Przepływy pracy LLMOps w usłudze Azure Databricks
Ten artykuł uzupełnia przepływy pracy metodyki MLOps w usłudze Databricks poprzez dodanie informacji specyficznych dla przepływów pracy LLMOps. Aby uzyskać więcej informacji, zobacz The Big Book of MLOps.
Jak zmienia się przepływ pracy MLOps dla LLMs?
LLMs to klasa modeli przetwarzania języka naturalnego (NLP), które znacznie przewyższyły swoich poprzedników pod względem wielkości i wydajności w zakresie różnych zadań, takich jak udzielanie otwartych odpowiedzi na pytania, podsumowywanie oraz wykonywanie instrukcji.
Programowanie i ocena LLM-ów różni się na kilka ważnych sposobów od tradycyjnych modeli uczenia maszynowego. W tej sekcji krótko podsumowano niektóre kluczowe właściwości LLMs oraz ich implikacje dla MLOps.
| Kluczowe właściwości LLMs | Implikacje dotyczące metodyki MLOps |
|---|---|
Maszyny LLM są dostępne w wielu formach.
|
Proces rozwoju: Projekty często rozwijają się przyrostowo, począwszy od istniejących, zewnętrznych lub modeli typu open source, a kończąc na niestandardowo dostosowanych modelach. |
| Wiele LLM-ów przyjmuje ogólne zapytania języka naturalnego i instrukcje jako dane wejściowe. Te zapytania mogą zawierać starannie opracowane wskazówki, aby wywołać żądane odpowiedzi. |
Proces rozwoju: Projektowanie szablonów tekstowych do zapytań przy użyciu LLM jest często ważną częścią tworzenia nowych potoków LLM. Tworzenie pakietów artefaktów uczenia maszynowego: wiele potoków LLM używa istniejących modułów LLM lub llM obsługujących punkty końcowe. Logika uczenia maszynowego opracowana dla tych potoków może skupić się na szablonach monitów, agentach lub łańcuchach zamiast samego modelu. Artefakty uczenia maszynowego spakowane i promowane do środowiska produkcyjnego mogą okazać się pipeline'ami, zamiast modeli. |
| Wiele funkcji LLM może otrzymać monity z przykładami, kontekstem lub innymi informacjami, aby pomóc w udzieleniu odpowiedzi na zapytanie. | Obsługa infrastruktury: podczas rozszerzania zapytań LLM z kontekstem można użyć dodatkowych narzędzi, takich jak bazy danych wektorów, aby wyszukać odpowiedni kontekst. |
| Zewnętrzne interfejsy API udostępniają zastrzeżone i otwartoźródłowe modele. | Zarządzanie API: Korzystanie ze scentralizowanego zarządzania API umożliwia łatwe przełączanie się między dostawcami API. |
| Modele LLM to bardzo duże modele uczenia głębokiego, często zajmujące od kilku do setek gigabajtów. |
Obsługa infrastruktury: moduły LLM mogą wymagać procesorów GPU do obsługi modeli w czasie rzeczywistym i szybkiego przechowywania modeli, które muszą być ładowane dynamicznie. Kompromisy związane z kosztami/wydajnością: ponieważ większe modele wymagają większej liczby obliczeń i są droższe do obsługi, mogą być wymagane techniki zmniejszania rozmiaru modelu i obliczeń. |
| Modele językowe LLM są trudne do oceny za pomocą tradycyjnych metryk uczenia maszynowego, ponieważ często nie ma jednej „właściwej” odpowiedzi. | Informacja zwrotna od ludzi: Informacja zwrotna od ludzi jest niezbędna do oceny i testowania LLM-ów. Opinie użytkowników należy uwzględnić bezpośrednio w procesie MLOps, w tym na potrzeby testowania, monitorowania i dostrajania w przyszłości. |
Podobieństwa między MLOps a LLMOps
Wiele aspektów procesów MLOps nie zmienia się w przypadku maszyn LLM. Na przykład: następujące wytyczne dotyczą również LLMów:
- Używaj oddzielnych środowisk do rozwoju, testowania i produkcji.
- Użyj narzędzia Git do kontroli wersji.
- Zarządzaj rozwojem modeli za pomocą platformy MLflow i zarządzaj cyklem życia modelu przy użyciu Modeli w katalogu Unity.
- Przechowuj dane w architekturze lakehouse przy użyciu tabel Delta.
- Istniejąca infrastruktura CI/CD nie powinna wymagać żadnych zmian.
- Modułowa struktura MLOps pozostaje taka sama, z potokami do cechowania, trenowania modelu, wnioskowanie modelu itd.
Diagramy architektury referencyjnej
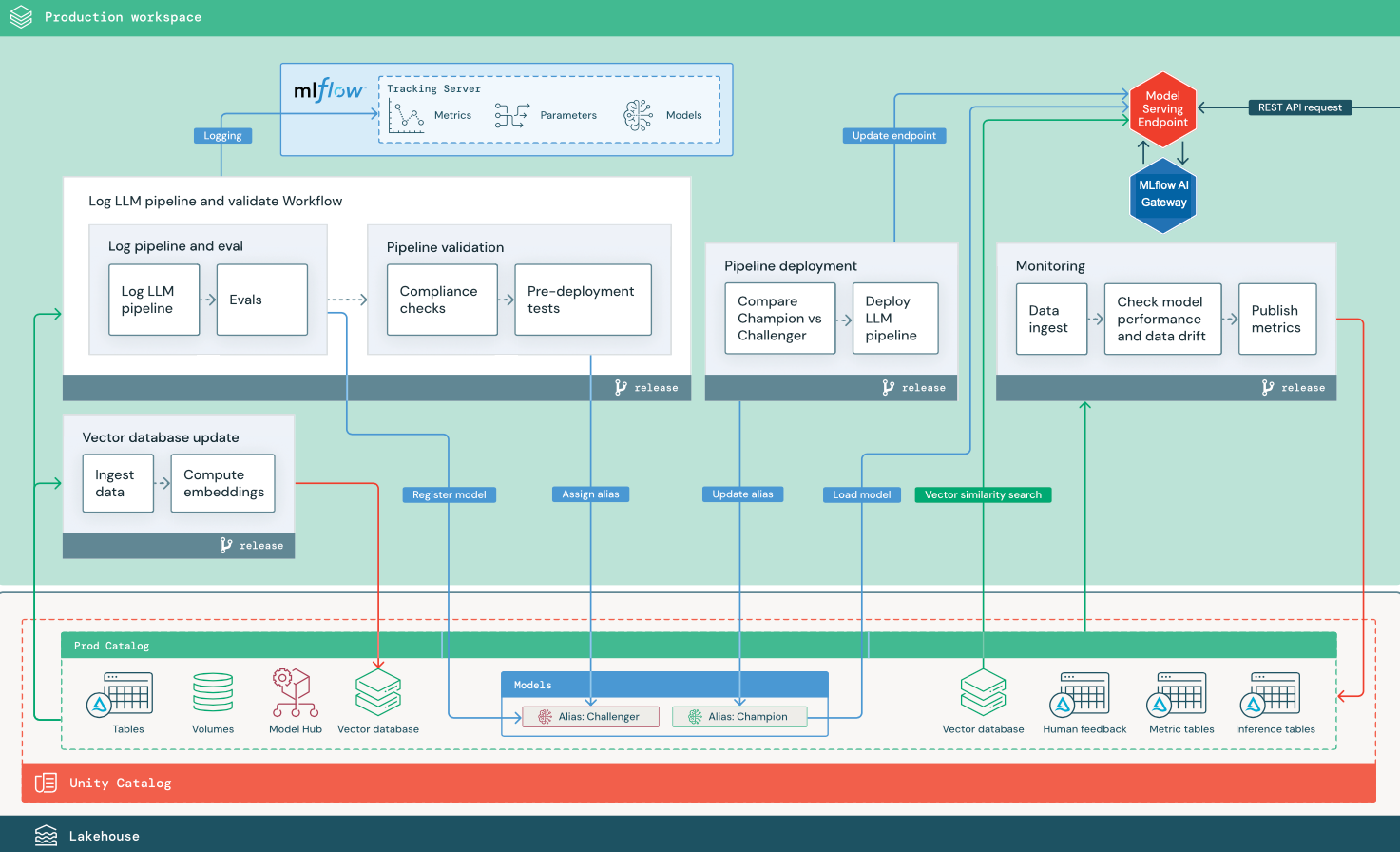
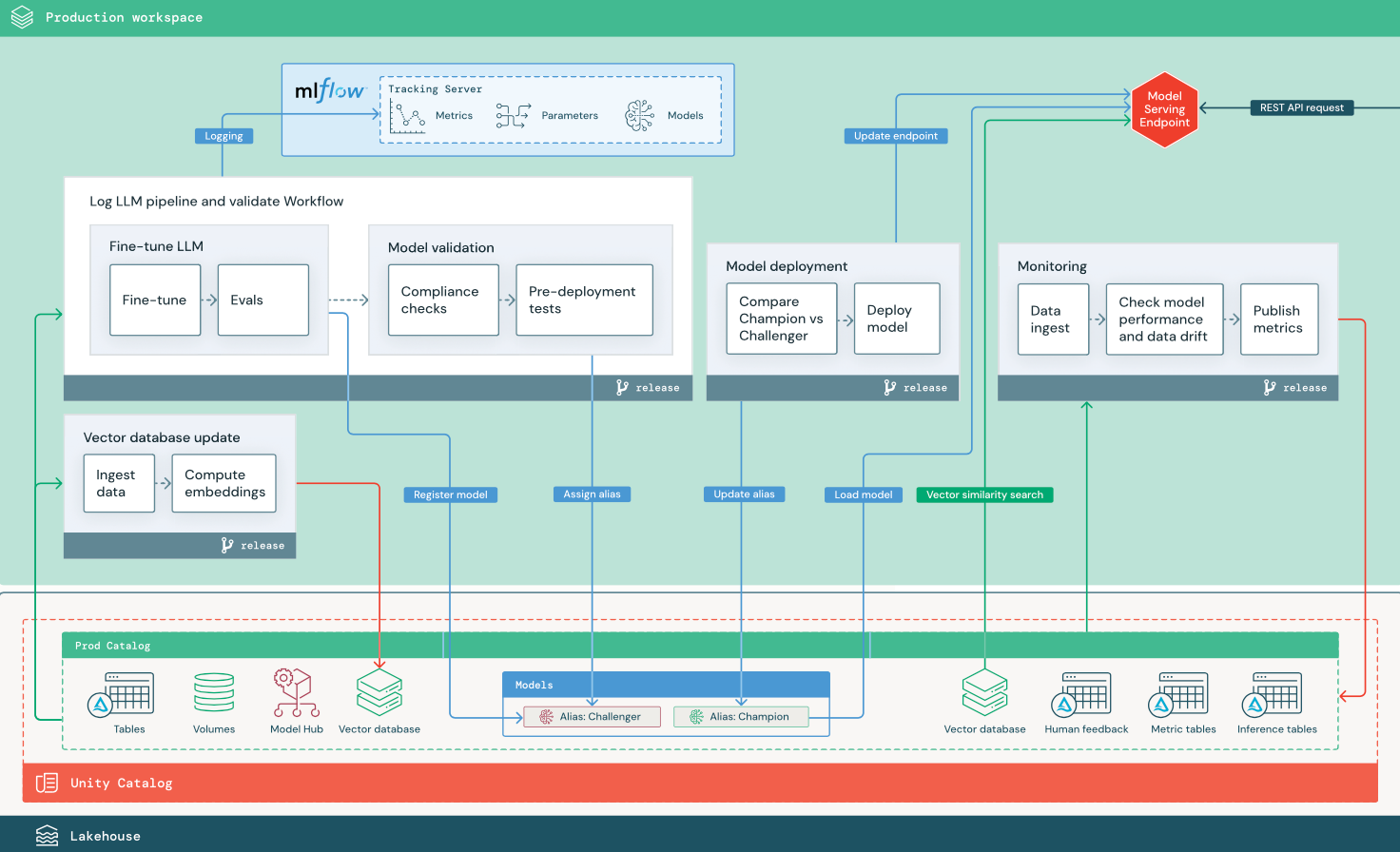
W tej sekcji użyto dwóch aplikacji opartych na LLM, aby zilustrować pewne dostosowania architektury referencyjnej tradycyjnej metodyki MLOps. Diagramy przedstawiają architekturę produkcyjną dla 1) aplikacji generacji wspomaganej wyszukiwaniem (RAG) za pomocą API zewnętrznego dostawcy oraz 2) aplikacji RAG z wykorzystaniem własnego, dostrojonego modelu hostowanego lokalnie. Oba diagramy pokazują opcjonalną bazę danych wektorów — ten element można zastąpić bezpośrednim zapytaniem do LLM za pośrednictwem punktu końcowego obsługi modelu.
RAG z interfejsem API LLM innej firmy
Na diagramie przedstawiono architekturę produkcyjną aplikacji RAG, która łączy się z interfejsem API LLM innej firmy przy użyciu modeli zewnętrznych usługi Databricks.
RAG z dostosowanym modelem open source
Na diagramie przedstawiono architekturę produkcyjną aplikacji RAG, która dostraja model open source.
Zmiany architektury produkcyjnej z LLMOps na MLOps
W tej sekcji przedstawiono główne zmiany architektury referencyjnej metodyki MLOps dla aplikacji LLMOps.
Centrum modelu
Aplikacje LLM często używają istniejących, wstępnie wytrenowanych modeli wybranych z wewnętrznego lub zewnętrznego centrum modelu. Model może być używany w taki sposób, jak jest lub dostrojony.
Usługa Databricks obejmuje wybór wysokiej jakości, wstępnie wytrenowanych modeli podstawowych w Unity Catalog i na markecie Databricks. Możesz użyć tych wstępnie wytrenowanych modeli, aby uzyskać dostęp do najnowocześniejszych funkcji sztucznej inteligencji, co pozwala zaoszczędzić czas i wydatki na tworzenie własnych modeli niestandardowych. Aby uzyskać szczegółowe informacje, zobacz Wstępnie wytrenowane modele w Unity Catalog i Rynku.
Wektorowa baza danych
Niektóre aplikacje LLM używają baz danych wektorów do szybkiego wyszukiwania podobieństwa, na przykład w celu zapewnienia wiedzy o kontekście lub domenie w zapytaniach LLM. Usługa Databricks oferuje zintegrowaną funkcję wyszukiwania wektorowego, która umożliwia użycie dowolnej tabeli Delta w Unity Catalogu jako wektorowej bazy danych. Indeks wyszukiwania wektorowego jest automatycznie synchronizowany z tabelą delty. Aby uzyskać szczegółowe informacje, zobacz Wyszukiwanie wektorowe.
Możesz utworzyć artefakt modelowy, który zawiera logikę umożliwiającą pobieranie informacji z bazy danych wektorów i przedstawia zwrócone dane jako kontekst dla LLM. Następnie możesz zarejestrować model przy użyciu odmiany modelu MLflow LangChain lub PyFunc.
Dostrajanie LLM
Ponieważ modele LLM są kosztowne i czasochłonne do utworzenia od podstaw, aplikacje LLM często dostrajają istniejący model w celu zwiększenia wydajności w konkretnym scenariuszu. W architekturze referencyjnej dostrajanie i wdrażanie modelu są reprezentowane jako odrębne zadania usługi Databricks. Walidacja dostosowanego modelu przed wdrożeniem jest często procesem ręcznym.
Databricks oferuje dostrajanie Modelu Fundamentowego, co umożliwia wykorzystanie własnych danych do dostosowania istniejącego modelu LLM w celu zoptymalizowania jego wydajności dla Twojej specyficznej aplikacji. Aby uzyskać szczegółowe informacje, zobacz Dostosowywanie modelu podstawowego.
Obsługa modelu
W scenariuszu RAG przy użyciu interfejsu API innej firmy ważna zmiana architektury polega na tym, że potok LLM wykonuje zewnętrzne wywołania interfejsu API z punktu końcowego obsługi modelu do wewnętrznych bądź zewnętrznych interfejsów API LLM. Zwiększa to złożoność, potencjalne opóźnienia i dodatkowe zarządzanie poświadczeniami.
Usługa Databricks udostępnia usługę Mosaic AI Model Serving, która udostępnia ujednolicony interfejs do wdrażania modeli sztucznej inteligencji, zarządzania nimi i wykonywania zapytań. Aby uzyskać szczegółowe informacje, zobacz Obsługa modelu AI Mosaic.
Opinie ludzi na temat monitorowania i oceny
Pętle sprzężenia zwrotnego ludzkiego są niezbędne w większości aplikacji opartych na LLM. Opinie ludzi powinny być zarządzane jak inne dane, najlepiej włączone do monitorowania w oparciu o przesyłanie strumieniowe niemal w czasie rzeczywistym.
Aplikacja recenzująca platformę agenta AI Mosaic pomaga w zbieraniu opinii od recenzentów. Aby uzyskać szczegółowe informacje, zobacz Użyj aplikacji Review do recenzji ludzkich aplikacji generatywnej AI.