Co to jest usługa Data Lakehouse?
System data lakehouse to system zarządzania danymi, który łączy zalety jezior danych i magazynów danych. W tym artykule jest opisany wzorzec architektury lakehouse i co można z nim zrobić w usłudze Azure Databricks.
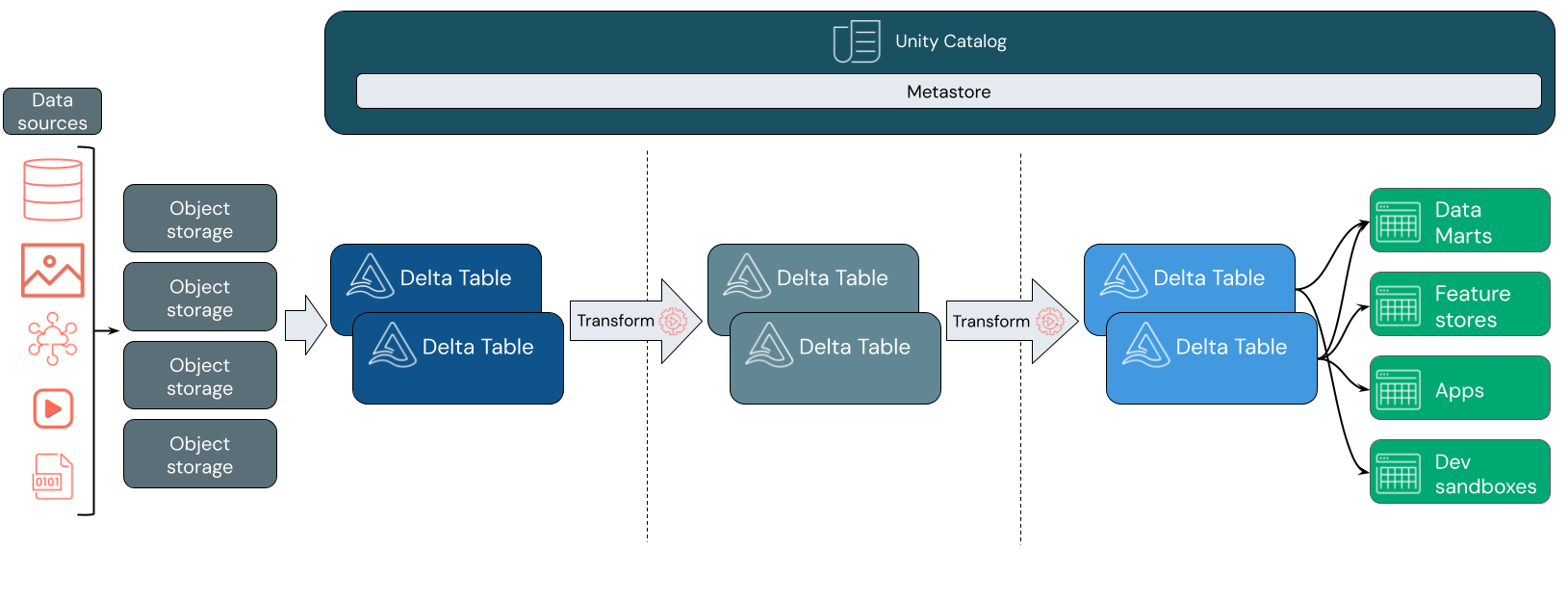
Do czego służy usługa Data Lakehouse?
Usługa Data Lakehouse zapewnia skalowalne możliwości magazynowania i przetwarzania dla nowoczesnych organizacji, które chcą uniknąć izolowanych systemów przetwarzania różnych obciążeń, takich jak uczenie maszynowe (ML) i analiza biznesowa (BI). Usługa Data Lakehouse może pomóc w ustaleniu pojedynczego źródła prawdy, wyeliminowaniu nadmiarowych kosztów i zapewnieniu aktualności danych.
Usługa Data Lakehouse często używa wzorca projektowego danych, który przyrostowo ulepsza, wzbogaca i udoskonala dane podczas przechodzenia przez warstwy przemieszczania i przekształcania. Każda warstwa jeziora może zawierać co najmniej jedną warstwę. Ten wzorzec jest często określany jako architektura medalionu. Aby uzyskać więcej informacji, przejdź do Czym jest architektura lakehouse w stylu medallion?
Jak działa usługa Databricks Lakehouse?
Usługa Databricks jest oparta na platformie Apache Spark. Apache Spark umożliwia wysoce skalowalny aparat, który działa na zasobach obliczeniowych oddzielonych od przechowywania. Aby uzyskać więcej informacji, zobacz Apache Spark w usłudze Azure Databricks
Usługa Databricks Lakehouse korzysta z dwóch dodatkowych kluczowych technologii:
- Delta Lake: zoptymalizowana warstwa magazynu, która obsługuje transakcje ACID i egzekwowanie zasad schematu.
- Katalog Unity: ujednolicone, precyzyjne rozwiązanie do zarządzania danymi i sztuczną inteligencją.
Pozyskiwanie danych
W warstwie pozyskiwania dane wsadowe lub przesyłane strumieniowo pochodzą z różnych źródeł i mają różne formaty. Ta pierwsza warstwa logiczna zapewnia miejsce, w których te dane mają wylądować w formacie nieprzetworzonym. Podczas konwertowania tych plików na tabele Delta możesz użyć funkcji wymuszania schematu w Delta Lake, aby sprawdzić brakujące lub nieoczekiwane dane. Za pomocą katalogu Unity można rejestrować tabele zgodnie z modelem nadzoru danych i wymaganymi granicami izolacji danych. Unity Catalog umożliwia śledzenie pochodzenia danych w trakcie ich przekształcania i udoskonalania, a także stosowanie ujednoliconego modelu zarządzania, aby zapewnić prywatność i bezpieczeństwo danych poufnych.
Przetwarzanie, opracowanie i integracja danych
Po zweryfikowaniu możesz rozpocząć selekcjonowanie i dopracowywanie swoich danych. Analitycy danych i praktycy uczenia maszynowego często pracują z danymi na tym etapie, aby rozpocząć łączenie lub tworzenie nowych funkcji i pełne czyszczenie danych. Po gruntownym oczyszczeniu danych można je zintegrować i zreorganizować w tabelach zaprojektowanych w celu spełnienia określonych potrzeb biznesowych.
Podejście schematu zapisu w połączeniu z możliwościami ewolucji schematu Delta oznacza, że można wprowadzać zmiany w tej warstwie bez konieczności ponownego zapisywania logiki dalszego przetwarzania, która dostarcza dane użytkownikom końcowym.
Obsługa danych
Warstwa końcowa obsługuje czyste, wzbogacone dane użytkownikom końcowym. Ostateczne tabele powinny być zaprojektowane tak, aby obsługiwały dane dla wszystkich przypadków użycia. Ujednolicony model zapewniania ładu oznacza, że możesz śledzić pochodzenie danych z powrotem do pojedynczego źródła prawdy. Układy danych, zoptymalizowane pod kątem różnych zadań, umożliwiają użytkownikom końcowym dostęp do danych dla aplikacji uczenia maszynowego, inżynierii danych oraz analizy biznesowej i raportowania.
Aby dowiedzieć się więcej o Delta Lake, zobacz Co to jest Delta Lake? Aby dowiedzieć się więcej o Katalogu Unity, zobacz Co to jest Katalog Unity?
Możliwości usługi Databricks Lakehouse
Lakehouse zbudowany na Databricks zastępuje bieżącą zależność od jezior danych i magazynów danych dla nowoczesnych firm danych. Niektóre kluczowe zadania, które można wykonać, obejmują:
- przetwarzanie danych w czasie rzeczywistym: Przetwarzanie danych przesyłanych strumieniowo w czasie rzeczywistym w celu natychmiastowej analizy i akcji.
- Integracja danych: Ujednolicenie danych w jednym systemie w celu umożliwienia współpracy i ustanowienia pojedynczego źródła prawdy dla organizacji.
- Ewolucja schematu: Zmodyfikuj schemat danych w czasie, aby dostosować się do zmieniających się potrzeb biznesowych bez zakłócania istniejących potoków danych.
- przekształcenia danych: Korzystanie z platformy Apache Spark i usługi Delta Lake zapewnia szybkość, skalowalność i niezawodność danych.
- Analiza danych i raportowanie: Wykonuj złożone zapytania analityczne za pomocą silnika zoptymalizowanego pod kątem obciążeń związanych z hurtownią danych.
- uczenia maszynowego i sztucznej inteligencji: Stosowanie zaawansowanych technik analitycznych do wszystkich danych. Użyj uczenia maszynowego, aby wzbogacić dane i obsługiwać inne obciążenia.
- Przechowywanie wersji i pochodzenia danych: Utrzymywać historię wersji zestawów danych i śledzić ich pochodzenie, aby zapewnić rozpoznawalność i możliwość śledzenia.
- Zarządzanie danymi: Użyj jednego, zintegrowanego systemu do kontrolowania dostępu do danych i przeprowadzania audytów.
- udostępnianie danych: ułatwia współpracę, umożliwiając udostępnianie wyselekcjonowanych zestawów danych, raportów i szczegółowych informacji między zespołami.
- Analiza operacyjna: Monitorowanie metryk jakości danych, metryk jakości modelu i dryfu przez zastosowanie uczenia maszynowego do danych monitorowania lakehouse.
Lakehouse vs Data Lake vs Data Warehouse
Magazyny danych wspierają podejmowanie decyzji w zakresie analityki biznesowej (BI) od około 30 lat, ewoluując jako zestaw wytycznych projektowych dla systemów kontrolujących przepływ danych. Magazyny danych przedsiębiorstwa optymalizują zapytania dotyczące raportów analizy biznesowej, ale generowanie wyników może potrwać kilka minut lub nawet godzin. Zaprojektowane pod kątem danych, które nie zmieniają się zbyt często, magazyny danych starają się zapobiec konfliktom między zapytaniami uruchamianymi równocześnie. Wiele magazynów danych korzysta z zastrzeżonych formatów, które często ograniczają obsługę uczenia maszynowego. Magazynowanie danych w usłudze Azure Databricks wykorzystuje możliwości usługi Databricks Lakehouse i Databricks SQL. Aby uzyskać więcej informacji, zobacz Co to jest magazynowanie danych w usłudze Azure Databricks?.
Napędzane postępem technologicznym w dziedzinie przechowywania danych oraz wykładniczym wzrostem różnorodności i ilości danych, jeziora danych stały się powszechnie stosowane w ciągu ostatniej dekady. Jeziora danych przechowują i przetwarzają dane w sposób tani i efektywny. Jeziora danych są często definiowane w przeciwieństwie do magazynów danych: magazyn danych dostarcza czyste, ustrukturyzowane dane do analityki biznesowej, podczas gdy jezioro danych trwale i tanio przechowuje dane o dowolnym charakterze w dowolnym formacie. Wiele organizacji korzysta z usług Data Lake do nauki o danych i uczenia maszynowego, ale nie do raportowania analizy biznesowej ze względu na jej niewalidowany charakter.
Usługa Data Lakehouse łączy zalety jezior danych i magazynów danych oraz zapewnia następujące korzyści:
- Otwarty, bezpośredni dostęp do danych przechowywanych w standardowych formatach danych.
- Protokoły indeksowania zoptymalizowane pod kątem uczenia maszynowego i nauki o danych.
- Małe opóźnienia zapytań i wysoka niezawodność analizy biznesowej i zaawansowanej analizy.
Dzięki połączeniu zoptymalizowanej warstwy metadanych ze zweryfikowanymi danymi przechowywanymi w standardowych formatach w magazynie obiektów w chmurze usługa Data Lakehouse umożliwia analitykom danych i inżynierom uczenia maszynowego tworzenie modeli z tych samych raportów analizy biznesowej opartych na danych.
Następny krok
Aby dowiedzieć się więcej o zasadach i najlepszych praktykach dotyczących wdrażania i obsługi architektury lakehouse przy użyciu usługi Databricks, zobacz Introduction to the well-architected data lakehouse