Używanie transformacji dbt w zadaniu usługi Azure Databricks
Projekty dbt Core można uruchamiać jako zadanie w zadaniu usługi Azure Databricks. Uruchamiając projekt dbt Core jako zadanie zadania, możesz skorzystać z następujących funkcji zadań usługi Azure Databricks:
- Automatyzowanie zadań dbt i planowanie przepływów pracy obejmujących zadania dbt.
- Monitoruj przekształcenia dbt i wysyłaj powiadomienia o stanie przekształceń.
- Uwzględnij projekt dbt w przepływie pracy z innymi zadaniami. Na przykład przepływ pracy może pozyskiwać dane za pomocą modułu automatycznego ładowania, przekształcać dane za pomocą dbt i analizować dane za pomocą zadania notesu.
- Automatyczne archiwizowanie artefaktów z przebiegów zadań, w tym dzienników, wyników, manifestów i konfiguracji.
Aby dowiedzieć się więcej na temat bazy danych dbt Core, zobacz dokumentację bazy danych.
Przepływ pracy tworzenia i produkcji
Usługa Databricks zaleca opracowywanie projektów dbt w usłudze Databricks SQL Warehouse. Korzystając z usługi Databricks SQL Warehouse, możesz przetestować bazę danych SQL wygenerowaną przez bazę danych i użyć historii zapytań usługi SQL Warehouse do debugowania zapytań generowanych przez bazę danych.
Aby uruchomić przekształcenia dbt w środowisku produkcyjnym, usługa Databricks zaleca użycie zadania dbt w zadaniu usługi Databricks. Domyślnie zadanie dbt uruchamia proces dbt python przy użyciu obliczeń usługi Azure Databricks i dbt wygenerowany sql względem wybranego magazynu SQL.
Przekształcenia dbt można uruchamiać w bezserwerowym magazynie SQL Warehouse lub pro SQL Warehouse, obliczeniach usługi Azure Databricks lub innym magazynie obsługiwanym przez bazę danych. W tym artykule omówiono dwie pierwsze opcje z przykładami.
Jeśli obszar roboczy jest włączony w wykazie aparatu Unity, a zadania bezserwerowe są domyślnie włączone, zadanie jest uruchamiane na obliczeniach bezserwerowych.
Uwaga
Tworzenie modeli dbt w usłudze SQL Warehouse i uruchamianie ich w środowisku produkcyjnym w obliczeniach usługi Azure Databricks może prowadzić do subtelnych różnic w wydajności i obsłudze języka SQL. Usługa Databricks zaleca używanie tej samej wersji środowiska Databricks Runtime dla obliczeń i magazynu SQL.
Wymagania
Aby dowiedzieć się, jak używać bazy danych dbt Core i
dbt-databrickspakietu do tworzenia i uruchamiania projektów dbt w środowisku projektowym, zobacz Nawiązywanie połączenia z bazą danych dbt Core.Usługa Databricks zaleca pakiet dbt-databricks , a nie pakiet dbt-spark. Pakiet dbt-databricks to rozwidlenie bazy danych dbt-spark zoptymalizowane pod kątem usługi Databricks.
Aby używać projektów dbt w zadaniu usługi Azure Databricks, należy skonfigurować integrację usługi Git dla folderów git usługi Databricks. Nie można uruchomić projektu dbt z systemu plików DBFS.
Musisz mieć włączone usługi bezserwerowe lub pro SQL Warehouse.
Musisz mieć uprawnienie sql usługi Databricks.
Tworzenie i uruchamianie pierwszego zadania dbt
W poniższym przykładzie użyto projektu jaffle_shop , przykładowego projektu, który demonstruje podstawowe pojęcia dbt. Aby utworzyć zadanie uruchamiające projekt sklepu jaffle, wykonaj następujące kroki.
Przejdź do strony docelowej usługi Azure Databricks i wykonaj jedną z następujących czynności:
- Kliknij pozycję
 Przepływy pracy na pasku bocznym i kliknij pozycję .
Przepływy pracy na pasku bocznym i kliknij pozycję .
- Na pasku bocznym kliknij pozycję
 Nowy i wybierz pozycję Zadanie.
Nowy i wybierz pozycję Zadanie.
- Kliknij pozycję
W polu tekstowym zadania na karcie Zadania zastąp ciąg Dodaj nazwę zadania... nazwą zadania.
W polu Nazwa zadania wprowadź nazwę zadania.
W polu Typ wybierz typ zadania dbt .
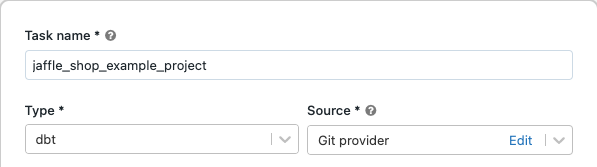
W menu rozwijanym Źródło możesz wybrać pozycję Obszar roboczy, aby użyć projektu dbt znajdującego się w folderze obszaru roboczego usługi Azure Databricks lub dostawcy git dla projektu znajdującego się w zdalnym repozytorium Git. Ponieważ w tym przykładzie użyto projektu sklepu jaffle znajdującego się w repozytorium Git, wybierz pozycję Dostawca Git, kliknij pozycję Edytuj i wprowadź szczegóły repozytorium GitHub sklepu jaffle.
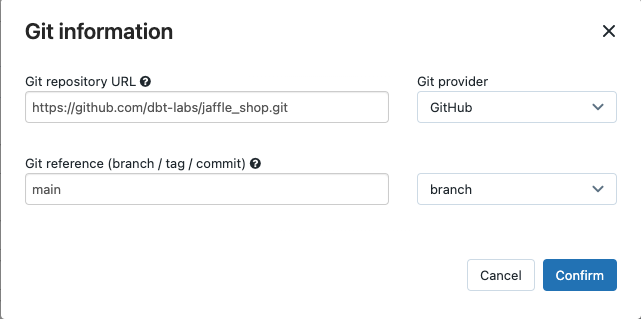
- W polu Adres URL repozytorium Git wprowadź adres URL projektu sklepu jaffle.
- W dokumentacji git (gałąź / tag / zatwierdzenie), wprowadź .
mainMożesz również użyć tagu lub algorytmu SHA.
Kliknij przycisk Potwierdź.
W polach tekstowych poleceń dbt określ polecenia dbt do uruchomienia (deps, seed i run). Należy prefiksować każde polecenie za pomocą
dbtpolecenia . Polecenia są uruchamiane w określonej kolejności.
W usłudze SQL Warehouse wybierz usługę SQL Warehouse, aby uruchomić bazę danych SQL wygenerowaną przez bazę danych. W menu rozwijanym usługi SQL Warehouse są wyświetlane tylko bezserwerowe i pro magazyny SQL.
(Opcjonalnie) Możesz określić schemat danych wyjściowych zadania. Domyślnie jest używany schemat
default.(Opcjonalnie) Jeśli chcesz zmienić konfigurację obliczeniową z systemem dbt Core, kliknij pozycję dbt CLI compute.
(Opcjonalnie) Dla zadania można określić wersję dbt-databricks. Aby na przykład przypiąć zadanie dbt do określonej wersji programowania i produkcji:
- W obszarze Biblioteki zależne kliknij obok
 bieżącej wersji dbt-databricks.
bieżącej wersji dbt-databricks. - Kliknij przycisk Dodaj.
-
W oknie dialogowym Dodawanie biblioteki zależnej wybierz pozycję PyPI i wprowadź wersję dbt-package w polu tekstowym Pakiet (na przykład
dbt-databricks==1.6.0). - Kliknij przycisk Dodaj.

Uwaga
Usługa Databricks zaleca przypinanie zadań dbt do określonej wersji pakietu dbt-databricks, aby upewnić się, że ta sama wersja jest używana do uruchamiania programowania i produkcji. Usługa Databricks zaleca wersję 1.6.0 lub nowszą pakietu dbt-databricks.
- W obszarze Biblioteki zależne kliknij obok
Kliknij pozycję Utwórz.
Aby uruchomić zadanie teraz, kliknij pozycję
 .
.
Wyświetlanie wyników zadania zadania dbt
Po zakończeniu zadania możesz przetestować wyniki, uruchamiając zapytania SQL z notesu lub uruchamiając zapytania w magazynie usługi Databricks. Zobacz na przykład następujące przykładowe zapytania:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Zastąp <schema> ciąg nazwą schematu skonfigurowaną w konfiguracji zadania.
Przykład interfejsu API
Interfejs API zadań umożliwia również tworzenie zadań obejmujących zadania dbt i zarządzanie nimi. Poniższy przykład tworzy zadanie z pojedynczym zadaniem dbt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Zaawansowane) Uruchamianie bazy danych z profilem niestandardowym
Aby uruchomić zadanie dbt za pomocą usługi SQL Warehouse (zalecane) lub obliczeniowego ogólnego przeznaczenia, użyj niestandardowego profiles.yml definiującego magazyn lub zasoby obliczeniowe usługi Azure Databricks, aby nawiązać połączenie. Aby utworzyć zadanie uruchamiające projekt sklepu jaffle z magazynem lub obliczeniami ogólnego przeznaczenia, wykonaj następujące kroki.
Uwaga
Jako obiekt docelowy zadania dbt można używać tylko usługi SQL Warehouse lub obliczeniowego ogólnego przeznaczenia. Nie można używać obliczeń zadań jako elementu docelowego dla dbt.
Utwórz rozwidlenie repozytorium jaffle_shop .
Sklonuj rozwidlenie repozytorium na pulpicie. Można na przykład uruchomić polecenie podobne do następującego:
git clone https://github.com/<username>/jaffle_shop.gitZastąp
<username>ciąg uchwytem usługi GitHub.Utwórz nowy plik o nazwie
profiles.ymlwjaffle_shopkatalogu z następującą zawartością:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Zastąp
<schema>ciąg nazwą schematu tabel projektu. - Aby uruchomić zadanie dbt z usługą SQL Warehouse, zastąp
<http-host>ciąg wartością Nazwa hosta serwera na karcie Szczegóły połączenia dla usługi SQL Warehouse. Aby uruchomić zadanie dbt z obliczeniami all-purpose, zastąp<http-host>wartość Server Hostname wartością Advanced Options (Opcje zaawansowane), kartą JDBC/ODBC dla obliczeń usługi Azure Databricks. - Aby uruchomić zadanie dbt z usługą SQL Warehouse, zastąp
<http-path>wartość ścieżką HTTP na karcie Szczegóły połączenia dla usługi SQL Warehouse. Aby uruchomić zadanie dbt z obliczeniami wszystkich celów, zastąp<http-path>wartość ścieżki HTTP z karty Opcje zaawansowane JDBC/ODBC dla obliczeń usługi Azure Databricks.
Nie określasz wpisów tajnych, takich jak tokeny dostępu, w pliku, ponieważ ten plik zostanie zaewidencjonowyny w kontroli źródła. Zamiast tego ten plik używa funkcji tworzenia szablonów dbt do dynamicznego wstawiania poświadczeń w czasie wykonywania.
Uwaga
Wygenerowane poświadczenia są prawidłowe przez czas trwania przebiegu do maksymalnie 30 dni i są automatycznie odwołyne po zakończeniu.
- Zastąp
Sprawdź ten plik w usłudze Git i wypchnij go do rozwidlenia repozytorium. Można na przykład uruchomić polecenia podobne do następujących:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushKliknij pozycję
Przepływy pracy na pasku bocznym interfejsu użytkownika usługi Databricks.Wybierz zadanie dbt i kliknij kartę Zadania .
W obszarze Źródło kliknij pozycję Edytuj i wprowadź szczegóły rozwidlenia sklepu jaffle w witrynie GitHub.
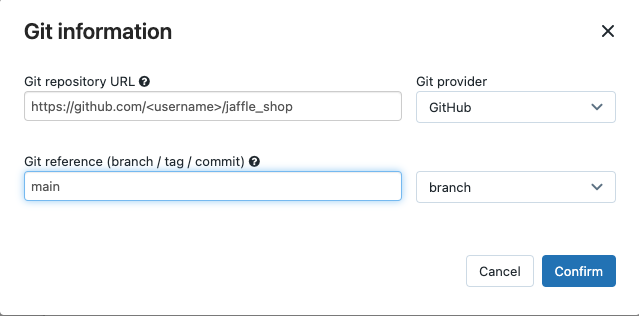
W usłudze SQL Warehouse wybierz pozycję Brak (ręczne).
W katalogu profiles wprowadź ścieżkę względną do katalogu zawierającego
profiles.ymlplik. Pozostaw wartość ścieżki pustą, aby użyć wartości domyślnej katalogu głównego repozytorium.
(Zaawansowane) Używanie modeli dbt Python w przepływie pracy
Uwaga
Obsługa dbt dla modeli języka Python jest w wersji beta i wymaga bazy danych dbt 1.3 lub nowszej.
Usługa dbt obsługuje teraz modele języka Python w określonych magazynach danych, w tym w usłudze Databricks. Za pomocą modeli języka Python dbt można używać narzędzi z ekosystemu języka Python do implementowania przekształceń, które są trudne do zaimplementowania przy użyciu języka SQL. Możesz utworzyć zadanie usługi Azure Databricks w celu uruchomienia pojedynczego zadania z modelem dbt Python lub dołączyć zadanie dbt jako część przepływu pracy obejmującego wiele zadań.
Nie można uruchamiać modeli języka Python w zadaniu dbt przy użyciu usługi SQL Warehouse. Aby uzyskać więcej informacji na temat używania modeli dbt Python w usłudze Azure Databricks, zobacz Określone magazyny danych w dokumentacji bazy danych.
Błędy i rozwiązywanie problemów
Plik profilu nie istnieje błąd
Komunikat o błędzie:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Możliwe przyczyny:
Nie profiles.yml można odnaleźć pliku w określonym $PATH. Upewnij się, że katalog główny projektu dbt zawiera plik profiles.yml.