Klasyfikacja przy użyciu rozwiązania AutoML
Użyj rozwiązania AutoML, aby automatycznie znaleźć najlepszy algorytm klasyfikacji i konfigurację hiperparametrów, aby przewidzieć etykietę lub kategorię danych wejściowych.
Set eksperyment zwiększania klasyfikacji przy użyciu interfejsu użytkownika
Możesz set problem klasyfikacji przy użyciu interfejsu użytkownika rozwiązania AutoML, wykonując następujące czynności:
Na pasku bocznym selectEksperymenty.
Na karcie klasyfikacji , selectRozpocznij szkolenie.
Zostanie wyświetlona strona Konfigurowanie eksperymentu automatycznego uczenia maszynowego. Na tej stronie skonfigurujesz proces AutoML, określając zestaw danych, typ problemu, cel lub etykietę column do przewidywania, metrykę do oceny i punktacji przebiegów eksperymentu oraz warunki zatrzymania.
W polu Computeselect klastra z uruchomionym środowiskiem Databricks Runtime ML.
W sekcji Dataset, selectPrzeglądaj.
Przejdź do table, którego chcesz użyć, a następnie kliknij Select. Zostanie wyświetlona tableschema.
- W środowisku Databricks Runtime 10.3 ML i nowszym można określić, który columns algorytm AutoML powinien być używany do szkolenia. Nie można remove wybranego column jako celu przewidywania lub czasu column podzielenia danych.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym możesz określić, w jaki sposób values null są impuplikowane, wybierając z listy rozwijanej Impute z. Domyślnie AutoML wybiera metodę imputacji na podstawie typu column i zawartości.
Uwaga
Jeśli określisz metodę imputacji innej niż domyślna, rozwiązanie AutoML nie wykonuje wykrywania typów semantycznych.
Kliknij pole Cel przewidywania. Pojawi się lista rozwijana, która zawiera columns wyświetlane w schema. Select column, który ma przewidywać model.
W polu Nazwa eksperymentu jest wyświetlana nazwa domyślna. Aby ją zmienić, wpisz nową nazwę w polu.
Możesz również wykonać następujące czynności:
- Określ dodatkowe opcje konfiguracji.
- Użyj istniejącej funkcji w Magazynie Funkcji tables, aby rozszerzyć oryginalny zestaw danych wejściowych.
Konfiguracje zaawansowane
Otwórz sekcję Advanced Configuration (opcjonalnie), aby uzyskać dostęp do tych ustawień parameters.
- Metryka oceny to podstawowa metryka używana do oceniania przebiegów.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym można wykluczyć struktury szkoleniowe z uwagi. Domyślnie rozwiązanie AutoML trenuje modele przy użyciu struktur wymienionych w obszarze Algorytmy automatycznego uczenia maszynowego.
- Możesz edytować warunki zatrzymywania. Domyślne warunki zatrzymywania to:
- W przypadku eksperymentów prognozowania zatrzymaj się po 120 minutach.
- W środowisku Databricks Runtime 10.4 LTS ML i poniżej w przypadku eksperymentów klasyfikacji i regresji zatrzymaj się po 60 minutach lub po ukończeniu 200 prób, w zależności od tego, co nastąpi wcześniej. W przypadku środowiska Databricks Runtime 11.0 ML i nowszych liczba prób nie jest używana jako stan zatrzymania.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym w przypadku eksperymentów klasyfikacji i regresji rozwiązanie AutoML obejmuje wczesne zatrzymywanie; zatrzymuje trenowanie i dostrajanie modeli, jeśli metryka walidacji nie jest już ulepszana.
- W środowisku Databricks Runtime 10.4 LTS ML i nowszym można select
time columnpodzielić dane na potrzeby trenowania, walidacji i testowania w kolejności chronologicznej (dotyczy tylko klasyfikacji i regresji ). - Usługa Databricks nie zaleca wypełniania pola Katalog danych. Spowoduje to wyzwolenie domyślnego zachowania bezpiecznego przechowywania zestawu danych jako artefaktu MLflow. Można określić ścieżkę systemu plików DBFS, ale w tym przypadku zestaw danych nie dziedziczy uprawnień dostępu eksperymentu automatycznego uczenia maszynowego.
Uruchamianie eksperymentu i monitorowanie wyników
Aby rozpocząć eksperyment automl, kliknij przycisk Uruchom rozwiązanie AutoML. Eksperyment rozpoczyna się od uruchomienia, a zostanie wyświetlona strona trenowania zautomatyzowanego uczenia maszynowego. Aby refresh wykonać table, kliknij przycisk  .
.
Wyświetlanie postępu eksperymentu
Z poziomu tej strony można:
- Zatrzymaj eksperyment w dowolnym momencie.
- Otwórz notes eksploracji danych.
- Monitorowanie przebiegów.
- Przejdź do strony uruchamiania dla dowolnego przebiegu.
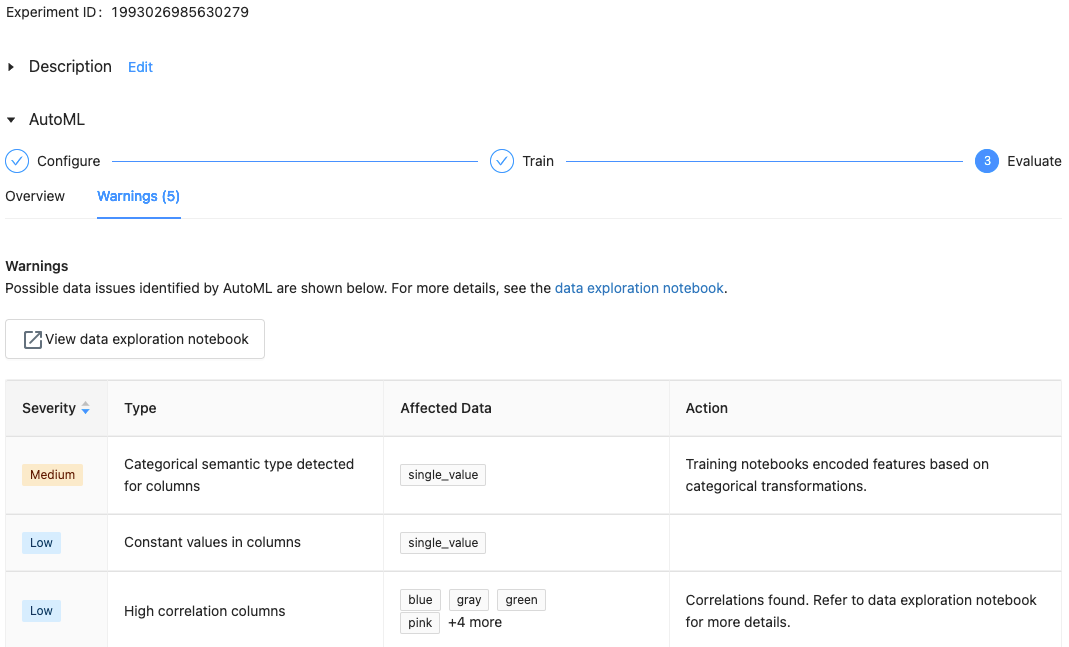
W przypadku Databricks Runtime 10.1 ML i nowszych, AutoML wyświetla ostrzeżenia dotyczące potencjalnych problemów z zestawem danych, takich jak nieobsługiwane typy column lub wysoka kardynalność columns.
Uwaga
Usługa Databricks najlepiej wskazuje potencjalne błędy lub problemy. Jednak może to nie być kompleksowe i może nie przechwytywać problemów lub błędów, które mogą być wyszukiwane.
Aby wyświetlić wszelkie ostrzeżenia dotyczące zestawu danych, kliknij kartę Ostrzeżenia na stronie trenowania lub na stronie eksperymentu po zakończeniu eksperymentu.
Wyświetlanie wyników
Po zakończeniu eksperymentu można wykonać następujące czynności:
- Zarejestruj i wdróż jeden z modeli za pomocą biblioteki MLflow.
- Select Wyświetl notes najlepszy model, aby przejrzeć i edytować notes, który utworzył ten model.
- Select Otwórz zeszyt eksploracji danych, aby wyświetlić zeszyt eksploracji danych.
- Wyszukaj, przefiltruj i posortuj przebiegi w table.
- Zobacz szczegóły dotyczące dowolnego przebiegu:
- Wygenerowany notes zawierający kod źródłowy dla przebiegu w wersji próbnej można znaleźć, klikając w przebiegu platformy MLflow. Notes jest zapisywany w sekcji Artefakty na stronie uruchamiania. Możesz pobrać ten notes i zaimportować go do obszaru roboczego, jeśli pobieranie artefaktów jest włączone przez administratorów obszaru roboczego.
- Aby wyświetlić wyniki przebiegu, kliknij Modelscolumn lub Godzina rozpoczęciacolumn. Zostanie wyświetlona strona uruchomienia zawierająca informacje o próbie (na przykład parameters, metryki i tagi) oraz artefakty utworzone podczas uruchomienia, w tym model. Ta strona zawiera również fragmenty kodu, których można użyć do przewidywania modelu.
Aby wrócić do tego eksperymentu automatycznego uczenia maszynowego później, znajdź go w table na stronie eksperymentów . Wyniki każdego eksperymentu zautomatyzowanego uczenia maszynowego, w tym notesów eksploracji i trenowania danych, są przechowywane w databricks_automlfolderze głównym użytkownika, który przeprowadził eksperyment.
Rejestrowanie i wdrażanie modelu
Model można zarejestrować i wdrożyć za pomocą interfejsu użytkownika rozwiązania AutoML:
- Select łącze w Modelscolumn do zarejestrowania modelu. Po zakończeniu przebiegu górny wiersz jest najlepszym modelem (na podstawie metryki podstawowej).
-
Select
 , aby zarejestrować model w Rejestrze Modeli .
, aby zarejestrować model w Rejestrze Modeli . -
Select
 Models na pasku bocznym, aby przejść do rejestru modeli.
Models na pasku bocznym, aby przejść do rejestru modeli. - Select nazwę twojego modelu w modelu table.
- Na stronie zarejestrowanego modelu można udostępnić model z obsługą modelu.
Brak modułu o nazwie "pandas.core.indexes.numeric"
W przypadku obsługi modelu utworzonego przy użyciu rozwiązania AutoML z obsługą modelu można get błąd: No module named 'pandas.core.indexes.numeric.
Jest to spowodowane niezgodną pandas wersją między rozwiązaniem AutoML a modelem obsługującym środowisko punktu końcowego. Ten błąd można rozwiązać, uruchamiając skrypt add-pandas-dependency.py. Skrypt edytuje element requirements.txt i conda.yaml dla zarejestrowanego modelu, aby zawierał odpowiednią pandas wersję zależności: pandas==1.5.3
- Zmodyfikuj skrypt, aby uwzględnić
run_idprzebiegu, w którym na platformie MLflow zarejestrowano Twój model where. - Ponowne zarejestrowanie modelu w rejestrze modeli MLflow.
- Spróbuj użyć nowej wersji modelu MLflow.