Wyjątki outOfMemoryError dla platformy Apache Spark w usłudze Azure HDInsight
W tym artykule opisano kroki rozwiązywania problemów i możliwe rozwiązania problemów podczas korzystania ze składników platformy Apache Spark w klastrach usługi Azure HDInsight.
Scenariusz: wyjątek OutOfMemoryError dla platformy Apache Spark
Problem
Aplikacja Platformy Apache Spark nie powiodła się z nieobsługiwanym wyjątkiem OutOfMemoryError. Może zostać wyświetlony komunikat o błędzie podobny do:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Przyczyna
Najbardziej prawdopodobną przyczyną tego wyjątku jest to, że do maszyn wirtualnych Java (JVM) przydzielono za mało pamięci stertowej. Te maszyny JVM są uruchamiane jako funkcje wykonawcze lub sterowniki w ramach aplikacji Platformy Apache Spark.
Rozwiązanie
Określ maksymalny rozmiar danych obsługiwanych przez aplikację Platformy Spark. Oszacuj rozmiar na podstawie maksymalnego rozmiaru danych wejściowych, danych pośrednich utworzonych przez przekształcenie danych wejściowych i danych wyjściowych utworzonych przez dalsze przekształcenie danych pośrednich. Jeśli wstępny szacunek jest niewystarczający, zwiększ nieznacznie rozmiar i powtarzaj ten krok, dopóki błędy pamięci nie ustąpią.
Upewnij się, że klaster usługi HDInsight, który ma być używany, ma wystarczającą ilość zasobów pamięci i rdzeni, aby pomieścić aplikację aparatu Spark. Można to określić, wyświetlając sekcję Metryki klastra interfejsu użytkownika usługi YARN klastra dla wartości używanej pamięci a sumy pamięci i liczby rdzeni wirtualnych używane a łączna liczba rdzeni wirtualnych.

Ustaw następujące konfiguracje platformy Spark na odpowiednie wartości. Zrównoważ wymagania aplikacji z dostępnymi zasobami w klastrze. Te wartości nie powinny przekraczać 90% dostępnej pamięci i rdzeni, które są wyświetlane przez usługę YARN, i powinny również spełniać minimalne wymagania dotyczące pamięci aplikacji Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Łączna ilość pamięci używanej przez wszystkie funkcje wykonawcze =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Całkowita ilość pamięci używanej przez sterownik =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Scenariusz: Błąd obszaru stert java podczas próby otwarcia serwera historii platformy Apache Spark
Problem
Podczas otwierania zdarzeń na serwerze historii platformy Spark występuje następujący błąd:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Przyczyna
Ten problem jest często spowodowany brakiem zasobów podczas otwierania dużych plików zdarzeń platformy Spark. Rozmiar sterty platformy Spark jest domyślnie ustawiony na 1 GB, ale duże pliki zdarzeń platformy Spark mogą wymagać więcej niż to.
Jeśli chcesz sprawdzić rozmiar plików, które próbujesz załadować, możesz wykonać następujące polecenia:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Rozwiązanie
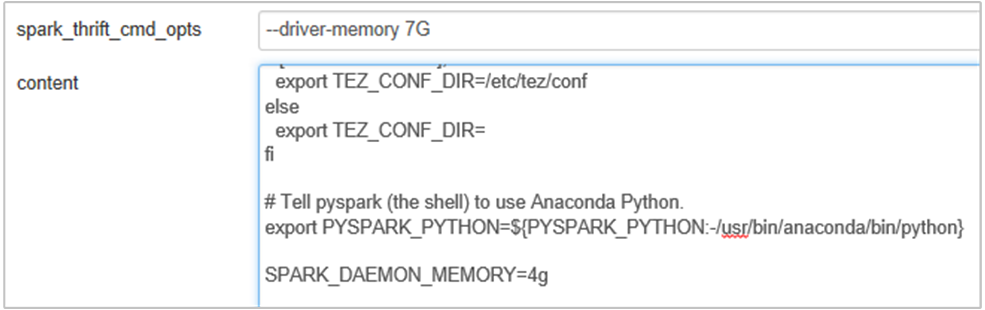
Pamięć serwera historii platformy Spark można zwiększyć, edytując SPARK_DAEMON_MEMORY właściwość w konfiguracji platformy Spark i ponownie uruchamiając wszystkie usługi.
Możesz to zrobić z poziomu interfejsu użytkownika przeglądarki Ambari, wybierając sekcję Spark2/Config/Advanced spark2-env.
Dodaj następującą właściwość, aby zmienić pamięć serwera historii platformy Spark z 1g na 4g: SPARK_DAEMON_MEMORY=4g.
Upewnij się, że wszystkie usługi, których dotyczy problem, zostały uruchomione ponownie z poziomu systemu Ambari.
Scenariusz: Nie można uruchomić serwera Livy w klastrze Apache Spark
Problem
Nie można uruchomić serwera Livy na platformie Apache Spark [(Spark 2.1 w systemie Linux (HDI 3.6)]. Próba ponownego uruchomienia powoduje wyświetlenie następującego stosu błędów z dzienników usługi Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Przyczyna
java.lang.OutOfMemoryError: unable to create new native thread wyróżnia system operacyjny nie może przypisywać większej liczby wątków natywnych do maszyn wirtualnych JVM. Potwierdzono, że ten wyjątek jest spowodowany naruszeniem limitu liczby wątków dla procesu.
Po nieoczekiwanym zakończeniu działania serwera Livy wszystkie połączenia z klastrami Spark również zostaną przerwane, co oznacza, że wszystkie zadania i powiązane dane zostaną utracone. W systemie odzyskiwania sesji HDP 2.6 wprowadzono usługę Livy przechowuje szczegóły sesji w zookeeper, które mają zostać odzyskane po powrocie serwera Livy.
Gdy tak wiele zadań jest przesyłanych za pośrednictwem usługi Livy, w ramach wysokiej dostępności dla usługi Livy Server przechowuje te stany sesji w zestawie ZK (w klastrach usługi HDInsight) i odzyskiwać te sesje po ponownym uruchomieniu usługi Livy. Po nieoczekiwanym zakończeniu ponownego uruchamiania usługa Livy tworzy jeden wątek na sesję i gromadzi niektóre sesje do odzyskania, co powoduje utworzenie zbyt wielu wątków.
Rozwiązanie
Usuń wszystkie wpisy, wykonując następujące kroki.
Uzyskiwanie adresu IP węzłów dozorców przy użyciu polecenia
grep -R zk /etc/hadoop/confPowyższe polecenie wymieniono wszystkie zookeepers dla klastra
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Pobierz cały adres IP węzłów zookeeper przy użyciu polecenia ping Lub możesz również nawiązać połączenie z usługą zookeeper z węzła głównego przy użyciu nazwy zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Po nawiązaniu połączenia z usługą zookeeper wykonaj następujące polecenie, aby wyświetlić listę wszystkich sesji, które próbuje się ponownie uruchomić.
Większość przypadków może to być lista ponad 8000 sesji ####
ls /livy/v1/batchNastępujące polecenie polega na usunięciu wszystkich sesji do odzyskania. #####
rmr /livy/v1/batch
Poczekaj na ukończenie powyższego polecenia i kursor, aby zwrócić wiersz polecenia, a następnie ponownie uruchomić usługę Livy z systemu Ambari, co powinno zakończyć się pomyślnie.
Uwaga
DELETE sesji usługi livy po zakończeniu wykonywania. Sesje wsadowe usługi Livy nie zostaną usunięte automatycznie po zakończeniu działania aplikacji platformy Spark, co jest zgodnie z projektem. Sesja usługi Livy to jednostka utworzona przez żądanie POST względem serwera REST usługi Livy. Do DELETE usunięcia tej jednostki jest wymagane wywołanie. Albo powinniśmy poczekać na kopanie GC.
Następne kroki
Jeśli problem nie został wyświetlony lub nie możesz go rozwiązać, odwiedź jeden z następujących kanałów, aby uzyskać więcej pomocy technicznej:
Omówienie zarządzania pamięcią platformy Spark.
Debugowanie aplikacji Spark w klastrach usługi HDInsight.
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Nawiąż połączenie z @AzureSupport — oficjalnym kontem platformy Microsoft Azure, aby ulepszyć środowisko klienta. Łączenie społeczności platformy Azure z odpowiednimi zasobami: odpowiedziami, pomocą techniczną i ekspertami.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.