Używanie usługi Delta Lake w usłudze Azure HDInsight w usłudze AKS z klastrem Apache Spark™ (wersja zapoznawcza)
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Usługa Azure HDInsight w usłudze AKS to zarządzana usługa oparta na chmurze na potrzeby analizy danych big data, która pomaga organizacjom przetwarzać duże ilości danych. W tym samouczku pokazano, jak używać usługi Delta Lake w usłudze Azure HDInsight w usłudze AKS z klastrem Apache Spark™.
Warunek wstępny
Tworzenie klastra Apache Spark™ w usłudze Azure HDInsight w usłudze AKS
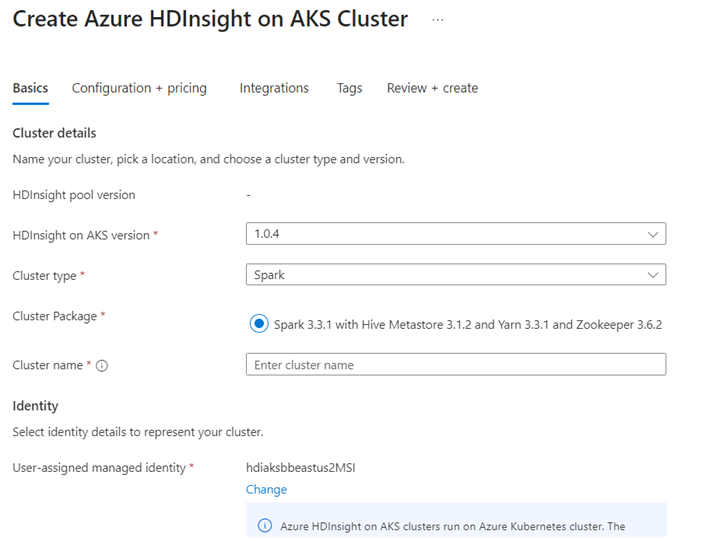
Uruchamianie scenariusza usługi Delta Lake w notesie Jupyter Notebook. Utwórz notes Jupyter i wybierz pozycję "Spark" podczas tworzenia notesu, ponieważ w języku Scala znajduje się poniższy przykład.
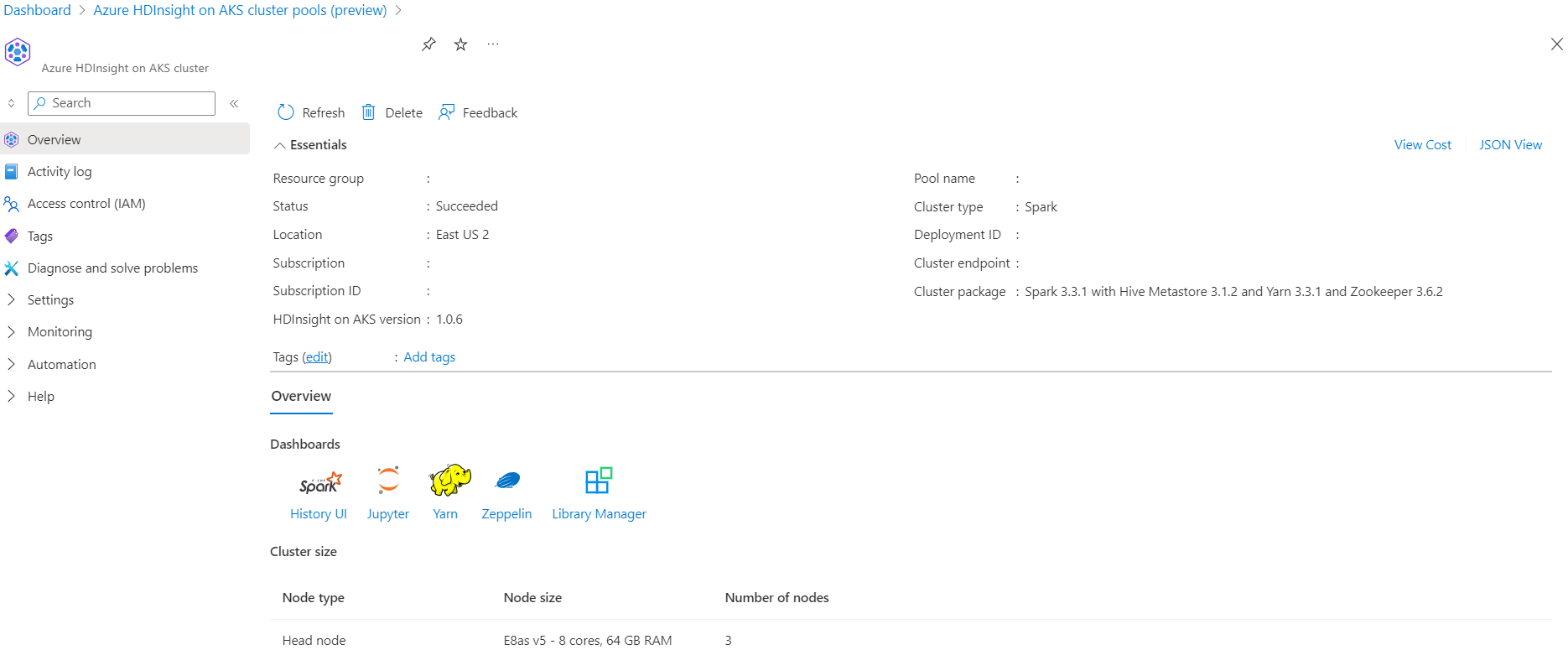


Scenariusz
- Przeczytaj format danych NYC Taxi Parquet — lista adresów URL plików Parquet jest dostarczana przez Komisję Nowojorskiej Taksówki i Limuzyny.
- Dla każdego adresu URL (pliku) wykonaj pewne przekształcenia i zapisz je w formacie delta.
- Oblicz średnią odległość, średni koszt na milę i średni koszt z tabeli delty przy użyciu obciążenia przyrostowego.
- Zapisz obliczoną wartość z kroku 3 w formacie delty do folderu wyjściowego kluczowego wskaźnika wydajności.
- Utwórz tabelę delty w folderze wyjściowym formatu delty (automatyczne odświeżanie).
- Folder wyjściowy kluczowego wskaźnika wydajności ma wiele wersji średniej odległości i średni koszt na milę dla podróży.
Podaj wymagania konfiguracji dla usługi delta lake
Usługa Delta Lake z macierzą zgodności platformy Apache Spark — usługa Delta Lake, zmiana wersji usługi Delta Lake na podstawie wersji platformy Apache Spark.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Wyświetlanie listy plików danych
Uwaga
Te adresy URL plików pochodzą z Komisji Nowojorskiej Taksówki i Limuzyny.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Tworzenie katalogu wyjściowego
Lokalizacja, w której chcesz utworzyć dane wyjściowe formatu różnicowego, w razie potrzeby zmień zmienną transformDeltaOutputPath i avgDeltaOutputKPIPath .
avgDeltaOutputKPIPath— do przechowywania średniego wskaźnika KPI w formacie różnicowymtransformDeltaOutputPath— przechowywanie przekształconych danych wyjściowych w formacie różnicowym
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Tworzenie danych formatu różnicowego na podstawie formatu Parquet
Dane wejściowe pochodzą z
listOfDataFilelokalizacji , z której pobierane są dane https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pageAby zademonstrować podróż i wersję czasu, załaduj dane indywidualnie
Wykonaj transformację i oblicz następujące wskaźniki KPI biznesowe na przyrostowym obciążeniu:
- Średnia odległość
- Średni koszt na milę
- Średni koszt
Zapisywanie przekształconych i kluczowych wskaźników wydajności danych w formacie różnicowym
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Odczytywanie formatu różnicowego przy użyciu tabeli delty
- odczytywanie przekształconych danych
- odczytywanie danych kluczowych wskaźników wydajności
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Drukuj schemat
- Drukuj schemat tabeli delty dla przekształconych i średnich danych kluczowych wskaźników wydajności1.
// tranform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema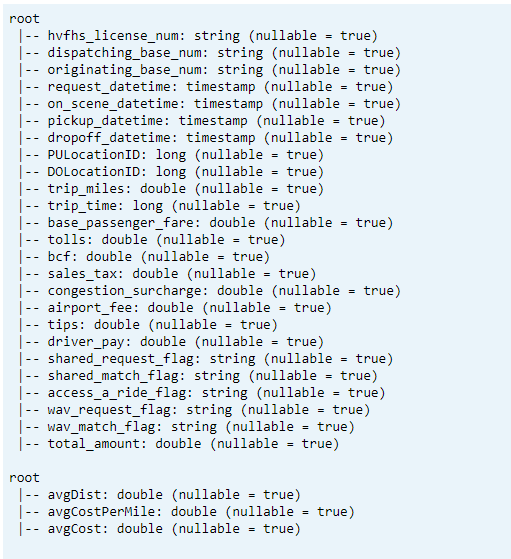
Wyświetlanie ostatniego obliczonego wskaźnika KPI z tabeli danych
dtAvgKpi.toDF.show(false)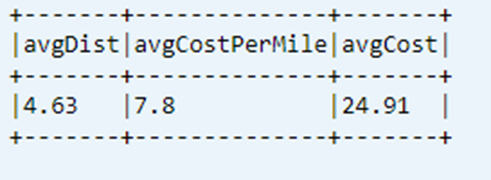


Wyświetlanie obliczonej historii kluczowego wskaźnika wydajności
W tym kroku jest wyświetlana historia tabeli transakcji kluczowego wskaźnika wydajności z _delta_log
dtAvgKpi.history().show(false)

Wyświetlanie danych kluczowych wskaźników wydajności po każdym załadowaniu danych
- Korzystając z podróży w czasie, można wyświetlić zmiany wskaźników KPI po każdym obciążeniu
- Wszystkie zmiany wersji można przechowywać w formacie CSV na
avgMoMKPIChangePathstronie , aby usługa Power BI mogła odczytywać te zmiany
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Odwołanie
- Nazwy projektów apache, Apache Spark, Spark i skojarzone z nimi nazwy projektów typu open source są znakami towarowymi platformy Apache Software Foundation (ASF).