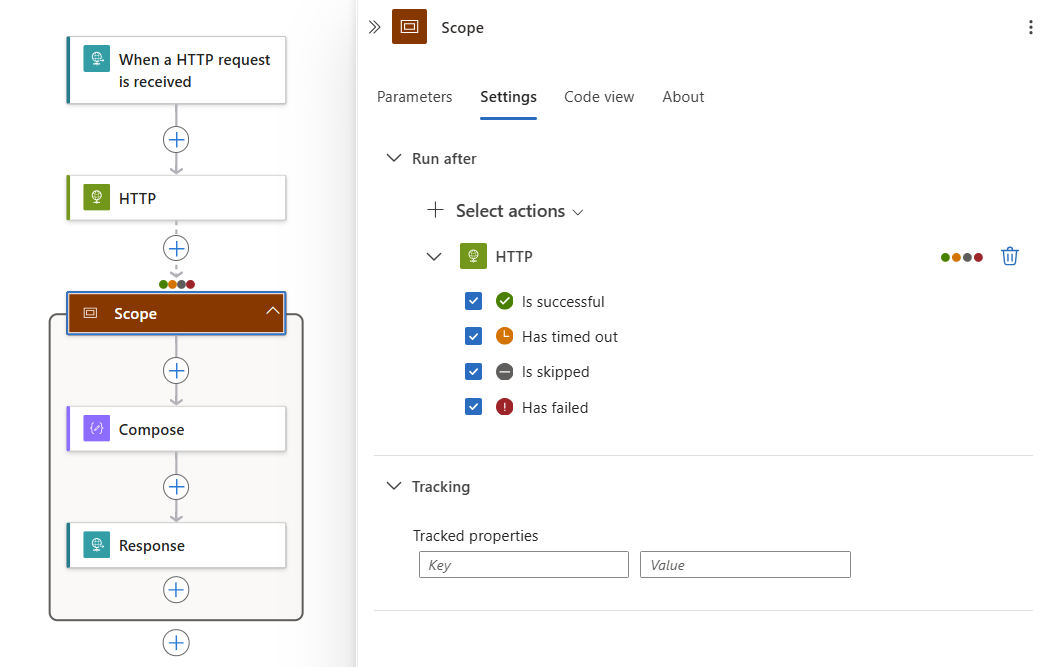
Teraz zdefiniuj reguły "Uruchom po" na potrzeby uruchamiania akcji w zakresie.
W projektancie wybierz tytuł Zakres . Po otwarciu okienka informacji o zakresie wybierz pozycję Ustawienia.
Jeśli masz więcej niż jedną poprzednią akcję w przepływie pracy, z listy Wybierz akcje wybierz akcję, po której chcesz uruchomić akcje o określonym zakresie.
Dla wybranej akcji wybierz wszystkie stany akcji, które mogą uruchamiać akcje o określonym zakresie.
Innymi słowy, każdy z wybranych stanów, które wynikają z wybranej akcji, powoduje, że akcje w zakresie do uruchomienia.
W poniższym przykładzie akcje o określonym zakresie są uruchamiane po zakończeniu akcji HTTP z dowolnymi wybranymi stanami:
Pobieranie kontekstu i wyników dla niepowodzeń
Chociaż przechwytywanie błędów z zakresu jest przydatne, możesz również chcieć uzyskać więcej kontekstu, aby ułatwić poznanie dokładnych akcji, które zakończyły się niepowodzeniem, oraz wszelkich błędów lub kodów stanu. Funkcja result() zwraca wyniki z akcji najwyższego poziomu w akcji o określonym zakresie. Ta funkcja akceptuje nazwę zakresu jako pojedynczy parametr i zwraca tablicę z wynikami z tych akcji najwyższego poziomu. Te obiekty akcji mają te same atrybuty co atrybuty zwracane przez actions() funkcję, takie jak czas rozpoczęcia akcji, czas zakończenia, stan, dane wejściowe, identyfikatory korelacji i dane wyjściowe.
Uwaga
Funkcja result() zwraca wyniki tylko z akcji najwyższego poziomu, a nie z bardziej zagnieżdżonych akcji, takich jak akcje przełączania lub warunku.
Aby uzyskać kontekst dotyczący akcji, które zakończyły się niepowodzeniem w zakresie, możesz użyć @result() wyrażenia z nazwą zakresu i ustawieniem "Uruchom po". Aby odfiltrować zwróconą tablicę do akcji, które mają stan Niepowodzenie, możesz dodać akcję Filtruj tablicę. Aby uruchomić akcję dla zwróconej akcji zakończonej niepowodzeniem, wykonaj zwróconą filtrowaną tablicę i użyj pętli Dla każdej pętli.
Poniższy przykład JSON wysyła żądanie HTTP POST z treścią odpowiedzi dla akcji, które zakończyły się niepowodzeniem w ramach akcji zakresu o nazwie My_Scope. Szczegółowy opis jest zgodny z przykładem.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
W poniższych krokach opisano, co się dzieje w tym przykładzie:
Aby uzyskać wynik ze wszystkich akcji wewnątrz My_Scope, akcja Filtruj tablicę używa tego wyrażenia filtru:
@result('My_Scope')Warunek dla tablicy filtrów to dowolny
@result()element, który ma stan równyFailed. Ten warunek filtruje tablicę zawierającą wszystkie wyniki akcji z My_Scope do tablicy z tylko wynikami akcji zakończonej niepowodzeniem.For_eachWykonaj akcję pętli na filtrowanych danych wyjściowych tablicy. Ten krok wykonuje akcję dla każdego wyniku akcji zakończonego niepowodzeniem, który został wcześniej odfiltrowany.Jeśli pojedyncza akcja w zakresie zakończy się niepowodzeniem, akcje w
For_eachpętli są uruchamiane tylko raz. Wiele nieudanych akcji powoduje jedną akcję na awarię.Wyślij wpis HTTP POST w
For_eachtreści odpowiedzi elementu, który jest wyrażeniem@item()['outputs']['body'].@result()Kształt elementu jest taki sam jak@actions()kształt i może być analizowany w taki sam sposób.Dołącz dwa nagłówki niestandardowe z nazwą akcji, która zakończyła się niepowodzeniem (
@item()['name']) i identyfikatorem śledzenia klienta nieudanego uruchomienia (@item()['clientTrackingId']).
Aby uzyskać odwołanie, poniżej przedstawiono przykład pojedynczego @result() elementu, który pokazuje namewłaściwości , bodyi clientTrackingId , które są analizowane w poprzednim przykładzie. Poza akcją For_each@result() zwraca tablicę tych obiektów.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Aby wykonać różne wzorce obsługi wyjątków, możesz użyć wyrażeń opisanych wcześniej w tym artykule. Możesz wykonać jedną akcję obsługi wyjątków poza zakresem, która akceptuje całą filtrowaną tablicę niepowodzeń, i usunąć For_each akcję. Możesz również uwzględnić inne przydatne właściwości z odpowiedzi zgodnie z \@result() wcześniejszym opisem.
Konfigurowanie dzienników usługi Azure Monitor
Poprzednie wzorce są przydatnymi sposobami obsługi błędów i wyjątków występujących w ramach przebiegu. Można jednak również identyfikować błędy występujące niezależnie od przebiegu i reagować na nie. Aby ocenić stan uruchomienia, możesz monitorować dzienniki i metryki przebiegów lub publikować je w dowolnym preferowanym narzędziu do monitorowania.
Na przykład usługa Azure Monitor zapewnia usprawniony sposób wysyłania wszystkich zdarzeń przepływu pracy, w tym wszystkich stanów uruchamiania i akcji, do miejsca docelowego. Alerty dla określonych metryk i progów można skonfigurować w usłudze Azure Monitor. Zdarzenia przepływu pracy można również wysyłać do obszaru roboczegousługi Log Analytics lub konta usługi Azure Storage. Możesz też przesyłać strumieniowo wszystkie zdarzenia za pośrednictwem usługi Azure Event Hubs do usługi Azure Stream Analytics. W usłudze Stream Analytics można pisać zapytania na żywo na podstawie wszelkich anomalii, średnich lub niepowodzeń z dzienników diagnostycznych. Usługi Stream Analytics można użyć do wysyłania informacji do innych źródeł danych, takich jak kolejki, tematy, SQL, Azure Cosmos DB lub Power BI.
Aby uzyskać więcej informacji, zobacz Konfigurowanie dzienników usługi Azure Monitor i zbieranie danych diagnostycznych dla usługi Azure Logic Apps.