Przesyłanie i zarządzanie zadaniami w klastrze Apache Spark™ w HDInsight na AKS
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej dzięki temu ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania platformy Microsoft Azure zawierają więcej warunków prawnych, które dotyczą funkcji platformy Azure będących w wersji beta, w wersji zapoznawczej lub w inny sposób jeszcze nieudostępnione ogólnie. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji prosimy o przesłanie zapytania na AskHDInsight ze szczegółami oraz obserwowanie nas dla uzyskania więcej informacji na temat społeczności Azure HDInsight.
Po utworzeniu klastra użytkownik może przesyłać zadania i zarządzać nimi za pomocą różnych interfejsów
- korzystanie z programu Jupyter
- korzystanie z Zeppelina
- korzystanie z protokołu ssh (spark-submit)
Korzystanie z programu Jupyter
Warunki wstępne
Klaster Apache Spark™ w usłudze HDInsight na AKS. Aby uzyskać więcej informacji, zobacz Tworzenie klastra Apache Spark.
Jupyter Notebook to interaktywne środowisko notesu, które obsługuje różne języki programowania.
Tworzenie notesu Jupyter
Przejdź do strony klastra Apache Spark™ i otwórz kartę Przegląd. Kliknij aplikację Jupyter. Zostanie wyświetlona prośba o uwierzytelnienie i otwarcie strony internetowej Jupyter.

Na stronie Jupyter wybierz Nowy > PySpark, aby utworzyć notatnik.
Utworzono i otwarto nowy notes z nazwą
Untitled(Untitled.ipynb).Notatka
Korzystając z jądra PySpark lub Python 3 do utworzenia notesu, sesja Spark jest tworzona automatycznie podczas uruchamiania pierwszej komórki kodu. Nie trzeba jawnie tworzyć sesji.
Wklej następujący kod w pustej komórce notesu Jupyter Notebook, a następnie naciśnij SHIFT + ENTER, aby uruchomić kod. Aby uzyskać więcej kontrolek w programie Jupyter, zobacz tutaj.

%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Wykreśl wykres z wynagrodzeniem na osi X i wiekiem na osi Y.
W tym samym notesie wklej następujący kod w pustej komórce notesu Jupyter Notebook, a następnie naciśnij shift + ENTER, aby uruchomić kod.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()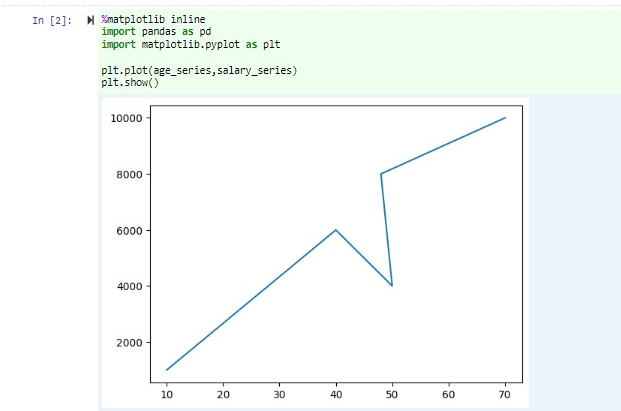




Zapisywanie notesu
Na pasku menu notesu przejdź do pozycji Plik > Zapisz i Punkt kontrolny.
Zamknij notes, aby zwolnić zasoby klastra: na pasku menu notesu przejdź do pozycji Plik > Zamknij i zatrzymaj. Możesz również uruchomić dowolny notebook w folderze przykłady.


Korzystanie z notesów Apache Zeppelin
Klastry Apache Spark w HDInsight na AKS obejmują notatniki Apache Zeppelin. Użyj notesów do uruchamiania zadań platformy Apache Spark. W tym artykule dowiesz się, jak używać notesu Zeppelin na klastrze HDInsight na AKS.
Warunki wstępne
Klaster Apache Spark na HDInsight w AKS. Aby uzyskać instrukcje, zobacz Tworzenie klastra Apache Spark.
Uruchamianie notesu Apache Zeppelin
Przejdź do strony przeglądu klastra Apache Spark i wybierz notebook Zeppelin z pulpitów klastra. Wymaga uwierzytelnienia i otwarcia strony Zeppelin.
Utwórz nowy notatnik. W okienku nagłówka przejdź do Notes >, aby utworzyć nową notatkę. Upewnij się, że nagłówek notesu pokazuje status połączenia. Oznacza zieloną kropkę w prawym górnym rogu.
Uruchom następujący kod w notesie Zeppelin:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Aby uruchomić fragment kodu, wybierz przycisk Odtwórz dla akapitu. Stan w prawym rogu akapitu powinien przechodzić od POZYCJI GOTOWE, OCZEKUJĄCE, URUCHOMIONE na ZAKOŃCZONO. Dane wyjściowe są wyświetlane w dolnej części tego samego akapitu. Zrzut ekranu wygląda jak na poniższej ilustracji:
Wyjście:





Korzystanie z uruchamiania zadań w Spark
Utwórz plik przy użyciu następującego polecenia "#vim samplefile.py"
To polecenie otwiera plik vim
Wklej następujący kod do pliku vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Zapisz plik przy użyciu następującej metody.
- Naciśnij przycisk Ucieczka
- Wprowadź polecenie
:wq
Uruchom następujące polecenie, aby uruchomić zadanie.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Monitorowanie zapytań w klastrze Apache Spark w HDInsight na AKS
Interfejs historii Spark
Kliknij zakładkę Przeglądowy i wybierz Spark History Server UI.

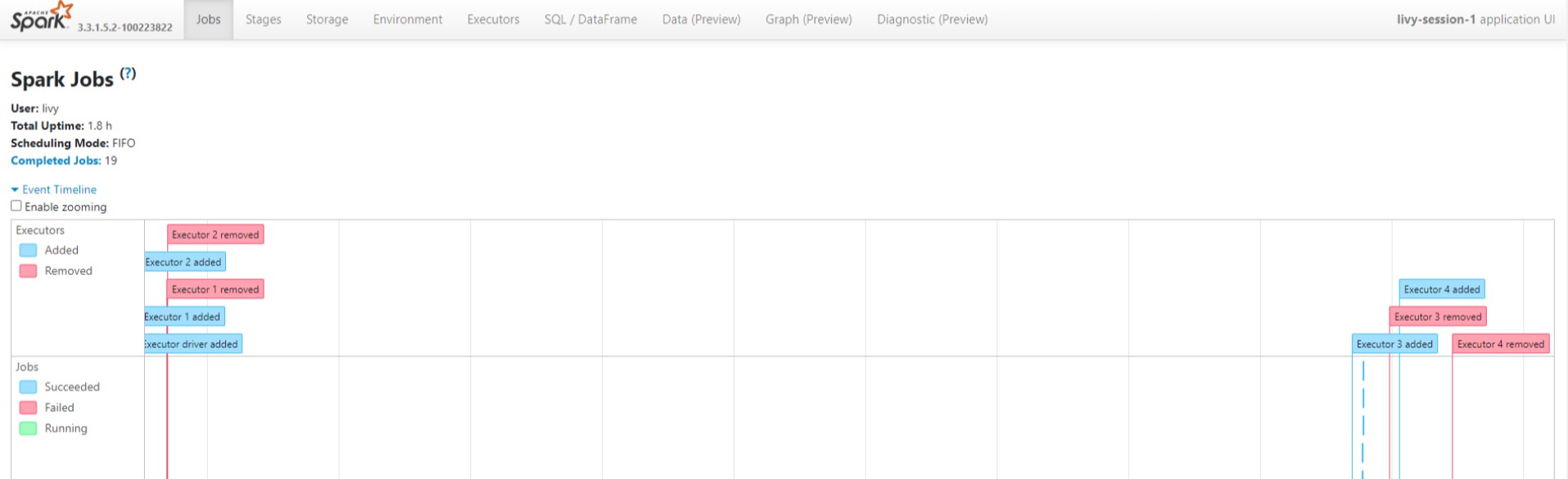
Wybierz ostatnie uruchomienie z interfejsu użytkownika przy użyciu tego samego identyfikatora aplikacji.

Wyświetl cykle skierowanego grafu Acyklicznego i etapy zadania w interfejsie użytkownika serwera historii platformy Spark.



interfejsu użytkownika sesji usługi Livy
Aby otworzyć interfejs użytkownika sesji usługi Livy, wpisz następujące polecenie w przeglądarce
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui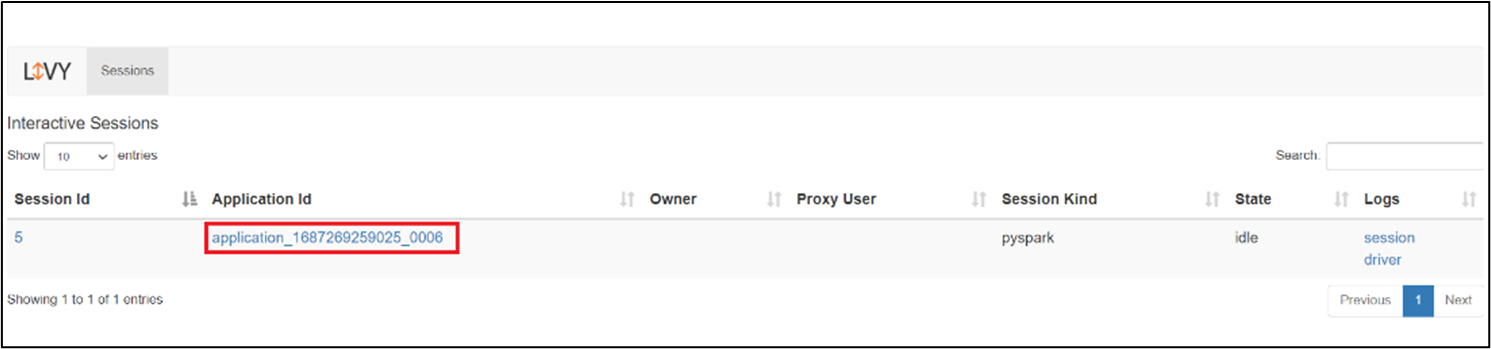
Wyświetl dzienniki sterowników, klikając opcję sterownika w obszarze dzienników.

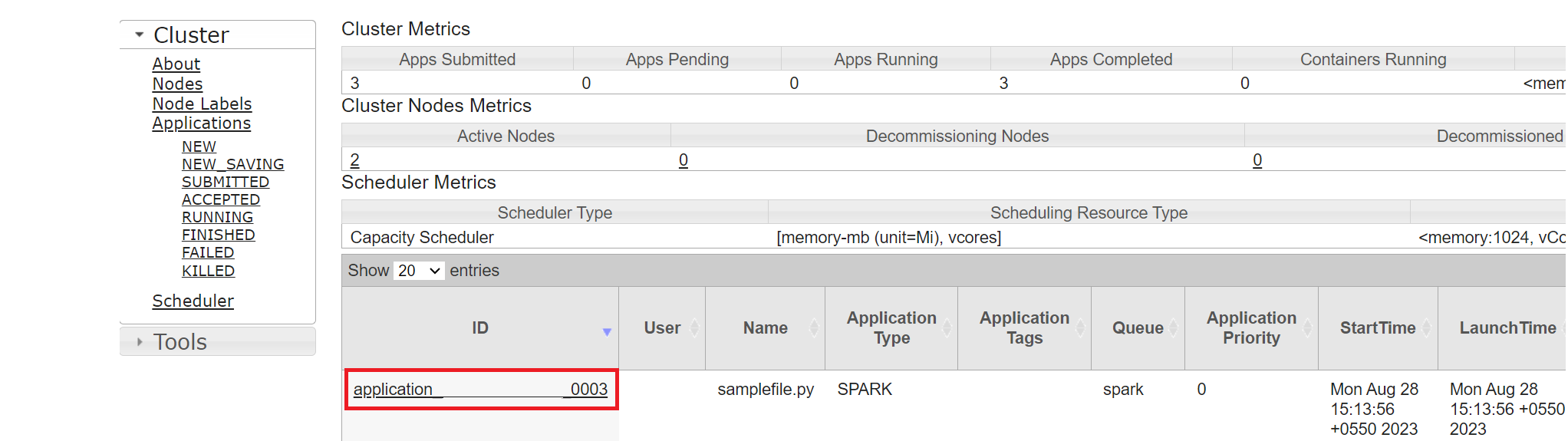
interfejsu użytkownika usługi Yarn
Na karcie Przegląd kliknij pozycję Yarn i otwórz interfejs użytkownika usługi Yarn.
Zadanie, które zostało ostatnio uruchomione, można śledzić według tego samego identyfikatora aplikacji.
Kliknij identyfikator aplikacji w usłudze Yarn, aby wyświetlić szczegółowe dzienniki zadania.


Odniesienie
- Nazwy projektów open source Apache, Apache Spark oraz związane z nimi są znakami towarowymiApache Software Foundation (ASF).