Ocena wydajności: Metryki, które mają znaczenie
W tym artykule opisano pomiar wydajności aplikacji RAG pod kątem jakości pobierania, odpowiedzi i wydajności systemu.
Pobieranie, odpowiedź i wydajność
Za pomocą zestawu oceny można zmierzyć wydajność aplikacji RAG w wielu różnych wymiarach, w tym:
- Jakość pobierania: Metryki pobierania oceniają, jak pomyślnie aplikacja RAG pobiera odpowiednie dane pomocnicze. Precyzja i kompletność to dwie kluczowe metryki pobierania.
- Jakość odpowiedzi: Metryki jakości odpowiedzi oceniają, jak dobrze aplikacja RAG odpowiada na żądanie użytkownika. Metryki odpowiedzi mogą na przykład mierzyć, jeśli wynikowa odpowiedź jest dokładna zgodnie z prawdą, jak dobrze uziętą odpowiedź otrzymała pobrany kontekst (na przykład czy halucynat LLM?) lub jak bezpieczna była odpowiedź (innymi słowy, brak toksyczności).
- Wydajność systemu (koszt i opóźnienie): Metryki przechwytują ogólny koszt i wydajność aplikacji RAG. Ogólne opóźnienie i użycie tokenu to przykłady metryk wydajności łańcucha.
Bardzo ważne jest zbieranie metryk odpowiedzi i pobierania. Aplikacja RAG może reagować źle pomimo pobierania poprawnego kontekstu; może również zapewnić dobre odpowiedzi na podstawie wadliwych pobierania. Tylko poprzez pomiar obu składników możemy dokładnie zdiagnozować i rozwiązać problemy w aplikacji.
Podejścia do mierzenia wydajności
Istnieją dwa kluczowe podejścia do mierzenia wydajności w tych metrykach:
- Miara deterministyczna: Metryki kosztów i opóźnień można obliczyć deterministycznie na podstawie danych wyjściowych aplikacji. Jeśli zestaw oceny zawiera listę dokumentów, które zawierają odpowiedź na pytanie, można również obliczyć podzbiór metryk pobierania.
- Pomiar oparty na sędziach LLM: W tym podejściu oddzielny moduł LLM działa jako sędzia w celu oceny jakości pobierania i odpowiedzi aplikacji RAG. Niektórzy sędziowie LLM, tacy jak poprawność odpowiedzi, porównują prawdę podstaw z etykietą człowieka a dane wyjściowe aplikacji. Inni sędziowie LLM, tacy jak uziemienie, nie wymagają od człowieka podstawy prawdy, aby ocenić swoje dane wyjściowe aplikacji.
Ważne
Aby sędzia LLM był skuteczny, należy go dostroić, aby zrozumieć przypadek użycia. Wymaga to starannej uwagi, aby zrozumieć, gdzie sędzia nie działa i nie działa dobrze, a następnie dostrajając sędziego, aby poprawić go w sprawach niepowodzeń.
Ocena agenta mozaiki sztucznej inteligencji zapewnia wbudowaną implementację przy użyciu hostowanych modeli sędziów LLM dla każdej metryki omówionej na tej stronie. W dokumentacji oceny agenta omówiono szczegóły wdrażania tych metryk i sędziów oraz możliwości dostosowywania sędziów do danych w celu zwiększenia ich dokładności
Omówienie metryk
Poniżej przedstawiono podsumowanie metryk zalecanych przez usługę Databricks do mierzenia jakości, kosztów i opóźnień aplikacji RAG. Te metryki są implementowane w narzędziu Mosaic AI Agent Evaluation.
| Wymiar | Nazwa metryki | Pytanie | Mierzony przez | Potrzebuje podstawowej prawdy? |
|---|---|---|---|---|
| Pobieranie | chunk_relevance/precyzja | Jaki procent pobranych fragmentów jest istotny dla żądania? | Sędzia LLM | Nie. |
| Pobieranie | document_recall | Jaki procent dokumentów podstawowych prawdy są reprezentowane we pobranych fragmentach? | Deterministyczny | Tak |
| Response | dokładność | Ogólnie rzecz biorąc, czy agent wygenerował poprawną odpowiedź? | Sędzia LLM | Tak |
| Response | relevance_to_query | Czy odpowiedź dotyczy żądania? | Sędzia LLM | Nie. |
| Response | uzięcie | Czy odpowiedź jest halucynacją, czy uziemiona w kontekście? | Sędzia LLM | Nie. |
| Response | bezpieczeństwo | Czy w odpowiedzi znajduje się szkodliwa zawartość? | Sędzia LLM | Nie. |
| Koszty | total_token_count, total_input_token_count, total_output_token_count | Jaka jest łączna liczba tokenów dla generacji LLM? | Deterministyczny | Nie. |
| Opóźnienie | latency_seconds | Jakie jest opóźnienie wykonywania aplikacji? | Deterministyczny | Nie. |
Jak działają metryki pobierania
Metryki pobierania pomagają zrozumieć, czy usługa retriever dostarcza odpowiednie wyniki. Metryki pobierania są oparte na precyzji i kompletności.
| Nazwa metryki | Odpowiedź na pytanie | Szczegóły |
|---|---|---|
| Dokładność | Jaki procent pobranych fragmentów jest istotny dla żądania? | Precyzja to proporcja pobranych dokumentów, które są rzeczywiście istotne dla żądania użytkownika. Sędzia LLM może służyć do oceny istotności każdego pobranego fragmentu żądania użytkownika. |
| Odwołaj | Jaki procent dokumentów podstawowych prawdy są reprezentowane we pobranych fragmentach? | Kompletność to proporcja dokumentów podstawowych prawdy, które są reprezentowane w pobranych fragmentach. Jest to miara kompletności wyników. |
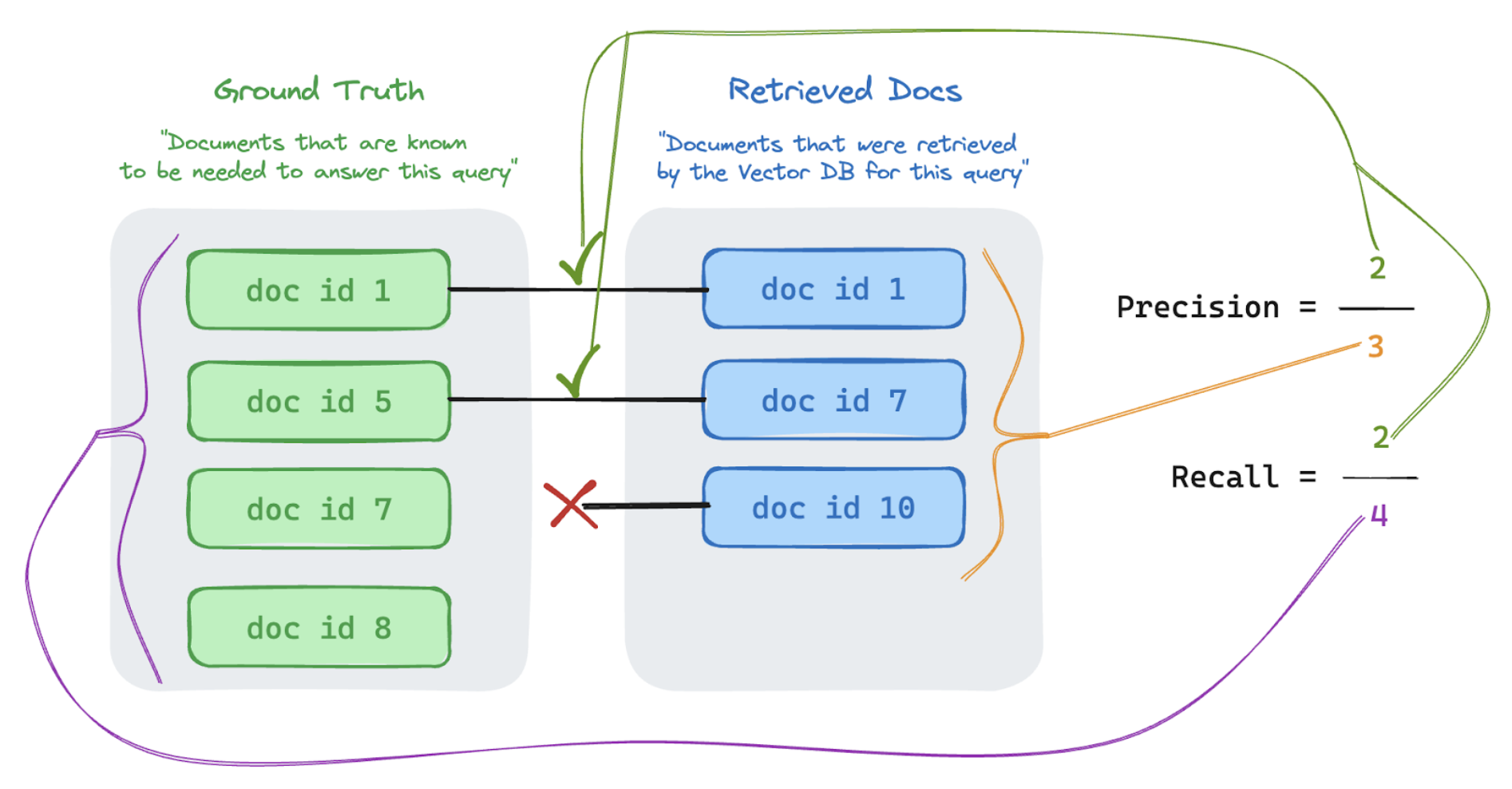
Precyzja i kompletność
Poniżej znajduje się szybki podkład na precyzję i kompletność zaadaptowana z doskonałego artykułu w Wikipedii.
Formuła precyzji
Miary precyzji "Z pobranych fragmentów, jaki procent tych elementów są rzeczywiście istotne dla zapytania mojego użytkownika?" Precyzja obliczeniowa nie wymaga znajomości wszystkich odpowiednich elementów.
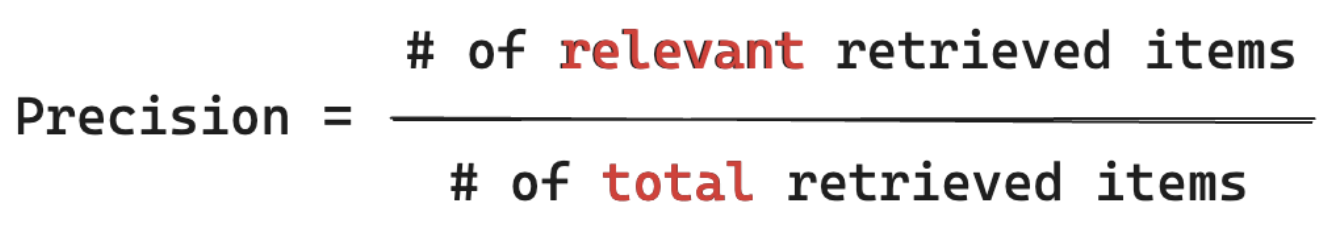
Formuła odwołania
Przypomnij sobie miary "Ze wszystkich dokumentów, które wiem, są istotne dla zapytania mojego użytkownika, z jakiego procentu pobrałem fragment?" Kompletność obliczeń wymaga, aby podstawowe informacje zawierały wszystkie istotne elementy. Elementy mogą być dokumentem lub fragmentem dokumentu.
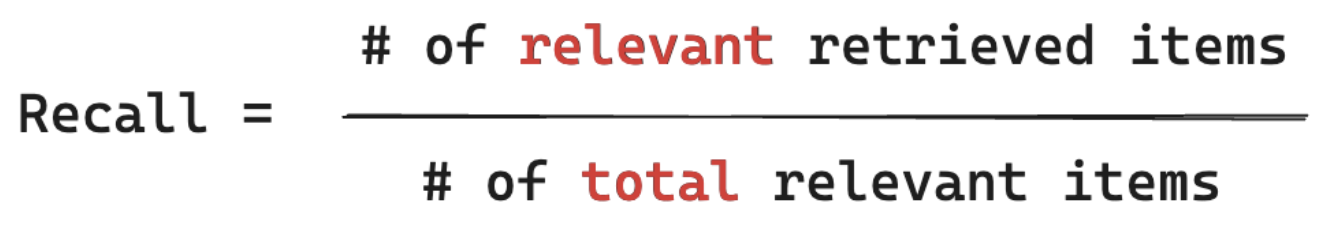
W poniższym przykładzie dwa z trzech pobranych wyników były istotne dla zapytania użytkownika, więc precyzja wynosiła 0,66 (2/3). Pobrane dokumenty zawierały dwie z czterech odpowiednich dokumentów, więc kompletność wynosiła 0,5 (2/4).