Reguły typów danych SQL
Dotyczy:![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Usługa Azure Databricks używa kilku reguł do rozwiązywania konfliktów między typami danych:
- Promocja bezpiecznie rozszerza typ do szerszego typu.
- Niejawna konwersja w dół zawęża typ. Przeciwieństwo promocji.
- Niejawne typowanie krzyżowe przekształca typ w typ innej rodziny typów.
Można również eksplicytnie rzutować między wieloma typami.
- Funkcja rzutowania wykonuje rzutowanie między większością typów i zwraca błędy, jeśli nie może.
- funkcja try_cast działa jak funkcja rzutu , ale zwraca wartość NULL, gdy zostaną przekazane nieprawidłowe wartości.
- Inne wbudowane funkcje rzutowane między typami przy użyciu udostępnionych dyrektyw formatu.
Podwyższanie typu
Podwyższanie typu to proces rzutowania typu na inny typ z tej samej rodziny typów, który zawiera wszystkie możliwe wartości oryginalnego typu.
W związku z tym podwyższenie poziomu typu jest bezpieczną operacją. Na przykład TINYINT ma zakres od -128 do 127. Wszystkie możliwe wartości można bezpiecznie podnieść do INTEGER.
Lista pierwszeństwa typów
Lista pierwszeństwa typu określa, czy wartości danego typu danych mogą być niejawnie promowane do innego typu danych.
| Typ danych | Lista pierwszeństwa (od najwęższej do najszerszej) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT - INT ->> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT - BIGINT ->> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT — DECIMAL —>> FLOAT (1) —> DOUBLE |
| DZIESIĘTNY | DZIESIĘTNE —> ZMIENNOPRZECINKOWE (1) —> PODWÓJNE |
| SPŁAWIK | ZMIENNOPRZECINKOWY (1) —> PODWÓJNY |
| PODWÓJNY | PODWÓJNY |
| DATA | DATA —> SYGNATURA CZASOWA |
| TIMESTAMP | TIMESTAMP |
| TABLICA | TABLICA (2) |
| DWÓJKOWY | DWÓJKOWY |
| BOOLEAN | BOOLEAN |
| INTERWAŁ | INTERWAŁ |
| MAPA | MAP (2) |
| STRING | STRUNA |
| STRUCT | STRUKTURA (2) |
| WARIANT | WARIANT |
| OBIEKT | OBJECT (3) |
(1) W przypadku najmniejszej typowej rozdzielczościFLOAT typu pomija się, aby uniknąć utraty precyzji.
(2) W przypadku typu złożonego reguła pierwszeństwa jest cyklicznie stosowana do jej elementów składników.
(3)OBJECT istnieje tylko w obrębie obiektu VARIANT.
Ciągi i NULL
Zasady specjalne mają zastosowanie do STRING i nieokreślone NULL:
-
NULLmożna przekonwertować na dowolny inny typ. -
STRINGmożna awansować doBIGINT, ,BINARYBOOLEANDATEDOUBLE,INTERVAL, i .TIMESTAMPJeśli nie można rzutować rzeczywistej wartości ciągu na najmniej typowy typ usługi Azure Databricks, zgłasza błąd środowiska uruchomieniowego. Podczas awansowania doINTERVALwartość ciągu musi być zgodna z jednostkami miar interwałów.
Wykres pierwszeństwa typu
Jest to graficzne przedstawienie hierarchii pierwszeństwa, łączące listę pierwszeństwa typu z ciągami oraz regułami dotyczącymi NULLs.
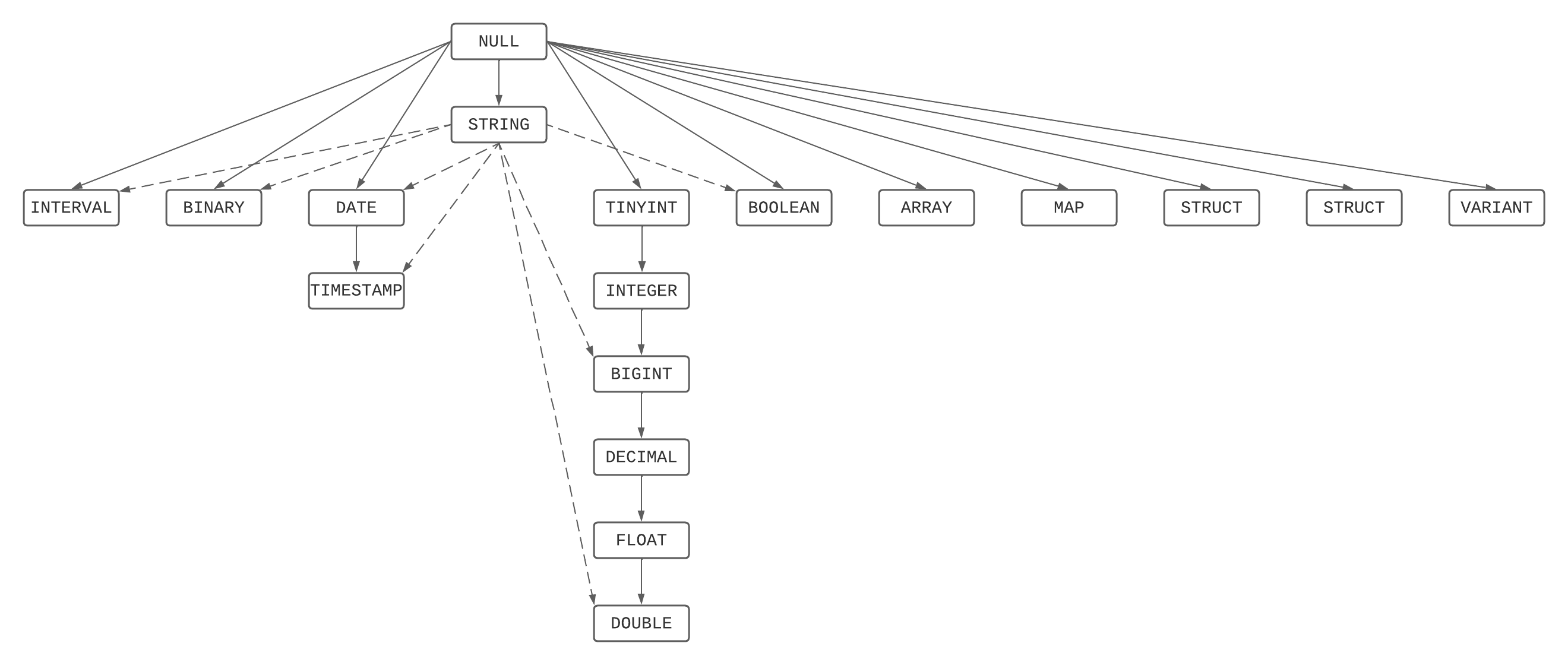
Rozwiązywanie najmniej powszechnego typu
Najmniej typowym typem z zestawu typów jest najwęższy typ osiągalny z wykresu pierwszeństwa typu przez wszystkie elementy zestawu typów.
Najmniej typowe rozpoznawanie typów jest używane do:
- Zdecyduj, czy funkcja, która oczekuje parametru danego typu, może być wywoływana przy użyciu argumentu węższego typu.
- Utwórz typ argumentu dla funkcji, która oczekuje wspólnego typu argumentu dla wielu parametrów, takich jak koalescencja, w, najmniejlub najwięcej.
- Wyprowadź typy operandów dla operatorów, takich jak operacje arytmetyczne lub porównania.
- Wyprowadź typ wyniku dla wyrażeń, takich jak wyrażenie case.
- Wyodrębnij typy elementów, kluczy lub wartości dla konstruktorów tablic i map .
- Określ typ wyniku operatorów zestawu UNION, INTERSECT lub EXCEPT.
Reguły specjalne są stosowane, jeśli najmniej typowy typ jest rozpoznawany jako FLOAT. Jeśli którykolwiek z typów współtworzących jest dokładnym typem liczbowym (TINYINT, SMALLINT, INTEGER, BIGINT lub DECIMAL), najmniejszy wspólny typ jest przenoszony do DOUBLE, aby uniknąć potencjalnej utraty cyfr.
Gdy najmniej typowy typ to STRING sortowanie jest obliczane zgodnie z regułami pierwszeństwa sortowania .
Niejawna konwersja w dół i rzutowanie krzyżowe
Usługa Azure Databricks wykorzystuje te formy niejawnego rzutowania tylko w przypadku wywołania funkcji i operatora oraz tylko wtedy, gdy może jednoznacznie określić intencję.
Niejawne rzutowanie w dół
Niejawne rzutowanie w dół automatycznie przekształca szerszy typ na węższy, bez konieczności jawnego określania rzutowania. Obniżanie jest wygodne, ale wiąże się z ryzykiem nieoczekiwanych błędów środowiska uruchomieniowego, jeśli rzeczywista wartość nie może być reprezentowana w wąskim typie.
Downcasting stosuje listę pierwszeństwa typu w odwrotnej kolejności.
Niejawne przesłanie krzyżowe
Niejawne rzutowanie krzyżowe rzutuje wartość z jednej rodziny typów na inną bez konieczności jawnego określenia rzutowania.
Usługa Azure Databricks obsługuje niejawne crosscasting z:
- Dowolny prosty typ, z wyjątkiem
BINARY, doSTRING. - Od
STRINGdowolnego prostego typu.
- Dowolny prosty typ, z wyjątkiem
Rzutowanie przy wywołaniu funkcji
Biorąc pod uwagę rozpoznaną funkcję lub operator, obowiązują następujące reguły w kolejności, w której są wymienione, dla każdego parametru i pary argumentów:
Jeśli obsługiwany typ parametru jest częścią grafu pierwszeństwa typu argumentu, usługa Azure Databricks promuje argument tego typu parametru.
W większości przypadków opis funkcji jawnie określa obsługiwane typy lub łańcuch, takie jak "dowolny typ liczbowy".
Na przykład sin(expr) działa na
DOUBLE, ale zaakceptuje dowolną wartość liczbową.Jeśli oczekiwany typ parametru to
STRING, a argument jest prostym typem, usługa Azure Databricks konwertuje argument na typ parametru ciągu znaków.Na przykład parametr substr(str, start, len) oczekuje
strwartości .STRINGZamiast tego można przekazać typ liczbowy lub daty-czasu.Jeśli typ argumentu to
STRING, a oczekiwany typ parametru jest prostym typem, usługa Azure Databricks przesłania argument ciągu do najszerszego obsługiwanego typu parametru.Na przykład date_add (data, dni) oczekuje
DATEiINTEGER.W przypadku wywołania
date_add()wraz z dwomaSTRINGs usługa Azure Databricks wykonuje przekształcenia krzyżowe pierwszegoSTRINGnaDATEi drugiegoSTRINGnaINTEGER.Jeśli funkcja oczekuje typu liczbowego, takiego jak typ
INTEGERlubDATE, ale argument jest bardziej ogólnym typem, takim jakDOUBLElubTIMESTAMP, usługa Azure Databricks niejawnie przekształca argument do tego typu parametru.Na przykład date_add(data, dni) wymaga parametru
DATEiINTEGER.Jeśli wywołasz
date_add()z elementemTIMESTAMPiBIGINT, usługa Azure Databricks przekształciTIMESTAMPnaDATEpoprzez usunięcie składnika czasu, a elementBIGINTnaINTEGER.W przeciwnym razie usługa Azure Databricks zgłasza błąd.
Przykłady
Funkcja coalesce akceptuje dowolny zestaw typów argumentów, o ile mają one najmniejszy wspólny typ.
Typ wyniku jest najmniej typowym typem argumentów.
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, ‘world’))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce(‘hello’ COLLATE UTF8_BINARY, ‘world’ COLLATE UNICODE), ‘world’));
UTF8_BINARY
Funkcja podciągu oczekuje argumentów typu STRING dla ciągu i INTEGER dla parametrów początku i długości.
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
|| (CONCAT) umożliwia niejawne rzutowanie na ciąg znaków.
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add można wywołać za pomocą TIMESTAMP lub BIGINT z powodu niejawnego "downcastingu".
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add można wywołać z STRING-ami z powodu niejawnego rzutowania typów.
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05