Utwórz klaster Spark w usłudze HDInsight na platformie AKS (wersja zapoznawcza)
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej z tym ogłoszeniem.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania platformy Microsoft Azure zawierają więcej warunków prawnych, które dotyczą funkcji platformy Azure w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze udostępnione w wersji ogólnodostępnej. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie na AskHDInsight z podaniem szczegółów. Śledź nas na Azure HDInsight Community, aby otrzymywać więcej aktualizacji.
Po zakończeniu wymagań wstępnych subskrypcji i wymagań wstępnych dotyczących zasobów oraz wdrożeniu puli klastrów, kontynuuj tworzenie klastra Spark przy użyciu portalu Azure. Za pomocą witryny Azure Portal można utworzyć klaster Apache Spark w puli klastrów. Następnie możesz utworzyć notatnik Jupyter i użyć go do uruchamiania zapytań Spark SQL na tabelach Apache Hive.
W portalu Azure wpisz "pule klastrów", a następnie wybierz pule klastrów, aby przejść do strony pul klastrów. Na stronie Pule klastrów wybierz pulę klastrów, w której można dodać nowy klaster Spark.
Na określonej stronie puli klastrów kliknij opcję + Utwórz nowy klaster.
Ten krok powoduje otwarcie strony tworzenia klastra.
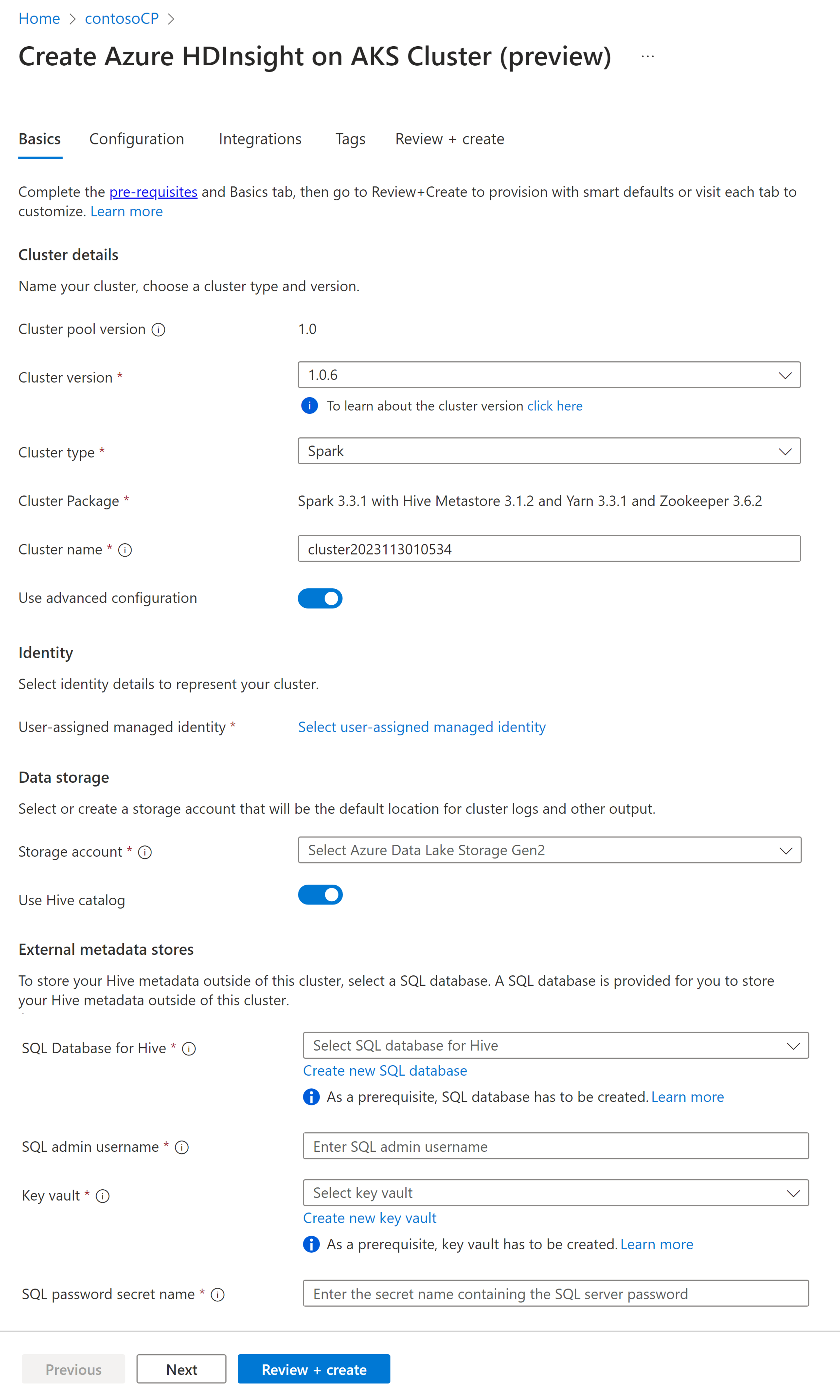
Własność Opis Subskrypcja Subskrypcja platformy Azure, która została zarejestrowana do użycia z usługą HDInsight w usłudze AKS w sekcji Wymagania wstępne, zostanie wstępnie wypełniona Grupa zasobów Ta sama grupa zasobów co pula klastrów będzie wcześniej wypełniona Region Ten sam region, co pula klastrów i usługi wirtualne, zostanie wstępnie wypełniony. Pula klastrów Nazwa puli klastrów zostanie automatycznie uzupełniona Wersja puli usługi HDInsight Wersja puli klastrów zostanie wstępnie wypełniona z wyboru tworzenia puli Usługa HDInsight w wersji usługi AKS Określanie HDI w wersji AKS Typ klastra Z listy rozwijanej wybierz pozycję Spark Wersja klastra Wybierz wersję obrazu, która ma być używana Nazwa klastra Wprowadź nazwę nowego klastra Zarządzana tożsamość przydzielona przez użytkownika Wybierz tożsamość zarządzaną przypisaną przez użytkownika, która będzie pełnić funkcję parametru połączenia z magazynem danych. Konto magazynu Wybierz wstępnie utworzone konto magazynu, które ma być używane jako magazyn podstawowy dla klastra Nazwa kontenera Wybierz nazwę kontenera (unikatową) w przypadku wstępnie utworzonego lub utworzenia nowego kontenera Katalog hive (opcjonalnie) Wybierz wstępnie utworzony magazyn metadanych Hive (Azure SQL DB) Baza danych SQL dla Hive Z listy rozwijanej wybierz bazę danych SQL Database, w której chcesz dodać tabele hive-metastore. Nazwa użytkownika administratora SQL Wprowadź nazwę użytkownika administratora SQL Skarbiec kluczy Z listy rozwijanej wybierz usługę Key Vault zawierającą tajemnicę z hasłem dla konta administratora SQL. Nazwa sekretu hasła SQL Wprowadź nazwę tajną z usługi Key Vault, w której jest przechowywane hasło bazy danych SQL Notatka
- Obecnie usługa HDInsight obsługuje tylko bazy danych programu MS SQL Server.
- Ze względu na ograniczenia systemu Hive znak "-" (łącznik) w nazwie bazy danych magazynu metadanych nie jest obsługiwany.
Wybierz pozycję Dalej: Konfiguracja i cennik, aby kontynuować.
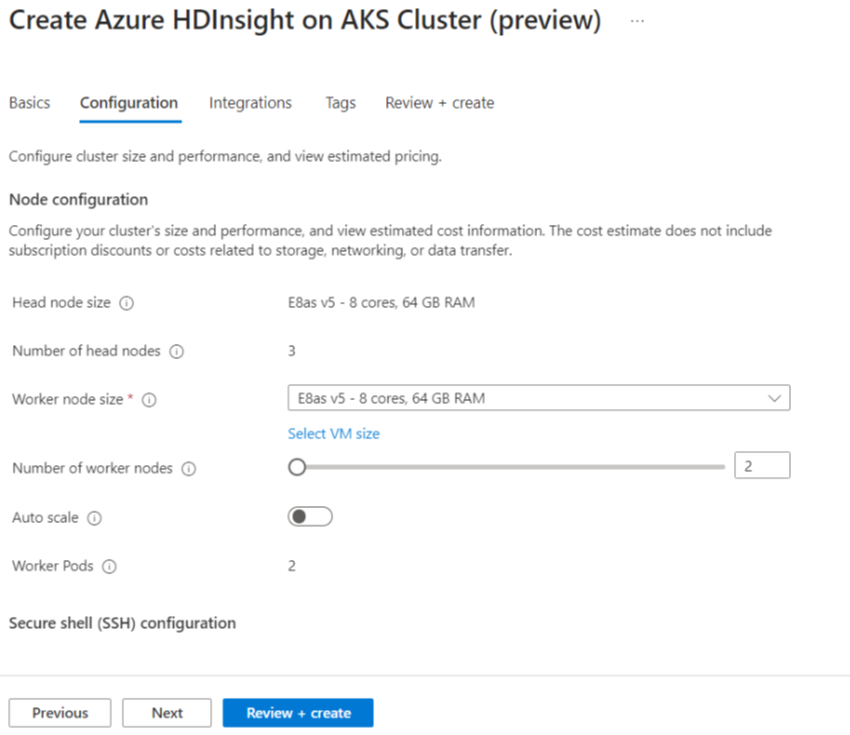
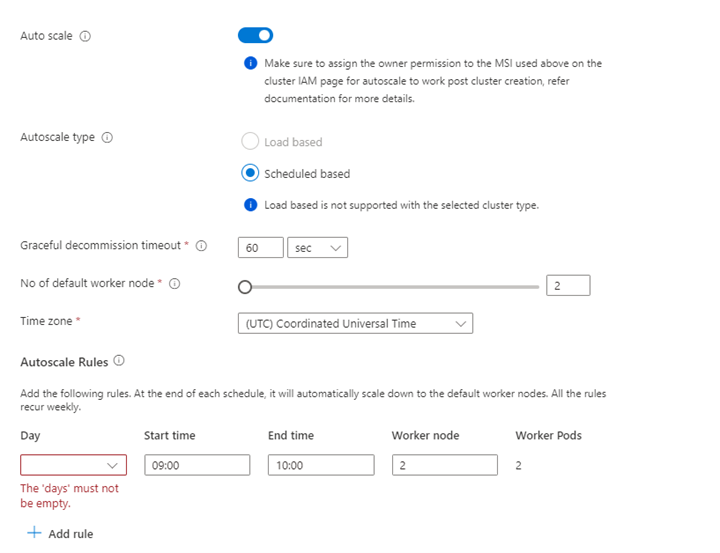
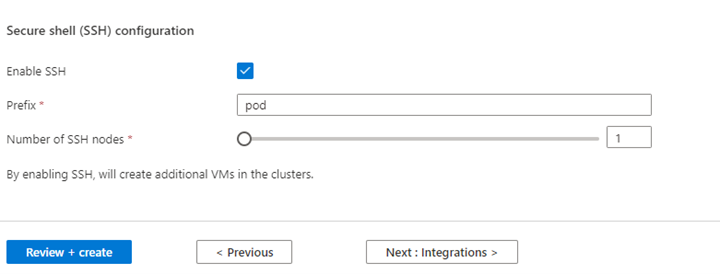
Własność Opis Rozmiar węzła Wybierz rozmiar węzła do użycia dla węzłów platformy Spark Liczba węzłów procesu roboczego Wybierz liczbę węzłów dla klastra Spark. Spośród nich trzy węzły są zarezerwowane dla usług koordynatora i usługi systemowe, pozostałe węzły są przeznaczone dla pracowników Spark, z jednym pracownikiem na węzeł. Na przykład w klastrze z pięcioma węzłami istnieją dwa procesy robocze Autoskalowanie Kliknij przycisk przełącznika, aby włączyć autoskalowanie Typ automatycznej skali Wybierz spośród automatycznego skalowania opartego na obciążeniu lub opartego na harmonogramie Łagodny limit czasu wycofania z eksploatacji Określenie limitu czasu łagodnego wycofania z eksploatacji Liczba domyślnych węzłów roboczych Wybieranie liczby węzłów do automatycznego skalowania Strefa czasowa Wybierz strefę czasową Reguły automatycznego skalowania Wybierz dzień, godzinę rozpoczęcia, godzinę zakończenia, liczbę węzłów roboczych Włączanie protokołu SSH Jeśli to ustawienie jest włączone, umożliwia zdefiniowanie prefiksu i liczby węzłów SSH Kliknij przycisk Dalej: Integracje, aby włączyć i wybrać Log Analytics do rejestrowania.
Usługę Azure Prometheus do monitorowania i pomiarów można włączyć po utworzeniu klastra.
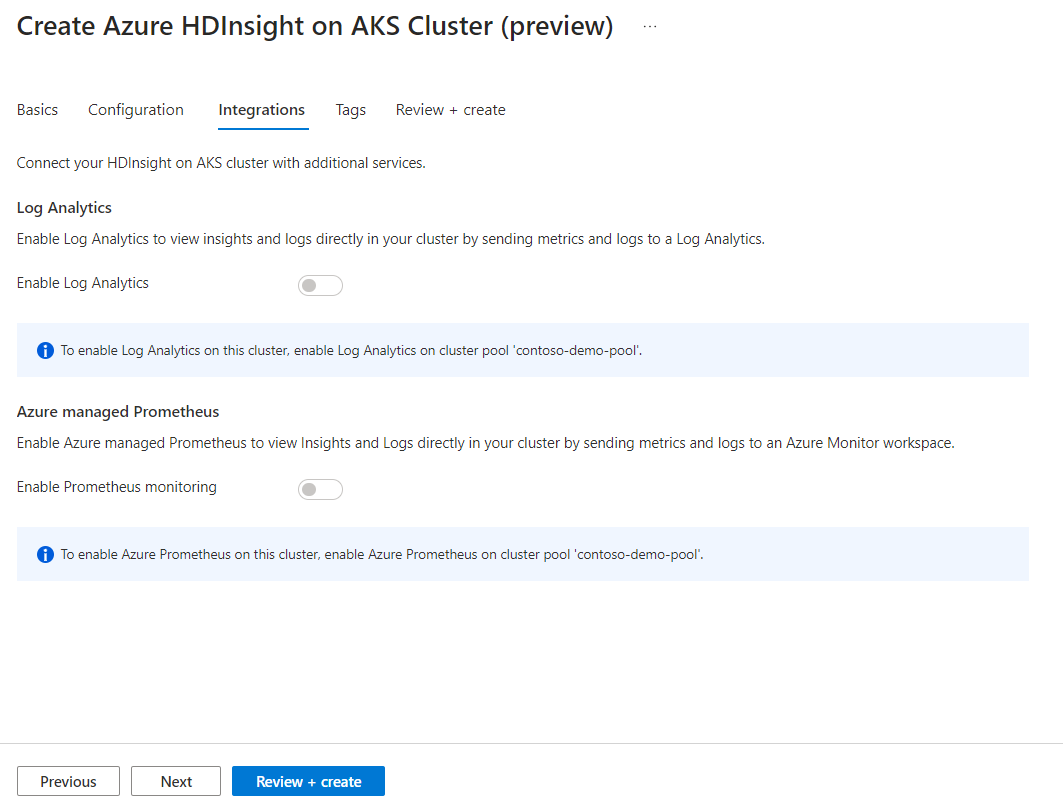
Kliknij przycisk Dalej: tagi, aby przejść do następnej strony.

Na stronie Tagi wprowadź wszelkie tagi, które chcesz dodać do zasobu.
Własność Opis Nazwa Fakultatywny. Wprowadź nazwę, taką jak HDInsight w prywatnej wersji zapoznawczej AKS, aby łatwo zidentyfikować wszystkie zasoby powiązane z twoimi zasobami. Wartość Pozostaw to pole puste Zasób Wybierz pozycję Wszystkie wybrane zasoby Kliknij przycisk Dalej: Przejrzyj i utwórz.
Na stronie Przeglądanie i tworzeniewyszukaj komunikat Walidacja zakończyła się pomyślnie w górnej części strony, a następnie kliknij przycisk Utwórz.
Wdrażanie jest w toku, a na stronie jest wyświetlana strona, gdzie tworzony jest klaster. Utworzenie klastra trwa od 5 do 10 minut. Po utworzeniu klastra zostanie wyświetlony komunikat Wdrożenie zostało ukończone. Jeśli opuścisz stronę, możesz sprawdzić swoje powiadomienia, aby dowiedzieć się o statusie.
Przejdź do strony przeglądu klastra , gdzie możesz zobaczyć linki punktów końcowych.








