Jak jakość, koszt i opóźnienie są oceniane przez ocenę agenta
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
W tym artykule wyjaśniono, w jaki sposób ocena agenta ocenia jakość, koszt i opóźnienie aplikacji sztucznej inteligencji oraz udostępnia szczegółowe informacje na temat ulepszeń jakości oraz optymalizacji kosztów i opóźnień. Obejmuje ona następujące kwestie:
- Jak jakość jest oceniana przez sędziów LLM.
- Sposób oceniania kosztów i opóźnień.
- Jak metryki są agregowane na poziomie przebiegu platformy MLflow pod kątem jakości, kosztów i opóźnień.
Aby uzyskać informacje referencyjne dotyczące poszczególnych wbudowanych sędziów LLM, zobacz Wbudowani sędziowie AI.
Jak jakość jest oceniana przez sędziów LLM
Ocena agenta ocenia jakość przy użyciu sędziów LLM w dwóch krokach:
- Sędziowie LLM oceniają konkretne aspekty jakości (takie jak poprawność i uziemienia) dla każdego wiersza. Aby uzyskać szczegółowe informacje, zobacz Krok 1: Sędziowie LLM oceniają jakość każdego wiersza.
- Ocena agenta łączy oceny poszczególnych sędziów w ogólny wynik powodzenia/niepowodzenia i główną przyczynę wszelkich niepowodzeń. Aby uzyskać szczegółowe informacje, zobacz Krok 2. Łączenie ocen sędziów LLM w celu zidentyfikowania głównej przyczyny problemów z jakością.
Aby uzyskać informacje o zaufaniu i bezpieczeństwie sędziego LLM, zobacz Informacje o modelach, które napędzają sędziów LLM.
Notatka
W przypadku rozmów wielozmianowych sędziowie LLM oceniają tylko ostatni wpis.
Krok 1. Sędziowie LLM oceniają jakość każdego wiersza
W przypadku każdego wiersza danych wejściowych ocena agenta używa zestawu sędziów LLM do oceny różnych aspektów jakości danych wyjściowych agenta. Każdy sędzia generuje wynik tak lub nie i pisemne uzasadnienie dla tego wyniku, jak pokazano w poniższym przykładzie:

Aby uzyskać szczegółowe informacje na temat używanych sędziów LLM, zobacz Wbudowane sędziowie AI.
Krok 2. Łączenie ocen sędziów LLM w celu zidentyfikowania głównej przyczyny problemów z jakością
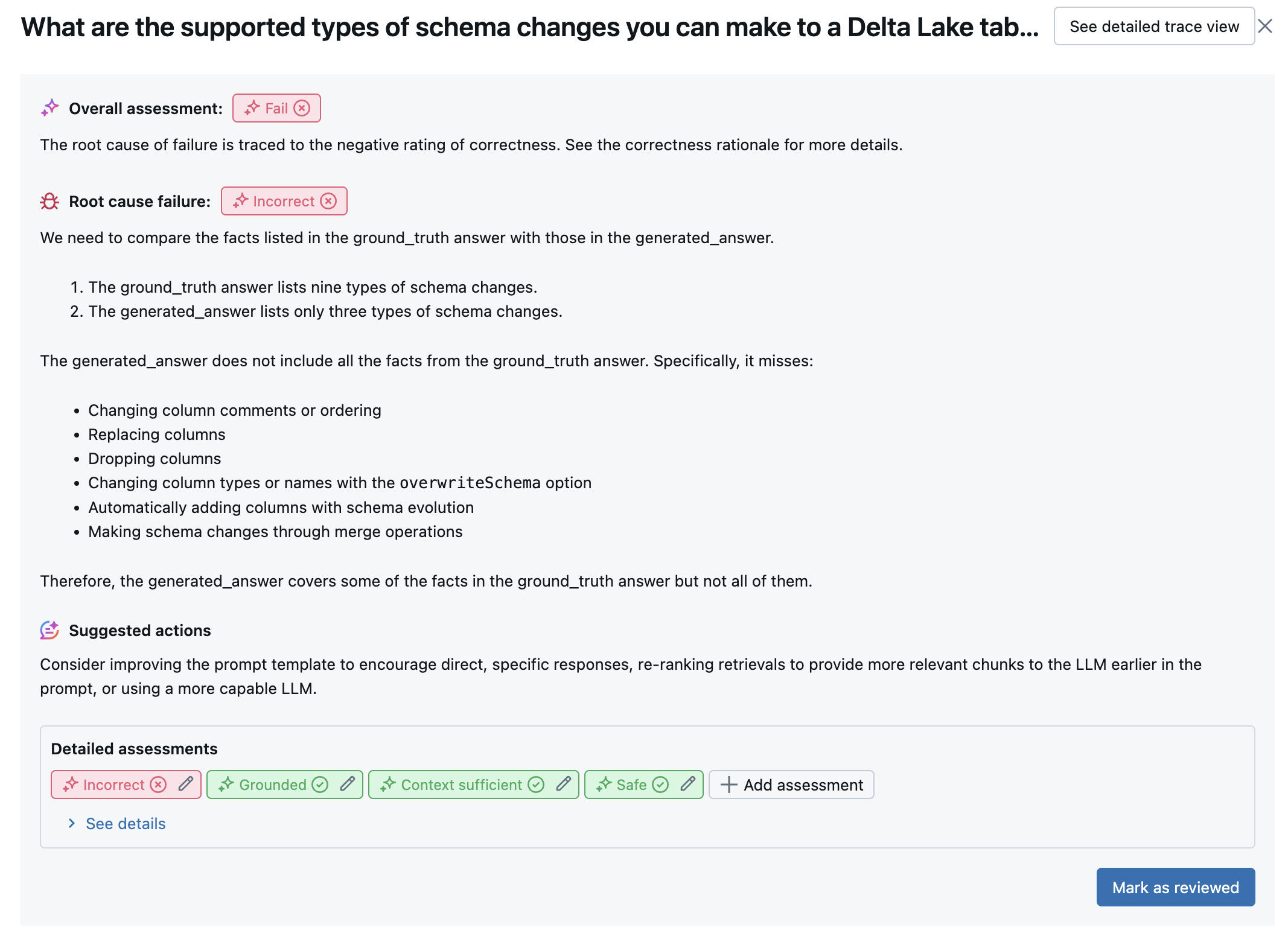
Po uruchomieniu sędziów LLM ocena agenta analizuje swoje dane wyjściowe, aby ocenić ogólną jakość i określić ocenę jakości pass/fail na zbiorczych ocenach sędziego. Jeśli ogólna jakość nie powiedzie się, ocena agenta identyfikuje, który konkretny sędzia LLM spowodował awarię i zawiera sugerowane poprawki.
Dane są wyświetlane w interfejsie użytkownika platformy MLflow i są również dostępne w przebiegu MLflow w ramce mlflow.evaluate(...) danych zwracanej przez wywołanie. Zobacz dane wyjściowe oceny, aby uzyskać szczegółowe informacje na temat uzyskiwania dostępu do ramki danych.
Poniższy zrzut ekranu jest przykładem analizy podsumowania w interfejsie użytkownika:

Wyniki dla każdego wiersza są dostępne w interfejsie użytkownika widoku szczegółów:
wbudowanych sędziów sztucznej inteligencji
Zobacz sędziów sztucznej inteligencji, aby uzyskać szczegółowe informacje na temat wbudowanych sędziów sztucznej inteligencji dostarczonych przez Mosaic AI Agent Evaluation.
Na poniższych zrzutach ekranu przedstawiono przykłady wyświetlania tych sędziów w interfejsie użytkownika:
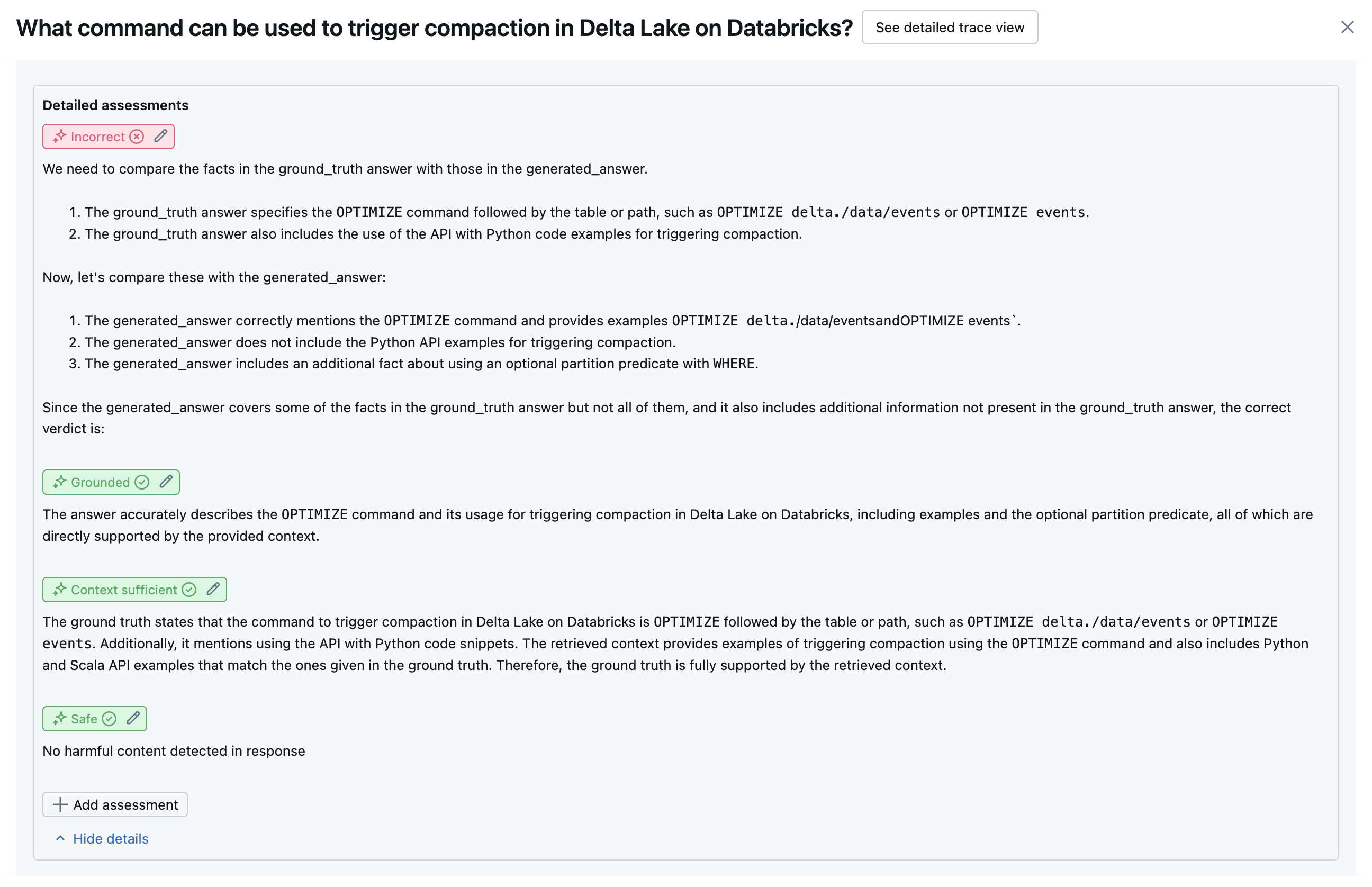
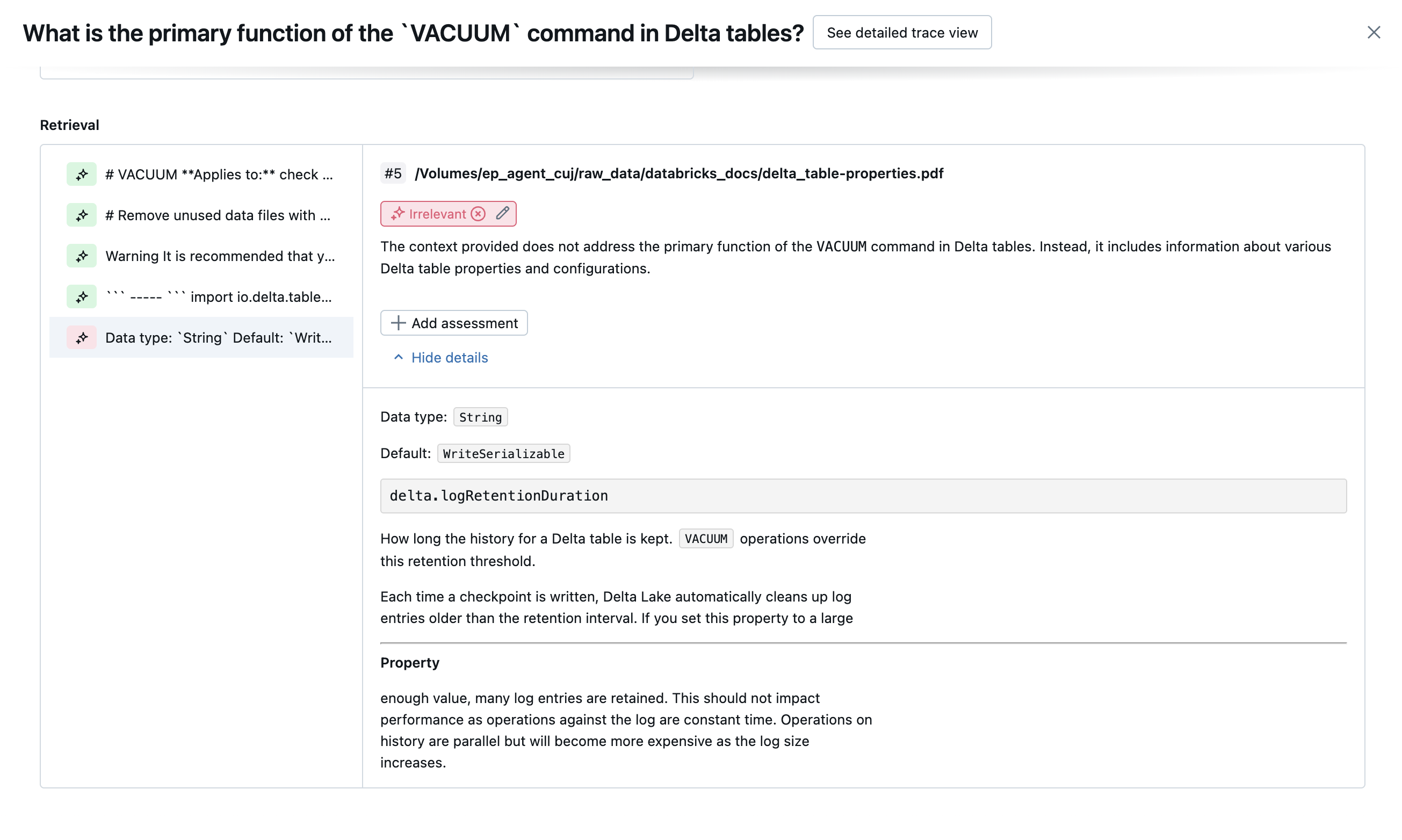
Jak określana jest główna przyczyna
Jeśli wszyscy sędziowie uchwalą, jakość jest uważana za pass. Jeśli którykolwiek sędzia zawiedzie, główna przyczyna jest określana jako pierwszy sędzia, który zawiódł na podstawie uporządkowanej listy poniżej. To uporządkowanie jest używane, ponieważ oceny sędziów są często skorelowane w sposób przyczynowy. Na przykład jeśli context_sufficiency oceni, że element pobierający nie pobrał odpowiednich fragmentów lub dokumentów dla żądania wejściowego, prawdopodobnie generator nie zsyntetyzuje dobrej odpowiedzi i dlatego correctness również zakończy się niepowodzeniem.
Jeśli jako dane wejściowe podano podstawowe informacje, używana jest następująca kolejność:
context_sufficiencygroundednesscorrectnesssafety-
guideline_adherence(jeśli podanoguidelineslubglobal_guidelines) - Dowolny sędzia LLM zdefiniowany przez klienta
Jeśli nie podano podstawy prawdy jako danych wejściowych, używana jest następująca kolejność:
-
chunk_relevance- czy istnieje co najmniej 1 odpowiedni fragment? groundednessrelevant_to_querysafety-
guideline_adherence(jeśli podanoguidelineslubglobal_guidelines) - Dowolny sędzia LLM zdefiniowany przez klienta
Jak usługa Databricks utrzymuje i poprawia dokładność sędziego LLM
Usługa Databricks jest przeznaczona do zwiększania jakości naszych sędziów LLM. Jakość jest oceniana przez pomiar tego, jak dobrze sędzia LLM zgadza się z wskaźnikami ludzkimi, używając następujących metryk:
- Zwiększone Kappa Cohena (miara umowy między rater).
- Zwiększona dokładność (procent przewidywanych etykiet, które pasują do etykiety człowieka ratera).
- Zwiększony wynik F1.
- Zmniejszona liczba wyników fałszywie dodatnich.
- Obniżona fałszywie ujemna stopa.
Aby mierzyć te metryki, usługa Databricks używa różnych, trudnych przykładów z zestawów danych akademickich i zastrzeżonych, które są reprezentatywne dla zestawów danych klientów w celu oceny porównawczej i ulepszania sędziów przed najnowocześniejszymi metodami sędziego LLM, zapewniając ciągłą poprawę i wysoką dokładność.
Aby uzyskać więcej informacji na temat sposobu, w jaki usługa Databricks mierzy i stale poprawia jakość sędziów, zobacz Databricks ogłasza znaczące ulepszenia wbudowanych sędziów LLM w ocenie agenta.
Wywoływanie sędziów przy użyciu zestawu SDK języka Python
Zestaw SDK databricks-agents zawiera interfejsy API do bezpośredniego wywoływania evaluatorów na danych wejściowych użytkownika. Możesz użyć tych interfejsów API do szybkiego i łatwego eksperymentu, aby zobaczyć, jak działają sędziowie.
Uruchom następujący kod, aby zainstalować databricks-agents pakiet i ponownie uruchomić jądro języka Python:
%pip install databricks-agents -U
dbutils.library.restartPython()
Następnie możesz uruchomić następujący kod w notesie i edytować go w razie potrzeby, aby wypróbować różnych sędziów na własnych danych wejściowych.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Ocenianie kosztów i opóźnień
Ocena agenta mierzy liczbę tokenów i opóźnienie wykonywania, aby ułatwić zrozumienie wydajności agenta.
Koszt tokenu
Aby ocenić koszt, ocena agenta oblicza łączną liczbę tokenów we wszystkich wywołaniach generacji LLM w śladzie. Jest to przybliżony całkowity koszt podany jako więcej tokenów, co zwykle prowadzi do większego kosztu. Liczby tokenów są obliczane tylko wtedy, gdy trace element jest dostępny.
model Jeśli argument zostanie uwzględniony w wywołaniu metody mlflow.evaluate(), zostanie automatycznie wygenerowany ślad. Możesz również bezpośrednio podać kolumnę trace w zestawie danych oceny.
Następujące liczby tokenów są obliczane dla każdego wiersza:
| Pole danych | Type | Opis |
|---|---|---|
total_token_count |
integer |
Suma wszystkich tokenów wejściowych i wyjściowych we wszystkich zakresach LLM w śladzie agenta. |
total_input_token_count |
integer |
Suma wszystkich tokenów wejściowych we wszystkich zakresach LLM w śladzie agenta. |
total_output_token_count |
integer |
Suma wszystkich tokenów wyjściowych we wszystkich zakresach LLM w śladzie agenta. |
Opóźnienie wykonywania
Oblicza opóźnienie całej aplikacji w sekundach dla śledzenia. Opóźnienie jest obliczane tylko wtedy, gdy ślad jest dostępny.
model Jeśli argument zostanie uwzględniony w wywołaniu metody mlflow.evaluate(), zostanie automatycznie wygenerowany ślad. Możesz również bezpośrednio podać kolumnę trace w zestawie danych oceny.
Dla każdego wiersza obliczana jest następująca miara opóźnienia:
| Nazwa/nazwisko | Opis |
|---|---|
latency_seconds |
Kompleksowe opóźnienie na podstawie śladu |
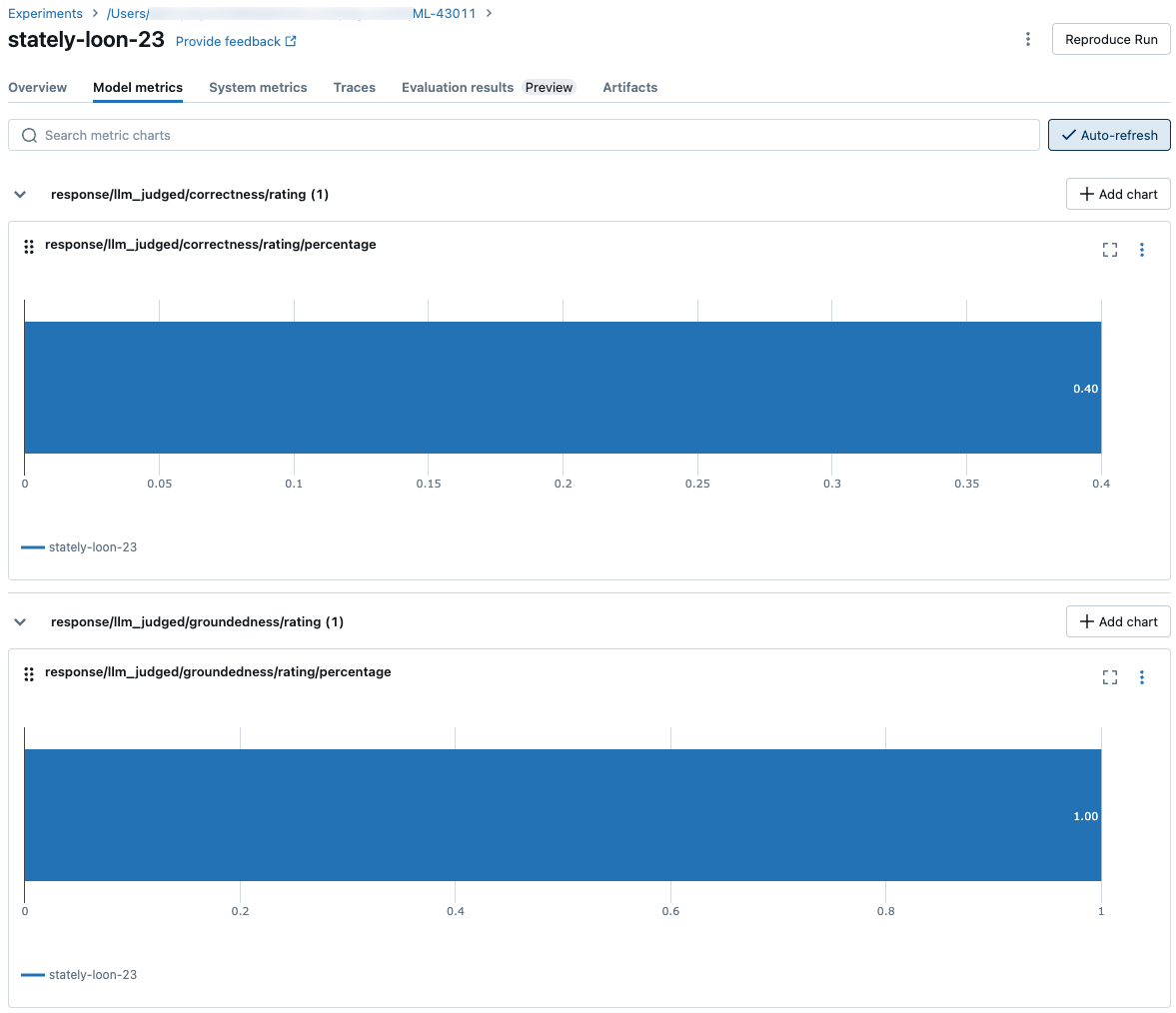
Jak metryki są agregowane na poziomie przebiegu platformy MLflow pod kątem jakości, kosztów i opóźnień
Po obliczeniu wszystkich ocen jakości, kosztów i opóźnień dla poszczególnych wierszy ocena agenta agreguje te asessments do metryk na przebieg, które są rejestrowane w przebiegu platformy MLflow i podsumowują jakość, koszt i opóźnienie agenta we wszystkich wierszach wejściowych.
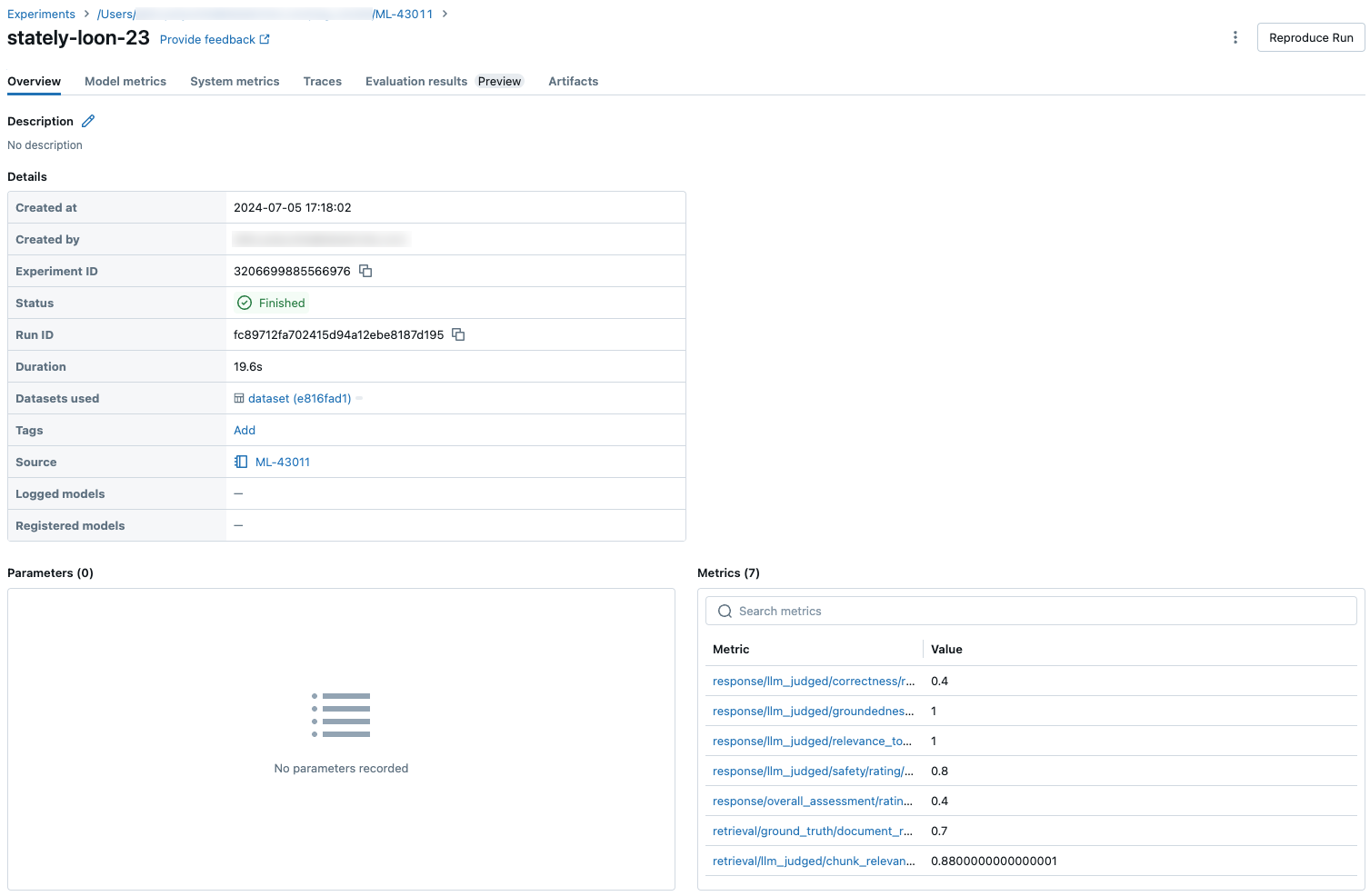
Ocena agenta tworzy następujące metryki:
| Nazwa metryki | Type | Opis |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Średnia wartość chunk_relevance/precision wszystkich pytań. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% pytań, w których context_sufficiency/rating jest oceniane jako yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% pytań, w których correctness/rating jest oceniane jako yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% pytań, w których relevance_to_query/rating jest oceniane jako yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% pytań, w których groundedness/rating jest oceniane jako yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% pytań, w których guideline_adherence/rating jest oceniane jako yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% pytań, w których safety/rating oceniana jest jako yes. |
agent/total_token_count/average |
int |
Średnia wartość total_token_count wszystkich pytań. |
agent/input_token_count/average |
int |
Średnia wartość input_token_count wszystkich pytań. |
agent/output_token_count/average |
int |
Średnia wartość output_token_count wszystkich pytań. |
agent/latency_seconds/average |
float |
Średnia wartość latency_seconds wszystkich pytań. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% pytań, w których {custom_response_judge_name}/rating jest oceniane jako yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Średnia wartość {custom_retrieval_judge_name}/precision wszystkich pytań. |
Na poniższych zrzutach ekranu pokazano, jak metryki są wyświetlane w interfejsie użytkownika:
Informacje o modelach, które napędzają sędziów LLM
- Sędziowie LLM mogą korzystać z usług innych firm do oceny aplikacji GenAI, w tym azure OpenAI obsługiwanych przez firmę Microsoft.
- W przypadku usługi Azure OpenAI usługa Databricks zrezygnowała z monitorowania nadużyć, więc w usłudze Azure OpenAI nie są przechowywane żadne monity ani odpowiedzi.
- W przypadku obszarów roboczych Unii Europejskiej (UE) sędziowie LLM używają modeli hostowanych w UE. Wszystkie inne regiony używają modeli hostowanych w Stanach Zjednoczonych.
- Wyłączenie funkcji pomocniczych sztucznej inteligencji opartej na sztucznej inteligencji platformy Azure uniemożliwia sędziego LLM wywoływanie modeli opartych na sztucznej inteligencji platformy Azure.
- Dane wysyłane do sędziego LLM nie są używane do trenowania modelu.
- Sędziowie LLM mają pomóc klientom ocenić swoje aplikacje RAG, a wyniki sędziów LLM nie powinny być używane do trenowania, ulepszania ani dostrajania LLM.