Co oznaczają zakresy tokenów na sekundę w aprowizowanej przepustowości?
W tym artykule opisano, jak i dlaczego usługa Databricks mierzy liczbę tokenów na sekundę przydzielonego obciążenia o określonej przepustowości dla interfejsów API modelu Foundation.
Wydajność dużych modeli językowych (LLM) jest często mierzona pod względem tokenów na sekundę. Podczas konfigurowania modelu produkcyjnego obsługującego punkty końcowe należy wziąć pod uwagę liczbę żądań wysyłanych przez aplikację do punktu końcowego. Dzięki temu można zrozumieć, czy punkt końcowy musi być skonfigurowany do skalowania, tak aby nie wpływał na opóźnienie.
Podczas konfigurowania zakresów skalowania dla punktów końcowych z przydzieloną przepustowością, Databricks stwierdził, że łatwiej jest rozumieć dane wejściowe trafiające do systemu za pomocą tokenów.
Co to są tokeny?
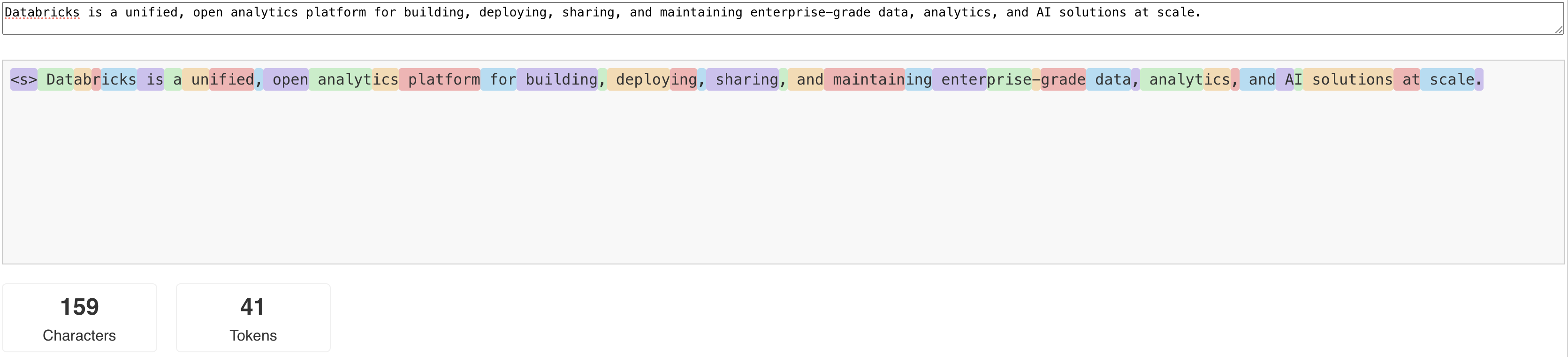
LLM-y odczytują i generują tekst w oparciu o to, co nazywane jest tokenem . Tokeny mogą być wyrazami lub wyrazami podrzędnymi, a dokładne reguły dzielenia tekstu na tokeny różnią się w zależności od modelu do modelu. Na przykład możesz użyć narzędzi online, aby zobaczyć, jak tokenizer Llama konwertuje wyrazy na tokeny.
Na poniższym diagramie przedstawiono przykład, w jaki sposób tokenizer Llama dzieli tekst:
Dlaczego warto zmierzyć wydajność usługi LLM pod względem tokenów na sekundę?
Tradycyjnie obsługa punktów końcowych jest konfigurowana na podstawie liczby współbieżnych żądań na sekundę (RPS). Jednak żądanie wnioskowania LLM zajmuje różną ilość czasu w zależności od liczby przekazanych tokenów oraz liczby tokenów, które generuje, co może prowadzić do nierównowagi między żądaniami. W związku z tym podjęcie decyzji o skali w poziomie punktu końcowego wymaga rzeczywistego pomiaru skali punktu końcowego pod względem liczby tokenów w zawartości żądania.
Różne przypadki użycia zawierają różne współczynniki tokenów wejściowych i wyjściowych:
- Różne długości kontekstów wejściowych: Podczas gdy niektóre żądania mogą obejmować tylko kilka tokenów wejściowych, na przykład krótkie pytanie, inne mogą obejmować setki lub nawet tysiące tokenów, takich jak długi dokument do podsumowania. Ta zmienność sprawia, że konfigurowanie punktu końcowego serwującego wyłącznie na podstawie RPS jest trudne, ponieważ nie uwzględnia zmiennych wymagań przetwarzania różnych żądań.
- różne długości danych wyjściowych w zależności od przypadku użycia: różne przypadki użycia dla maszyn LLM mogą prowadzić do znacznie różnych długości tokenów wyjściowych. Generowanie tokenów wyjściowych jest najbardziej czasochłonną częścią wnioskowania LLM, dzięki czemu może to znacząco wpłynąć na przepływność. Na przykład podsumowanie obejmuje krótsze, bardziej treściwe odpowiedzi, ale generowanie tekstu, takie jak pisanie artykułów lub opisów produktów, może prowadzić do znacznie dłuższych odpowiedzi.
Jak wybrać zakres tokenów na sekundę dla mojego punktu końcowego?
Konfigurowanie przepustowości punktów końcowych odbywa się w zakresie od określonej liczby tokenów na sekundę, które można wysłać do punktu końcowego. Punkt końcowy automatycznie dostosowuje się do wzrastającego i malejącego obciążenia aplikacji produkcyjnej. Opłaty są naliczane za godzinę na podstawie zakresu tokenów na sekundę, do którego jest skalowany punkt końcowy.
Najlepszym sposobem, aby dowiedzieć się, jaki zakres tokenów na sekundę w przepustowości aprowizowanej działa na twoim punkcie końcowym dla konkretnego przypadku użycia, jest przeprowadzenie testu obciążeniowego z reprezentatywnym zestawem danych. Zobacz Przeprowadź własny test porównawczy punktu końcowego LLM.
Należy wziąć pod uwagę dwa ważne czynniki:
- Jak Databricks mierzy wydajność modelu LLM w tokenach na sekundę.
- Jak działa skalowanie automatyczne.
Jak usługa Databricks mierzy tokeny na sekundę wydajności usługi LLM
Databricks przeprowadza testy punktów końcowych względem obciążenia reprezentującego zadania podsumowujące, które są typowe dla przypadków użycia generacji wspomaganej pobieraniem. W szczególności obciążenie składa się z następujących elementów:
- 2048 tokenów wejściowych
- 256 tokenów wyjściowych
Wyświetlane zakresy tokenów łączą przepustowość tokenów wejściowych i wyjściowych i domyślnie optymalizują pod kątem równoważenia przepustowości i opóźnienia.
Testy porównawcze Databricks wskazują, że użytkownicy mogą wysyłać tak wiele tokenów na sekundę do punktu końcowego przy rozmiarze partii 1 na każde żądanie. Symuluje to jednocześnie wiele żądań osiągnięcia punktu końcowego, co dokładniej reprezentuje sposób rzeczywistego używania punktu końcowego w środowisku produkcyjnym.
- Jeśli na przykład aprowizowany punkt końcowy obsługujący przepływność ma ustawioną szybkość 2304 tokenów na sekundę (2048 + 256), pojedyncze żądanie z danymi wejściowymi tokenów 2048 i oczekiwaną wartością wyjściową 256 tokenów powinno potrwać około jednej sekundy.
- Podobnie, jeśli szybkość jest ustawiona na 5600, można oczekiwać, że przetworzenie pojedynczego żądania zajmie około 0,5 sekundy przy uwzględnieniu powyższych ilości tokenów wejściowych i wyjściowych. Oznacza to, że punkt końcowy może przetwarzać dwa podobne żądania w ciągu około jednej sekundy.
Jeśli obciążenie różni się od powyższych, możesz oczekiwać, że opóźnienie będzie się zmieniać w odniesieniu do podanej stopy zagwarantowanej przepływności. Jak wspomniano wcześniej, generowanie większej liczby tokenów wyjściowych jest bardziej czasochłonne niż uwzględnianie większej liczby tokenów wejściowych. Jeśli przeprowadzasz wnioskowanie wsadowe i chcesz oszacować czas potrzebny do ukończenia, możesz obliczyć średnią liczbę tokenów wejściowych i wyjściowych oraz porównać je z powyższym obciążeniem porównawczym usługi Databricks.
- Jeśli na przykład masz 1000 wierszy ze średnią liczbą tokenów wejściowych wynoszącą 3000 i średnią liczbą tokenów wyjściowych wynoszącą 500, a aprowizowaną przepływność wynoszącą 3500 tokenów na sekundę, może upłynąć dłużej niż 1000 sekund (jedna sekunda na wiersz), ponieważ średnia liczba tokenów jest większa niż test porównawczy usługi Databricks.
- Podobnie jeśli masz 1000 wierszy, średnie dane wejściowe 1500 tokenów, średnie dane wyjściowe 100 tokenów i aprowizowaną przepływność wynoszącą 1600 tokenów na sekundę, może upłynąć mniej niż 1000 sekund (jedna sekunda na wiersz) ze względu na średnie liczby tokenów mniej niż test porównawczy usługi Databricks.
Aby oszacować idealną aprowizowaną przepustowość wymaganą do ukończenia obciążenia wnioskowania wsadowego, możesz użyć notatnika w sekcji Wykonywanie wnioskowania wsadowego LLM przy użyciu ai_query
Jak działa skalowanie automatyczne
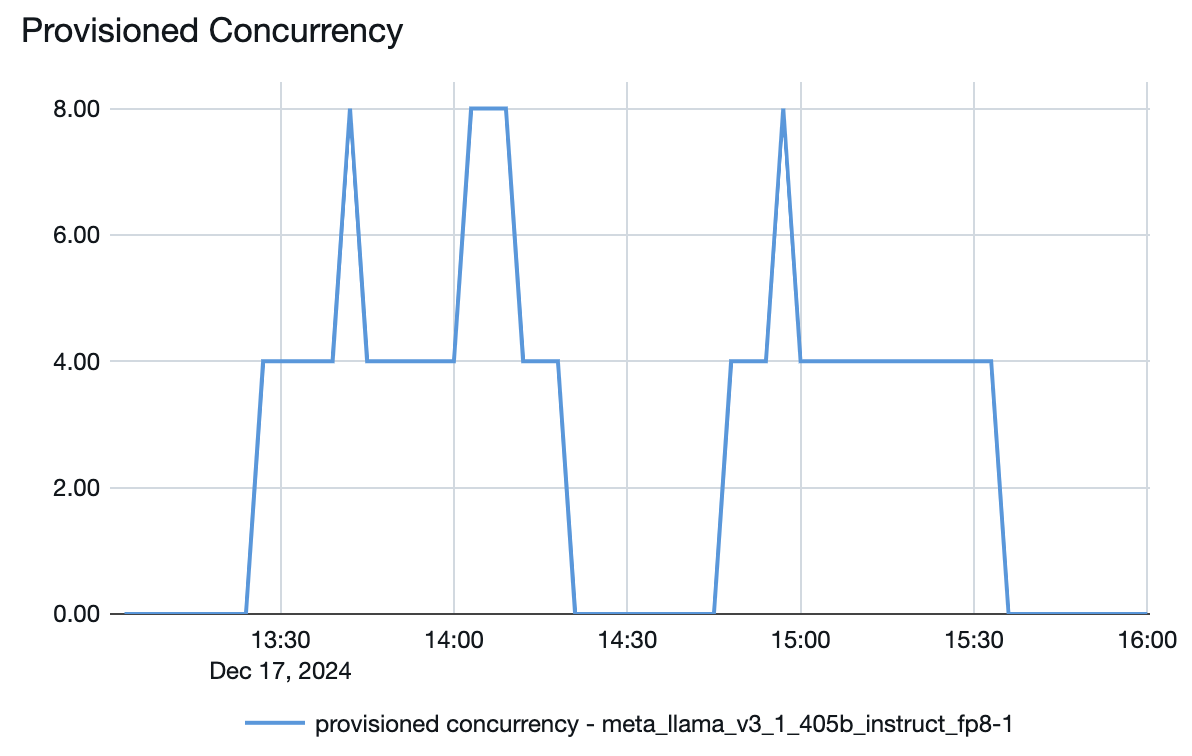
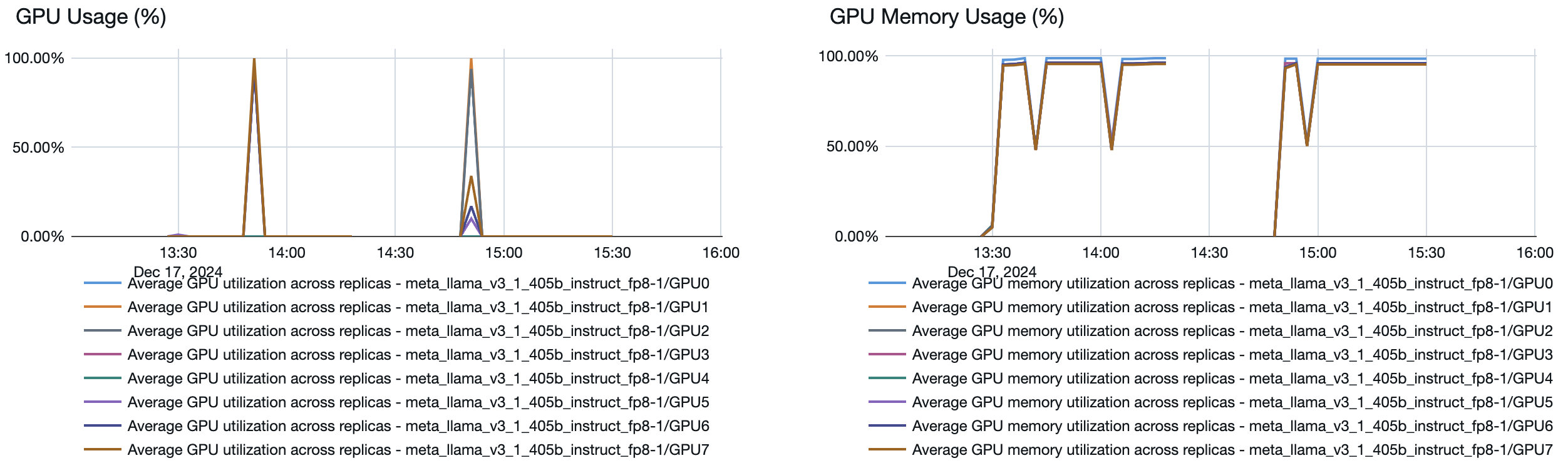
Obsługa modelu oferuje szybki system skalowania automatycznego, który dostosowuje moc obliczeniową do zapotrzebowania aplikacji na liczbę tokenów na sekundę. Usługa Databricks zwiększa aprowizowaną przepustowość w częściach według liczby tokenów na sekundę, więc opłaty są naliczane tylko wtedy, gdy używasz dodatkowych jednostek aprowizowanej przepustowości.
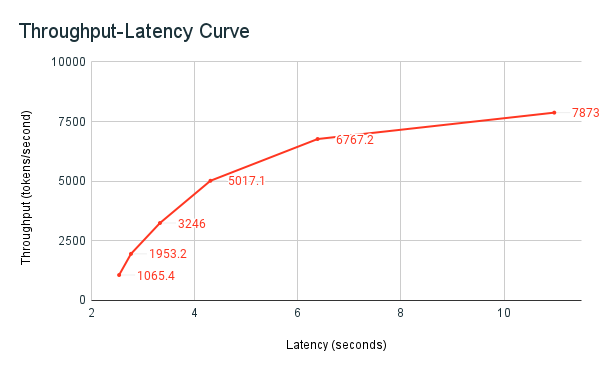
Poniższy wykres przepływności-opóźnienia przedstawia przetestowany punkt końcowy z zagwarantowaną przepływnością z rosnącą liczbą żądań równoległych. Pierwszy punkt reprezentuje 1 żądanie, drugie, 2 żądania równoległe, trzecie, 4 równoległe żądania itd. W miarę wzrostu liczby żądań i zapotrzebowania na tokeny na sekundę, widać, że przydzielona przepustowość również wzrasta. Ten wzrost wskazuje, że skalowanie automatyczne zwiększa dostępne zasoby obliczeniowe. Można jednak zacząć zauważać, że przepływność zaczyna się wypłaszczać, osiągając limit ok. 8000 tokenów na sekundę, gdy jest składanych więcej równoległych żądań. Łączne opóźnienie zwiększa się, ponieważ więcej żądań musi czekać w kolejce przed przetworzeniem, ponieważ przydzielone zasoby obliczeniowe są używane jednocześnie.
Notatka
Możesz zachować spójność przepływności, wyłączając skalowanie do zera i konfigurując minimalną przepływność w punkcie końcowym obsługującym. Pozwala to uniknąć konieczności oczekiwania na skalowanie punktu końcowego w górę.
Możesz również zobaczyć z poziomu modelu obsługującego punkt końcowy, w jaki sposób zasoby są przenoszone w górę lub w dół w zależności od zapotrzebowania: