Samouczek: uzyskiwanie szczegółowych informacji z przetworzonych danych
W tym samouczku wypełnisz pulpit nawigacyjny w czasie rzeczywistym, aby przechwycić szczegółowe informacje z danych OPC UA wysłanych do usługi Event Hubs w poprzednim samouczku. Korzystając z analizy czasu rzeczywistego usługi Microsoft Fabric, możesz przenieść dane z usługi Event Hubs do usługi Microsoft Fabric i zamapować je do bazy danych KQL, która może być źródłem pulpitów nawigacyjnych czasu rzeczywistego. Następnie utworzysz pulpit nawigacyjny, aby wyświetlić te dane na kafelkach wizualizacji, które przechwytują szczegółowe informacje i pokazują wartości w czasie.
Te operacje są ostatnimi krokami w przykładowym środowisku kompleksowego samouczka, który przechodzi od wdrażania operacji usługi Azure IoT na urządzeniach brzegowych dzięki uzyskiwaniu szczegółowych informacji z tych danych urządzenia w chmurze.
Wymagania wstępne
Przed rozpoczęciem tego samouczka musisz ukończyć samouczek: wysyłanie danych telemetrycznych zasobów do chmury przy użyciu przepływu danych
Potrzebna jest również subskrypcja usługi Microsoft Fabric. W ramach subskrypcji musisz mieć dostęp do obszaru roboczego z uprawnieniami współautora lub wyższymi uprawnieniami.
Ponadto dzierżawa sieci szkieletowej musi zezwalać na tworzenie pulpitów nawigacyjnych w czasie rzeczywistym. Jest to ustawienie, które można włączyć przez administratora dzierżawy. Aby uzyskać więcej informacji, zobacz Włączanie ustawień dzierżawy w portalu administracyjnym.
Jaki problem rozwiążemy?
Gdy dane OPC UA dotarły do chmury, będziesz mieć wiele informacji dostępnych do przeanalizowania. Możesz zorganizować te dane i utworzyć raporty zawierające grafy i wizualizacje, aby uzyskać szczegółowe informacje na podstawie danych. Kroki opisane w tym samouczku ilustrują sposób łączenia tych danych z analizą w czasie rzeczywistym i tworzenia pulpitu nawigacyjnego w czasie rzeczywistym.
Pozyskiwanie danych do analizy w czasie rzeczywistym
W tej sekcji skonfigurujesz strumień zdarzeń usługi Microsoft Fabric w celu połączenia centrum zdarzeń z bazą danych KQL w analizie czasu rzeczywistego. Ten proces obejmuje skonfigurowanie mapowania danych w celu przekształcenia danych ładunku z formatu JSON na kolumny w języku KQL.
Tworzenie strumienia zdarzeń
W tej sekcji utworzysz strumień zdarzeń, który będzie używany do przeniesienia danych z usługi Event Hubs do analizy czasu rzeczywistego usługi Microsoft Fabric, a ostatecznie do bazy danych KQL.
Zacznij od przechodzenia do środowiska analizy w czasie rzeczywistym w usłudze Microsoft Fabric i otwierania obszaru roboczego usługi Fabric.
Wykonaj kroki opisane w temacie Tworzenie strumienia zdarzeń w usłudze Microsoft Fabric , aby utworzyć nowy zasób strumienia zdarzeń w obszarze roboczym.
Po utworzeniu strumienia zdarzeń zobaczysz edytor główny, w którym można rozpocząć tworzenie strumienia zdarzeń.
Dodawanie centrum zdarzeń jako źródła
Następnie dodaj centrum zdarzeń z poprzedniego samouczka jako źródło danych dla strumienia zdarzeń.
Wykonaj kroki opisane w artykule Dodawanie źródła usługi Azure Event Hubs do strumienia zdarzeń, aby dodać źródło zdarzeń. Pamiętaj o następujących uwagach:
- Utworzysz nowe połączenie w chmurze z uwierzytelnianiem klucza dostępu współdzielonego.
- Upewnij się, że w centrum zdarzeń włączono uwierzytelnianie lokalne. Tę opcję można ustawić na stronie Przegląd w witrynie Azure Portal.
- W obszarze Grupa odbiorców użyj zaznaczenia domyślnego ($Default).
- W obszarze Format danych wybierz pozycję Json (można go wybrać już domyślnie).
Po ukończeniu tego przepływu centrum zdarzeń platformy Azure jest widoczne w widoku na żywo transmisji zdarzeń jako źródła.
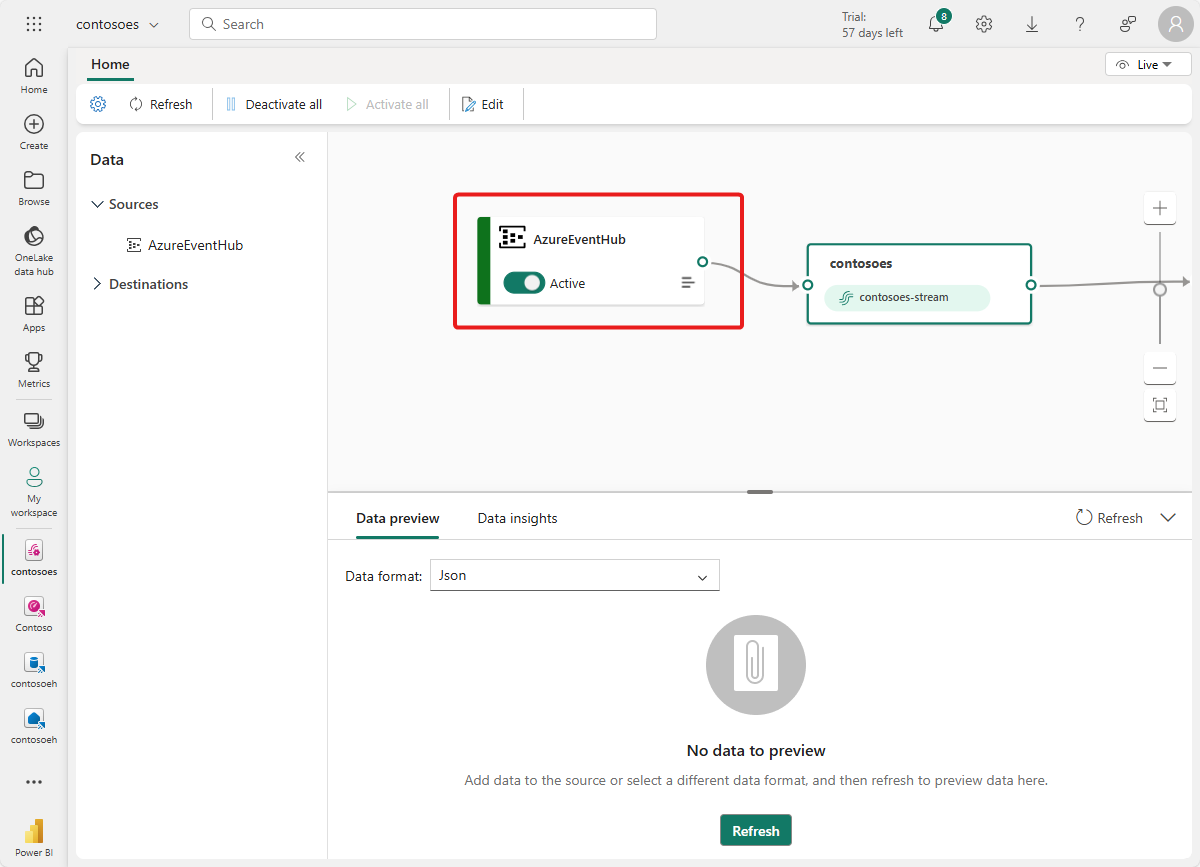
Weryfikowanie przepływu danych
Wykonaj następujące kroki, aby sprawdzić swoją pracę do tej pory i upewnić się, że dane przepływają do strumienia zdarzeń.
Uruchom klaster, w którym wdrożono operacje usługi Azure IoT we wcześniejszych samouczkach. Symulator OPC PLC wdrożony za pomocą wystąpienia operacji usługi Azure IoT powinien zacząć działać i wysyłać dane do brokera MQTT. Tę część przepływu można sprawdzić przy użyciu mqttui zgodnie z opisem w artykule Weryfikowanie przepływu danych.
Poczekaj kilka minut na propagację danych. Następnie w widoku na żywo transmisji strumieniowej zdarzeń wybierz źródło usługi AzureEventHub i odśwież podgląd danych. W tabeli powinny zostać wyświetlone dane JSON z symulatora.
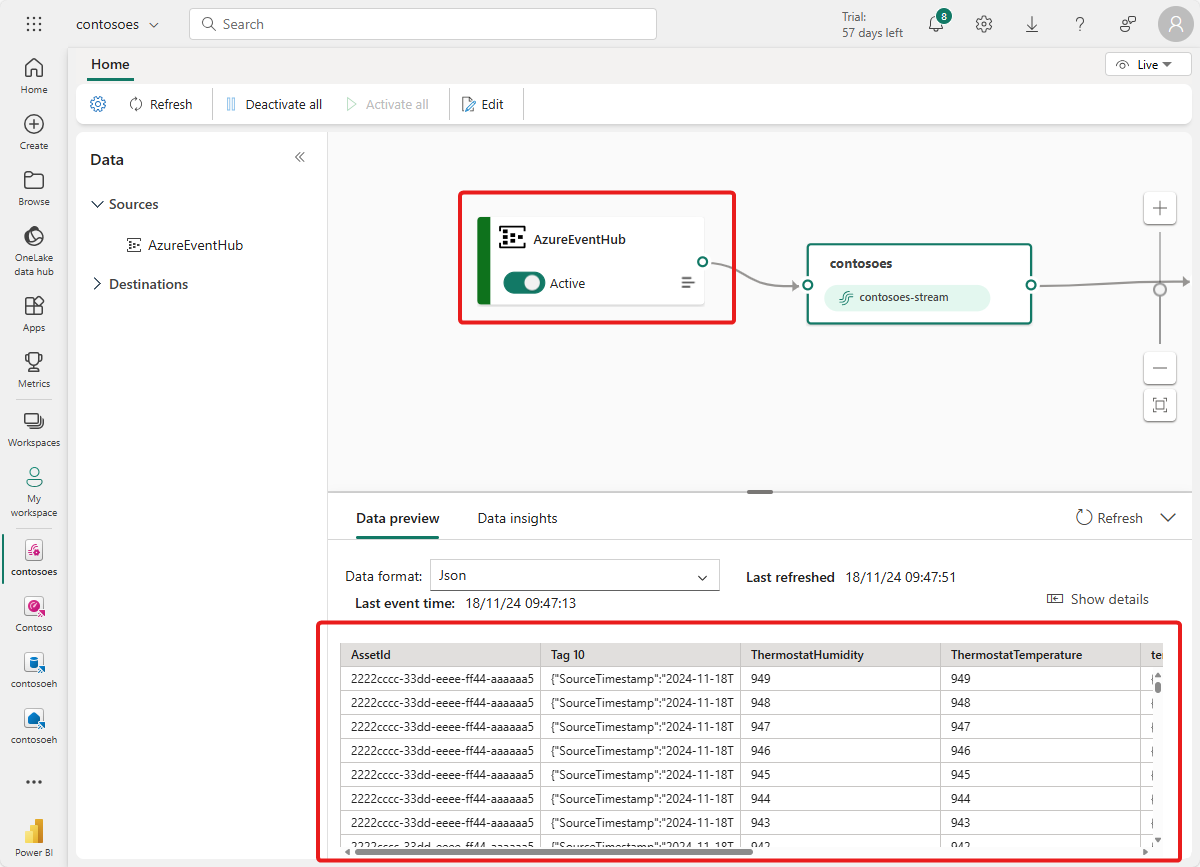
Napiwek
Jeśli dane nie dotarły do strumienia zdarzeń, możesz sprawdzić działanie centrum zdarzeń, aby sprawdzić, czy odbiera komunikaty. Pomoże to wyizolować sekcję przepływu do debugowania.
Przygotowywanie zasobów KQL
W tej sekcji utworzysz bazę danych KQL w obszarze roboczym usługi Microsoft Fabric, która będzie używana jako miejsce docelowe danych.
Wykonaj kroki opisane w temacie Tworzenie magazynu zdarzeń, aby utworzyć magazyn zdarzeń analizy w czasie rzeczywistym z podrzędną bazą danych KQL. Musisz ukończyć tylko sekcję zatytułowaną Tworzenie magazynu zdarzeń.
Następnie utwórz tabelę w bazie danych. Wywołaj go OPCUA i użyj następujących kolumn.
Nazwa kolumny Typ danych Identyfikator zasobu string Temperatura decimal Sygnatura czasowa datetime Po utworzeniu tabeli OPCUA wybierz bazę danych i użyj przycisku Zapytanie z kodem , aby otworzyć okno zapytania.
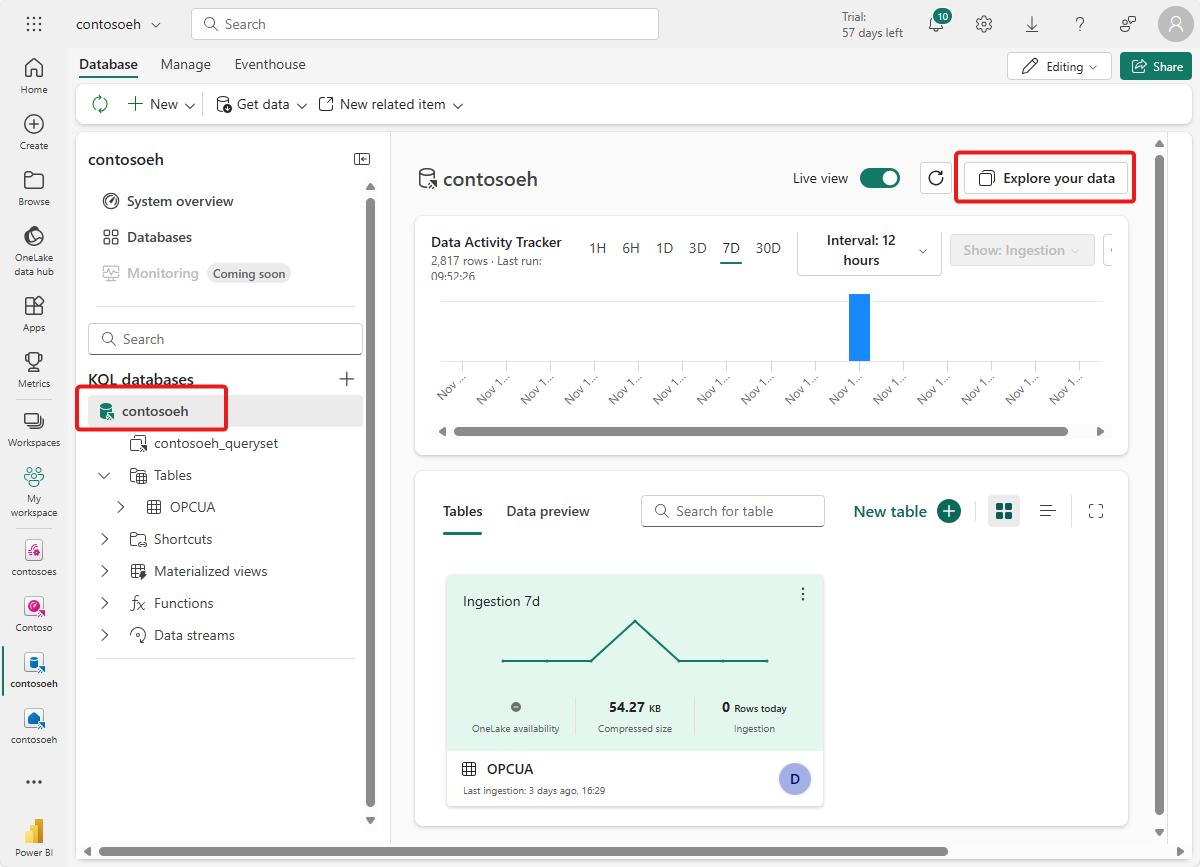
Usuń istniejący kod i uruchom następujące zapytanie KQL, aby utworzyć mapowanie danych dla tabeli. Mapowanie danych będzie nazywane opcua_mapping.
.create table ['OPCUA'] ingestion json mapping 'opcua_mapping' '[{"column":"AssetId", "Properties":{"Path":"$[\'AssetId\']"}},{"column":"Temperature", "Properties":{"Path":"$[\'ThermostatTemperatureF\']"}},{"column":"Timestamp", "Properties":{"Path":"$[\'EventProcessedUtcTime\']"}}]'
Dodawanie tabeli danych jako miejsca docelowego
Następnie wróć do widoku strumienia zdarzeń, w którym możesz dodać nową tabelę KQL jako miejsce docelowe strumienia zdarzeń.
Wykonaj kroki opisane w temacie Dodawanie miejsca docelowego bazy danych KQL do strumienia zdarzeń, aby dodać miejsce docelowe. Pamiętaj o następujących uwagach:
Użyj trybu bezpośredniego pozyskiwania.
W kroku Konfigurowanie wybierz utworzoną wcześniej tabelę OPCUA.
W kroku Inspekcja wybierz pozycję opcua_mapping, wybierz pozycję Istniejące mapowanie i wybierz pozycję opcua_mapping.
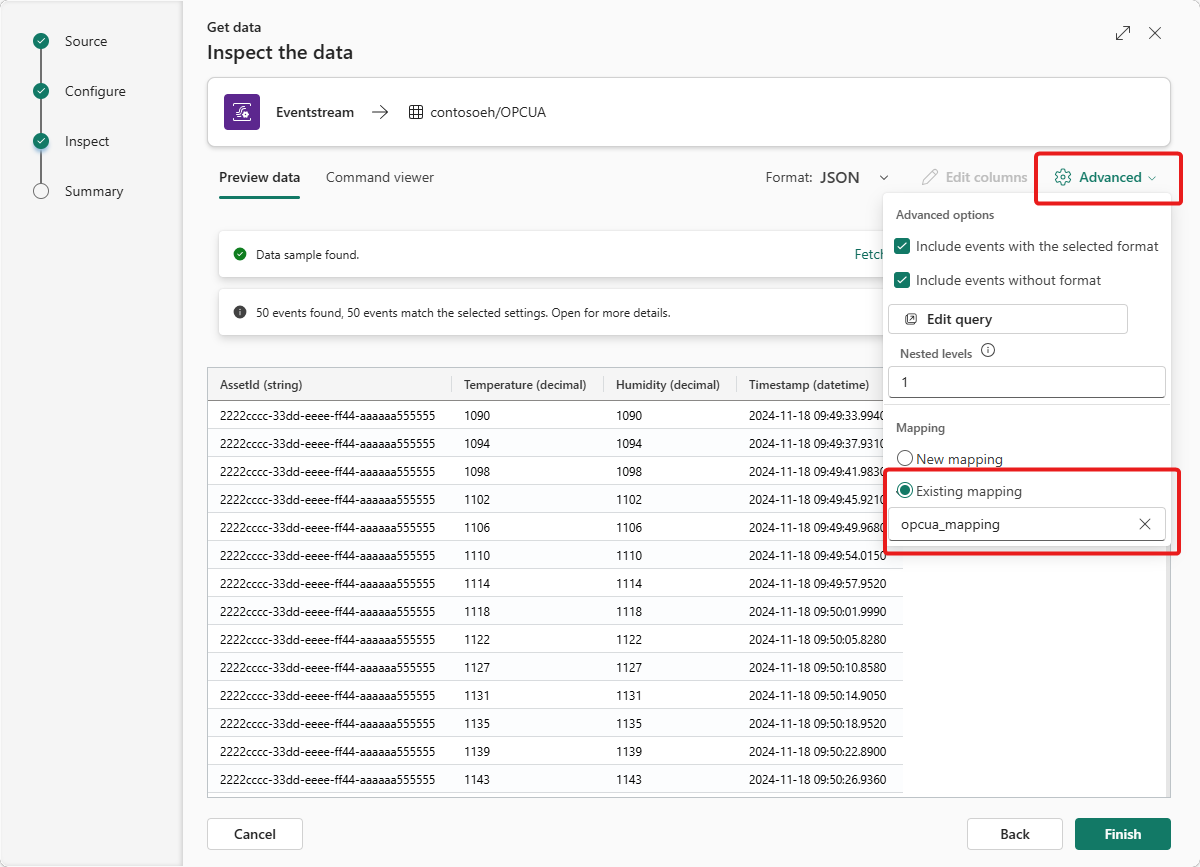
Napiwek
Jeśli nie znaleziono żadnych istniejących mapowań, spróbuj odświeżyć edytor strumienia zdarzeń i ponownie uruchomić kroki, aby dodać miejsce docelowe. Alternatywnie możesz zainicjować ten sam proces konfiguracji z tabeli KQL zamiast z strumienia zdarzeń, zgodnie z opisem w temacie Pobieranie danych z strumienia zdarzeń.
Po ukończeniu tego przepływu tabela KQL jest widoczna w widoku na żywo transmisji zdarzeń jako miejsca docelowego.
Poczekaj kilka minut na propagację danych i stan miejsca docelowego, aby zmienić wartość Na Aktywne
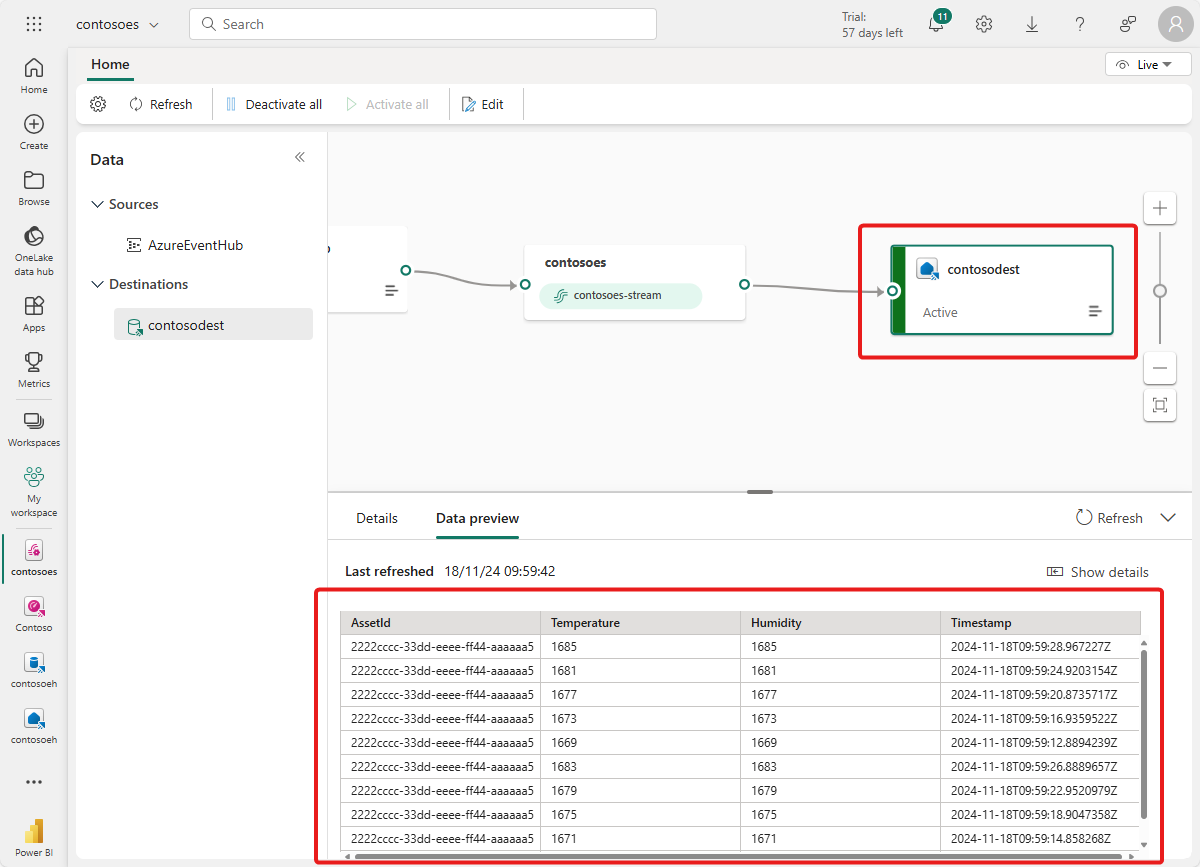
Jeśli chcesz, możesz również wyświetlać i wykonywać zapytania dotyczące tych danych bezpośrednio w bazie danych KQL.
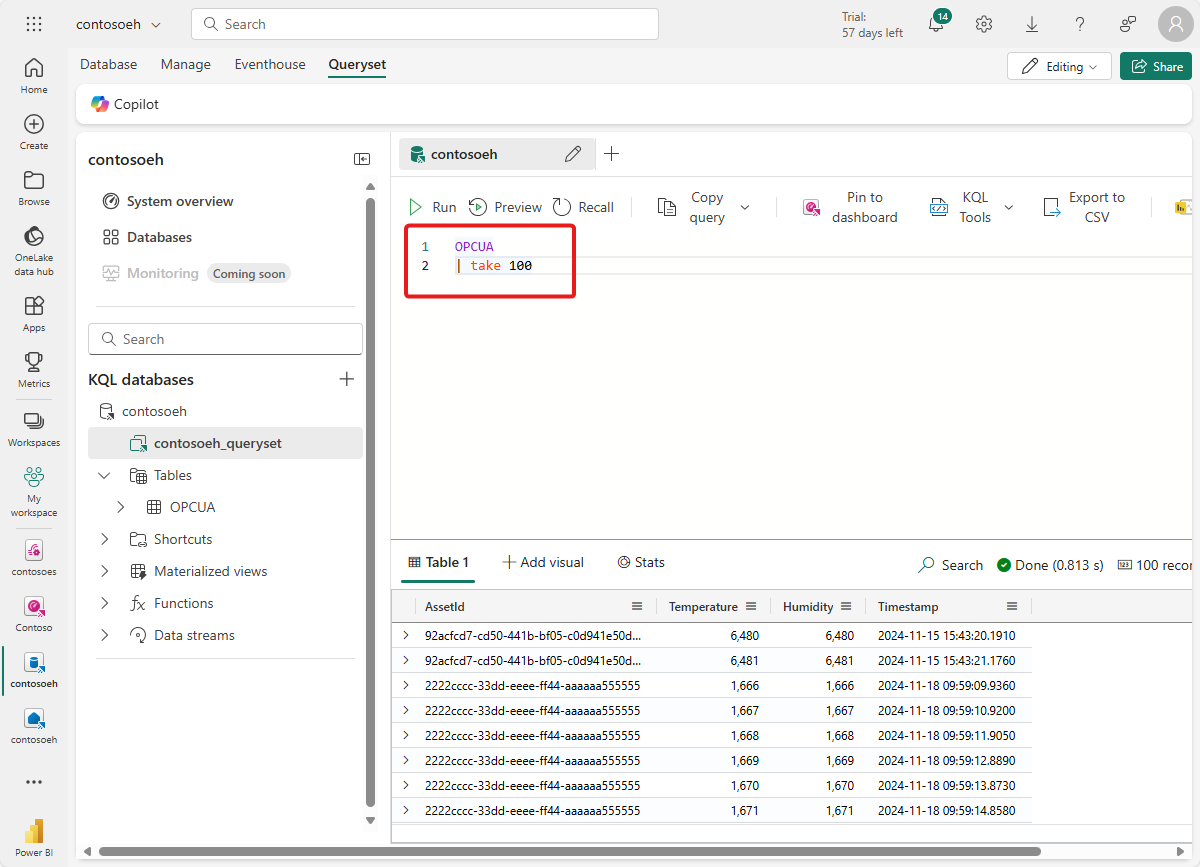
Tworzenie pulpitu nawigacyjnego w czasie rzeczywistym
W tej sekcji utworzysz nowy pulpit nawigacyjny w czasie rzeczywistym, aby wizualizować dane samouczka. Pulpit nawigacyjny umożliwi filtrowanie według identyfikatora zasobu i znacznika czasu oraz wyświetli wizualne podsumowania danych dotyczących temperatury i wilgotności.
Uwaga
Pulpity nawigacyjne w czasie rzeczywistym można tworzyć tylko wtedy, gdy administrator dzierżawy włączył tworzenie pulpitów nawigacyjnych czasu rzeczywistego w dzierżawie sieci szkieletowej. Aby uzyskać więcej informacji, zobacz Włączanie ustawień dzierżawy w portalu administracyjnym.
Tworzenie pulpitu nawigacyjnego i łączenie źródła danych
Wykonaj kroki opisane w sekcji Tworzenie nowego pulpitu nawigacyjnego, aby utworzyć nowy pulpit nawigacyjny w czasie rzeczywistym na podstawie możliwości analizy w czasie rzeczywistym.
Następnie wykonaj kroki opisane w sekcji Dodawanie źródła danych, aby dodać bazę danych jako źródło danych. Pamiętaj o następujących kwestiach:
- W okienku Źródła danych baza danych będzie znajdować się w obszarze Baza danych Eventhouse/KQL.
Konfigurowanie parametrów
Następnie skonfiguruj niektóre parametry pulpitu nawigacyjnego, aby można było filtrować wizualizacje według identyfikatora zasobu i znacznika czasu. Pulpit nawigacyjny zawiera domyślny parametr do filtrowania według zakresu czasu, więc musisz utworzyć tylko taki, który może filtrować według identyfikatora zasobu.
Przejdź do karty Zarządzanie i wybierz pozycję Parametry. Wybierz pozycję + Dodaj , aby dodać nowy parametr.
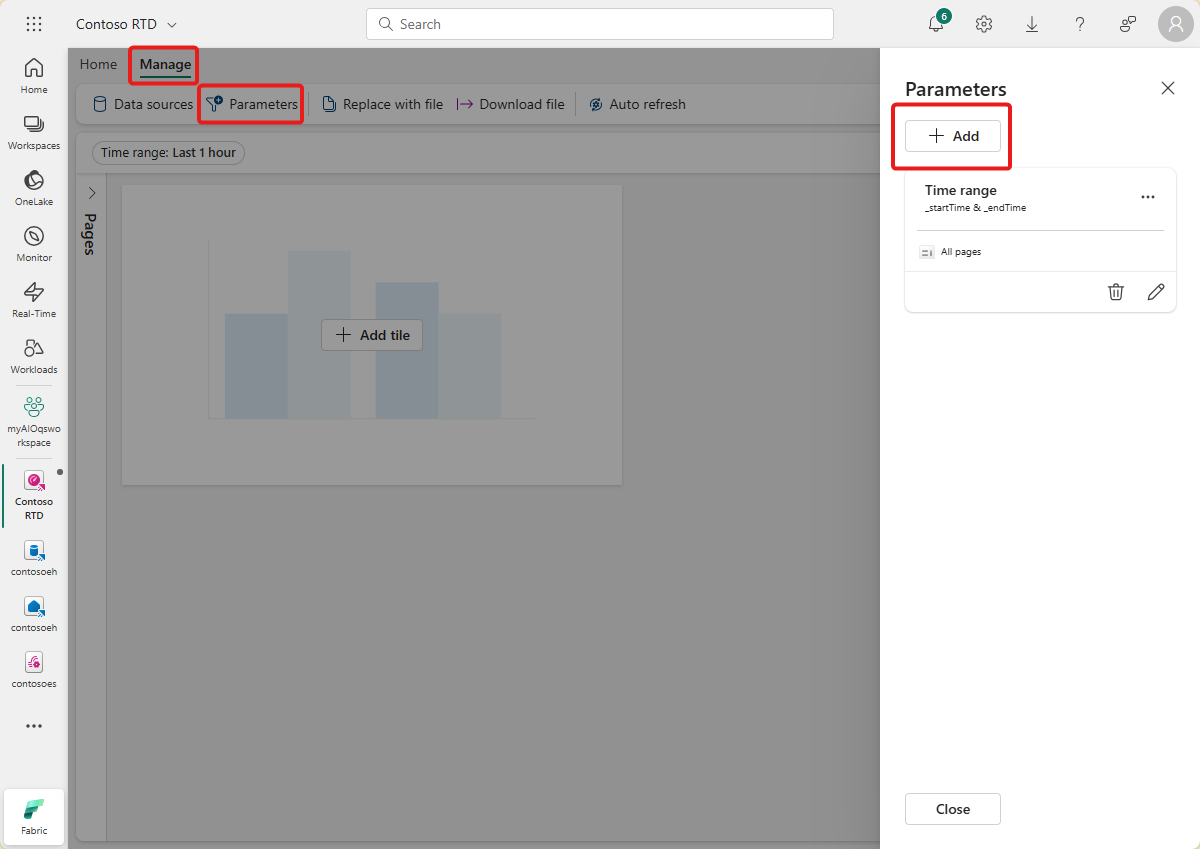
Utwórz nowy parametr z następującymi cechami:
- Etykieta: zasób
- Typ parametru: Wybór pojedynczy (już wybrany domyślnie)
- Nazwa zmiennej: _asset
- Typ danych: ciąg (już wybrany domyślnie)
-
Źródło: Zapytanie
Źródło danych: Baza danych (już wybrana domyślnie)
Wybierz pozycję Edytuj zapytanie i dodaj następujące zapytanie KQL.
OPCUA | summarize by AssetId
- Kolumna wartości: AssetId
- Wartość domyślna: wybierz pierwszą wartość zapytania
Wybierz pozycję Gotowe , aby zapisać parametr.
Kafelek Tworzenie wykresu liniowego
Następnie dodaj kafelek do pulpitu nawigacyjnego, aby wyświetlić wykres liniowy temperatury i wilgotności w czasie dla wybranego zasobu i zakresu czasu.
Wybierz pozycję + Dodaj kafelek lub Nowy kafelek, aby dodać nowy kafelek.
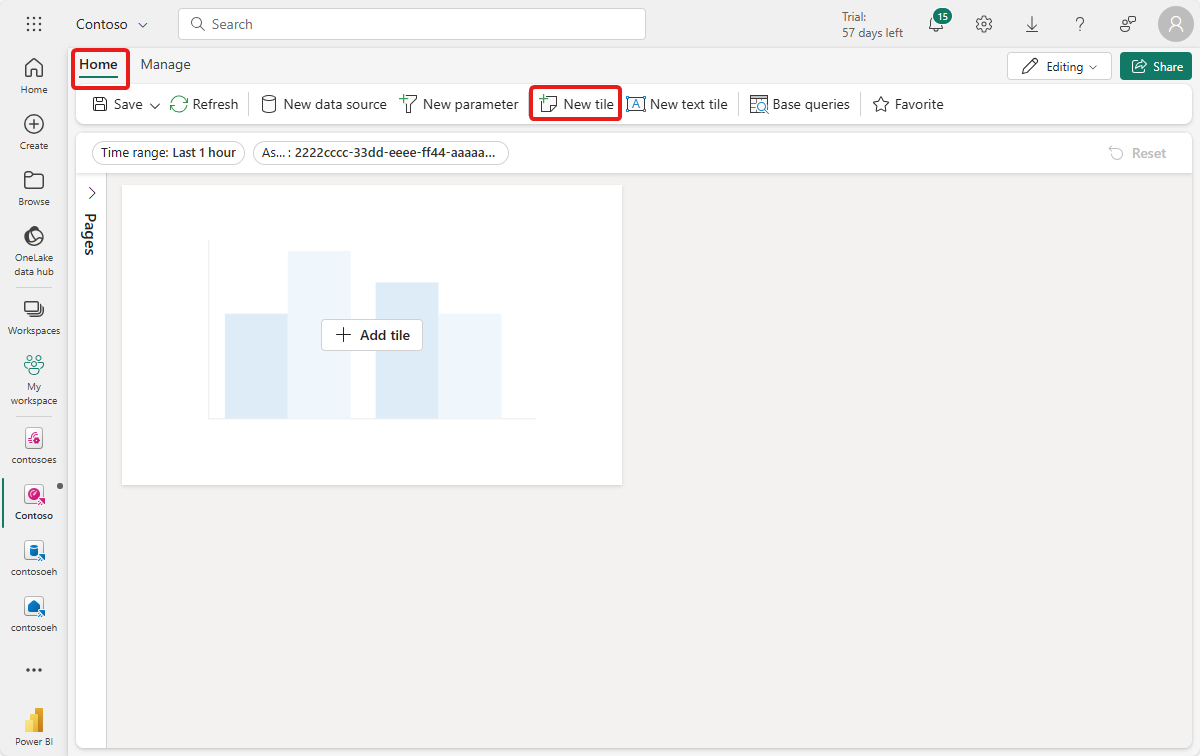
Wprowadź następujące zapytanie KQL dla kafelka. To zapytanie stosuje parametry filtru z selektorów pulpitu nawigacyjnego dla zakresu czasu i elementu zawartości oraz pobiera wynikowe rekordy ze znacznikiem czasu, temperaturą i wilgotnością.
OPCUA | where Timestamp between (_startTime.._endTime) | where AssetId == _asset | project Timestamp, TemperatureUruchom zapytanie, aby sprawdzić, czy dane można znaleźć.
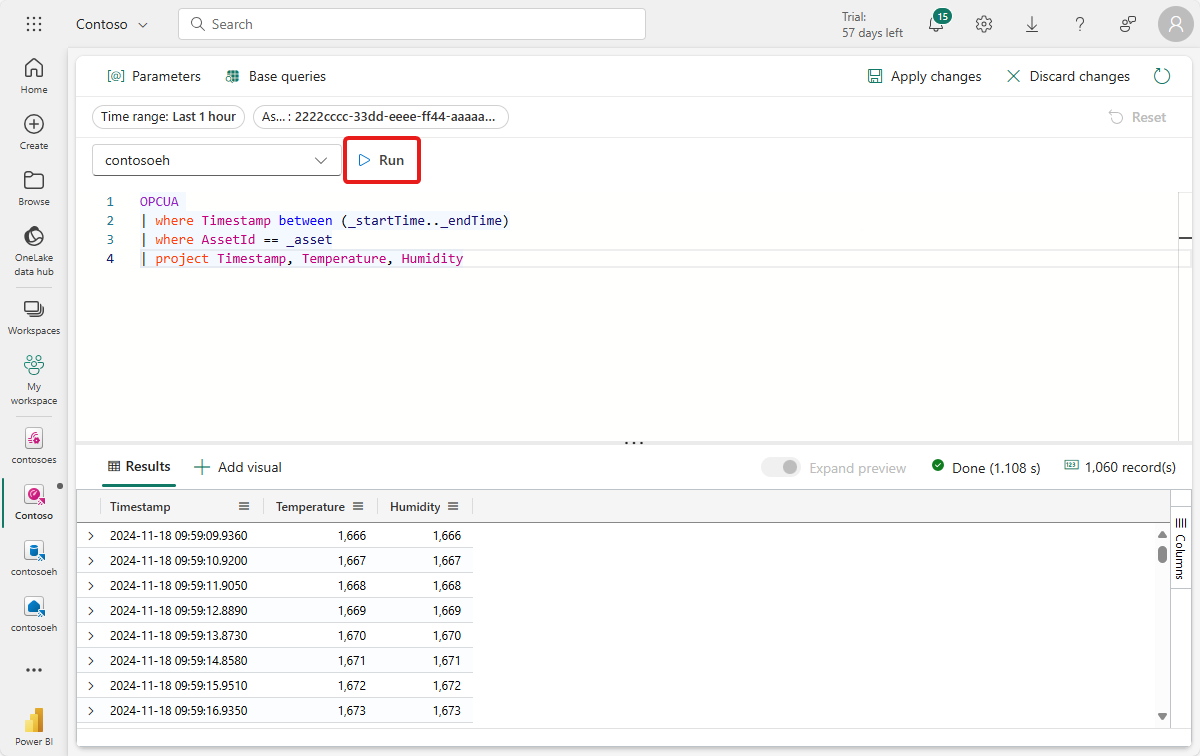
Wybierz pozycję + Dodaj wizualizację obok wyników zapytania, aby dodać wizualizację dla tych danych. Utwórz wizualizację z następującymi cechami:
- Nazwa kafelka: Temperatura w czasie
- Typ wizualizacji: Wykres liniowy
-
Dane:
- Kolumny Y: temperatura (dziesiętna) (już wnioskowana domyślnie)
- Kolumny X: sygnatura czasowa (data/godzina) (już wywnioskowana domyślnie)
-
Oś Y:
- Etykieta: Jednostki
-
Oś X:
- Etykieta: znacznik czasu
Wybierz pozycję Zastosuj zmiany , aby utworzyć kafelek.
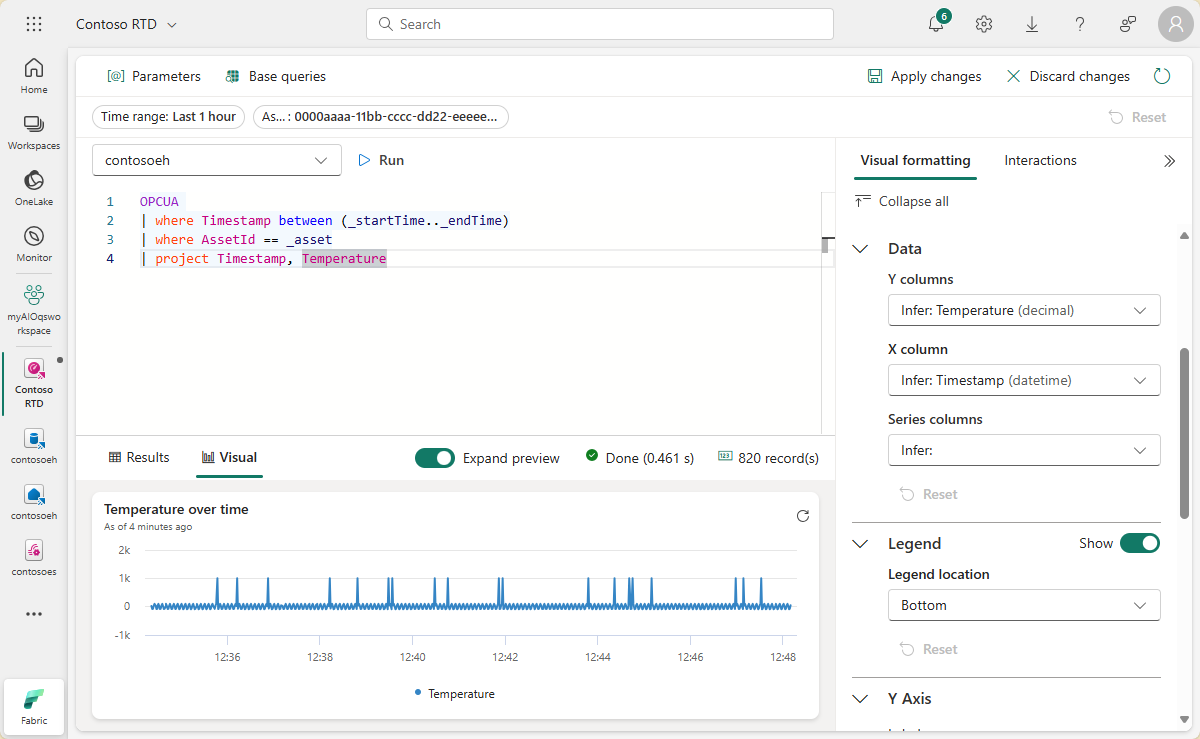
Wyświetl gotowy kafelek na pulpicie nawigacyjnym.
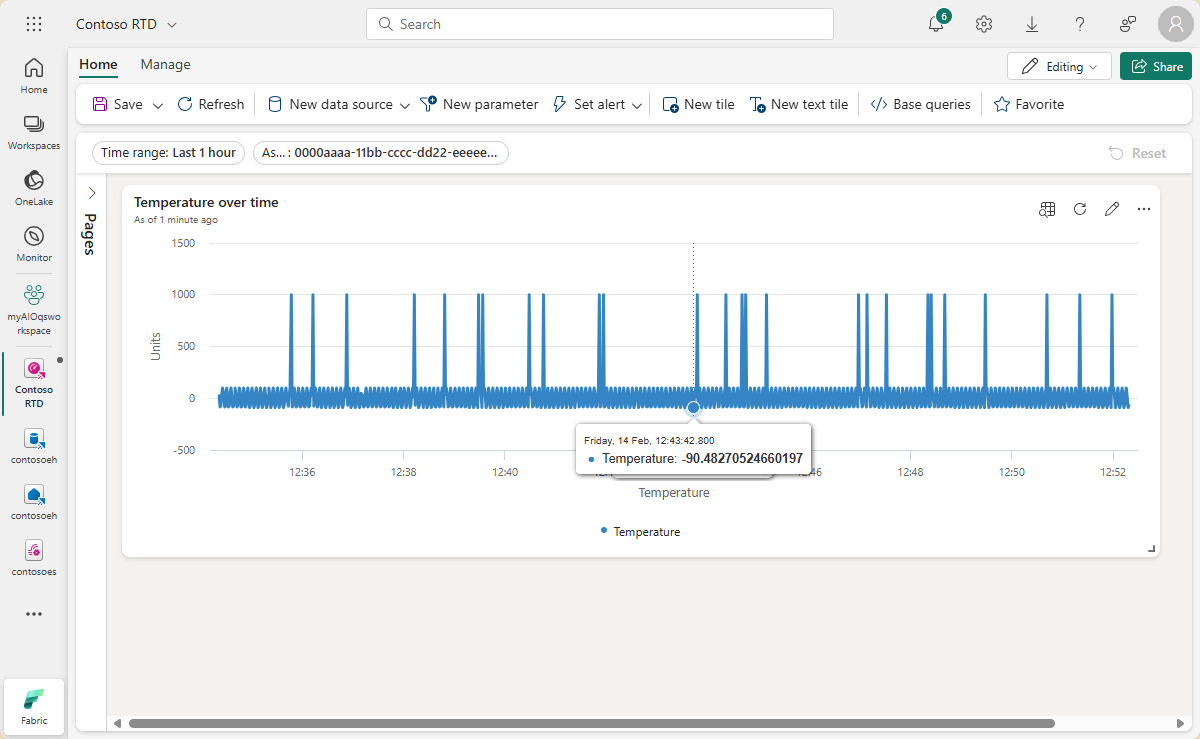
Tworzenie kafelków maksymalnej wartości
Następnie utwórz niektóre kafelki, aby wyświetlić maksymalne wartości temperatury i wilgotności.
Wybierz pozycję Nowy kafelek , aby utworzyć nowy kafelek.
Wprowadź następujące zapytanie KQL dla kafelka. To zapytanie stosuje parametry filtru z selektorów pulpitu nawigacyjnego dla zakresu czasu i zasobu oraz przyjmuje najwyższą wartość temperatury z wynikowych rekordów.
OPCUA | where Timestamp between (_startTime.._endTime) | where AssetId == _asset | top 1 by Temperature desc | summarize by TemperatureUruchom zapytanie, aby sprawdzić, czy można znaleźć maksymalną temperaturę.
Wybierz pozycję + Dodaj wizualizację , aby dodać wizualizację dla tych danych. Utwórz wizualizację z następującymi cechami:
- Nazwa kafelka: Maksymalna temperatura
- Typ wizualizacji: Stat
-
Dane:
- Kolumna wartości: Temperatura (dziesiętna) (już wnioskowana domyślnie)
Wybierz pozycję Zastosuj zmiany , aby utworzyć kafelek.
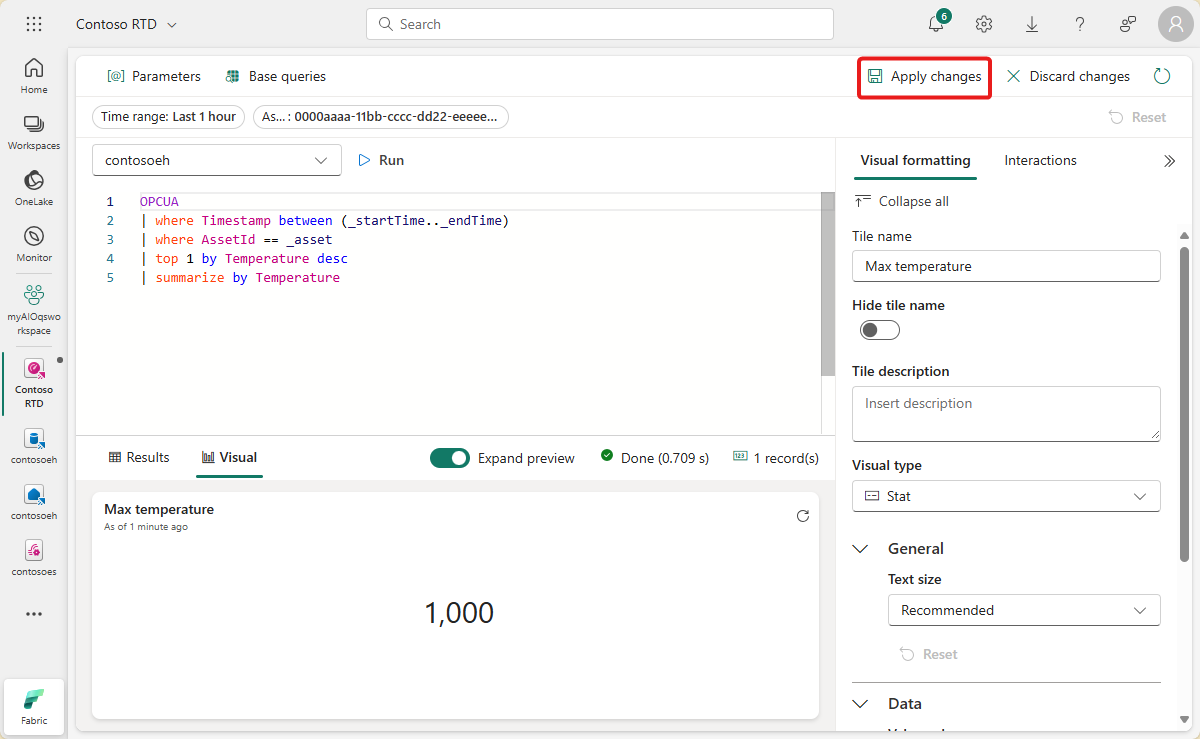
Wyświetl gotowy kafelek na pulpicie nawigacyjnym (możesz zmienić rozmiar kafelka, aby pełny tekst był widoczny).
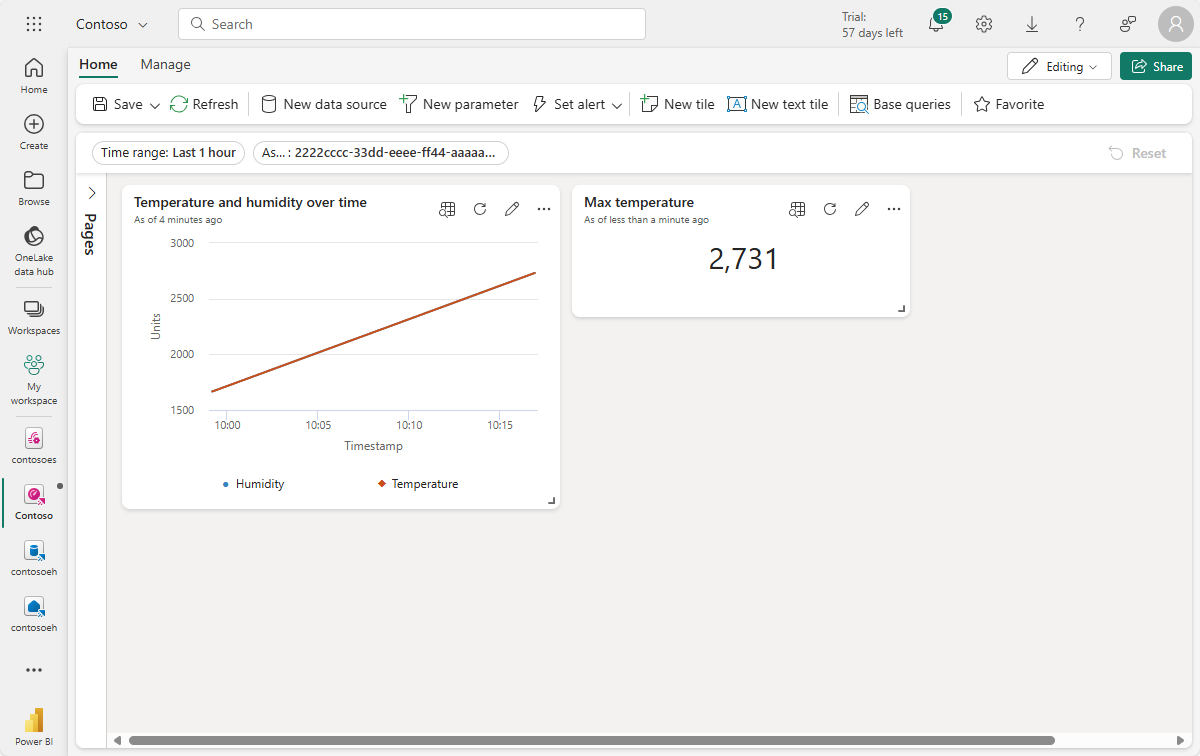
Zapisz ukończony pulpit nawigacyjny.
Teraz masz pulpit nawigacyjny, który wyświetla różne typy wizualizacji dla danych zasobów w tych samouczkach. W tym miejscu możesz poeksperymentować z filtrami i dodawać inne typy kafelków, aby zobaczyć, jak pulpit nawigacyjny może umożliwić wykonywanie większej ilości danych.
Jak rozwiązaliśmy ten problem?
W tym samouczku użyto strumienia zdarzeń do pozyskiwania danych usługi Event Hubs do bazy danych KQL w usłudze Microsoft Fabric Real-Time Intelligence. Następnie utworzono pulpit nawigacyjny w czasie rzeczywistym obsługiwany przez te dane, który wizualnie śledzi zmiany wartości w czasie. Dzięki połączeniu danych brzegowych z różnych źródeł w usłudze Microsoft Fabric można tworzyć raporty z wizualizacjami i interaktywnymi funkcjami, które oferują bardziej szczegółowe informacje na temat kondycji zasobów, wykorzystania i trendów operacyjnych. Dzięki temu można zwiększyć produktywność, poprawić wydajność zasobów i podjąć świadome podejmowanie decyzji w celu uzyskania lepszych wyników biznesowych.
Spowoduje to ukończenie ostatniego kroku przepływu samouczka dotyczącego używania operacji usługi Azure IoT do zarządzania danymi urządzenia z wdrożenia za pośrednictwem analizy w chmurze.
Czyszczenie zasobów
Jeśli przejdziesz do następnego samouczka, zachowaj wszystkie zasoby.
Jeśli chcesz usunąć wdrożenie operacji usługi Azure IoT, ale zachować klaster, użyj polecenia az iot ops delete :
az iot ops delete --cluster $CLUSTER_NAME --resource-group $RESOURCE_GROUP
Jeśli chcesz usunąć wszystkie zasoby utworzone na potrzeby tego przewodnika Szybki start, usuń klaster Kubernetes, w którym wdrożono operacje usługi Azure IoT, a następnie usuń grupę zasobów platformy Azure zawierającą klaster.
Jeśli na potrzeby tych przewodników Szybki start użyto usługi Codespaces, usuń środowisko Codespace z usługi GitHub.
Uwaga
Grupa zasobów zawiera przestrzeń nazw usługi Event Hubs utworzoną w tym samouczku.
Możesz również usunąć obszar roboczy usługi Microsoft Fabric i/lub wszystkie zasoby skojarzone z tym samouczkiem, w tym strumienia zdarzeń, usługi Eventhouse i pulpitu nawigacyjnego czasu rzeczywistego.