Przepływy pracy metodyki MLOps w usłudze Azure Databricks
W tym artykule opisano sposób używania metodyki MLOps na platformie Databricks w celu zoptymalizowania wydajności i długoterminowej wydajności systemów uczenia maszynowego. Zawiera on ogólne zalecenia dotyczące architektury MLOps i opisuje uogólniony przepływ pracy przy użyciu platformy Databricks, której można użyć jako modelu dla procesu programowania i produkcji uczenia maszynowego. Aby uzyskać informacje o modyfikacjach tego przepływu pracy dla aplikacji LLMOps, zobacz przepływy pracy LLMOps.
Aby uzyskać więcej informacji, zobacz The Big Book of MLOps (Książka big book of MLOps).
Co to jest MLOps?
Metodyka MLOps to zestaw procesów i zautomatyzowanych kroków do zarządzania kodem, danymi i modelami w celu poprawy wydajności, stabilności i długoterminowej wydajności systemów uczenia maszynowego. Łączy metodyki DevOps, DataOps i ModelOps.
Zasoby uczenia maszynowego, takie jak kod, dane i modele, są opracowywane na etapach, które przechodzą od wczesnych etapów programowania, które nie mają ścisłych ograniczeń dostępu i nie są rygorystycznie testowane przez etap testowania pośredniego do końcowego etapu produkcyjnego, który jest ściśle kontrolowany. Platforma Databricks umożliwia zarządzanie tymi zasobami na jednej platformie przy użyciu ujednoliconej kontroli dostępu. Aplikacje danych i aplikacje uczenia maszynowego można tworzyć na tej samej platformie, co zmniejsza ryzyko i opóźnienia związane z przenoszeniem danych.
Ogólne zalecenia dotyczące metodyki MLOps
Ta sekcja zawiera kilka ogólnych zaleceń dotyczących metodyki MLOps w usłudze Databricks z linkami, aby uzyskać więcej informacji.
Tworzenie oddzielnego środowiska dla każdego etapu
Środowisko wykonywania to miejsce, w którym modele i dane są tworzone lub używane przez kod. Każde środowisko wykonywania składa się z wystąpień obliczeniowych, ich środowisk uruchomieniowych i bibliotek oraz zautomatyzowanych zadań.
Usługa Databricks zaleca tworzenie oddzielnych środowisk dla różnych etapów programowania kodu uczenia maszynowego i modelu z jasno zdefiniowanymi przejściami między etapami. Przepływ pracy opisany w tym artykule jest zgodny z tym procesem, używając nazw pospolitych etapów:
Inne konfiguracje mogą być również używane do spełnienia określonych potrzeb organizacji.
Kontrola dostępu i przechowywanie wersji
Kontrola dostępu i przechowywanie wersji są kluczowymi składnikami dowolnego procesu operacji oprogramowania. Usługa Databricks zaleca następujące kwestie:
- Użyj narzędzia Git do kontroli wersji. Potoki i kod powinny być przechowywane w usłudze Git na potrzeby kontroli wersji. Przeniesienie logiki uczenia maszynowego między etapami może być następnie interpretowane jako przenoszenie kodu z gałęzi programowania do gałęzi przejściowej do gałęzi wydania. Użyj Git folderów Databricks, aby zintegrować się z dostawcą Git i synchronizować notesy oraz kod źródłowy z obszarami roboczymi Databricks. Usługa Databricks udostępnia również dodatkowe narzędzia do integracji z usługą Git i kontroli wersji; zobacz Lokalne narzędzia programistyczne.
- Przechowywanie danych w architekturze lakehouse przy użyciu tabel delty. Dane powinny być przechowywane w architekturze lakehouse na koncie chmury. Zarówno nieprzetworzone dane, jak i tabele funkcji powinny być przechowywane jako tabele delty z kontrolą dostępu w celu określenia, kto może je odczytywać i modyfikować.
- Zarządzanie programowaniem modeli za pomocą platformy MLflow. Możesz użyć MLflow do śledzenia procesu tworzenia modelu i zapisywania migawek kodu, parametrów modelu, metryk i innych metadanych.
- Użyj modeli w Unity Catalog do zarządzania cyklem życia modelu. Użyj modeli w Unity Catalog do zarządzania wersjonowaniem modeli, ich ładem i stanem wdrożenia.
Wdrażanie kodu, a nie modeli
W większości sytuacji usługa Databricks zaleca, aby podczas procesu opracowywania uczenia maszynowego promować kod, a nie modele, z jednego środowiska do drugiego. Przeniesienie zasobów projektu w ten sposób gwarantuje, że cały kod w procesie programowania uczenia maszynowego przechodzi przez te same procesy przeglądu kodu i testowania integracji. Gwarantuje również, że wersja produkcyjna modelu zostanie wytrenowana na podstawie kodu produkcyjnego. Aby zapoznać się z bardziej szczegółowym omówieniem opcji i kompromisów, zobacz Wzorce wdrażania modelu.
Zalecany przepływ pracy metodyki MLOps
W poniższych sekcjach opisano typowy przepływ pracy metodyki MLOps obejmujący każdy z trzech etapów: programowanie, przemieszczanie i produkcja.
W tej sekcji użyto terminów "analityk danych" i "Inżynier uczenia maszynowego" jako archetypalnych personas; określone role i obowiązki w przepływie pracy metodyki MLOps będą się różnić w zależności od zespołów i organizacji.
Etap programowania
Celem etapu programowania jest eksperymentowanie. Analitycy danych opracowują funkcje i modele i uruchamiają eksperymenty w celu zoptymalizowania wydajności modelu. Dane wyjściowe procesu programowania to kod potoku uczenia maszynowego, który może obejmować obliczenia funkcji, trenowanie modelu, wnioskowanie i monitorowanie.
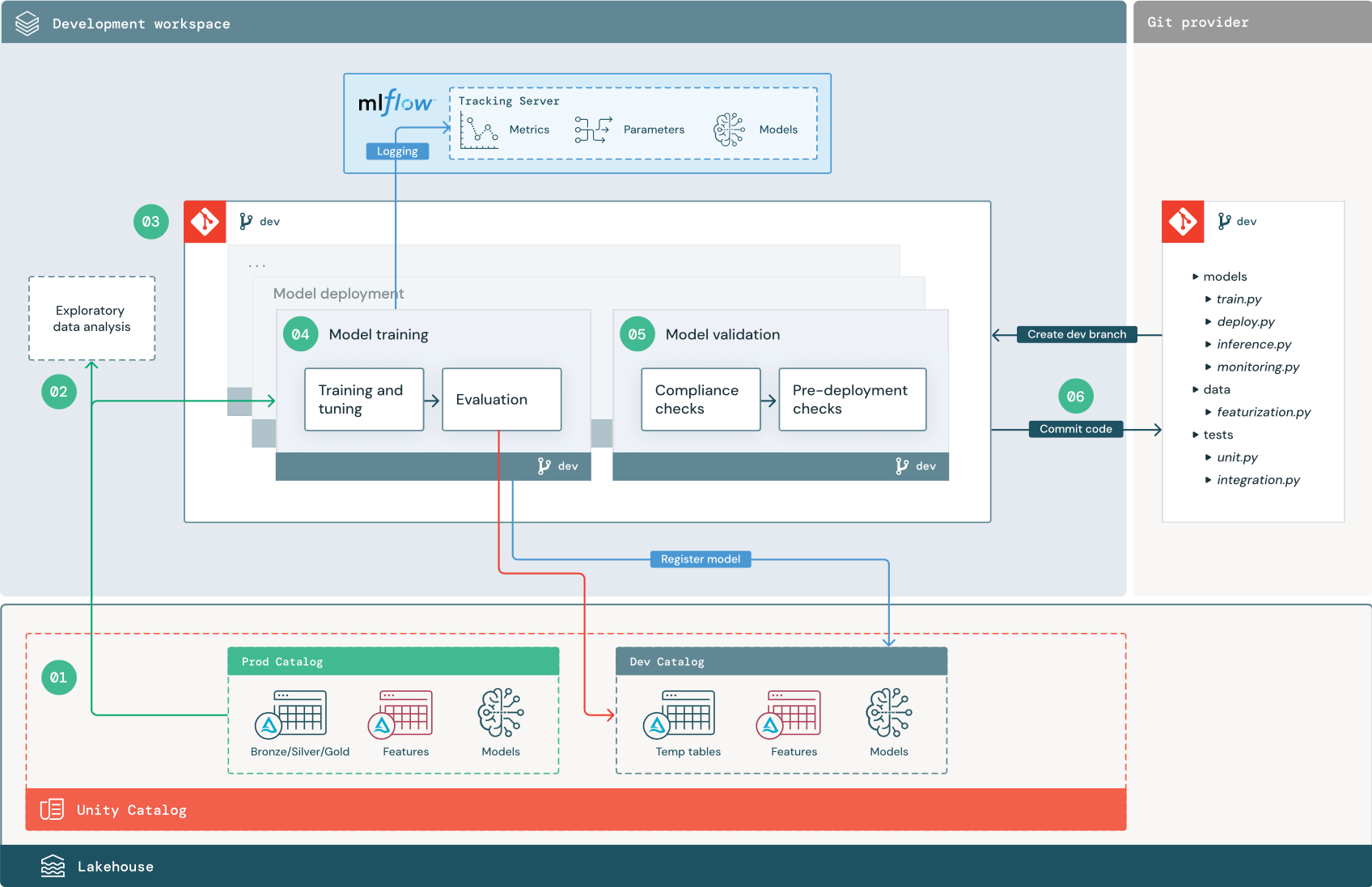
Liczba kroków odpowiada liczbom pokazanym na diagramie.
1. Źródła danych
Środowisko programistyczne jest reprezentowane przez katalog deweloperski w Unity Catalog. Analitycy danych mają dostęp do odczytu i zapisu do katalogu deweloperskiego podczas tworzenia tymczasowych danych i tabel cech w środowisku programistycznym. Modele utworzone na etapie programowania są rejestrowane w katalogu deweloperów.
W idealnym przypadku naukowcy danych pracujący w środowisku programistycznym mają również dostęp tylko do odczytu do danych produkcyjnych w katalogu prod. Umożliwienie naukowcom danych odczytu danych produkcyjnych, tabel wnioskowania i tabel metryk w katalogu produkcyjnym pozwala im analizować bieżące prognozy i wydajność modelu produkcyjnego. Analitycy danych powinni również mieć możliwość ładowania modeli produkcyjnych na potrzeby eksperymentowania i analizy.
Jeśli nie można udzielić dostępu tylko do odczytu do katalogu prod, migawkę danych produkcyjnych można zapisać w wykazie deweloperów, aby umożliwić analitykom danych opracowywanie i ocenianie kodu projektu.
2. Eksploracyjna analiza danych (EDA)
Analitycy danych eksplorują i analizują dane w interaktywnym, iteracyjnym procesie przy użyciu notesów. Celem jest ocena, czy dostępne dane mają potencjał do rozwiązania problemu biznesowego. W tym kroku analityk danych rozpoczyna identyfikowanie kroków przygotowywania i cechowania danych na potrzeby trenowania modelu. Ten proces ad hoc zazwyczaj nie jest częścią potoku, który zostanie wdrożony w innych środowiskach wykonywania.
Rozwiązanie AutoML przyspiesza ten proces, generując modele bazowe dla zestawu danych. Rozwiązanie AutoML wykonuje zestaw prób i rejestruje zestaw prób oraz udostępnia notes języka Python z kodem źródłowym dla każdego przebiegu wersji próbnej, dzięki czemu można przeglądać, odtwarzać i modyfikować kod. Rozwiązanie AutoML oblicza również statystyki podsumowania zestawu danych i zapisuje te informacje w notesie, który można przejrzeć.
3. Kod
Repozytorium kodu zawiera wszystkie potoki, moduły i inne pliki projektu dla projektu uczenia maszynowego. Analitycy danych tworzą nowe lub zaktualizowane potoki w gałęzi programowania ("dev") repozytorium projektu. Począwszy od EDA i początkowych faz projektu, analitycy danych powinni pracować w repozytorium, aby udostępnić kod i śledzić zmiany.
4. Trenowanie modelu (programowanie)
Naukowcy danych opracowują przepływ treningowy modelu w środowisku deweloperskim przy użyciu tabel z katalogów deweloperskich lub produkcyjnych.
Ten potok obejmuje 2 zadania:
Trenowanie i dostrajanie. Proces trenowania rejestruje parametry modelu, metryki i artefakty na serwerze śledzenia MLflow. Po trenowaniu i dostrajaniu hiperparametrów końcowy artefakt modelu jest rejestrowany na serwerze śledzenia w celu zarejestrowania połączenia między modelem, danych wejściowych, na których został wytrenowany, oraz kodu użytego do jego wygenerowania.
Ocena Ocena jakości modelu przez testowanie danych przechowywanych. Wyniki tych testów są rejestrowane na serwerze śledzenia MLflow. Celem oceny jest ustalenie, czy nowo opracowany model działa lepiej niż bieżący model produkcyjny. Biorąc pod uwagę wystarczające uprawnienia, każdy model produkcyjny zarejestrowany w katalogu prod można załadować do obszaru roboczego programowania i porównać go z nowo wytrenowanym modelem.
Jeśli wymagania dotyczące ładu w organizacji zawierają dodatkowe informacje o modelu, możesz zapisać go przy użyciu śledzenia platformy MLflow. Typowe artefakty to zwykłe opisy tekstu i interpretacje modeli, takie jak wykresy generowane przez algorytm SHAP. Określone wymagania dotyczące ładu mogą pochodzić od dyrektora ds. ładu danych lub osób biorących udział w projekcie biznesowym.
Dane wyjściowe potoku trenowania modelu to artefakt modelu uczenia maszynowego przechowywany na serwerze śledzenia MLflow dla środowiska deweloperskiego. Jeśli potok jest wykonywany w obszarze roboczym przejściowym lub produkcyjnym, artefakt modelu jest przechowywany na serwerze śledzenia MLflow dla tego obszaru roboczego.
Po zakończeniu trenowania modelu zarejestruj model w Unity Catalog. Skonfiguruj kod pipeline'u, aby zarejestrować model w wykazie odpowiadającym środowisku, w którym został wykonany pipeline modelu; w tym przykładzie w wykazie dev.
W przypadku zalecanej architektury wdrażasz wielozadaniowy przepływ pracy usługi Databricks, w którym pierwszym zadaniem jest potok trenowania modelu, a następnie zadania weryfikacji modelu i wdrażania modelu. Zadanie trenowania modelu zwraca identyfikator URI modelu, którego może używać zadanie weryfikacji modelu. Możesz użyć wartości zadania , aby przekazać ten identyfikator URI do modelu.
5. Weryfikowanie i wdrażanie modelu (programowanie)
Oprócz potoku trenowania modelu inne potoki, takie jak walidacja modelu i potoki wdrażania modelu, są opracowywane w środowisku projektowym.
Walidacja modelu. Potok weryfikacji modelu pobiera identyfikator URI modelu z potoku trenowania modelu, ładuje model z Unity Catalog i uruchamia sprawdzenia poprawności.
Sprawdzanie poprawności zależy od kontekstu. Mogą one obejmować podstawowe kontrole, takie jak potwierdzanie formatu i wymaganych metadanych, oraz bardziej złożone kontrole, które mogą być wymagane w przypadku wysoce regulowanych branż, takich jak wstępnie zdefiniowane kontrole zgodności i potwierdzanie wydajności modelu dla wybranych wycinków danych.
Podstawową funkcją potoku weryfikacji modelu jest określenie, czy model powinien przejść do kroku wdrażania. Jeśli model przejdzie testy przed wdrożeniem, można przypisać mu przydomek "Challenger" w Unity Catalog. Jeśli testy zakończą się niepowodzeniem, proces zakończy się. Przepływ pracy można skonfigurować tak, aby powiadamiał użytkowników o niepowodzeniu walidacji. Zobacz Dodawanie powiadomień dotyczących zadania.
Wdrażanie modelu. Potok wdrażania modelu zazwyczaj bezpośrednio promuje nowo wytrenowany model "Challenger" do statusu "Champion" przy użyciu aktualizacji aliasu lub umożliwia porównanie istniejącego modelu "Champion" i nowego modelu "Challenger". Ten przepływ pracy może również skonfigurować dowolną wymaganą infrastrukturę wnioskowania, taką jak punkty końcowe serwujące model. Aby zapoznać się ze szczegółowym omówieniem kroków związanych z potokiem wdrażania modelu, zobacz Production (Produkcja).
6. Zatwierdzanie kodu
Po utworzeniu kodu na potrzeby trenowania, walidacji, wdrażania i innych potoków analityk danych lub inżynier uczenia maszynowego zatwierdza zmiany gałęzi deweloperów w kontroli źródła.
Etap przejściowy
Celem tego etapu jest przetestowanie kodu potoku uczenia maszynowego, aby upewnić się, że jest gotowy do produkcji. Cały kod potoku uczenia maszynowego jest testowany na tym etapie, w tym kod do trenowania modelu, a także potoki inżynierii cech, kod wnioskowania itd.
Inżynierowie uczenia maszynowego tworzą potok ciągłej integracji, aby zaimplementować testy jednostkowe i integracyjne uruchamiane na tym etapie. Dane wyjściowe procesu przejściowego to gałąź wydania, która wyzwala system ciągłej integracji/ciągłego wdrażania w celu rozpoczęcia etapu produkcji.
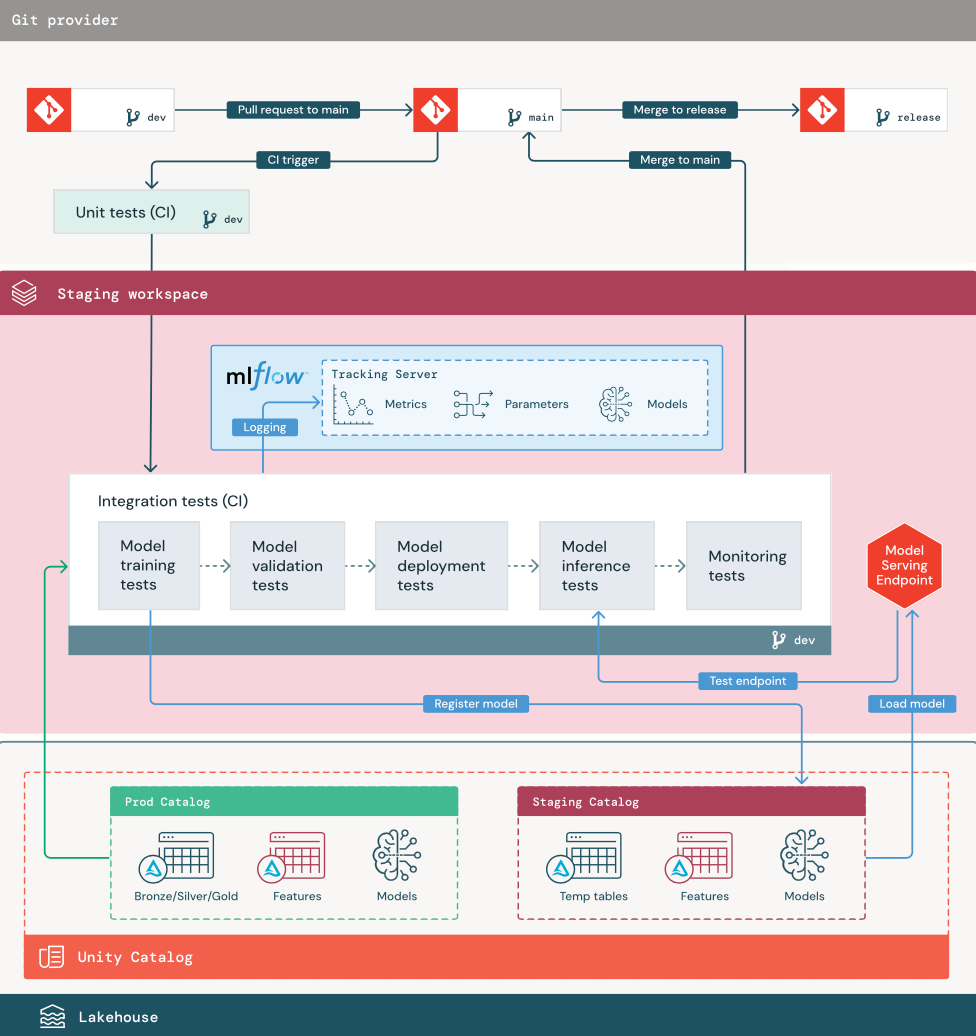
1. Dane
Środowisko przejściowe powinno mieć własny katalog w Unity Catalog do testowania potoków ML i rejestrowania modeli w Unity Catalog. Ten wykaz jest wyświetlany jako wykaz "przejściowy" na diagramie. Zasoby zapisane w tym wykazie są zazwyczaj tymczasowe i przechowywane tylko do czasu ukończenia testowania. Środowisko programistyczne może również wymagać dostępu do wykazu przejściowego na potrzeby debugowania.
2. Scal kod
Naukowcy danych opracowują potok trenowania modelu w środowisku rozwojowym przy użyciu tabel z katalogów rozwojowych lub produkcyjnych.
Żądanie ściągnięcia. Proces wdrażania rozpoczyna się po utworzeniu żądania ściągnięcia względem głównej gałęzi projektu w kontroli źródła.
Testy jednostkowe (CI). Żądanie ściągnięcia automatycznie kompiluje kod źródłowy i wyzwala testy jednostkowe. Jeśli testy jednostkowe nie powiedzą się, żądanie ściągnięcia zostanie odrzucone.
Testy jednostkowe są częścią procesu tworzenia oprogramowania i są stale wykonywane i dodawane do bazy kodu podczas opracowywania dowolnego kodu. Uruchamianie testów jednostkowych w ramach potoku ciągłej integracji gwarantuje, że zmiany wprowadzone w gałęzi dewelopera nie przerywają istniejących funkcji.
3. Testy integracji (CI)
Następnie proces ciągłej integracji uruchamia testy integracji. Testy integracji uruchamiają wszystkie potoki (w tym inżynierię cech, trenowanie modelu, wnioskowanie i monitorowanie), aby upewnić się, że działają prawidłowo. Środowisko przejściowe powinno być zgodne ze środowiskiem produkcyjnym tak ściśle, jak jest to uzasadnione.
Jeśli wdrażasz aplikację uczenia maszynowego z wnioskowaniem w czasie rzeczywistym, należy utworzyć i przetestować infrastrukturę obsługi w środowisku przejściowym. Obejmuje to wyzwolenie potoku wdrażania modelu, który tworzy punkt końcowy obsługujący w środowisku przejściowym i ładuje model.
Aby skrócić czas wymagany do uruchomienia testów integracji, niektóre kroki mogą odróżnić wierność testowania i szybkości lub kosztów. Jeśli na przykład modele są kosztowne lub czasochłonne do trenowania, możesz użyć małych podzbiorów danych lub uruchomić mniej iteracji trenowania. W przypadku obsługi modelu, w zależności od wymagań produkcyjnych, można przeprowadzić testowanie obciążeniowe na pełną skalę w testach integracji lub po prostu przetestować małe zadania wsadowe lub żądania do tymczasowego punktu końcowego.
4. Scalanie do gałęzi przejściowej
Jeśli wszystkie testy przejdą, nowy kod zostanie scalony z gałęzią główną projektu. Jeśli testy kończą się niepowodzeniem, system ciągłej integracji/ciągłego wdrażania powinien powiadamiać użytkowników i publikować wyniki w żądaniu ściągnięcia.
Można zaplanować okresowe testy integracji w gałęzi głównej. Jest to dobry pomysł, jeśli gałąź jest często aktualizowana z równoczesnymi żądaniami ściągnięcia od wielu użytkowników.
5. Tworzenie gałęzi wydania
Po zakończeniu testów CI i scaleniu gałęzi dev z gałęzią główną, inżynier uczenia maszynowego tworzy gałąź wydania, która wyzwala system CI/CD w celu zaktualizowania zadań produkcyjnych.
Etap produkcyjny
Inżynierowie ml posiadają środowisko produkcyjne, w którym są wdrażane i wykonywane potoki uczenia maszynowego. Te potoki danych wyzwalają trenowanie modelu, walidację i wdrażanie nowych wersji modelu, publikowanie przewidywań w tabelach podrzędnych lub aplikacjach oraz monitorowanie całego procesu, aby uniknąć degradacji wydajności i niestabilności.
Analitycy danych zwykle nie mają dostępu do zapisu ani obliczeń w środowisku produkcyjnym. Jednak ważne jest, aby oni mieli wgląd w wyniki testów, dzienniki, artefakty modelu, stan potoku produkcyjnego i tabele monitorowania. Ta widoczność pozwala im identyfikować i diagnozować problemy w środowisku produkcyjnym oraz porównywać wydajność nowych modeli z modelami obecnie w środowisku produkcyjnym. W tym celu można udzielić analitykom danych dostępu tylko do odczytu do zasobów w katalogu produkcyjnym.
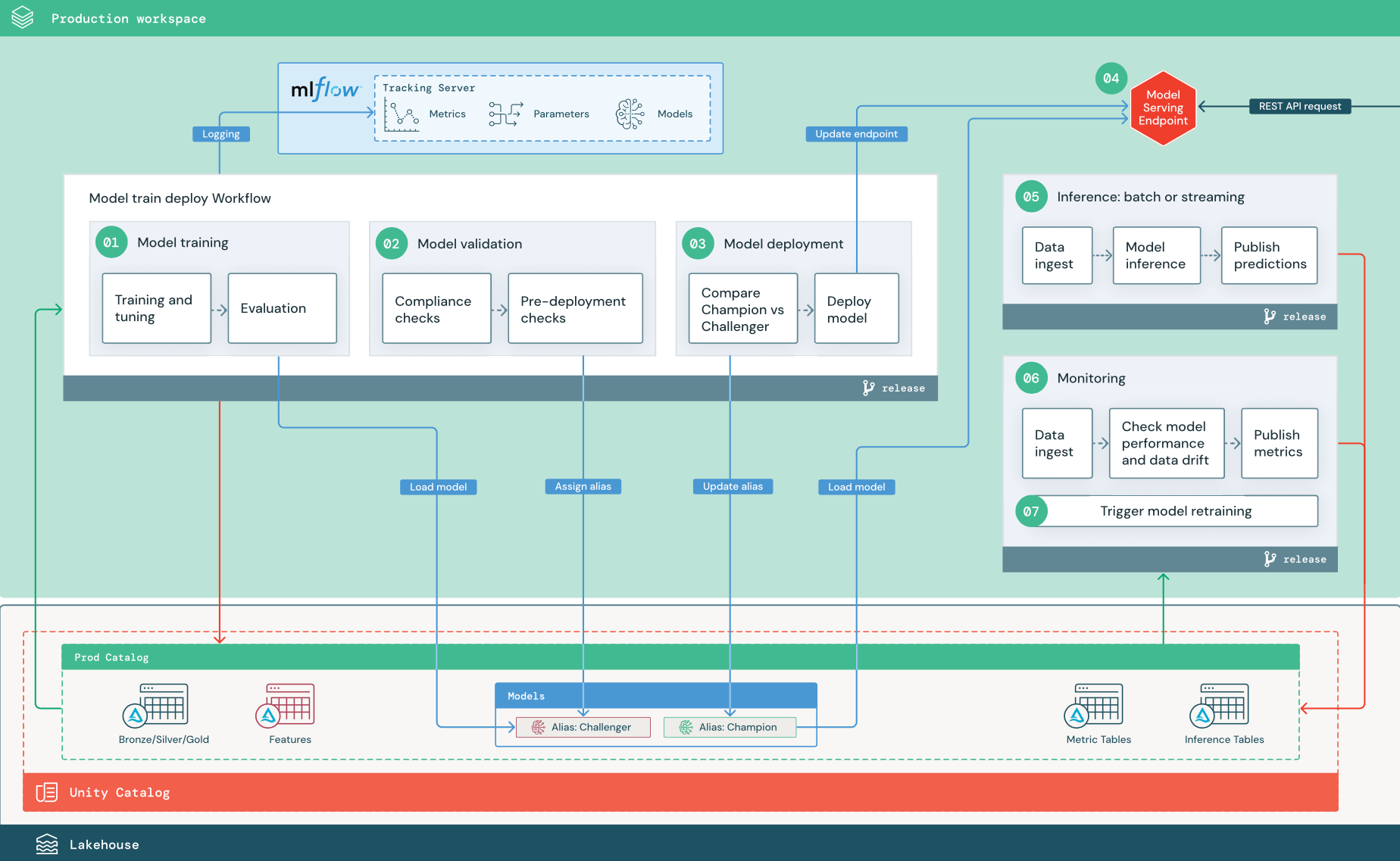
Liczba kroków odpowiada liczbom pokazanym na diagramie.
1. Trenowanie modelu
Ten potok może być wyzwalany przez zmiany kodu lub przez automatyczne ponowne trenowanie zadań. W tym kroku tabele z wykazu produkcyjnego są używane do wykonania poniższych kroków.
Trenowanie i dostrajanie. Podczas procesu trenowania dzienniki są rejestrowane na serwerze śledzenia MLflow środowiska produkcyjnego. Te dzienniki obejmują metryki modelu, parametry, tagi i sam model. Jeśli używasz tabel cech, model jest zapisywany w usłudze MLflow przy użyciu klienta magazynu cech usługi Databricks, który dołącza do modelu informacje o wyszukiwaniu cech używane w czasie wnioskowania.
Podczas opracowywania analitycy danych mogą testować wiele algorytmów i hiperparametrów. W kodzie szkoleniowym produkcyjnym często należy wziąć pod uwagę tylko opcje o najwyższej wydajności. Ograniczenie dostrajania w ten sposób pozwala zaoszczędzić czas i zmniejszyć wariancję przed dostrajaniem w zautomatyzowanym ponownym trenowaniu.
Jeśli analitycy danych mają dostęp tylko do odczytu do katalogu produkcyjnego, mogą być w stanie określić optymalny zestaw hiperparametrów dla modelu. W takim przypadku potok trenowania modelu wdrożony w środowisku produkcyjnym można wykonać przy użyciu wybranego zestawu hiperparametrów, zwykle zawartych w potoku jako pliku konfiguracji.
Ocena Jakość modelu jest oceniana przez testowanie przechowywanych danych produkcyjnych. Wyniki tych testów są rejestrowane na serwerze śledzenia MLflow. W tym kroku są używane metryki oceny określone przez analityków danych na etapie programowania. Te metryki mogą obejmować kod niestandardowy.
Zarejestruj model. Po zakończeniu trenowania modelu, artefakt modelu jest zapisywany jako zarejestrowana wersja na określonej ścieżce modelu w katalogu produkcyjnym w Unity Catalog. Zadanie trenowania modelu zwraca identyfikator URI modelu, którego może używać zadanie weryfikacji modelu. Aby przekazać ten identyfikator URI do modelu, możesz użyć wartości zadań .
2. Weryfikowanie modelu
Ten pipeline używa URI modelu z Kroku 1 i ładuje model z Unity Catalog. Następnie wykonuje serię kontroli poprawności. Te testy zależą od organizacji i przypadku użycia oraz mogą zawierać takie elementy jak podstawowe weryfikacje formatu i metadanych, oceny wydajności dla wybranych wycinków danych oraz zgodność z wymaganiami organizacji, takimi jak sprawdzanie zgodności tagów lub dokumentacji.
Jeśli model pomyślnie przejdzie wszystkie testy weryfikacyjne, możesz przypisać alias "Challenger" do wersji modelu w katalogu Unity. Jeśli model nie przejdzie wszystkich testów sprawdzania poprawności, proces zakończy działanie i użytkownicy będą mogli zostać automatycznie powiadomieni. Tagi umożliwiają dodawanie atrybutów klucz-wartość w zależności od wyniku tych testów sprawdzania poprawności. Można na przykład utworzyć tag "model_validation_status" i ustawić wartość "OCZEKUJĄCE" podczas wykonywania testów, a następnie zaktualizować go do wartości "PASSED" lub "FAILED" po zakończeniu potoku.
Ponieważ model jest zarejestrowany w Unity Catalog, naukowcy danych pracujący w środowisku deweloperskim mogą załadować tę wersję modelu z katalogu produkcyjnego, aby zbadać, czy model nie przechodzi walidacji. Niezależnie od wyniku wyniki są rejestrowane w zarejestrowanym modelu w katalogu produkcyjnym przy użyciu adnotacji do wersji modelu.
3. Wdrażanie modelu
Podobnie jak potok weryfikacji, potok wdrażania modelu zależy od organizacji i przypadku użycia. W tej sekcji założono, że przypisano nowo zweryfikowany model aliasu "Challenger" i że istniejący model produkcyjny został przypisany alias "Champion". Pierwszym krokiem przed wdrożeniem nowego modelu jest potwierdzenie, że działa co najmniej, jak również bieżący model produkcyjny.
Porównaj model "CHALLENGER" z modelem "CHAMPION". To porównanie można wykonać w trybie offline lub w trybie online. Porównanie w trybie offline ocenia oba modele względem zestawu danych przechowywanych i śledzi wyniki przy użyciu serwera śledzenia MLflow. W przypadku obsługi modelu w czasie rzeczywistym warto wykonywać dłuższe porównania online, takie jak testy A/B lub stopniowe wdrażanie nowego modelu. Jeśli wersja modelu "Challenger" działa lepiej w porównaniu, zastępuje bieżący alias "Champion".
Funkcje obsługi modeli mozaiki sztucznej inteligencji i monitorowanie usługi Databricks Lakehouse umożliwiają automatyczne zbieranie i monitorowanie tabel wnioskowania zawierających dane żądania i odpowiedzi dla punktu końcowego.
Jeśli nie ma istniejącego modelu "Champion", możesz porównać model "Challenger" z heurystyczną biznesową lub inną wartością progową jako punkt odniesienia.
Opisany tutaj proces jest w pełni zautomatyzowany. Jeśli wymagane są ręczne kroki zatwierdzania, możesz skonfigurować te elementy przy użyciu powiadomień o przepływie pracy lub wywołań zwrotnych CI/CD (ciągła integracja/ciągłe wdrażanie) z potoku wdrażania modelu.
Wdrażanie modelu. Potoki wnioskowania wsadowego lub przesyłania strumieniowego można skonfigurować tak, aby używać modelu z aliasem "Champion". W przypadku przypadków użycia w czasie rzeczywistym należy skonfigurować infrastrukturę w celu wdrożenia modelu jako punktu końcowego interfejsu API REST. Możesz utworzyć ten punkt końcowy i zarządzać nim przy użyciu usługi Mozaika AI Model Serving. Jeśli punkt końcowy jest już używany dla bieżącego modelu, możesz zaktualizować punkt końcowy przy użyciu nowego modelu. Usługa serwowania modelu AI Mosaic wykonuje aktualizację bez przestoju, utrzymując działającą bieżącą konfigurację, aż nowa będzie gotowa.
4. Obsługa modelu
Podczas konfigurowania punktu końcowego obsługi modelu należy określić nazwę modelu w Unity Catalog oraz wersję, która ma być obsługiwana. Jeśli wersja modelu została wytrenowana przy użyciu cech z tabel w katalogu Unity, model przechowuje zależności dla cech i funkcji. Usługa modelowa automatycznie używa tego grafu zależności do wyszukiwania funkcji z odpowiednich sklepów online w czasie wnioskowania. Takie podejście może również służyć do stosowania funkcji przetwarzania wstępnego danych lub do obliczania funkcji na żądanie podczas oceniania modelu.
Możesz utworzyć pojedynczy punkt końcowy z wieloma modelami i określić podział ruchu punktów końcowych między tymi modelami, umożliwiając przeprowadzanie porównań "Champion" online i "Challenger".
5. Wnioskowanie: wsadowe lub przesyłane strumieniowo
Potok wnioskowania odczytuje najnowsze dane z wykazu produkcyjnego, wykonuje funkcje do obliczania funkcji na żądanie, ładuje model "Champion", ocenia dane i zwraca przewidywania. Wnioskowanie wsadowe lub strumieniowe jest zazwyczaj najbardziej opłacalną opcją dla większej przepływności, większych przypadków użycia opóźnień. W przypadku sytuacji, w których wymagane są niskoopóźnieniowe przewidywania, ale mogą być one obliczane offline, tego typu przewidywania wsadowe można publikować w internetowym magazynie klucz-wartość, takim jak DynamoDB lub Cosmos DB.
Zarejestrowany model w Unity Catalog jest odwoływany poprzez jego alias. Potok wnioskowania jest skonfigurowany do ładowania i stosowania wersji modelu "Champion". Jeśli wersja "Champion" zostanie zaktualizowana do nowej wersji modelu, potok wnioskowania automatycznie używa nowej wersji do następnego wykonania. W ten sposób krok wdrażania modelu jest oddzielony od potoków wnioskowania.
Zadania wsadowe zwykle publikują przewidywania w tabelach w katalogu produkcyjnym, w plikach prostych lub za pośrednictwem połączenia JDBC. Zadania strumieniowe zazwyczaj publikują przewidywania w tabelach katalogu Unity lub w kolejkach wiadomości, takich jak Apache Kafka.
6. Monitorowanie usługi Lakehouse
Monitorowanie usługi Lakehouse monitoruje właściwości statystyczne, takie jak dryf danych i wydajność modelu, dane wejściowe i przewidywania modelu. Alerty można tworzyć na podstawie tych metryk lub publikować je na pulpitach nawigacyjnych.
- Pozyskiwanie danych. Ten potok odczytuje dzienniki z wsadowego, przesyłania strumieniowego lub wnioskowania online.
- Sprawdź dokładność i dryf danych. Potok oblicza metryki dotyczące danych wejściowych, przewidywań modelu i wydajności infrastruktury. Analitycy danych określają metryki danych i modelu podczas opracowywania, a inżynierowie uczenia maszynowego określają metryki infrastruktury. Możesz również zdefiniować metryki niestandardowe za pomocą funkcji Monitorowania usługi Lakehouse.
- Publikowanie metryk i konfigurowanie alertów. Pipeline zapisuje do tabel w katalogu produkcyjnym na potrzeby analizy i raportowania. Te tabele należy skonfigurować tak, aby można je było odczytać ze środowiska deweloperskiego, aby analitycy danych mieli dostęp do analizy. Za pomocą usługi Databricks SQL można tworzyć pulpity nawigacyjne monitorowania w celu śledzenia wydajności modelu oraz skonfigurować zadanie monitorowania lub narzędzie pulpitu nawigacyjnego w celu wystawienia powiadomienia, gdy metryka przekroczy określony próg.
- Wyzwalanie ponownego trenowania modelu. Gdy metryki monitorowania wskazują problemy z wydajnością lub zmiany danych wejściowych, analityk danych może wymagać opracowania nowej wersji modelu. Możesz skonfigurować alerty SQL w celu powiadamiania analityków danych, gdy tak się stanie.
7. Ponowne trenowanie
Ta architektura obsługuje automatyczne ponowne trenowanie przy użyciu tego samego potoku trenowania modelu powyżej. Usługa Databricks zaleca rozpoczęcie od zaplanowanego, okresowego ponownego trenowania i przechodzenia do wyzwalanego ponownego trenowania w razie potrzeby.
- Zaplanowane. Jeśli nowe dane są regularnie dostępne, możesz utworzyć zaplanowane zadanie uruchamiania kodu trenowania modelu na najnowszych dostępnych danych. Zobacz Automatyzowanie zadań za pomocą harmonogramów i wyzwalaczy
- Wyzwalane Jeśli potok monitorowania może identyfikować problemy z wydajnością modelu i wysyłać alerty, może również wyzwolić ponowne trenowanie. Jeśli na przykład rozkład danych przychodzących ulegnie znacznej zmianie lub jeśli wydajność modelu ulegnie pogorszeniu, automatyczne ponowne trenowanie i ponowne wdrażanie może zwiększyć wydajność modelu przy minimalnej interwencji człowieka. Można to osiągnąć za pomocą alertu SQL, aby sprawdzić, czy metryka jest nietypowa (na przykład sprawdzić dryf lub jakość modelu względem progu). Alert można skonfigurować tak, aby używał miejsca docelowego elementu webhook, co może następnie wyzwolić przepływ pracy trenowania.
Jeśli potok ponownego trenowania lub inne potoki wykazują problemy z wydajnością, analityk danych może wrócić do środowiska deweloperskiego, aby uzyskać dodatkowe eksperymenty, aby rozwiązać problemy.