Migrowanie klastra usługi HDInsight do nowszej wersji
Aby korzystać z najnowszych funkcji usługi HDInsight, zalecamy regularne migrowanie klastrów usługi HDInsight do najnowszej wersji. Usługa HDInsight nie obsługuje uaktualnień w miejscu, w których istniejący klaster jest uaktualniany do nowszej wersji składnika. Należy utworzyć nowy klaster z odpowiednią wersją składnika i platformy, a następnie zmigrować aplikacje do korzystania z nowego klastra. Postępuj zgodnie z poniższymi wytycznymi, aby przeprowadzić migrację wersji klastra usługi HDInsight.
Uwaga
Jeśli tworzysz klaster Hive z podstawowym kontenerem magazynu, skopiuj go z istniejącego klastra usługi HDInsight. Nie kopiuj pełnej zawartości. Skopiuj tylko skonfigurowane foldery danych.
Zadania migracji
Przepływ pracy uaktualniania klastra usługi HDInsight jest następujący.
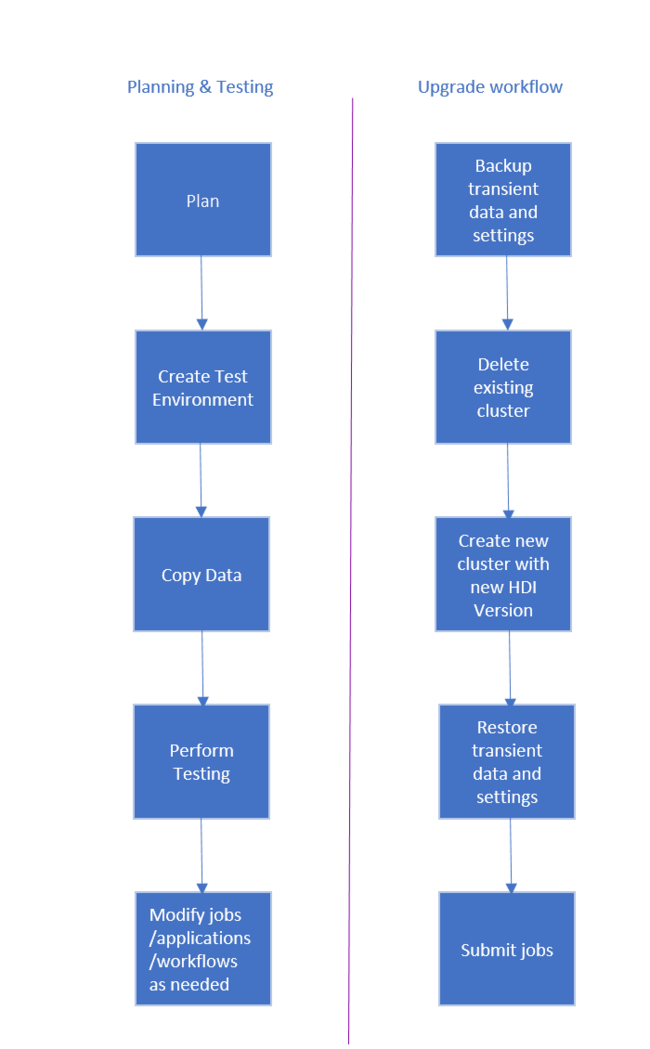
- Przeczytaj każdą sekcję tego dokumentu, aby zrozumieć zmiany, które mogą być wymagane podczas uaktualniania klastra usługi HDInsight.
- Utwórz klaster jako środowisko kontroli jakości/testowania. Aby uzyskać więcej informacji na temat tworzenia klastra, zobacz Dowiedz się, jak tworzyć klastry usługi HDInsight oparte na systemie Linux
- Skopiuj istniejące zadania, źródła danych i ujścia do nowego środowiska.
- Przeprowadź testy poprawności, aby upewnić się, że zadania działają zgodnie z oczekiwaniami w nowym klastrze.
Po sprawdzeniu, czy wszystko działa zgodnie z oczekiwaniami, zaplanuj przestój migracji. Podczas tego przestoju wykonaj następujące czynności:
- Twórz kopie zapasowe wszystkich danych przejściowych przechowywanych lokalnie w węzłach klastra. Jeśli na przykład masz dane przechowywane bezpośrednio w węźle głównym.
- Usuń istniejący klaster.
- Utwórz klaster w tej samej podsieci sieci wirtualnej z najnowszą (lub obsługiwaną) wersją usługi HDI przy użyciu tego samego domyślnego magazynu danych używanego przez poprzedni klaster. Umożliwia to nowemu klastrowi kontynuowanie pracy z istniejącymi danymi produkcyjnymi.
- Zaimportuj wszystkie dane przejściowe, których kopia zapasowa została utworzona.
- Uruchom zadania/kontynuuj przetwarzanie przy użyciu nowego klastra.
Wskazówki dotyczące obciążenia
Poniższe dokumenty zawierają wskazówki dotyczące migrowania określonych obciążeń:
Kopia zapasowa i przywracanie
Aby uzyskać więcej informacji na temat tworzenia kopii zapasowych i przywracania bazy danych, zobacz Odzyskiwanie bazy danych w usłudze Azure SQL Database przy użyciu automatycznych kopii zapasowych bazy danych.
Scenariusze uaktualniania
Jak wspomniano powyżej, firma Microsoft zaleca regularne migrowanie klastrów usługi HDInsight do najnowszej wersji w celu skorzystania z nowych funkcji i poprawek. Zapoznaj się z następującą listą powodów, dla których zażądamy usunięcia klastra i ponownego wdrożenia:
- Wersja klastra jest wycofana lub jeśli masz problem z klastrem, który zostanie rozwiązany przy użyciu nowszej wersji.
- Główną przyczyną problemu z klastrem jest powiązanie niedowymiarowej maszyny wirtualnej. Wyświetl zalecaną konfigurację węzła firmy Microsoft.
- Klient otworzy zgłoszenie do pomocy technicznej, a zespół inżynierów firmy Microsoft ustali, że problem został już rozwiązany w nowszej wersji klastra.
- Domyślna baza danych magazynu metadanych (Ambari, Hive, Oozie, Ranger) osiągnęła limit wykorzystania. Firma Microsoft prosi o ponowne utworzenie klastra przy użyciu niestandardowej bazy danych magazynu metadanych .
- Główną przyczyną problemu z klastrem jest nieobsługiwana operacja. Oto niektóre typowe nieobsługiwane operacje:
- Przenoszenie lub dodawanie usługi w systemie Ambari. Zobacz informacje na temat usług klastra w systemie Ambari. Jedną z akcji dostępnych w menu Akcje usługi jest Przenoszenie [nazwa usługi]. Inną akcją jest Dodawanie [nazwa usługi]. Obie te opcje nie są obsługiwane.
- Uszkodzenie pakietu języka Python. Klastry usługi HDInsight zależą od wbudowanych środowisk języka Python, python 2.7 i Python 3.5. Bezpośrednie instalowanie pakietów niestandardowych w tych domyślnych środowiskach wbudowanych może spowodować nieoczekiwane zmiany wersji biblioteki i przerwać działanie klastra. Dowiedz się, jak bezpiecznie instalować niestandardowe zewnętrzne pakiety języka Python dla aplikacji platformy Spark.
- Oprogramowanie innych firm. Klienci mają możliwość instalowania oprogramowania innych firm w swoich klastrach usługi HDInsight; Zalecamy jednak ponowne utworzenie klastra, jeśli ulegnie awarii istniejącej funkcjonalności.
- Wiele obciążeń w tym samym klastrze. W usłudze HDInsight 4.0 łącznik magazynu Hive potrzebuje oddzielnych klastrów dla obciążeń Spark i Interactive Query. Wykonaj następujące kroki, aby skonfigurować oba klastry w usłudze Azure HDInsight. Podobnie integracja platformy Spark z bazą danych HBASE wymaga dwóch różnych klastrów.
- Niestandardowe hasło bazy danych Ambari uległo zmianie. Hasło bazy danych Ambari jest ustawiane podczas tworzenia klastra i nie ma bieżącego mechanizmu aktualizacji. Jeśli klient wdraża klaster z niestandardową bazą danych Ambari, może zmienić hasło bazy danych w bazie danych SQL DB. Nie ma jednak możliwości zaktualizowania tego hasła dla uruchomionego klastra usługi HDInsight.
- Modyfikowanie modułów równoważenia obciążenia usługi HDInsight. Moduły równoważenia obciążenia usługi HDInsight, które są automatycznie wdrażane dla systemu Ambari i dostępu SSH, nie powinny być modyfikowane ani usuwane. Jeśli zmodyfikujesz moduły równoważenia obciążenia usługi HDInsight i spowoduje to przerwanie działania klastra, zaleca się ponowne wdrożenie klastra.
- Ponowne używanie baz danych Ranger 4.X w wersji 5.X. Usługa HDInsight 5.1 ma platformę Apache Ranger w wersji 2.3.0 , która jest uaktualnieniem wersji głównej z wersji 1.2.0 w klastrach usługi HDInsight 4.X. Ponowne użycie bazy danych hdInsight 4.X Ranger w usłudze HDInsight 5.1 uniemożliwiłoby uruchomienie usługi Ranger z powodu różnic w schemacie bazy danych. Aby pomyślnie wdrożyć klastry ESP usługi HDInsight 5.1 ESP, należy utworzyć pustą bazę danych ranger.