Optymalizacja użycia pamięci dla platformy Apache Spark
W tym artykule omówiono sposób optymalizacji zarządzania pamięcią klastra Apache Spark w celu uzyskania najlepszej wydajności w usłudze Azure HDInsight.
Omówienie
Platforma Spark działa przez umieszczenie danych w pamięci. Zarządzanie zasobami pamięci jest kluczowym aspektem optymalizacji wykonywania zadań platformy Spark. Istnieje kilka technik, które można zastosować, aby efektywnie używać pamięci klastra.
- Preferuj mniejsze partycje danych i konto dla rozmiaru, typów i dystrybucji danych w strategii partycjonowania.
- Rozważ nowsze, bardziej wydajne
Kryo data serialization, a nie domyślne serializacji Języka Java. - Preferuj używanie usługi YARN, ponieważ oddziela
spark-submitją partia. - Monitorowanie i dostrajanie ustawień konfiguracji platformy Spark.
W dokumentacji struktura pamięci platformy Spark i niektóre parametry pamięci wykonawczej klucza są wyświetlane na następnej ilustracji.
Zagadnienia dotyczące pamięci platformy Spark
Jeśli używasz usługi Apache Hadoop YARN, usługa YARN kontroluje pamięć używaną przez wszystkie kontenery w każdym węźle spark. Na poniższym diagramie przedstawiono kluczowe obiekty i ich relacje.
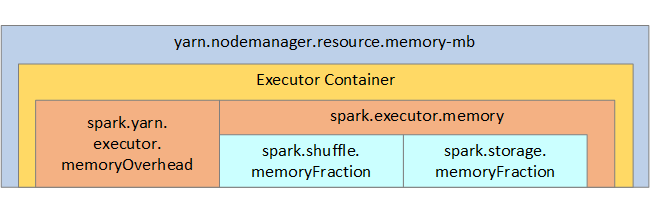
Aby rozwiązać problem z komunikatami braku pamięci, spróbuj:
- Przejrzyj shuffles zarządzania DAG. Zmniejszanie danych źródłowych po stronie mapy, wstępne partycjonowanie (lub zasobniki), maksymalizowanie pojedynczych mieszania i zmniejszanie ilości wysyłanych danych.
- Preferuj
ReduceByKeyze stałym limitem pamięci doGroupByKey, który zapewnia agregacje, okna i inne funkcje, ale ma limit niezwiązanej pamięci. - Preferuj
TreeReduceelement , który wykonuje więcej pracy na funkcjach wykonawczych lub partycjach, doReduce, co wykonuje całą pracę na sterowniku. - Używaj ramek danych, a nie obiektów RDD niższego poziomu.
- Utwórz typy złożone, które hermetyzują akcje, takie jak "Top N", różne agregacje lub operacje okien.
Aby uzyskać dodatkowe kroki rozwiązywania problemów, zobacz Wyjątki OutOfMemoryError dla platformy Apache Spark w usłudze Azure HDInsight.