Rozszerzanie dużych modeli językowych poprzez generowanie wspomagane pobieraniem lub dostrajanie
W serii artykułów omawiamy mechanizmy pobierania wiedzy używane przez duże modele językowe (LLMs) do generowania odpowiedzi. Domyślnie LLM ma dostęp tylko do danych użytych do treningu. Można jednak rozszerzyć model tak, aby uwzględniał dane w czasie rzeczywistym lub dane prywatne.
Pierwszy mechanizm to generacja wspomagana wyszukiwaniem (RAG). RAG jest formą przetwarzania wstępnego, która łączy semantyczne wyszukiwanie z kontekstowym primingiem. Prymowanie kontekstowe jest szczegółowo omówione w Kluczowe pojęcia i zagadnienia dotyczące tworzenia generacyjnych rozwiązań sztucznej inteligencji.
Mechanizm drugi to dostrajanie. W ramach dostrajania moduł LLM jest dodatkowo trenowany na określonym zestawie danych po początkowym szerokim szkoleniu. Celem jest dostosowanie usługi LLM do lepszego wykonywania zadań lub zrozumienia pojęć związanych z zestawem danych. Ten proces pomaga modelowi specjalizować się lub poprawić jego dokładność i wydajność w obsłudze określonych typów danych wejściowych lub domen.
W poniższych sekcjach opisano te dwa mechanizmy bardziej szczegółowo.
Informacje o rag
Funkcja RAG jest często używana do włączania scenariusza "czatu za pośrednictwem moich danych". W tym scenariuszu organizacja ma potencjalnie duży korpus treści tekstowych, takich jak dokumenty, dokumentacja i inne zastrzeżone dane. Używa tego korpusu jako podstawy odpowiedzi na polecenia użytkownika.
Generalnie, tworzysz wpis bazy danych dla każdego dokumentu lub części dokumentu oznaczonego jako ciąg. Fragment jest indeksowany na jego osadzanie , czyli tablica liczb (wektor), reprezentujących aspekty dokumentu. Gdy użytkownik prześle zapytanie, przeszukujesz bazę danych pod kątem podobnych dokumentów, a następnie prześlesz zapytanie i dokumenty do usługi LLM, aby utworzyć odpowiedź.
Uwaga
Używamy terminu generacja wspomagana wyszukiwaniem (RAG) adaptacyjnie. Proces wdrażania systemu czatów opartego na RAG, jak opisano w tym artykule, można zastosować niezależnie od tego, czy chcesz używać danych zewnętrznych w funkcji wspierającej (RAG) lub jako głównego elementu odpowiedzi (RCG). Zniuansowane rozróżnienie nie jest omówione w większości lektury dotyczącej RAG.
Tworzenie indeksu wektoryzowanych dokumentów
Pierwszym krokiem do utworzenia systemu czatu opartego na systemie RAG jest utworzenie magazynu danych wektorowych zawierającego wektor osadzania dokumentu lub fragmentu. Rozważmy poniższy diagram, który przedstawia podstawowe kroki tworzenia wektoryzowanego indeksu dokumentów.

Diagram reprezentuje potok danych . Rurociąg przetwarzania danych jest odpowiedzialny za pozyskiwanie, przetwarzanie i zarządzanie danymi stosowanymi przez system. Potok obejmuje wstępne przetwarzanie danych przechowywanych w bazie danych wektorów i zapewnienie, że dane przekazywane do usługi LLM mają poprawny format.
Cały proces jest sterowany pojęciem osadzania, które jest liczbową reprezentacją danych (zazwyczaj wyrazami, frazami, zdaniami lub nawet całymi dokumentami), które przechwytują semantyczne właściwości danych wejściowych w sposób, który może być przetwarzany przez modele uczenia maszynowego.
Aby utworzyć osadzanie, należy wysłać fragment zawartości (zdania, akapity lub całe dokumenty) do interfejsu API osadzania usługi Azure OpenAI. Interfejs API zwraca wektor. Każda wartość w wektorze reprezentuje cechę (wymiar) zawartości. Wymiary mogą obejmować znaczenie tematu, znaczenie semantyczne, składnię i gramatykę, użycie wyrazów i fraz, relacje kontekstowe, styl lub ton. Razem wszystkie wartości wektora reprezentują przestrzeń wymiarową zawartości. Jeśli myślisz o reprezentacji 3D wektora, który ma trzy wartości, konkretny wektor znajduje się w określonym obszarze płaszczyzny płaszczyzny XYZ. Co zrobić, jeśli masz 1000 wartości, a nawet więcej? Chociaż nie jest możliwe, aby ludzie narysowali graf o wymiarach 1000 na arkuszu papieru, aby był bardziej zrozumiały, komputery nie mają problemu z zrozumieniem tego stopnia przestrzeni wymiarowej.
Następny krok diagramu przedstawia przechowywanie wektora i zawartości (lub wskaźnika do lokalizacji zawartości) i innych metadanych w bazie danych wektorów. Baza danych wektorów jest podobna do dowolnego typu bazy danych, ale z dwiema różnicami:
- Wektorowe bazy danych używają wektora jako indeksu do wyszukiwania danych.
- Bazy danych wektorowych implementują algorytm o nazwie wyszukiwania z użyciem cosinusa podobieństwa, nazywany również wyszukiwaniem najbliższego sąsiada. Algorytm używa wektorów, które najlepiej pasują do kryteriów wyszukiwania.
Dzięki korpusowi dokumentów przechowywanych w bazie danych wektorów deweloperzy mogą utworzyć składnik retriever w celu pobrania dokumentów, które są zgodne z zapytaniem użytkownika. Dane są używane do dostarczania LLM danych potrzebnych, aby odpowiedzieć na zapytanie użytkownika.
Odpowiadanie na zapytania przy użyciu dokumentów
System RAG najpierw używa wyszukiwania semantycznego, aby znaleźć artykuły, które mogą być pomocne dla LLM podczas komponowania odpowiedzi. Następnym krokiem jest wysłanie pasujących artykułów wraz z oryginalnym zapytaniem użytkownika do LLM w celu utworzenia odpowiedzi.
Rozważmy następujący diagram jako prostą implementację RAG (czasami nazywaną naiwną rag):
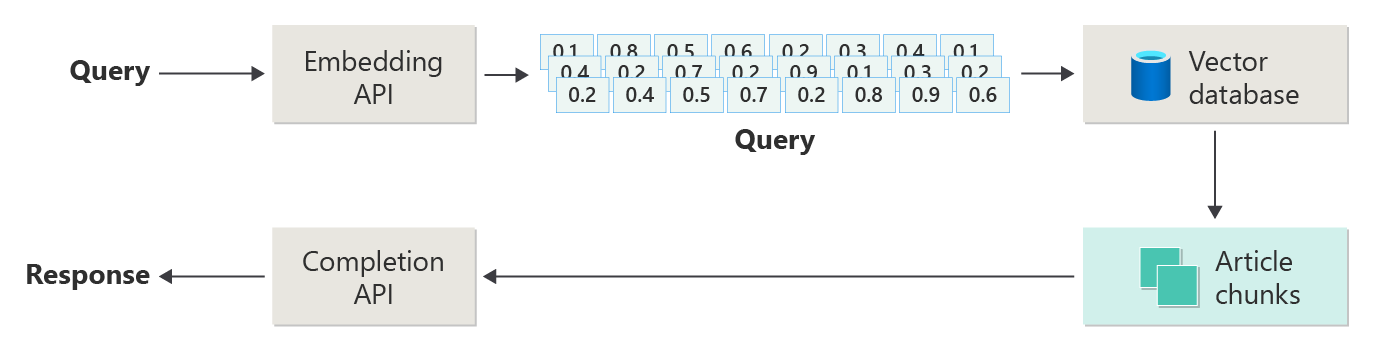
Na diagramie użytkownik przesyła zapytanie. Pierwszym krokiem jest utworzenie osadzenia zapytania użytkownika, aby otrzymać wektor. Następnym krokiem jest przeszukanie wektorowej bazy danych dla tych dokumentów (lub części dokumentów), które są zgodne z najbliższym sąsiadem.
Podobieństwo cosinusowe to miara, która pomaga określić, jak podobne są dwa wektory. Zasadniczo metryka ocenia cosinus kąta między nimi. Podobieństwo cosinus zbliżone do 1 wskazuje wysoki stopień podobieństwa (mały kąt). Podobieństwo bliskie -1 oznacza brak podobieństwa (kąt prawie 180 stopni). Ta metryka ma kluczowe znaczenie dla zadań, takich jak podobieństwo dokumentu, gdzie celem jest znalezienie dokumentów, które mają podobną zawartość lub znaczenie.
algorytmy najbliższego sąsiada działają, wyszukując najbliższe wektory (sąsiady) dla punktu w przestrzeni wektorowej. W algorytmie k najbliższych sąsiadów (KNN)k odnosi się do liczby najbliższych sąsiadów do rozważenia. Takie podejście jest szeroko stosowane w klasyfikacji i regresji, gdzie algorytm przewiduje etykietę nowego punktu danych na podstawie etykiety większości spośród jego k najbliższych sąsiadów w zestawie treningowym. Funkcja KNN i podobieństwo cosinus są często używane razem w systemach, takich jak aparaty rekomendacji, gdzie celem jest znalezienie elementów najbardziej podobnych do preferencji użytkownika, reprezentowanych jako wektory w miejscu osadzania.
Bierzesz najlepsze wyniki z tego wyszukiwania i przesyłasz pasującą treść w oparciu o zapytanie użytkownika, aby wygenerować odpowiedź, która (miejmy nadzieję) bazuje na dopasowanej treści.
Wyzwania i zagadnienia
System RAG ma swój zestaw wyzwań związanych z implementacją. Prywatność danych jest najważniejsza. System musi obsługiwać dane użytkowników w sposób odpowiedzialny, szczególnie w przypadku pobierania i przetwarzania informacji ze źródeł zewnętrznych. Wymagania obliczeniowe mogą być również istotne. Zarówno proces pobierania, jak i procesy generowania intensywnie korzystają z zasobów. Zapewnienie dokładności i istotności odpowiedzi podczas zarządzania uprzedzeniami w danych lub modelu jest kolejnym krytycznym zagadnieniem. Deweloperzy muszą uważnie poruszać się po tych wyzwaniach, aby tworzyć wydajne, etyczne i cenne systemy RAG.
Budowa zaawansowanych systemów generacji wspomaganej wyszukiwaniem przedstawia więcej informacji na temat tworzenia potoków danych i inferencji w celu wdrożenia gotowego do produkcji systemu RAG.
Jeśli chcesz od razu rozpocząć eksperymentowanie z tworzeniem generowania rozwiązania sztucznej inteligencji, zalecamy zapoznanie się z omówieniem rozpoczynania czatu przy użyciu własnego przykładu danych dla języka Python. Samouczek jest również dostępny dla .NET, Javai JavaScript.
Dostrajanie modelu
W kontekście usługi LLM dostrajanie jest procesem dostosowywania parametrów modelu przez trenowanie go w zestawie danych specyficznym dla domeny po początkowym wytrenowaniu modułu LLM na dużym, zróżnicowanym zestawie danych.
Maszyny LLM są trenowane (wstępnie trenowane) na szerokim zestawie danych, chwytając strukturę języka, kontekst i szeroką gamę wiedzy. Ten etap obejmuje uczenie się ogólnych wzorców językowych. Dostrajanie precyzyjne dodaje więcej trenowania do wstępnie wytrenowanego modelu na podstawie mniejszego, konkretnego zestawu danych. Ta faza szkolenia pomocniczego ma na celu dostosowanie modelu w celu lepszego wykonania określonych zadań lub zrozumienia określonych domen, zwiększenie dokładności i istotności tych wyspecjalizowanych aplikacji. Podczas dostrajania wagi modelu są dostosowywane w celu lepszego przewidywania lub zrozumienia niuansów tego mniejszego zestawu danych.
Oto kilka kwestii do rozważenia:
- Specjalizacja: Dostrajanie dopasowuje model do określonych zadań, takich jak analiza dokumentów prawnych, interpretacja tekstu medycznego lub interakcje z obsługą klienta. Ta specjalizacja sprawia, że model jest bardziej skuteczny w tych obszarach.
- Wydajność: bardziej wydajne jest dostosowanie wstępnie wytrenowanego modelu dla określonego zadania niż trenowanie modelu od podstaw. Dostrajanie wymaga mniejszej ilości danych i mniejszej liczby zasobów obliczeniowych.
- Adaptacja: Dostrajanie umożliwia dostosowanie do nowych zadań lub domen, które nie były częścią oryginalnych danych treningowych. Możliwość dostosowywania modeli LLM sprawia, że są one wszechstronnymi narzędziami do różnorodnych zastosowań.
- Ulepszona wydajność: W przypadku zadań, które różnią się od tych, na których model został pierwotnie wytrenowany, dostrajanie może prowadzić do lepszej wydajności. Dostrajanie dopasowuje model, aby zrozumieć konkretny język, styl lub terminologię używaną w nowej domenie.
- Personalizacja: w niektórych aplikacjach dostrajanie może pomóc w spersonalizowaniu odpowiedzi lub przewidywań modelu w celu dopasowania do określonych potrzeb lub preferencji użytkownika lub organizacji. Jednak dostrajanie ma określone wady i ograniczenia. Zrozumienie tych czynników może pomóc w podjęciu decyzji, kiedy wybrać precyzyjne dostrajanie w porównaniu z alternatywami, takimi jak RAG.
- wymagania dotyczące danych: dostrajanie wymaga wystarczająco dużego i wysokiej jakości zestawu danych specyficznego dla docelowego zadania lub domeny. Zbieranie i curowanie tego zestawu danych może być trudne i intensywnie obciążające zasoby.
- Ryzyko nadmiernego dopasowania: Nadmierne dopasowanie jest ryzykiem, zwłaszcza w przypadku małego zestawu danych. Nadmierne dopasowanie sprawia, że model działa dobrze na danych treningowych, ale słabo na nowych, niewidzianych danych. Zdolność do uogólniania spada w przypadku nadmiernego dopasowania.
- koszty i zasoby: Chociaż mniej zasobożerne niż trenowanie od podstaw, fine-tuning nadal wymaga zasobów obliczeniowych, zwłaszcza w przypadku dużych modeli i zestawów danych. Koszt może być zbyt uciążliwy dla niektórych użytkowników lub projektów.
- Konserwacja i aktualizowanie: Dopasowane modele mogą wymagać regularnych aktualizacji, aby zachować swoją skuteczność, gdy informacje specyficzne dla domeny zmieniają się z czasem. Ta ciągła konserwacja wymaga dodatkowych zasobów i danych.
- Dryf modelu: ponieważ model jest dostosowany do określonych zadań, może utracić niektóre ogólne rozumienie języka i wszechstronność. To zjawisko nazywa się dryfem modelu .
Dostosowywanie modelu za pomocą dostrajania wyjaśnia, jak dostosować model. Na wysokim poziomie udostępniasz zestaw danych JSON z potencjalnymi pytaniami i preferowanymi odpowiedziami. Dokumentacja sugeruje, że istnieją zauważalne ulepszenia, zapewniając od 50 do 100 par pytań i odpowiedzi, ale prawidłowa liczba różni się znacznie w przypadku użycia.
Dostrajanie w porównaniu z RAG
Na pierwszy rzut oka, może się wydawać, że istnieje sporo pola wspólnego między dostrajaniem a RAG. Wybór między dostrajaniem i pobieraniem rozszerzonej generacji zależy od konkretnych wymagań zadania, w tym oczekiwań dotyczących wydajności, dostępności zasobów i potrzeby specyficznej dla domeny w porównaniu z uogólnianiem.
Kiedy należy używać dostrajania zamiast RAG:
- wydajność specyficzna dla zadania: dostrajanie modelu jest preferowane, gdy krytyczne znaczenie ma wysoka wydajność w określonym zadaniu i istnieją wystarczające dane specyficzne dla domeny, aby skutecznie trenować model bez znaczącego ryzyka nadmiernego dopasowania.
- Kontrola nad danymi: Jeśli masz zastrzeżone lub wysoce wyspecjalizowane dane, które znacznie różnią się od danych, na których model podstawowy został wytrenowany, dzięki czemu dostrajanie pozwala uwzględnić unikatową wiedzę w modelu.
- Ograniczona potrzeba aktualizacji w czasie rzeczywistym: jeśli zadanie nie wymaga ciągłego aktualizowania modelu przy użyciu najnowszych informacji, dostrajanie może być bardziej wydajne, ponieważ modele RAG zwykle potrzebują dostępu do up-to-date zewnętrznych baz danych lub Internetu w celu ściągnięcia najnowszych danych.
Kiedy wolisz RAG nad dostrajaniem:
- zawartość dynamiczna lub rozwijająca się zawartość: RAG jest bardziej odpowiedni do zadań, w których najbardziej aktualne informacje mają krytyczne znaczenie. Ponieważ modele RAG mogą pobierać dane ze źródeł zewnętrznych w czasie rzeczywistym, są one lepiej dostosowane do aplikacji, takich jak generowanie wiadomości lub odpowiadanie na pytania dotyczące ostatnich zdarzeń.
- Uogólnienie nad specjalizacją: Jeśli celem jest utrzymanie silnej wydajności w wielu różnych tematach, a nie wyróżnianie się w wąskiej domenie, RAG może być preferowane. Używa ona baza wiedzy zewnętrznych, umożliwiając generowanie odpowiedzi w różnych domenach bez ryzyka nadmiernego dopasowania do określonego zestawu danych.
- ograniczenia zasobów: w przypadku organizacji z ograniczonymi zasobami na potrzeby zbierania danych i trenowania modeli użycie metody RAG może oferować opłacalną alternatywę do dostrajania, zwłaszcza jeśli model podstawowy wykonuje już dość dobrze odpowiednie zadania.
Końcowe zagadnienia dotyczące projektowania aplikacji
Poniżej przedstawiono krótką listę kwestii, które należy wziąć pod uwagę i inne wnioski z tego artykułu, które mogą mieć wpływ na decyzje projektowe aplikacji:
- Zdecyduj między dostrajaniem a narzędziem RAG na podstawie konkretnych potrzeb aplikacji. Dostrajanie może oferować lepszą wydajność wyspecjalizowanych zadań, podczas gdy rag może zapewnić elastyczność i up-to-date zawartości dla aplikacji dynamicznych.