Na czym polega architektura lakehouse typu medallion?
Architektura medalionu opisuje serię warstw danych, które określają jakość danych przechowywanych w lakehouse. Usługa Azure Databricks zaleca zastosowanie wielowarstwowego podejścia do stworzenia jednego źródła prawdy dla produktów danych korporacyjnych.
Ta architektura gwarantuje niepodzielność, spójność, izolację i trwałość, ponieważ dane przechodzą przez wiele warstw weryfikacji i przekształceń przed zapisaniem w układzie zoptymalizowanym pod kątem wydajnej analizy. Terminy brązowe (surowe), srebrne (zweryfikowane) i złote (wzbogacone) opisują jakość danych w każdej z tych warstw.
Architektura medalionu jako wzorzec projektowania danych
Architektura medalionu to wzorzec projektowania danych używany do logicznego organizowania danych. Jej celem jest przyrostowe i stopniowe ulepszanie struktury i jakości danych w miarę ich przepływu przez poszczególne warstwy architektury (od tabel warstwy Bronze ⇒ Silver ⇒ Gold). Architektury medalionowe są czasami określane również jako architektury wieloskokowe.
Postępując zgodnie z postępem danych w tych warstwach, organizacje mogą przyrostowo poprawić jakość i niezawodność danych, dzięki czemu będą bardziej odpowiednie dla aplikacji do analizy biznesowej i uczenia maszynowego.
Stosowanie architektury medalonu jest zalecanym najlepszym rozwiązaniem, ale nie wymaganiem.
| Pytanie | Brąz | Srebrny | Złoty |
|---|---|---|---|
| Co się dzieje w tej warstwie? | Pozyskiwanie nieprzetworzonych danych | Czyszczenie i walidacja danych | Modelowanie wymiarowe i agregacja |
| Kto jest zamierzonym użytkownikiem? | - Inżynierowie danych — Operacje na danych - Zespoły ds. zgodności i inspekcji |
- Inżynierowie danych — Analitycy danych (używają warstwy Silver do bardziej wyrafinowanego zestawu danych, który nadal zachowuje szczegółowe informacje niezbędne do szczegółowej analizy) - Analitycy danych (tworzenie modeli i wykonywanie zaawansowanych analiz) |
— Analitycy biznesowi i deweloperzy analizy biznesowej - Analitycy danych i inżynierowie uczenia maszynowego - Kierownictwo i decydenci - Zespoły operacyjne |
Przykładowa architektura medalionu
W tym przykładzie architektury medalionu przedstawiono brązowe, srebrne i złote warstwy do użycia przez zespół ds. operacji biznesowych. Każda warstwa jest przechowywana w innym schemacie wykazu operacji.
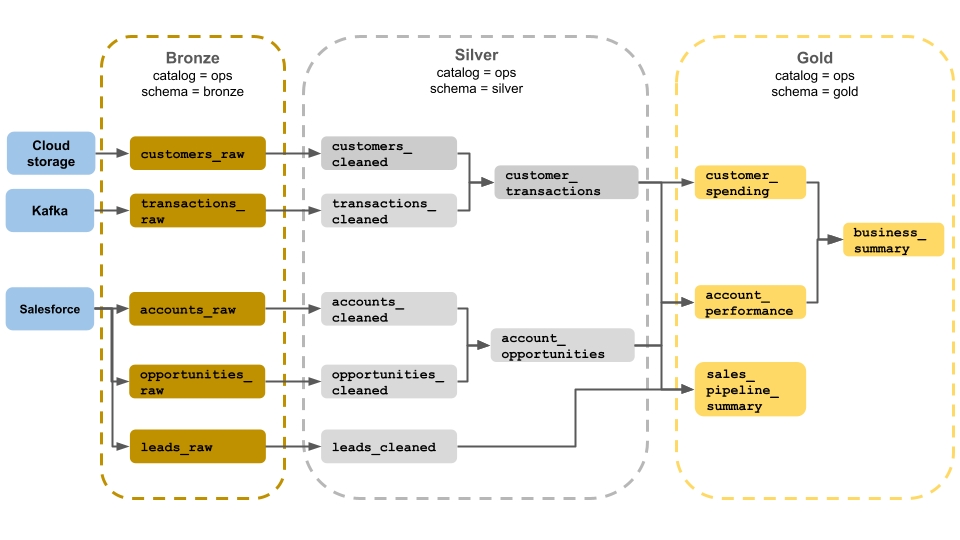
-
Warstwa brązowa (
ops.bronze): Pozyskuje nieprzetworzone dane z magazynu w chmurze, platformy Kafka i usługi Salesforce. W tym miejscu nie jest przeprowadzane czyszczenie danych ani walidacja. -
Warstwa srebrna (
ops.silver): czyszczenie i walidacja danych są wykonywane w tej warstwie.- Dane dotyczące klientów i transakcji są czyszczone przez usuwanie pustych wartości oraz izolowanie nieprawidłowych rekordów. Te zestawy danych są przyłączone do nowego zestawu danych o nazwie
customer_transactions. Analitycy danych mogą używać tego zestawu danych do analizy predykcyjnej. - Podobnie konta i zestawy danych szans sprzedaży z Salesforce są łączone w celu utworzenia
account_opportunities, rozszerzonego o informacje o koncie. - Dane
leads_rawsą czyszczone w zestawie danych o nazwieleads_cleaned.
- Dane dotyczące klientów i transakcji są czyszczone przez usuwanie pustych wartości oraz izolowanie nieprawidłowych rekordów. Te zestawy danych są przyłączone do nowego zestawu danych o nazwie
-
Warstwa złota (
ops.gold): ta warstwa jest przeznaczona dla użytkowników biznesowych. Zawiera mniej zestawów danych niż srebro i złoto.-
customer_spending: Średnie i łączne wydatki dla każdego klienta. -
account_performance: Dzienna wydajność dla każdego konta. -
sales_pipeline_summary: informacje na temat kompleksowego potoku sprzedaży. -
business_summary: Wysoce zagregowane informacje dla kadry kierowniczej.
-
Pozyskiwanie danych pierwotnych do warstwy z brązu
Warstwa brązowa zawiera nieprzetworzone, niewalidowane dane. Dane pozyskane w warstwie brązu zwykle mają następujące cechy:
- Zawiera i utrzymuje stan pierwotny źródła danych w oryginalnych formatach.
- Dołączany jest stopniowo i rośnie wraz z upływem czasu.
- Jest przeznaczony do użycia przez obciążenia, które wzbogacają dane dla silver tables, a nie do uzyskiwania dostępu przez analityków i naukowców danych.
- Służy jako pojedyncze źródło prawdy, zachowując wierność danych.
- Umożliwia ponowne przetwarzanie i inspekcję przez przechowywanie wszystkich danych historycznych.
- Może to być dowolna kombinacja transakcji strumieniowych i wsadowych ze źródeł, w tym magazynu obiektów w chmurze (na przykład S3, GCS, ADLS), magistrali komunikatów (na przykład Kafka, Kinesis itp.) i systemów federacyjnych (na przykład federacja Lakehouse).
Ograniczanie oczyszczania lub walidacji danych
Minimalna weryfikacja danych jest wykonywana w warstwie brązowej. Aby zapewnić ochronę przed porzuconymi danymi, usługa Azure Databricks zaleca przechowywanie większości pól jako ciągów, wariantów lub plików binarnych w celu ochrony przed nieoczekiwanymi zmianami schematu. Kolumny metadanych mogą być dodawane, takie jak pochodzenie lub źródło danych (na przykład _metadata.file_name ).
Weryfikowanie i deduplikowanie danych w warstwie srebrnej
Czyszczenie i walidacja danych są wykonywane w warstwie srebrnej.
Tworzenie srebrnych stołów z warstwy z brązu
Aby utworzyć warstwę srebrną, odczytaj dane z co najmniej jednej tabeli z brązu lub srebra i zapisuj dane do tabel srebrnych.
Usługa Azure Databricks nie zaleca pisania bezpośrednio do srebrnych tabel z procesu pozyskiwania danych. Jeśli zapisujesz bezpośrednio z pozyskiwania, wprowadzisz błędy spowodowane zmianami schematu lub uszkodzonymi rekordami w źródłach danych. Zakładając, że wszystkie źródła są tylko dołączane, skonfiguruj większość odczytów z brązu jako odczyty strumieniowe. Operacje odczytu wsadowego powinny być zarezerwowane dla małych zestawów danych (na przykład tabel o małych wymiarach).
Warstwa srebrna reprezentuje zweryfikowane, oczyszczone i wzbogacone wersje danych. Warstwa srebra:
- Zawsze należy uwzględnić co najmniej jedną zweryfikowaną, niegregowaną reprezentację każdego rekordu. Jeśli reprezentacje zagregowane napędzają wiele obciążeń podrzędnych, te reprezentacje mogą znajdować się w warstwie srebrnej, ale zazwyczaj znajdują się w warstwie złota.
- To miejsce, w którym wykonujesz czyszczenie danych, deduplikację i normalizację.
- Poprawia jakość danych, poprawiając błędy i niespójności.
- Strukturyzuje dane w bardziej przystępnym formacie do dalszego przetwarzania.
Wymuszanie jakości danych
W tabelach silver są wykonywane następujące operacje:
- Wymuszanie schematów
- Obsługa wartości null i brakujących wartości
- Deduplikacja danych
- Rozwiązywanie problemów z danymi nieuporządkowanymi i późno przybywającymi
- Kontrole jakości danych i egzekwowanie
- Ewolucja schematu
- Rzutowanie typów
- Połączenia
Rozpoczynanie modelowania danych
Często rozpoczyna się modelowanie danych w warstwie srebrnej, w tym wybieranie sposobu reprezentowania silnie zagnieżdżonych lub częściowo ustrukturyzowanych danych:
- Użyj
VARIANTtypu danych. - Użyj
JSONciągów. - Tworzenie struktur, map i tablic.
- Spłaszczanie schematu lub normalizacja danych w wielu tabelach.
Analiza zużycia energii z warstwą złota
Warstwa złota reprezentuje wysoce wyrafinowane widoki danych, które napędzają analizę podrzędną, pulpity nawigacyjne, uczenie maszynowe i aplikacje. Dane warstwy złotej są często wysoce agregowane i filtrowane dla określonych okresów lub regionów geograficznych. Zawiera on semantycznie znaczące zestawy danych, które są mapowane na funkcje i potrzeby biznesowe.
Warstwa złota:
- Składa się z zagregowanych danych dostosowanych do analizy i raportowania.
- Jest zgodna z logiką biznesową i wymaganiami.
- Jest zoptymalizowany pod kątem wydajności zapytań i dashboardów.
Dopasowanie do logiki biznesowej i wymagań
Warstwa złota to miejsce, w którym modelujesz dane na potrzeby raportowania i analizy przy użyciu modelu wymiarowego, ustanawiając relacje i definiując miary. Analitycy z dostępem do danych w złocie powinni mieć możliwość znajdowania danych specyficznych dla domeny i odpowiadania na pytania.
Ponieważ warstwa złota modeluje domenę biznesową, niektórzy klienci tworzą wiele warstw złota, aby spełnić różne potrzeby biznesowe, takie jak kadry, finanse i dział IT.
Tworzenie agregacji dostosowanych do analizy i raportowania
Organizacje często muszą tworzyć funkcje agregujące dla miar, takich jak średnie, liczby, maksimum i minimum. Jeśli na przykład twoja firma musi odpowiedzieć na pytania dotyczące łącznej sprzedaży tygodniowej, możesz utworzyć zmaterializowany widok o nazwie weekly_sales , który poprzedza te dane, aby analitycy i inni nie musieli ponownie tworzyć często używanych zmaterializowanych widoków.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optymalizowanie pod kątem wydajności zapytań i pulpitów nawigacyjnych
Optymalizacja tabel warstw złota pod kątem wydajności jest najlepszym rozwiązaniem, ponieważ te zestawy danych są często odpytywane. Duże ilości danych historycznych są zwykle dostępne w warstwie sliver i nie są materializowane w warstwie złota.
Kontrolowanie kosztów przez dostosowanie częstotliwości pozyskiwania danych
Kontrolowanie kosztów przez określenie, jak często pozyskiwać dane.
| Częstotliwość pozyskiwania danych | Koszt | Opóźnienie | Przykłady deklaratywne | Przykłady proceduralne |
|---|---|---|---|---|
| Ciągłe pozyskiwanie przyrostowe | Wyższa | Obniżyć | — Tabela strumieniowa używająca spark.readStream do pozyskiwania z magazynu w chmurze lub magistrali komunikatów.— Proces przetwarzania DLT, który aktualizuje tę tabelę strumieniową, działa w sposób ciągły. — Kod używany do strukturalnego przetwarzania danych strumieniowych z pomocą spark.readStream w notesie do pobierania danych z magazynu w chmurze lub z magistrali komunikatów do tabeli Delta.— Notatnik jest zarządzany za pomocą zadania usługi Azure Databricks z ciągłym wyzwalaczem. |
|
| Wyzwalane pozyskiwanie przyrostowe | niższy | Wyższa | — Przesyłanie danych tabel z magazynu w chmurze lub magistrali komunikatów przy użyciu spark.readStream.— Rurociąg, który aktualizuje tę tabelę strumieniową, jest uruchamiany przez wyzwalacz zaplanowanego zadania lub wyzwalacz przybycia pliku. — Kod przesyłania strumieniowego ze strukturą w notesie z wyzwalaczem Trigger.Available .— Ten notatnik jest uruchamiany przez zaplanowane zadanie lub przybycie pliku. |
|
| Pozyskiwanie wsadowe przy użyciu ręcznego pozyskiwania przyrostowego | Niższy | Najwyższy, z powodu rzadkich uruchomień. | — Ingestowanie tabel za pomocą przesyłania strumieniowego z magazynu w chmurze przy użyciu spark.read.— Nie używa Strukturalnego przesyłania strumieniowego. Zamiast tego użyj elementów pierwotnych, takich jak zastępowanie partycji, aby jednocześnie zaktualizować całą partycję. — Wymaga rozbudowanej architektury nadrzędnej w celu skonfigurowania przetwarzania przyrostowego, co pozwala na koszt podobny do odczytu/zapisu ze strukturą przesyłania strumieniowego. — Wymaga również partycjonowania danych źródłowych według datetime pola, a następnie przetwarzania wszystkich rekordów z tej partycji do obiektu docelowego. |