Tworzenie zaawansowanych systemów generowania rozszerzonego pobierania
W tym artykule szczegółowo omówiono generację z rozszerzeniem pobierania (RAG). Opiszemy pracę i zagadnienia, które są wymagane dla deweloperów w celu utworzenia gotowego do produkcji rozwiązania RAG.
Aby dowiedzieć się więcej o dwóch opcjach tworzenia aplikacji "czat oparty na danych", jednym z najważniejszych przypadków użycia generatywnej sztucznej inteligencji w firmach, patrz Rozszerzenie LLM za pomocą RAG lub dostrajanie.
Na poniższym diagramie przedstawiono kroki lub fazy RAG:
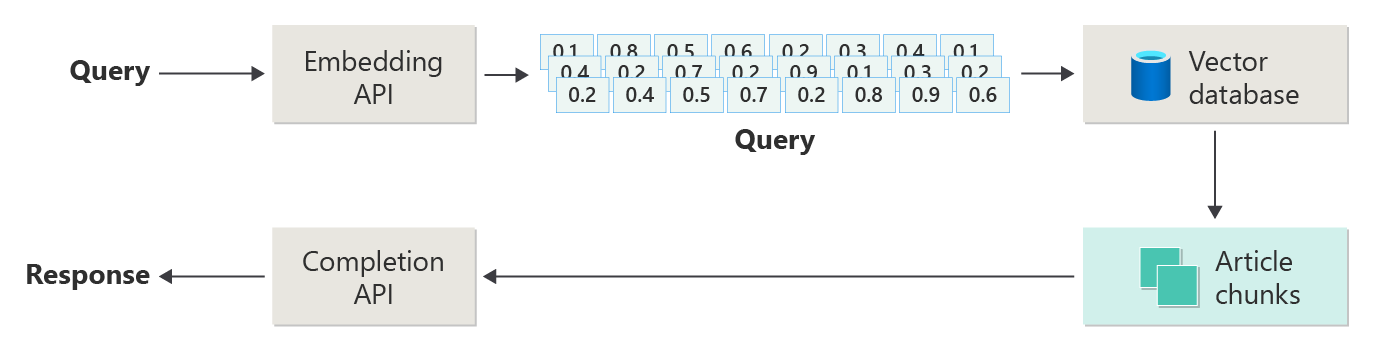
Ten obraz jest określany jako naiwny RAG. Jest to przydatny sposób początkowego zrozumienia mechanizmów, ról i obowiązków, które są wymagane do zaimplementowania systemu czatów opartych na systemie RAG.
Jednak rzeczywista implementacja ma o wiele więcej kroków przetwarzania wstępnego i końcowego, aby przygotować artykuły, zapytania i odpowiedzi do użycia. Na poniższym diagramie przedstawiono bardziej realistyczne przedstawienie RAG, czasami nazywane zaawansowanym RAG:

Ten artykuł zawiera koncepcyjną strukturę do zrozumienia faz przetwarzania wstępnego i przetwarzania końcowego w rzeczywistym systemie czatów opartych na programie RAG:
- Faza pozyskiwania
- Faza przetwarzania wnioskowania
- Faza oceny
Pozyskiwanie danych
Wprowadzanie polega przede wszystkim na przechowywaniu dokumentów organizacji, dzięki czemu można łatwo uzyskać dostęp do nich, aby odpowiedzieć na pytanie użytkownika. Wyzwanie polega na upewnieniu się, że części dokumentów, które najlepiej pasują do zapytania użytkownika, znajdują się i są używane podczas wnioskowania. Dopasowywanie odbywa się głównie poprzez wektoryzowane osadzanie i wyszukiwanie podobieństwa cosinus. Jednak dopasowywanie ułatwia zrozumienie charakteru zawartości (na przykład wzorców i formularzy) oraz strategii organizacji danych (struktury danych przechowywanych w bazie danych wektorowej).
W przypadku przetwarzania deweloperzy muszą wziąć pod uwagę następujące kroki:
- Wstępne przetwarzanie i wyodrębnianie zawartości
- Strategia fragmentowania
- Organizacja fragmentowania
- Strategia aktualizacji
Wstępne przetwarzanie i wyodrębnianie zawartości
Czysta i dokładna zawartość jest jednym z najlepszych sposobów poprawy ogólnej jakości systemu czatów opartych na rag. Aby uzyskać czystą, dokładną zawartość, zacznij od przeanalizowanie kształtu i formularza dokumentów do indeksowania. Czy dokumenty są zgodne z określonymi wzorcami zawartości, takimi jak dokumentacja? Jeśli nie, jakie typy pytań mogą odpowiedzieć na dokumenty?
W pierwszej kolejności przygotuj kroki w potoku przetwarzania danych w celu:
- Standaryzacja formatów tekstu
- Obsługa znaków specjalnych
- Usuwanie niepowiązanej, nieaktualnej zawartości
- Konto dla zawartości w wersji
- Konto środowiska zawartości (karty, obrazy, tabele)
- Wyodrębnianie metadanych
Niektóre z tych informacji (na przykład metadane) mogą być przydatne, jeśli dokument jest przechowywany w bazie danych wektorów do użycia podczas procesu pobierania i oceny w potoku wnioskowania. Można go również połączyć z fragmentem tekstu, aby wpłynąć na wektorowe osadzanie fragmentu.
Strategia fragmentowania
Jako deweloper musisz zdecydować, jak podzielić większy dokument na mniejsze fragmenty. Fragmentowanie może poprawić istotność dodatkowej zawartości wysyłanej do usługi LLM, aby dokładnie odpowiedzieć na zapytania użytkowników. Rozważ również, jak używać fragmentów po pobraniu. Projektanci systemów powinni badać typowe techniki branżowe i przeprowadzać eksperymenty. Możesz nawet przetestować swoją strategię w ograniczonym zakresie w swojej organizacji.
Deweloperzy muszą wziąć pod uwagę następujące kwestie:
- Optymalizacja rozmiaru fragmentu: Określ idealny rozmiar fragmentu i sposób wyznaczania fragmentu. Według sekcji? Według akapitu? Według zdania?
- nakładające się i przesuwane fragmenty okien: określ, czy chcesz podzielić zawartość na odrębne fragmenty, czy fragmenty nakładają się na siebie? Można nawet wykonać obie czynności w projekcie okna przesuwnego.
- Small2Big: Gdy fragmentowanie odbywa się na poziomie szczegółowym, takim jak jedno zdanie, czy zawartość jest zorganizowana tak, aby łatwo było znaleźć sąsiednie zdania lub akapit zawierający zdanie? Pobranie tych informacji i dostarczenie ich do modułu LLM może dostarczyć mu więcej kontekstu, aby odpowiedzieć na zapytania użytkowników. Aby uzyskać więcej informacji, zobacz następną sekcję.
Organizacja fragmentowania
W systemie RAG strategicznie organizowanie danych w bazie danych wektorów jest kluczem do efektywnego pobierania odpowiednich informacji w celu rozszerzenia procesu generowania. Poniżej przedstawiono typy strategii indeksowania i pobierania, które można wziąć pod uwagę:
- indeksy hierarchiczne: takie podejście obejmuje tworzenie wielu warstw indeksów. Indeks najwyższego poziomu (indeks podsumowania) szybko zawęża przestrzeń wyszukiwania do podzbioru potencjalnie odpowiednich fragmentów. Indeks drugiego poziomu (indeks fragmentów) zapewnia bardziej szczegółowe wskaźniki do rzeczywistych danych. Ta metoda może znacznie przyspieszyć proces wyszukiwania, ponieważ zmniejsza liczbę wpisów do skanowania w szczegółowym indeksie poprzez wstępne filtrowanie przy użyciu indeksu podsumowującego.
-
wyspecjalizowane indeksy: w zależności od charakteru danych i relacji między fragmentami można użyć wyspecjalizowanych indeksów, takich jak grafowe lub relacyjne bazy danych:
- Indeksy oparte na grafach są przydatne, gdy fragmenty mają połączone informacje lub relacje, które mogą zwiększyć pobieranie, takie jak sieci cytatów lub wykresy wiedzy.
- Relacyjne bazy danych mogą być skuteczne, jeśli fragmenty są ustrukturyzowane w formacie tabelarycznym. Użyj zapytań SQL, aby filtrować i pobierać dane na podstawie określonych atrybutów lub relacji.
- Indeksy hybrydowe: Pewne podejście hybrydowe łączy wiele metod indeksowania, aby zastosować ich mocne strony do Twojej ogólnej strategii. Na przykład możesz użyć indeksu hierarchicznego do początkowego filtrowania i indeksu opartego na grafach, aby dynamicznie eksplorować relacje między fragmentami podczas pobierania.
Optymalizacja wyrównania
Aby zwiększyć istotność i dokładność pobranych fragmentów, należy je ściśle dopasować do pytań lub typów zapytań, na które odpowiadają. Jedną ze strategii jest wygenerowanie i wstawienie hipotetycznego pytania dla każdego fragmentu reprezentującego pytanie, na które najlepiej odpowiada fragment. Pomaga to na kilka sposobów:
- Ulepszone dopasowywanie: podczas pobierania system może porównać zapytanie przychodzące z tymi hipotetycznymi pytaniami, aby znaleźć najlepsze dopasowanie w celu poprawy istotności pobranych fragmentów.
- dane treningowe modeli uczenia maszynowego: te pary pytań i fragmentów mogą być danymi treningowymi w celu ulepszenia modeli uczenia maszynowego, które są składnikami bazowymi systemu RAG. System RAG uczy się, na które typy pytań najlepiej odpowiada każdy fragment.
- obsługa zapytań bezpośrednich: jeśli zapytanie rzeczywistego użytkownika jest ściśle zgodne z hipotetycznym pytaniem, system może szybko pobrać odpowiedni fragment i użyć odpowiedniego fragmentu i przyspieszyć czas odpowiedzi.
Hipotetyczne pytanie każdego fragmentu działa jak etykieta, która kieruje algorytmem pobierania, dzięki czemu jest on bardziej skoncentrowany i świadomy kontekstu. Ten rodzaj optymalizacji jest przydatny, gdy fragmenty obejmują szeroką gamę tematów lub typów informacji.
Strategie aktualizacji
Jeśli organizacja indeksuje dokumenty, które są często aktualizowane, ważne jest zachowanie zaktualizowanego korpusu, aby upewnić się, że składnik pobierania może uzyskać dostęp do najbardziej aktualnych informacji. Składnik retriever jest logiką w systemie, która uruchamia zapytanie względem bazy danych wektorów, a następnie zwraca wyniki. Poniżej przedstawiono kilka strategii aktualizowania wektorowej bazy danych w następujących typach systemów:
Aktualizacje przyrostowe:
- Regularne odstępy: Zaplanuj aktualizacje w regularnych odstępach czasu (na przykład codziennie lub co tydzień) w zależności od częstotliwości zmian w dokumencie. Ta metoda zapewnia okresowe odświeżanie bazy danych zgodnie ze znanym harmonogramem.
- aktualizacje oparte na wyzwalaczach: zaimplementuj system, w którym aktualizacja wyzwala ponowne indeksowanie. Na przykład wszelkie modyfikacje lub dodanie dokumentu automatycznie inicjują ponowne indeksowanie w dotkniętych sekcjach.
aktualizacje częściowe:
- Selektywne ponowne indeksowanie: Zamiast ponownego indeksowania całej bazy danych, zaktualizuj tylko zmienione części danych. Takie podejście może być bardziej wydajne niż pełne ponowne indeksowanie, zwłaszcza w przypadku dużych zestawów danych.
- Kodowanie różnicowe: przechowuj tylko różnice między istniejącymi dokumentami a ich zaktualizowanymi wersjami. Takie podejście zmniejsza obciążenie przetwarzania danych, unikając konieczności przetwarzania niezmienionych danych.
wersjonowanie:
- Migawka: obsługa wersji corpus dokumentu w różnych punktach w czasie. Ta technika zapewnia mechanizm tworzenia kopii zapasowych i umożliwia systemowi przywracanie lub odwoływanie się do poprzednich wersji.
- Kontrola wersji dokumentu: użyj systemu kontroli wersji, aby systematycznie śledzić zmiany dokumentów w celu utrzymania historii zmian i upraszczania procesu aktualizacji.
aktualizacje w czasie rzeczywistym:
- Przetwarzanie strumieniowe: Gdy aktualność informacji ma kluczowe znaczenie, stosuj technologie przetwarzania strumieniowego do aktualizacji baz danych wektorowych w czasie rzeczywistym w miarę wprowadzania zmian w dokumencie.
- wykonywanie zapytań na żywo: Zamiast polegać wyłącznie na wektorach wstępnie indeksowanych, użyj podejścia do zapytań o dane na żywo dla odpowiedzi up-to-date, ewentualnie łącząc dane na żywo z buforowanymi wynikami w celu uzyskania wydajności.
techniki optymalizacji:
przetwarzanie wsadowe: przetwarzanie wsadowe gromadzi zmiany, aby stosować je rzadziej, optymalizując tym samym zasoby i zmniejszając obciążenie.
podejścia hybrydowe: połącz różne strategie:
- Użyj aktualizacji przyrostowych w przypadku drobnych zmian.
- Użyj pełnego ponownego indeksowania dla głównych aktualizacji.
- Dokumentowanie zmian strukturalnych wprowadzonych w korpusie.
Wybór odpowiedniej strategii aktualizacji lub odpowiedniej kombinacji zależy od konkretnych wymagań, w tym:
- Rozmiar korpusu dokumentu
- Częstotliwość aktualizacji
- Wymagania dotyczące danych w czasie rzeczywistym
- Dostępność zasobów
Oceń te czynniki na podstawie potrzeb określonej aplikacji. Każde podejście ma kompromisy w zakresie złożoności, kosztów i opóźnień aktualizacji.
Potok wnioskowania
Artykuły są fragmentowane, wektoryzowane i przechowywane w bazie danych wektorów. Teraz skoncentruj się na rozwiązywaniu problemów z ukończeniem.
Aby uzyskać najdokładniejsze i wydajne ukończenie, należy uwzględnić wiele czynników:
- Czy zapytanie użytkownika zostało napisane w sposób umożliwiający uzyskanie wyników, których szuka użytkownik?
- Czy zapytanie użytkownika narusza jakiekolwiek zasady organizacji?
- Jak ponownie napisać zapytanie użytkownika, aby zwiększyć prawdopodobieństwo znalezienia najbliższych dopasowań w bazie danych wektorów?
- Jak ocenić wyniki zapytania, aby upewnić się, że fragmenty artykułu są zgodne z zapytaniem?
- Jak ocenić i zmodyfikować wyniki zapytania przed przekazaniem ich do usługi LLM, aby upewnić się, że w zakończeniu znajdują się najbardziej istotne szczegóły?
- Jak ocenić odpowiedź llM, aby upewnić się, że ukończenie usługi LLM odpowiada na oryginalne zapytanie użytkownika?
- Jak upewnić się, że odpowiedź LLM jest zgodna z zasadami organizacji?
Cały pipeline wnioskowania działa w czasie rzeczywistym. Nie ma jednego właściwego sposobu projektowania kroków przetwarzania wstępnego i przetwarzania końcowego. Prawdopodobnie zdecydujesz się na połączenie logiki programowania z innymi wywołaniami LLM. Jedną z najważniejszych kwestii jest kompromis między tworzeniem najbardziej dokładnego i zgodnego potoku oraz kosztem i opóźnieniem wymaganym do jego wykonania.
Zidentyfikujmy konkretne strategie na każdym etapie potoku wnioskowania.
Kroki przetwarzania wstępnego zapytań
Przetwarzanie wstępne zapytań odbywa się natychmiast po przesłaniu zapytania przez użytkownika:

Celem tych kroków jest upewnienie się, że użytkownik zadaje pytania, które znajdują się w zakresie systemu i przygotować zapytanie użytkownika w celu zwiększenia prawdopodobieństwa zlokalizowania najlepszych możliwych fragmentów artykułu przy użyciu podobieństwa cosinus lub wyszukiwania "najbliższego sąsiada".
Sprawdzanie zasad: Na tym etapie stosuje się mechanizmy logiczne, które identyfikują, usuwają, oznaczają lub odrzucają określoną zawartość. Niektóre przykłady obejmują usuwanie danych osobowych, usuwanie wulgaryzmów i identyfikowanie prób jailbreaku. Jailbreaking odnosi się do prób użytkowników obejścia lub manipulowania wbudowanymi wytycznymi dotyczącymi bezpieczeństwa, etyki lub działania modelu.
Przekształcanie zapytań: ten krok może zawierać rozszerzanie akronimów, usuwanie slangu lub przeformułowanie pytania, aby zadać je w sposób bardziej abstrakcyjny, wyodrębniając pojęcia i zasady wysokiego poziomu (zachęcanie do refleksji).
Odmianą monitowania metodą krokowego wycofywania się jest Hipotetyczne Osadzanie Dokumentów (HyDE). HyDE używa LLM do odpowiadania na pytanie użytkownika, tworzy wektor dla tej odpowiedzi (hipotetyczny wektor dokumentu), a następnie używa tego wektora do uruchomienia wyszukiwania przeciwko bazie danych wektorów.
Zapytania podrzędne
Krok przetwarzania podzapytania jest oparty na oryginalnym zapytaniu. Jeśli oryginalne zapytanie jest długie i złożone, może być przydatne programowe podzielenie go na kilka mniejszych zapytań, a następnie połączenie wszystkich odpowiedzi.
Na przykład pytanie dotyczące odkryć naukowych w fizyce może brzmieć: "Kto przyczynił się bardziej znaczący wkład w nowoczesną fizykę, Alberta Einsteina lub Nielsa Bohra?"
Podział złożonych zapytań na podzapytania sprawia, że są one bardziej zarządzane:
- Subquery 1: "Jaki jest kluczowy wkład Alberta Einsteina w nowoczesną fizykę?"
- Subquery 2: "Jaki jest kluczowy wkład Nielsa Bohra do nowoczesnej fizyki?"
Wyniki tych podzapytań przedstawiają główne teorie i odkrycia każdego fizyka. Na przykład:
- Dla Einsteina wkład może obejmować teorię względności, efekt fotoelektryczny i E=mc^2.
- W przypadku Bohra wkład może obejmować model Bohra atomu wodoru, prace Bohra nad mechaniką kwantową i zasadą uzupełniania Bohra.
Po określeniu tych elementów można je ocenić, aby ustalić więcej podzapytań. Na przykład:
- Subquery 3: "Jak teorie Einsteina miały wpływ na rozwój współczesnej fizyki?"
- Subquery 4: "Jak teorie Bohra miały wpływ na rozwój współczesnej fizyki?"
Te podzapytania badają wpływ każdego naukowca na fizykę, na przykład:
- Jak teorie Einsteina doprowadziły do postępu w kosmologii i teorii kwantowej
- Jak praca Bohra przyczyniła się do zrozumienia struktury atomowej i mechaniki kwantowej
Połączenie wyników tych podzapytania może pomóc modelowi językowemu stworzyć bardziej kompleksową odpowiedź na temat tego, kto wniósł większy wkład w nowoczesną fizykę w oparciu o ich postęp teoretyczny. Ta metoda upraszcza oryginalne złożone zapytanie, uzyskując dostęp do bardziej szczegółowych, odpowiadających składników, a następnie syntetyzując te ustalenia w spójną całość.
Router zapytań
Organizacja może wybrać podzielenie jej korpusu zawartości na wiele magazynów wektorów lub na całe systemy pobierania. W tym scenariuszu można użyć routera zapytań. Router zapytań wybiera najbardziej odpowiednią bazę danych lub indeks, aby zapewnić najlepsze odpowiedzi na określone zapytanie.
Router zapytań zwykle działa w punkcie po sformułowaniu zapytania przez użytkownika, ale przed wysłaniem zapytania do systemów pobierania.
Oto uproszczony przepływ pracy routera zapytań:
- analiza zapytań: LLM lub inny składnik analizuje przychodzące zapytanie, aby zrozumieć jego zawartość, kontekst i rodzaj informacji, które mogą być potrzebne.
- wybór indeksu: na podstawie analizy router zapytań wybiera jeden lub więcej indeksów z potencjalnie kilku dostępnych indeksów. Każdy indeks może być zoptymalizowany pod kątem różnych typów danych lub zapytań. Na przykład niektóre indeksy mogą być bardziej odpowiednie dla zapytań faktycznych. Inne indeksy mogą wyróżniać się w dostarczaniu opinii lub subiektywnej treści.
- Przesłano zapytanie: Zapytanie jest wysyłane do wybranego indeksu.
- agregacja wyników: odpowiedzi z wybranych indeksów są pobierane i ewentualnie agregowane lub dalej przetwarzane w celu utworzenia kompleksowej odpowiedzi.
- generowania odpowiedzi: ostatnim krokiem jest generowanie spójnej odpowiedzi na podstawie pobranych informacji, ewentualnie integrowanie lub synchronizowanie zawartości z wielu źródeł.
Organizacja może używać wielu aparatów pobierania lub indeksów dla następujących przypadków użycia:
- specjalizacja typu danych: Niektóre indeksy mogą specjalizować się w artykułach informacyjnych, innych w dokumentach akademickich, a jeszcze inne w ogólnej zawartości internetowej lub określonych bazach danych, takich jak informacje medyczne lub prawne.
- optymalizacji typów zapytań: niektóre indeksy mogą być zoptymalizowane pod kątem szybkiego wyszukiwania faktów (na przykład dat lub zdarzeń). Inne mogą być lepsze w przypadku złożonych zadań rozumowania lub zapytań wymagających głębokiej wiedzy na temat domeny.
- Różnice algorytmiczne: Różne algorytmy pobierania mogą być używane w różnych silnikach, takich jak wyszukiwania podobieństwa oparte na wektorach, tradycyjne wyszukiwania oparte na słowach kluczowych lub bardziej zaawansowane modele rozumienia semantycznego.
Wyobraź sobie system oparty na RAG, który jest używany w kontekście doradztwa medycznego. System ma dostęp do wielu indeksów:
- Indeks publikacji medycznej zoptymalizowany pod kątem szczegółowych i technicznych wyjaśnień
- Indeks badania przypadku klinicznego, który dostarcza rzeczywistych przykładów objawów i leczenia
- Ogólny indeks informacji o kondycji dla podstawowych zapytań i informacji o zdrowiu publicznym
Jeśli użytkownik zadaje pytanie techniczne dotyczące skutków chemicznych nowego leku, router zapytań może określić priorytety indeksu papieru badawczego medycznego ze względu na jego głębokość i nacisk techniczny. Na pytanie dotyczące typowych objawów typowej choroby, jednak ogólny indeks zdrowia może być wybrany dla jego szerokiej i łatwo zrozumiałej treści.
Kroki przetwarzania po pobraniu
Przetwarzanie po pobraniu następuje po tym, jak komponent retriever pozyska odpowiednie fragmenty zawartości z bazy danych wektorów.

Po pobraniu fragmentów zawartości kandydata następnym krokiem jest zweryfikowanie przydatności fragmentu artykułu podczas wzbogacania zapytania LLM przed przygotowaniem zapytania do prezentacji LLM.
Poniżej przedstawiono niektóre aspekty podpowiedzi do rozważenia:
- Uwzględnienie zbyt dużej ilości informacji uzupełniających może spowodować zignorowanie najważniejszych informacji.
- Uwzględnienie nieistotnych informacji może negatywnie wpłynąć na odpowiedź.
Innym zagadnieniem jest igła w siana problem, termin, który odnosi się do znanego dziwactwa niektórych LLMs, w których zawartość na początku i na końcu monitu mają większą wagę do LLM niż zawartość w środku.
Na koniec należy wziąć pod uwagę maksymalną długość okna kontekstowego llM i liczbę tokenów wymaganych do wykonania niezwykle długich monitów (zwłaszcza w przypadku zapytań na dużą skalę).
Aby rozwiązać te problemy, potok przetwarzania po pobraniu może obejmować następujące kroki:
- wyniki filtrowania: W tym kroku upewnij się, że fragmenty artykułu zwracane przez bazę danych wektorów są istotne dla zapytania. Jeśli tak nie jest, wynik zostanie zignorowany, gdy zostanie skomponowany monit LLM.
- Ponowne klasyfikowanie: Przypisywanie rang fragmentom artykułu pobranym z magazynu wektorów, aby upewnić się, że odpowiednie szczegóły znajdują się w pobliżu krawędzi (początku i końca) zapytania.
- Kompresja zapytania: użyj małego, niedrogiego modelu do skompresowania i podsumowania wielu fragmentów artykułu w jednym skompresowanym zapytaniu przed wysłaniem zapytania do LLM.
Kroki przetwarzania po zakończeniu
Przetwarzanie po zakończeniu odbywa się po wykonaniu zapytania użytkownika i wysłaniu wszystkich fragmentów zawartości do usługi LLM:

Walidacja dokładności odbywa się po zakończeniu monitu usługi LLM. Potok przetwarzania po zakończeniu może obejmować następujące kroki:
- sprawdzanie faktów: celem jest zidentyfikowanie konkretnych oświadczeń przedstawionych w artykule, które są przedstawione jako fakty, a następnie sprawdzenie tych faktów pod kątem dokładności. Jeśli krok sprawdzania faktów zakończy się niepowodzeniem, może być konieczne ponowne zapytanie LLM w nadziei na uzyskanie lepszej odpowiedzi lub zwrócenie użytkownikowi komunikatu o błędzie.
- Sprawdzanie zasad: ostatni wiersz obrony w celu zapewnienia, że odpowiedzi nie zawierają szkodliwej zawartości, zarówno dla użytkownika, jak i organizacji.
Ocena
Ocena wyników systemu niedeterministycznego nie jest tak prosta, jak uruchamianie testów jednostkowych lub testów integracji, które są znane większości deweloperów. Należy wziąć pod uwagę kilka czynników:
- Czy użytkownicy są zadowoleni z uzyskiwanych wyników?
- Czy użytkownicy otrzymują dokładne odpowiedzi na swoje pytania?
- Jak przechwytywać opinie użytkowników? Czy istnieją jakiekolwiek zasady, które ograniczają dane, które można zbierać na temat danych użytkowników?
- Czy w przypadku diagnozowania niezadowalających odpowiedzi masz wgląd w całą pracę, która została wykonana w celu odpowiedzi na pytanie? Czy prowadzisz rejestr każdego etapu w potoku inferencji danych wejściowych i wyjściowych, by móc przeprowadzić analizę przyczyn źródłowych?
- Jak można wprowadzać zmiany w systemie bez regresji lub pogorszenia wyników?
Przechwytywanie opinii użytkowników i podejmowanie działań na ich podstawie
Jak opisano wcześniej, może być konieczne współpracowanie z zespołem ds. prywatności organizacji w celu zaprojektowania mechanizmów przechwytywania informacji zwrotnych, telemetrii i rejestrowania na potrzeby analizy kryminalistycznej i analizy przyczyn źródłowych sesji zapytań.
Następnym krokiem jest opracowanie potoku oceny. Proces oceny pomaga w radzeniu sobie ze złożonością i czasochłonnością analizowania dokładnych informacji zwrotnych oraz przyczyn źródłowych odpowiedzi dostarczonych przez system sztucznej inteligencji. Ta analiza ma kluczowe znaczenie, ponieważ obejmuje badanie każdej odpowiedzi, aby zrozumieć, w jaki sposób zapytanie sztucznej inteligencji wygenerowało wyniki, sprawdzając odpowiedniość fragmentów zawartości używanych z dokumentacji oraz strategie stosowane podczas dzielenia tych dokumentów.
Obejmuje to również rozważenie dodatkowych kroków przetwarzania wstępnego lub po przetworzeniu, które mogą poprawić wyniki. To szczegółowe badanie często ujawnia luki w zawartości, szczególnie jeśli nie istnieje odpowiednia dokumentacja w odpowiedzi na zapytanie użytkownika.
Tworzenie procesu oceny staje się niezbędne do efektywnego zarządzania skalą tych zadań. Wydajny potok używa niestandardowych narzędzi do oceny metryk, które przybliżają jakość odpowiedzi generowanych przez sztuczną inteligencję. Ten system usprawnia proces określania, dlaczego dana odpowiedź została udzielona na pytanie użytkownika, które dokumenty zostały użyte do wygenerowania tej odpowiedzi oraz skuteczność potoku wnioskowania, który przetwarza zapytania.
Złoty zestaw danych
Jedną ze strategii oceny wyników nieokreślonego systemu, takiego jak system czatu RAG, jest użycie złotego zestawu danych. złoty zestaw danych to wyselekcjonowany zestaw pytań i zatwierdzonych odpowiedzi, metadanych (takich jak temat i typ pytania), odwołań do dokumentów źródłowych, które mogą służyć jako podstawowe informacje na temat odpowiedzi, a nawet odmian (różne frazy służące do przechwytywania różnorodności tego, jak użytkownicy mogą zadawać te same pytania).
Złoty zestaw danych reprezentuje "najlepszy scenariusz". Deweloperzy mogą ocenić system, aby sprawdzić, jak dobrze działa, a następnie przeprowadzać testy regresji podczas implementowania nowych funkcji lub aktualizacji.
Ocenianie szkody
Modelowanie szkód to metodologia mająca na celu przewidywanie potencjalnych szkód, wykrycie braków w produkcie, które może stanowić zagrożenie dla osób fizycznych i opracowanie proaktywnych strategii w celu ograniczenia takich zagrożeń.
Narzędzie przeznaczone do oceny wpływu technologii, szczególnie systemów sztucznej inteligencji, zawierałoby kilka kluczowych składników opartych na zasadach modelowania szkód, jak opisano w podanych zasobach.
Kluczowe funkcje narzędzia do oceny szkód mogą obejmować:
identyfikacja interesariuszy: Narzędzie może pomóc użytkownikom identyfikować i kategoryzować różne interesujące strony, których dotyczy technologia, w tym bezpośrednich użytkowników, strony pośrednio dotknięte, oraz inne podmioty, takie jak przyszłe pokolenia lub nieludzkie czynniki, na przykład kwestie środowiskowe.
kategorie i opisy szkód: Narzędzie może zawierać kompleksową listę potencjalnych szkód, takich jak utrata prywatności, cierpienie emocjonalne lub wykorzystywanie gospodarcze. Narzędzie może prowadzić użytkownika przez różne scenariusze, ilustrować, w jaki sposób technologia może spowodować te szkody, i pomóc ocenić zarówno zamierzone, jak i niezamierzone konsekwencje.
oceny poważności i prawdopodobieństwa: narzędzie może pomóc użytkownikom ocenić poważność i prawdopodobieństwo każdej zidentyfikowanej szkody. Użytkownik może określić priorytety problemów, aby najpierw rozwiązać problemy. Przykłady obejmują oceny jakościowe obsługiwane przez dane tam, gdzie są dostępne.
strategie ograniczania ryzyka: narzędzie może sugerować potencjalne strategie ograniczania ryzyka po zidentyfikowaniu i ocenie szkód. Przykłady obejmują zmiany w projekcie systemu, dodawanie zabezpieczeń i alternatywnych rozwiązań technologicznych, które minimalizują zidentyfikowane zagrożenia.
Mechanizmy opinii: narzędzie powinno zawierać mechanizmy zbierania opinii od uczestników projektu, tak aby proces oceny szkód był dynamiczny i reagował na nowe informacje i perspektywy.
dokumentacja i raportowanie: w celu zapewnienia przejrzystości i odpowiedzialności narzędzie może ułatwić szczegółowe raporty dokumentujące proces oceny szkód, wyniki i potencjalne podjęte działania zaradcze.
Te funkcje mogą pomóc w zidentyfikowaniu i ograniczeniu ryzyka, ale również ułatwiają projektowanie bardziej etycznych i odpowiedzialnych systemów sztucznej inteligencji, biorąc pod uwagę szerokie spektrum wpływu od samego początku.
Aby uzyskać więcej informacji, zobacz następujące artykuły:
Testowanie i weryfikowanie zabezpieczeń
W tym artykule opisano kilka procesów mających na celu ograniczenie możliwości wykorzystania lub naruszenia zabezpieczeń systemu czatów opartych na systemie RAG. Red Teaming odgrywa kluczową rolę w zapewnieniu skuteczności środków zaradczych. Red-teaming obejmuje symulowanie działań potencjalnego przeciwnika w celu wykrycia potencjalnych słabości lub luk w zabezpieczeniach w aplikacji. Takie podejście jest szczególnie istotne w rozwiązywaniu znacznego ryzyka złamania więzienia.
Deweloperzy muszą rygorystycznie ocenić zabezpieczenia systemu czatów opartych na programie RAG w różnych scenariuszach wytycznych, aby skutecznie je przetestować i zweryfikować. Takie podejście nie tylko zapewnia niezawodność, ale także pomaga dostosować odpowiedzi systemu w celu ścisłego przestrzegania zdefiniowanych standardów etycznych i procedur operacyjnych.
Końcowe zagadnienia dotyczące projektowania aplikacji
Poniżej przedstawiono krótką listę kwestii, które należy wziąć pod uwagę i inne wnioski z tego artykułu, które mogą mieć wpływ na decyzje projektowe aplikacji:
- Uznaj niedeterministyczny charakter generatywnej sztucznej inteligencji w swoim projekcie. Planowanie zmienności w danych wyjściowych i konfigurowanie mechanizmów w celu zapewnienia spójności i istotności w odpowiedziach.
- Oceń korzyści wynikające ze wstępnego przetwarzania monitów użytkownika o potencjalny wzrost opóźnienia i kosztów. Uproszczenie lub modyfikowanie monitów przed przesłaniem może poprawić jakość odpowiedzi, ale może zwiększyć złożoność i czas do cyklu odpowiedzi.
- Aby zwiększyć wydajność, zbadaj strategie równoległego przetwarzania żądań LLM. Takie podejście może zmniejszyć opóźnienie, ale wymaga starannego zarządzania, aby uniknąć zwiększonej złożoności i potencjalnych konsekwencji kosztów.
Jeśli chcesz od razu rozpocząć eksperymentowanie z tworzeniem generującego rozwiązania sztucznej inteligencji, zalecamy zapoznanie się z Rozpoczynanie pracy z czatem przy użyciu własnego przykładu danych dla języka Python. Samouczek jest również dostępny dla .NET, Javai JavaScript.