Migrowanie klastra Apache HBase do nowej wersji
W tym artykule omówiono sposób aktualizowania klastra Apache HBase w usłudze Azure HDInsight do nowszej wersji.
Ten artykuł ma zastosowanie tylko wtedy, gdy używasz tego samego konta usługi Azure Storage dla klastrów źródłowych i docelowych. Aby uaktualnić nowe lub inne konto magazynu dla klastra docelowego, zobacz Migrowanie bazy danych Apache HBase do nowej wersji przy użyciu nowego konta magazynu.
Przestój podczas uaktualniania powinien trwać tylko kilka minut. Ten przestój jest spowodowany przez kroki opróżniania wszystkich danych w pamięci oraz czasu konfigurowania i ponownego uruchamiania usług w nowym klastrze. Wyniki będą się różnić w zależności od liczby węzłów, ilości danych i innych zmiennych.
Przegląd zgodności bazy danych Apache HBase
Przed uaktualnieniem bazy danych Apache HBase upewnij się, że wersje bazy danych HBase w klastrach źródłowych i docelowych są zgodne. Zapoznaj się z macierzą zgodności wersji bazy danych HBase i informacjami o wersji w przewodniku referencyjnym bazy danych HBase , aby upewnić się, że aplikacja jest zgodna z nową wersją.
Oto przykładowa macierz zgodności. Y wskazuje zgodność, a N wskazuje potencjalną niezgodność:
| Typ zgodności | Wersja główna | Wersja pomocnicza | Patch |
|---|---|---|---|
| zgodność z przewodami Client-Server | N | Y | Y |
| zgodność Server-Server | N | Y | Y |
| Zgodność formatu pliku | N | Y | Y |
| Zgodność interfejsu API klienta | N | Y | Y |
| Zgodność binarna klienta | N | N | Y |
| Zgodność interfejsu API po stronie serwera | |||
| Stable | N | Y | Y |
| Ewoluuje | N | N | Y |
| Niestabilny | N | N | N |
| Zgodność zależności | N | Y | Y |
| Zgodność operacyjna | N | N | Y |
Aby uzyskać więcej informacji na temat wersji i zgodności usługi HDInsight, zobacz Wersje usługi Azure HDInsight.
Omówienie migracji klastra Apache HBase
Aby uaktualnić klaster Apache HBase w usłudze Azure HDInsight, wykonaj następujące podstawowe kroki. Aby uzyskać szczegółowe instrukcje, zobacz szczegółowe kroki i polecenia lub użyj skryptów w sekcji Migrowanie bazy danych HBase przy użyciu skryptów do migracji automatycznej.
Przygotuj klaster źródłowy:
- Zatrzymaj pozyskiwanie danych.
- Opróżnij dane magazynu memstore.
- Zatrzymaj bazę danych HBase z systemu Ambari.
- W przypadku klastrów z przyspieszonymi zapisami utwórz kopię zapasową katalogu Write Ahead Log (WAL).
Przygotuj klaster docelowy:
- Utwórz klaster docelowy.
- Zatrzymaj bazę danych HBase z systemu Ambari.
- Zaktualizuj
fs.defaultFSkonfiguracje usługi HDFS, aby odwoływać się do oryginalnego kontenera klastra źródłowego. - W przypadku klastrów z przyspieszonymi zapisami zaktualizuj konfiguracje
hbase.rootdirusługi HBase, aby odwołać się do oryginalnego kontenera klastra źródłowego. - Wyczyść dane usługi Zookeeper.
Ukończ migrację:
- Wyczyść i zmigruj plik WAL.
- Skopiuj aplikacje z domyślnego kontenera klastra docelowego do oryginalnego kontenera źródłowego.
- Uruchom wszystkie usługi z klastra docelowego Systemu Ambari.
- Sprawdź bazę danych HBase.
- Usuń klaster źródłowy.
Szczegółowe kroki migracji i polecenia
Aby przeprowadzić migrację klastra Apache HBase, wykonaj te szczegółowe kroki i polecenia.
Przygotowywanie klastra źródłowego
Zatrzymaj pozyskiwanie do źródłowego klastra HBase.
Opróżnij źródłowy klaster HBase, który uaktualniasz.
Baza HBase zapisuje dane przychodzące do magazynu w pamięci o nazwie memstore. Gdy magazyn mem osiągnie określony rozmiar, baza HBase opróżni ją na dysk na potrzeby długoterminowego magazynu na koncie magazynu klastra. Usunięcie klastra źródłowego po uaktualnieniu powoduje również usunięcie wszystkich danych w magazynie memstores. Aby zachować dane, ręcznie opróżnij magazyn memstore każdej tabeli na dysk przed uaktualnieniem.
Dane magazynu memstore można opróżnić, uruchamiając skrypt flush_all_tables.sh z repozytorium GitHub azure hbase-utils.
Możesz również opróżnić dane magazynu memstore, uruchamiając następujące polecenie powłoki HBase z klastra usługi HDInsight:
hbase shell flush "<table-name>"Zaloguj się do serwera Apache Ambari w klastrze źródłowym przy użyciu polecenia
https://<OLDCLUSTERNAME>.azurehdinsight.neti zatrzymaj usługi HBase.W wierszu polecenia potwierdzenia wybierz pole, aby włączyć tryb konserwacji bazy danych HBase.
Aby uzyskać więcej informacji na temat nawiązywania połączenia z systemem Ambari i używania go, zobacz Manage HDInsight clusters by using the Ambari Web UI (Zarządzanie klastrami usługi HDInsight przy użyciu internetowego interfejsu użytkownika systemu Ambari).
Jeśli źródłowy klaster HBase nie ma funkcji Przyspieszone zapisy , pomiń ten krok. W przypadku źródłowych klastrów HBase z przyspieszonymi zapisami wykonaj kopię zapasową katalogu WAL w systemie plików HDFS, uruchamiając następujące polecenia z sesji SSH w dowolnym z węzłów usługi Zookeeper lub węzłów roboczych klastra źródłowego.
hdfs dfs -mkdir /hbase-wal-backup hdfs dfs -cp hdfs://mycluster/hbasewal /hbase-wal-backup
Przygotowywanie klastra docelowego
W Azure Portal skonfiguruj nowy docelowy klaster usługi HDInsight przy użyciu tego samego konta magazynu co klaster źródłowy, ale o innej nazwie kontenera:
Zaloguj się do serwera Apache Ambari w nowym klastrze w lokalizacji
https://<NEWCLUSTERNAME>.azurehdinsight.neti zatrzymaj usługi HBase.W obszarze Usługi> HDFSConfigs>Advanced Advanced>Core-site zmień
fs.defaultFSustawienieHDFS>, aby wskazać oryginalną nazwę kontenera klastra źródłowego. Na przykład ustawienie na poniższym zrzucie ekranu powinno zostać zmienione nawasbs://hbase-upgrade-old-2021-03-22.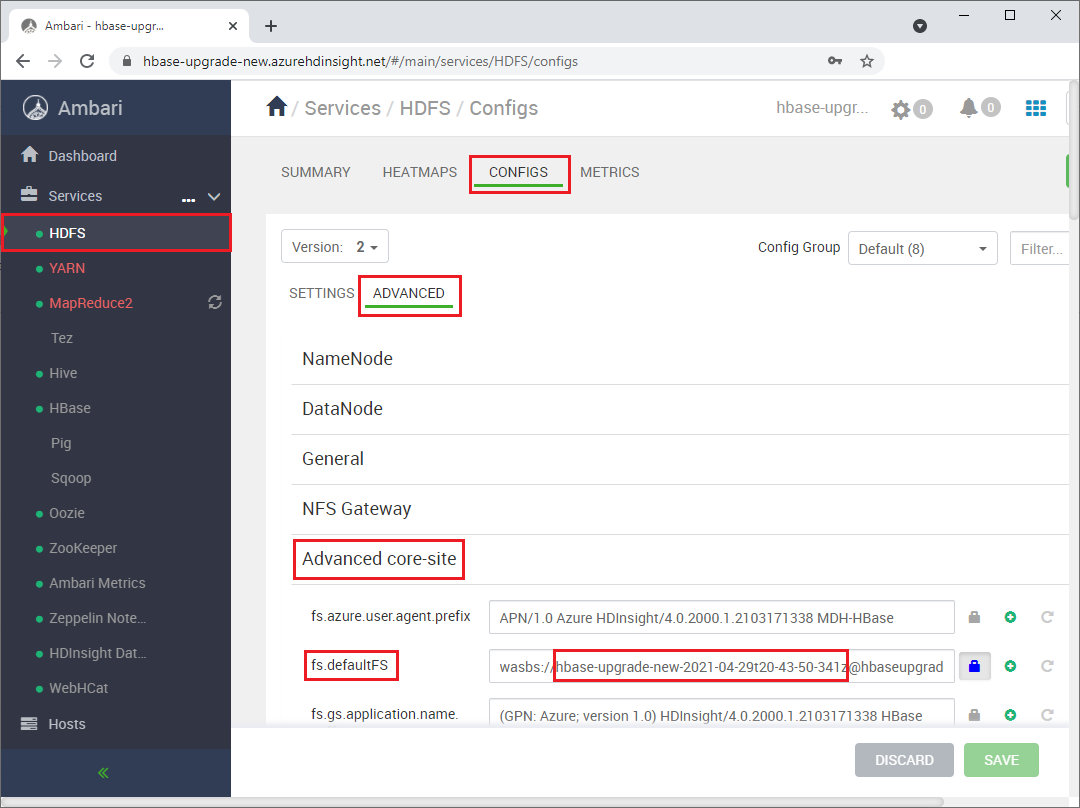
Jeśli klaster docelowy ma funkcję Przyspieszone zapisy, zmień
hbase.rootdirścieżkę, aby wskazać oryginalną nazwę kontenera klastra źródłowego. Na przykład następująca ścieżka powinna zostać zmieniona nahbase-upgrade-old-2021-03-22. Jeśli klaster nie ma przyspieszonych zapisów, pomiń ten krok.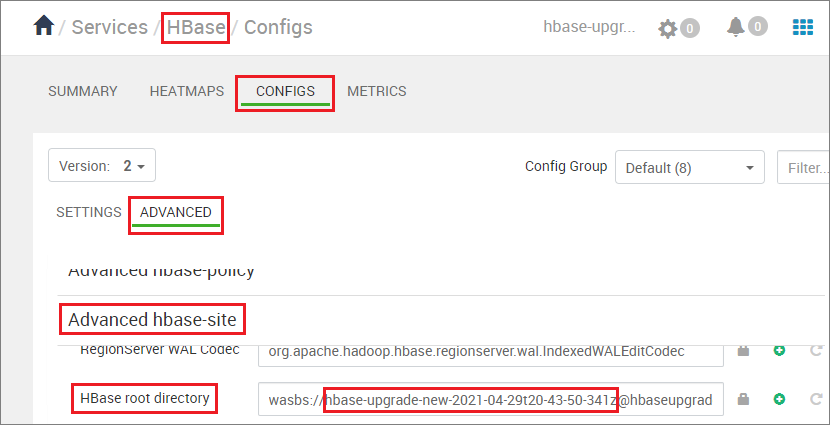
Wyczyść dane usługi Zookeeper w klastrze docelowym, uruchamiając następujące polecenia w dowolnym węźle usługi Zookeeper lub w węźle procesu roboczego:
hbase zkcli rmr /hbase-unsecure quit
Czyszczenie i migrowanie pliku WAL
Uruchom następujące polecenia, w zależności od źródłowej wersji usługi HDI i tego, czy klastry źródłowe i docelowe mają przyspieszone zapisy.
- Klaster docelowy jest zawsze hdI w wersji 4.0, ponieważ usługa HDI 3.6 jest obsługiwana w warstwie Podstawowa i nie jest zalecana w przypadku nowych klastrów.
- Polecenie kopiowania systemu plików HDFS to
hdfs dfs <copy properties starting with -D> -cp <source> <destination> # Serial execution.
Uwaga
- Typ
<source-container-fullpath>magazynu WASB towasbs://<source-container-name>@<storageaccountname>.blob.core.windows.net. - Typ
<source-container-fullpath>magazynu Azure Data Lake Storage Gen2 toabfs://<source-container-name>@<storageaccountname>.dfs.core.windows.net.
- Klaster źródłowy to HDI 3.6 z przyspieszonymi zapisami, a klaster docelowy ma przyspieszone zapisy.
- Klaster źródłowy to HDI 3.6 bez przyspieszonych zapisów, a klaster docelowy ma przyspieszone zapisy.
- Klaster źródłowy to HDI 3.6 bez przyspieszonych zapisów, a klaster docelowy nie ma przyspieszonych zapisów.
- Klaster źródłowy to HDI 4.0 z przyspieszonymi zapisami, a klaster docelowy ma przyspieszone zapisy.
- Klaster źródłowy to HDI 4.0 bez przyspieszonych zapisów, a klaster docelowy ma przyspieszone zapisy.
- Klaster źródłowy to HDI 4.0 bez przyspieszonych zapisów, a klaster docelowy nie ma przyspieszonych zapisów.
Klaster źródłowy to HDI 3.6 lub HDI 4.0 z przyspieszonymi zapisami, a klaster docelowy ma przyspieszone zapisy
Wyczyść dane WAL FS dla klastra docelowego i skopiuj katalog WAL z klastra źródłowego do systemu plików HDFS klastra docelowego. Skopiuj katalog, uruchamiając następujące polecenia w dowolnym węźle zookeeper lub węźle procesu roboczego w klastrze docelowym:
sudo -u hbase hdfs dfs -rm -r hdfs://mycluster/hbasewal
sudo -u hbase hdfs dfs -cp <source-container-fullpath>/hbase-wal-backup/hbasewal hdfs://mycluster/
Klaster źródłowy to HDI 3.6 bez przyspieszonych zapisów, a klaster docelowy ma przyspieszone zapisy
Wyczyść dane WAL FS dla klastra docelowego i skopiuj katalog WAL z klastra źródłowego do systemu plików HDFS klastra docelowego. Skopiuj katalog, uruchamiając następujące polecenia w dowolnym węźle zookeeper lub węźle procesu roboczego w klastrze docelowym:
sudo -u hbase hdfs dfs -rm -r hdfs://mycluster/hbasewal
sudo -u hbase hdfs dfs -Dfs.azure.page.blob.dir="/hbase/WALs,/hbase/MasterProcWALs,/hbase/oldWALs" -cp <source-container>/hbase/*WALs hdfs://mycluster/hbasewal
Klaster źródłowy to HDI 3.6 bez przyspieszonych zapisów, a klaster docelowy nie ma przyspieszonych zapisów
Wyczyść dane wal FS dla klastra docelowego i skopiuj katalog WAL klastra źródłowego do klastra docelowego HDFS. Aby skopiować katalog, uruchom następujące polecenia w dowolnym węźle zookeeper lub węźle procesu roboczego w klastrze docelowym:
sudo -u hbase hdfs dfs -rm -r /hbase-wals/*
sudo -u hbase hdfs dfs -Dfs.azure.page.blob.dir="/hbase/WALs,/hbase/MasterProcWALs,/hbase/oldWALs" -cp <source-container-fullpath>/hbase/*WALs /hbase-wals
Klaster źródłowy to HDI 4.0 bez przyspieszonych zapisów, a klaster docelowy ma przyspieszone zapisy
Wyczyść dane WAL FS dla klastra docelowego i skopiuj katalog WAL z klastra źródłowego do systemu plików HDFS klastra docelowego. Skopiuj katalog, uruchamiając następujące polecenia w dowolnym węźle zookeeper lub węźle procesu roboczego w klastrze docelowym:
sudo -u hbase hdfs dfs -rm -r hdfs://mycluster/hbasewal
sudo -u hbase hdfs dfs -cp <source-container-fullpath>/hbase-wals/* hdfs://mycluster/hbasewal
Klaster źródłowy to HDI 4.0 bez przyspieszonych zapisów, a klaster docelowy nie ma przyspieszonych zapisów
Wyczyść dane wal FS dla klastra docelowego i skopiuj katalog WAL klastra źródłowego do klastra docelowego HDFS. Aby skopiować katalog, uruchom następujące polecenia w dowolnym węźle zookeeper lub węźle procesu roboczego w klastrze docelowym:
sudo -u hbase hdfs dfs -rm -r /hbase-wals/*
sudo -u hbase hdfs dfs -Dfs.azure.page.blob.dir="/hbase-wals" -cp <source-container-fullpath>/hbase-wals /
Kończenie migracji
sudo -u hdfsZa pomocą kontekstu użytkownika skopiuj folder/hdp/apps/<new-version-name>i jego zawartość z<destination-container-fullpath>folderu do folderu w/hdp/appsobszarze<source-container-fullpath>. Folder można skopiować, uruchamiając następujące polecenia w klastrze docelowym:sudo -u hdfs hdfs dfs -cp /hdp/apps/<hdi-version> <source-container-fullpath>/hdp/appsPrzykład:
sudo -u hdfs hdfs dfs -cp /hdp/apps/4.1.3.6 wasbs://hbase-upgrade-old-2021-03-22@hbaseupgrade.blob.core.windows.net/hdp/appsW klastrze docelowym zapisz zmiany i uruchom ponownie wszystkie wymagane usługi, jak wskazuje ambari.
Wskaż aplikację do klastra docelowego.
Uwaga
Statyczna nazwa DNS aplikacji zmienia się podczas uaktualniania. Zamiast kodować tę nazwę DNS na stałe, można skonfigurować nazwę CNAME w ustawieniach DNS nazwy domeny, które wskazuje nazwę klastra. Inną opcją jest użycie pliku konfiguracji dla aplikacji, który można zaktualizować bez ponownego wdrażania.
Rozpocznij pozyskiwanie.
Sprawdź spójność bazy danych HBase i proste operacje języka DDL (Data Definition Language) i języka manipulowania danymi (DML).
Jeśli klaster docelowy jest zadowalający, usuń klaster źródłowy.
Migrowanie bazy danych HBase przy użyciu skryptów
Wykonaj skrypt migrate-hbase-source.sh w klastrze źródłowym i migrate-hbase-dest.sh w klastrze docelowym. Użyj poniższych instrukcji, aby wykonać te skrypty.
Uwaga
Te skrypty nie kopiują starych list WALs bazy danych HBase w ramach migracji; dlatego skrypty nie mają być używane w klastrach z włączoną funkcją kopia zapasowa bazy danych HBase lub replikacja.
W klastrze źródłowym
sudo bash migrate-hbase-source.shW klastrze docelowym
sudo bash migrate-hbase-dest.sh -f <src_default_Fs>
Obowiązkowy argument dla powyższego polecenia:
-f, --src-fs
The fs.defaultFS of the source cluster
For example:
-f wasb://anynamehbase0316encoder-2021-03-17t01-07-55-935z@anynamehbase0hdistorage.blob.core.windows.net
Następne kroki
Aby dowiedzieć się więcej na temat bazy danych Apache HBase i uaktualniania klastrów usługi HDInsight, zobacz następujące artykuły: