Techniki ciągłej integracji/ciągłego wdrażania z folderami Git i Databricks Git (Repos)
Poznaj techniki używania folderów Git usługi Databricks w przepływach pracy ciągłej integracji/ciągłego wdrażania. Konfigurując foldery Git usługi Databricks w obszarze roboczym, możesz użyć kontroli źródła dla plików projektu w repozytoriach Git i zintegrować je z potokami inżynierii danych.
Na poniższej ilustracji przedstawiono przegląd technik i przepływu pracy.
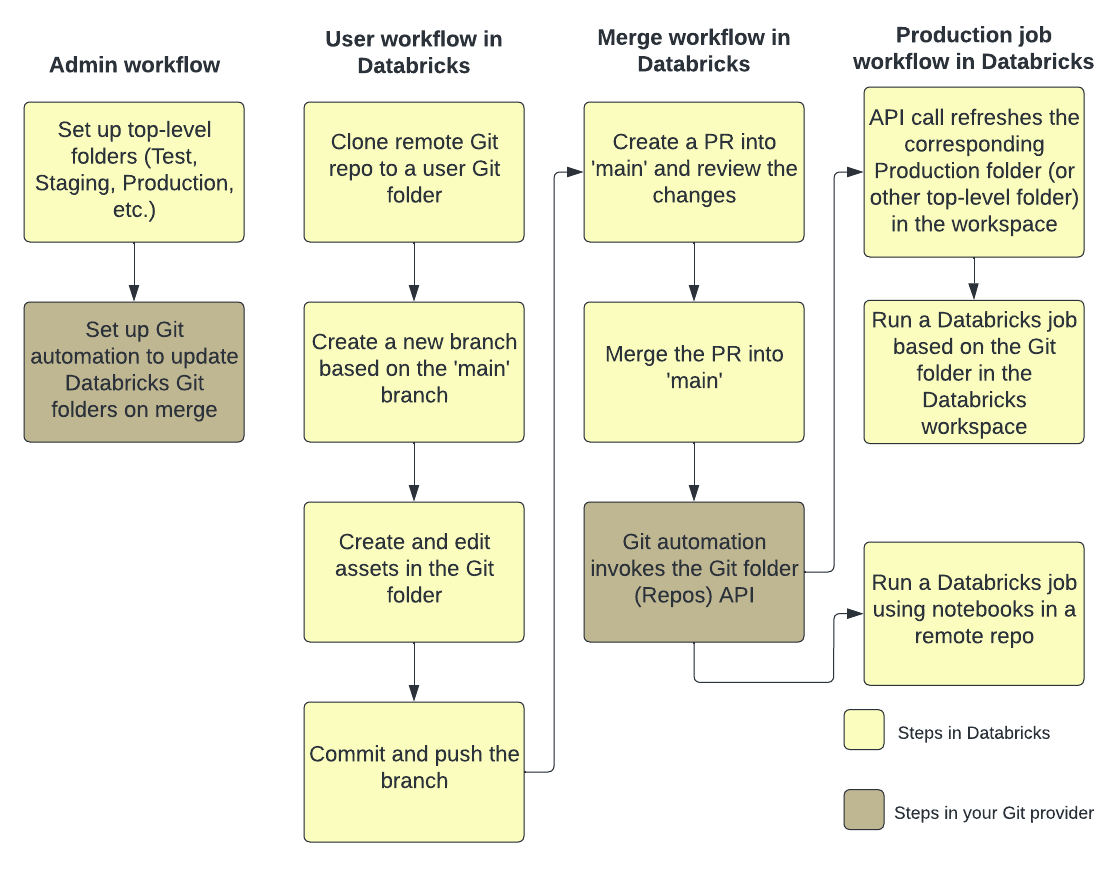
Aby zapoznać się z omówieniem ciągłej integracji/ciągłego wdrażania w usłudze Azure Databricks, zobacz Co to jest ciągła integracja/ciągłe wdrażanie w usłudze Azure Databricks?.
Przepływ programowania
Foldery usługi Git usługi Databricks mają foldery na poziomie użytkownika. Foldery na poziomie użytkownika są tworzone automatycznie, gdy użytkownicy najpierw klonują repozytorium zdalne. Foldery Git w Databricks można traktować jako "lokalne kopie robocze", indywidualne dla każdego użytkownika, w których użytkownicy wprowadzają zmiany w swoich kodach.
W folderze użytkownika w folderach Git usługi Databricks sklonuj repozytorium zdalne. Najlepszym rozwiązaniem jest utworzenie nowej gałęzi funkcjonalności lub wybranie wcześniej utworzonej gałęzi do pracy zamiast bezpośredniego zatwierdzania i wypychania zmian do gałęzi głównej. Możesz wprowadzać zmiany, zatwierdzać i wypychać zmiany w tej gałęzi. Gdy wszystko będzie gotowe do scalenia kodu, możesz to zrobić w interfejsie użytkownika folderów Git.
Wymagania
Ten przepływ pracy wymaga, abyś wcześniej skonfigurował integrację z usługą Git.
Uwaga
Usługa Databricks zaleca, aby każdy deweloper działał we własnej gałęzi funkcji. Aby uzyskać informacje na temat rozwiązywania konfliktów scalania, zobacz Rozwiązywanie konfliktów scalania.
Współpraca w folderach Git
Poniższy przepływ pracy używa gałęzi o nazwie feature-b , która jest oparta na gałęzi głównej.
- Sklonuj istniejące repozytorium Git do obszaru roboczego usługi Databricks.
- Użyj interfejsu użytkownika folderów Git, aby utworzyć gałąź funkcji z gałęzi głównej. W tym przykładzie użyto jednej gałęzi
feature-bfunkcji dla uproszczenia. Aby wykonać swoją pracę, możesz utworzyć i użyć wielu gałęzi funkcji. - Wprowadź modyfikacje notesów usługi Azure Databricks i innych plików w repozytorium.
- Zatwierdź i wypchnij zmiany do dostawcy usługi Git.
- Współautorzy mogą teraz sklonować repozytorium Git do własnego folderu użytkownika.
- Pracując nad nową gałęzią, współpracownik wprowadza zmiany w notesach i innych plikach w folderze Git.
- Współautor zatwierdza i wypycha zmiany do dostawcy usługi Git.
- Aby scalić zmiany z innych gałęzi lub zmienić bazę gałęzi feature-b w usłudze Databricks, w interfejsie użytkownika folderów Git użyj jednego z następujących przepływów pracy:
-
Scal gałęzie. Jeśli nie występuje konflikt, scalanie jest wypychane do zdalnego repozytorium Git przy użyciu polecenia
git push. - Zmień bazę na inną gałąź.
-
Scal gałęzie. Jeśli nie występuje konflikt, scalanie jest wypychane do zdalnego repozytorium Git przy użyciu polecenia
- Gdy wszystko będzie gotowe do scalenia pracy ze zdalnym repozytorium Git i
maingałęzią, użyj interfejsu użytkownika folderów Git, aby scalić zmiany z funkcji b. Jeśli wolisz, możesz zamiast tego scalić zmiany bezpośrednio z repozytorium Git z kopią zapasową folderu Git.
Przepływ pracy zadania produkcyjnego
Foldery Git usługi Databricks udostępniają dwie opcje uruchamiania zadań produkcyjnych:
-
Opcja 1. Podaj zdalne odwołanie do usługi Git w definicji zadania. Na przykład uruchom konkretny notes w
maingałęzi repozytorium Git. - opcja 2: skonfiguruj produkcyjne repozytorium Git i wywołaj interfejsy API Repozytoria, aby zaktualizować je programowo. Uruchom zadania względem folderu Git usługi Databricks, który klonuje to repozytorium zdalne. Wywołanie interfejsu API repozytoriów powinno być pierwszym zadaniem w zadaniu.
Opcja 1. Uruchamianie zadań przy użyciu notesów w repozytorium zdalnym
Uprość proces definicji zadania i zachowaj pojedyncze źródło prawdy, uruchamiając zadanie usługi Azure Databricks przy użyciu notesów znajdujących się w zdalnym repozytorium Git. To odwołanie usługi Git może być zatwierdzeniem, tagiem lub gałęzią usługi Git i jest udostępniane przez Ciebie w definicji zadania.
Pomaga to zapobiec niezamierzonym zmianom w zadaniu produkcyjnym, na przykład wtedy, gdy użytkownik wprowadza zmiany lokalne w repozytorium produkcyjnym lub przełącza gałęzie. Automatyzuje również krok ciągłego wdrażania, ponieważ nie trzeba tworzyć oddzielnego produkcyjnego folderu Git w usłudze Databricks, zarządzać uprawnieniami i aktualizować go.
Zobacz Używanie usługi Git z zadaniami.
opcja 2: konfigurowanie produkcyjnego folderu Git i automatyzacji usługi Git
W tej opcji skonfigurujesz produkcyjny folder Git i automatyzację w celu zaktualizowania folderu Git podczas scalania.
Krok 1. Konfigurowanie folderów najwyższego poziomu
Administrator tworzy foldery najwyższego poziomu innego niż użytkownik. Najczęstszym przypadkiem użycia tych folderów najwyższego poziomu jest utworzenie folderów programistycznych, przejściowych i produkcyjnych zawierających foldery Usługi Git usługi Databricks dla odpowiednich wersji lub gałęzi na potrzeby programowania, przemieszczania i produkcji. Jeśli na przykład firma korzysta z gałęzi produkcyjnej main , folder "production" Git musi mieć main wyewidencjonowany gałąź.
Zazwyczaj uprawnienia do tych folderów najwyższego poziomu są tylko do odczytu dla wszystkich użytkowników niebędących administratorami w obszarze roboczym. W przypadku takich folderów najwyższego poziomu zalecamy dostarczanie tylko jednostek usługi z uprawnieniami CAN EDIT i CAN MANAGE, aby uniknąć przypadkowej edycji kodu produkcyjnego przez użytkowników obszaru roboczego.
Krok 2. Konfigurowanie automatycznych aktualizacji folderów Git usługi Databricks przy użyciu interfejsu API folderów Git
Aby zachować folder Git w usłudze Databricks w najnowszej wersji, możesz skonfigurować automatyzację Git, aby wywołać API Repos. W dostawcy usługi Git skonfiguruj automatyzację, która po każdym pomyślnym scaleniu żądania ściągnięcia z gałęzią główną wywołuje punkt końcowy interfejsu API repozytoriów w odpowiednim folderze Git, aby zaktualizować go do najnowszej wersji.
Na przykład w usłudze GitHub można to osiągnąć za pomocą funkcji GitHub Actions. Aby uzyskać więcej informacji, zobacz interfejs API repozytoriów.
Użyj głównej jednostki usługi do automatyzacji z folderami Git na platformie Databricks
Możesz użyć konsoli konta usługi Azure Databricks lub interfejsu wiersza polecenia usługi Databricks, aby utworzyć jednostkę usługi autoryzowaną do uzyskiwania dostępu do folderów Git obszaru roboczego.
Aby utworzyć nową jednostkę usługi, zobacz Zarządzanie jednostkami usługi. Jeśli masz jednostkę usługi w swoim obszarze roboczym, możesz połączyć z nią Twoje poświadczenia Git, aby uzyskać dostęp do folderów Git obszaru roboczego w ramach automatyzacji.
Autoryzowanie jednostki usługi do uzyskiwania dostępu do folderów Git
Aby zapewnić autoryzowany dostęp do folderów Git dla jednostki usługi przy użyciu konsoli konta usługi Azure Databricks:
Zaloguj się do obszaru roboczego usługi Azure Databricks. Aby wykonać te kroki, musisz mieć uprawnienia administratora do obszaru roboczego. Jeśli nie masz uprawnień administratora dla obszaru roboczego, poproś o nie lub skontaktuj się z administratorem konta.
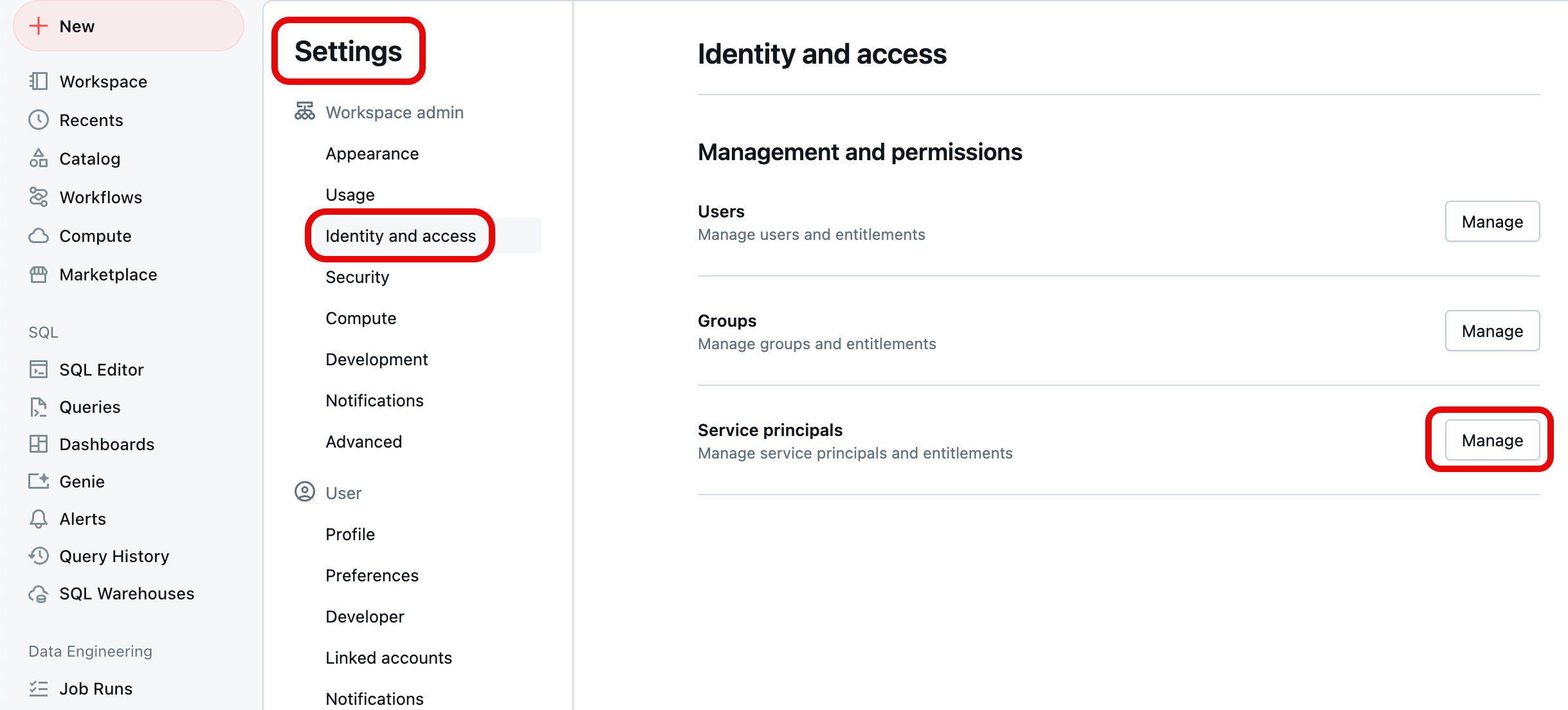
W prawym górnym rogu dowolnej strony kliknij swoją nazwę użytkownika, a następnie wybierz pozycję Ustawienia.
Wybierz Identity and access w obszarze Workspace admin w lewym panelu nawigacyjnym, a następnie wybierz przycisk Zarządzaj dla Service Principals.
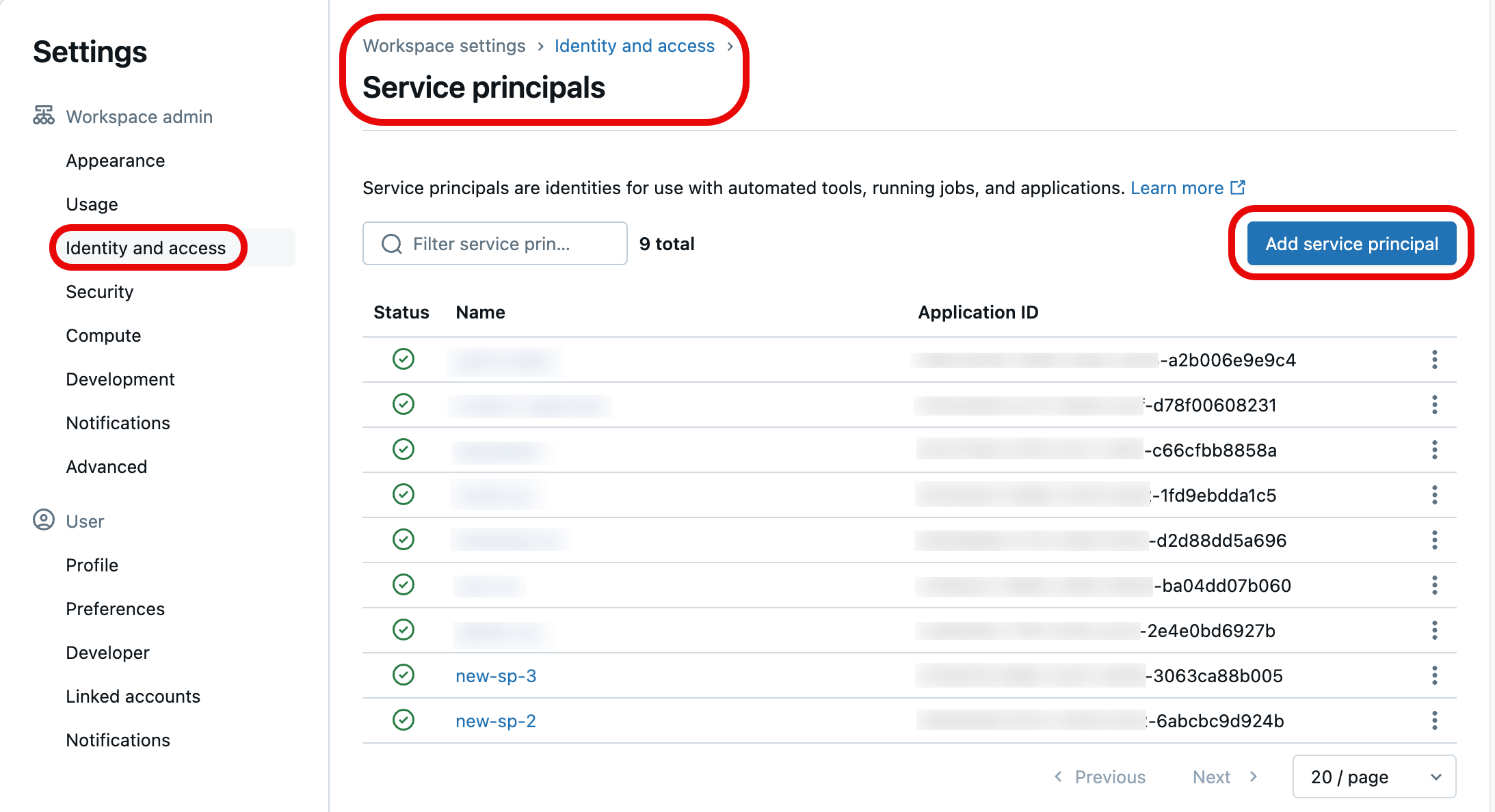
Z listy jednostek usługi wybierz tę, którą chcesz zaktualizować przy użyciu poświadczeń Git. Możesz również utworzyć nową jednostkę usługi, wybierając pozycję Dodaj jednostkę usługi.
Wybierz kartę integracji z usługą Git. (Jeśli nie utworzono jednostki usługi lub nie przypisano do niej uprawnień menedżera jednostki usługi, będzie wyszarzona). Pod nią wybierz dostawcę usługi Git dla poświadczeń (takiego jak GitHub), wybierz Połącz konto Git, a następnie Link.
Możesz również użyć osobistego tokenu dostępu usługi Git, jeśli nie chcesz łączyć własnych poświadczeń usługi Git. Aby użyć zamiast tego tokenu PAT, wybierz Osobisty token dostępu i podaj informacje o tokenie dla konta Git, które będzie używane podczas uwierzytelniania dostępu jednostki usługi. Aby uzyskać więcej informacji na temat uzyskiwania osobistego tokena dostępu (PAT) od dostawcy usługi Git, zobacz Konfigurowanie poświadczeń Git & łączenie zdalnego repozytorium z Azure Databricks.
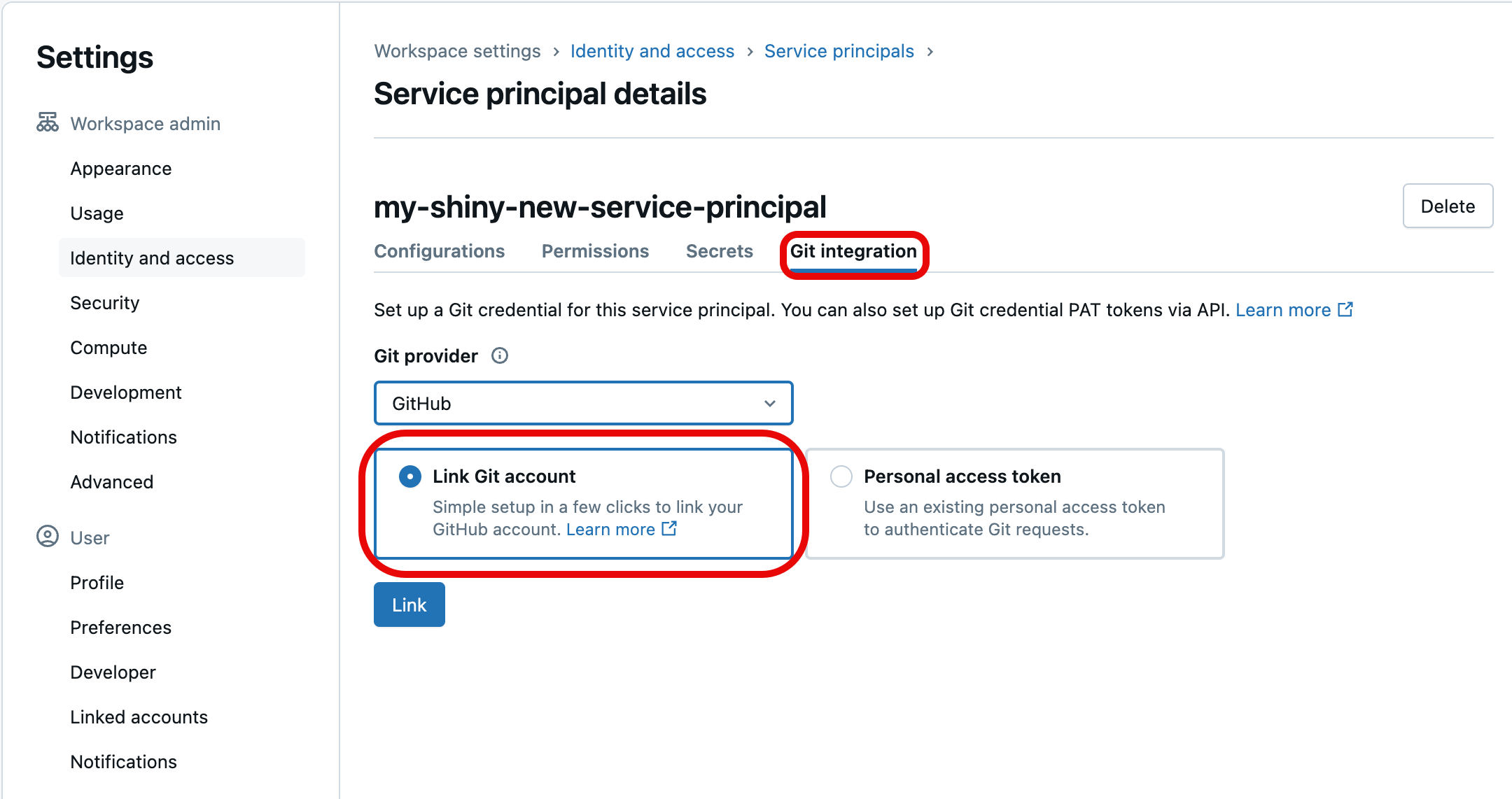
Zostanie wyświetlony monit o wybranie konta użytkownika usługi Git w celu połączenia. Wybierz konto użytkownika Git, które jednostka usługi będzie używać w celu uzyskania dostępu, a następnie wybierz Kontynuuj. (Jeśli nie widzisz konta użytkownika, którego chcesz użyć, wybierz pozycję Użyj innego konta).
W następnym oknie dialogowym wybierz pozycję Autoryzuj usługę Databricks. Zostanie wyświetlony komunikat "Łączenie konta..." a następnie zaktualizowane dane jednostki usługi.
ekran potwierdzenia
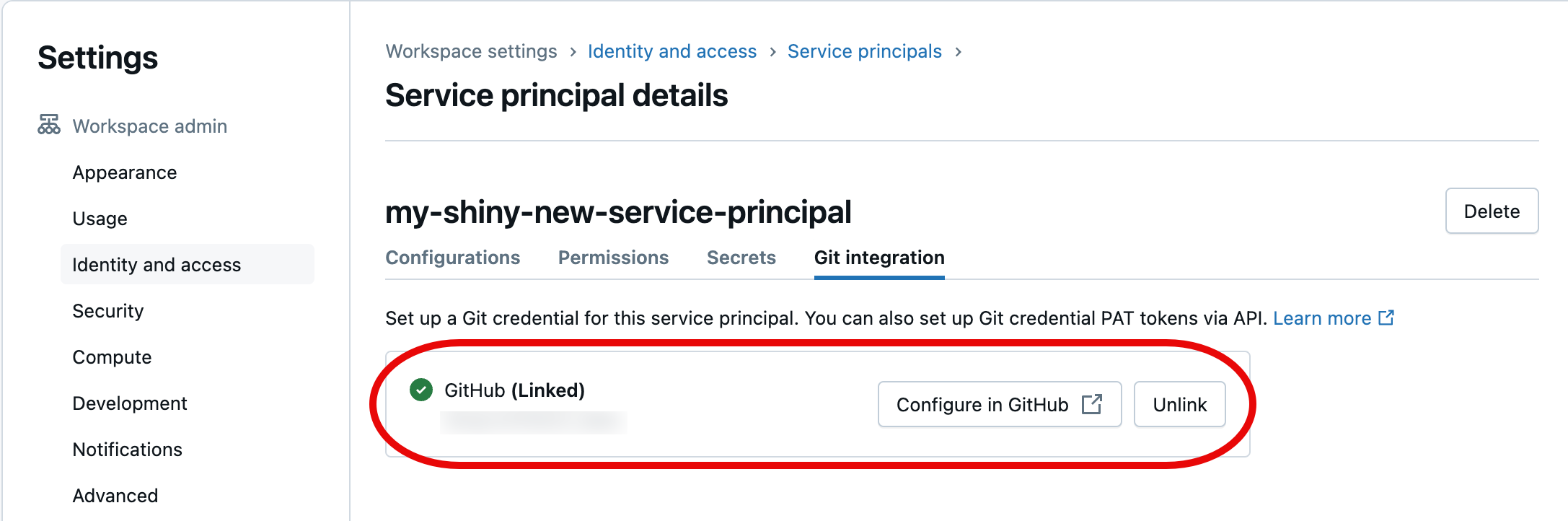
Wybrany pryncypał usługi będzie teraz stosować połączone poświadczenia Git podczas uzyskiwania dostępu do zasobów folderów Git obszaru roboczego Azure Databricks w ramach Twojej automatyzacji.
Integracja z programem Terraform
Foldery Git usługi Databricks można również zarządzać w pełni zautomatyzowanym instalatorem przy użyciu narzędzia Terraform i databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Aby przy użyciu narzędzia Terraform dodać poświadczenia Git do jednostki usługi, wprowadź następującą konfigurację:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Konfigurowanie zautomatyzowanego potoku ciągłej integracji/ciągłego wdrażania za pomocą folderów Git usługi Databricks
Oto prosta automatyzacja, którą można uruchomić jako akcję usługi GitHub.
Wymagania
- Folder Git został utworzony w obszarze roboczym usługi Databricks śledzącym scalanie gałęzi podstawowej.
- Masz pakiet języka Python, który tworzy artefakty do umieszczenia w lokalizacji systemu plików DBFS. Kod musi:
- Zaktualizuj repozytorium powiązane z preferowaną gałęzią (na przykład
development), aby zawierało najnowsze wersje notatników. - Skompiluj wszystkie artefakty i skopiuj je do ścieżki biblioteki.
- Zastąp ostatnie wersje artefaktów kompilacji, aby uniknąć konieczności ręcznego aktualizowania wersji artefaktów w zadaniu.
- Zaktualizuj repozytorium powiązane z preferowaną gałęzią (na przykład
Tworzenie zautomatyzowanego przepływu pracy ciągłej integracji/ciągłego wdrażania
Skonfiguruj tajemnice, aby twój kod mógł uzyskać dostęp do obszaru roboczego Databricks. Dodaj następujące wpisy tajne do repozytorium Github:
-
DEPLOYMENT_TARGET_URL: Ustaw to jako adres URL swojego obszaru roboczego. Nie dołączaj podciągów
/?o. - DEPLOYMENT_TARGET_TOKEN: ustaw tę opcję na osobisty token dostępu (PAT) usługi Databricks. Można wygenerować osobisty token dostępu (PAT) usługi Databricks, postępując zgodnie z instrukcjami w uwierzytelnianie za pomocą osobistego tokenu dostępu (PAT) w usłudze Azure Databricks.
-
DEPLOYMENT_TARGET_URL: Ustaw to jako adres URL swojego obszaru roboczego. Nie dołączaj podciągów
Przejdź do karty Akcje repozytorium Git i kliknij przycisk Nowy przepływ pracy . W górnej części strony wybierz pozycję Skonfiguruj przepływ pracy samodzielnie i wklej następujący skrypt:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itZaaktualizuj poniższe wartości zmiennych środowiskowych na własne:
-
DBFS_LIB_PATH: ścieżka w systemie plików DBFS do bibliotek (kół) używanych w tej automatyzacji, która zaczyna się od
dbfs:. Na przykładdbfs:/mnt/myproject/libraries. - REPO_PATH: ścieżka w obszarze roboczym usługi Databricks do teczki Git, w której notesy będą aktualizowane.
-
LATEST_WHEEL_NAME: nazwa ostatniego skompilowanego pliku koła języka Python (
.whl). Służy to do unikania ręcznego aktualizowania wersji koła w zadaniach usługi Databricks. Na przykładyour_wheel-latest-py3-none-any.whl.
-
DBFS_LIB_PATH: ścieżka w systemie plików DBFS do bibliotek (kół) używanych w tej automatyzacji, która zaczyna się od
Wybierz pozycję Skommituj zmiany..., aby skommitować skrypt jako workflow GitHub Actions. Po scaleniu żądania ściągnięcia dla tego przepływu pracy przejdź do karty Akcje repozytorium Git i upewnij się, że akcje zakończyły się pomyślnie.