Jak monitorować jakość agenta w ruchu produkcyjnym
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
W tym artykule opisano sposób monitorowania jakości wdrożonych agentów na ruchu produkcyjnym przy użyciu narzędzia Mosaic AI Agent Evaluation.
Monitorowanie online jest kluczowym aspektem zapewnienia, że agent działa zgodnie z oczekiwaniami z rzeczywistymi żądaniami. Korzystając z poniższego notesu, możesz uruchamiać ocenę agenta w sposób ciągły na żądaniach obsługiwanych za pośrednictwem punktu końcowego obsługującego agenta. Notes generuje pulpit nawigacyjny, który wyświetla metryki jakości, a także opinie użytkowników (kciuki w górę 👍 lub kciuki w dół 👎) dla danych wyjściowych agenta dotyczących żądań produkcyjnych. Te opinie mogą pochodzić z aplikacji do przeglądu od osób biorących udział w projekcie lub interfejsu API opinii na temat produkcyjnych punktów końcowych, które umożliwiają przechwytywanie reakcji użytkowników końcowych. Pulpit nawigacyjny umożliwia fragmentowanie metryk według różnych wymiarów, w tym według czasu, opinii użytkowników, stanu przekazywania/niepowodzenia i tematu żądania wejściowego (na przykład w celu zrozumienia, czy określone tematy są skorelowane z danymi wyjściowymi niższej jakości). Ponadto możesz dokładniej zapoznać się z poszczególnymi żądaniami z odpowiedziami o niskiej jakości, aby je dodatkowo debugować. Wszystkie artefakty, takie jak pulpit nawigacyjny, można w pełni dostosowywać.
Wymagania
- Funkcje pomocnicze sztucznej inteligencji oparte na sztucznej inteligencji platformy Azure muszą być włączone dla obszaru roboczego.
- tabele wnioskowania należy włączyć w punkcie końcowym obsługującym agenta.
Ciągły proces ruchu produkcyjnego za pośrednictwem oceny agenta
Poniższy przykładowy notes ilustruje sposób uruchamiania oceny agenta w dziennikach żądań z punktu końcowego obsługującego agenta. Aby uruchomić notes, wykonaj następujące kroki:
- Zaimportuj notes w obszarze roboczym (instrukcje). Możesz kliknąć poniższy przycisk "Kopiuj link do importu", aby uzyskać adres URL importu.
- Wypełnij wymagane parametry w górnej części zaimportowanego notesu.
- Nazwa wdrożonego punktu końcowego obsługującego agenta.
- Częstotliwość próbkowania z zakresu od 0,0 do 1,0 do przykładowych żądań. Użyj niższej stawki dla punktów końcowych z dużymi ilościami ruchu.
- (Opcjonalnie) Folder obszaru roboczego do przechowywania wygenerowanych artefaktów (takich jak pulpity nawigacyjne). Wartość domyślna to folder główny.
- (Opcjonalnie) Lista tematów do kategoryzowania żądań wejściowych. Wartość domyślna to lista składająca się z pojedynczego tematu ogólnego.
- Kliknij pozycję Uruchom wszystko w zaimportowanych notesach. Spowoduje to wstępne przetwarzanie dzienników produkcyjnych w 30-dniowym oknie i zainicjowanie pulpitu nawigacyjnego, który podsumowuje metryki jakości.
- Kliknij przycisk Harmonogram , aby okresowo tworzyć zadanie do uruchamiania notesu. Zadanie będzie stopniowo przetwarzać dzienniki produkcyjne i aktualizować pulpit nawigacyjny.
Notes wymaga zasobów obliczeniowych bezserwerowych lub klastra z uruchomionym środowiskiem Databricks Runtime 15.2 lub nowszym. W przypadku ciągłego monitorowania ruchu produkcyjnego w punktach końcowych z dużą liczbą żądań zalecamy ustawienie częstszego harmonogramu. Na przykład harmonogram godzinowy będzie działać dobrze dla punktu końcowego z ponad 10 000 żądań na godzinę i 10% częstotliwości próbkowania.
Uruchamianie oceny agenta w notesie ruchu produkcyjnego
Egzekwowanie wytycznych dotyczących odpowiedzi agenta
Sędzia zgodności wytycznych zapewnia, że dane wyjściowe modelu są zgodne z podanymi wytycznymi. Możesz napisać te wytyczne globalne, jak pokazano w notesie podanym powyżej lub w następujący sposób:
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}
}
)
Wyniki tego oceniającego zostaną umieszczone w tabeli ocenionych dzienników żądań wygenerowanej przez przykładowy notatnik (eval_requests_log_table_name w notatniku), a pulpit nawigacyjny można dostosować, aby wyświetlić wyniki oceniającego w dłuższym okresie czasu.
Tworzenie alertów dotyczących metryk oceny
Po zaplanowaniu okresowego uruchamiania notesu można dodać alerty, aby otrzymywać powiadomienia, gdy metryki jakości spadną niż oczekiwano. Te alerty są tworzone i używane w taki sam sposób jak inne alerty SQL usługi Databricks. Najpierw utwórz zapytanie SQL usługi Databricks w tabeli dziennika żądań oceny utworzonej przez przykładowy notatnik. Poniższy kod przedstawia przykładowe zapytanie w tabeli żądań oceny, filtrując żądania z ostatniej godziny:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Następnie utwórz alert SQL usługi Databricks, aby ocenić zapytanie z żądaną częstotliwością i wysłać powiadomienie, jeśli alert zostanie wyzwolony. Na poniższej ilustracji przedstawiono przykładową konfigurację wysyłania alertu, gdy ogólna szybkość przekazywania spadnie poniżej 80%.
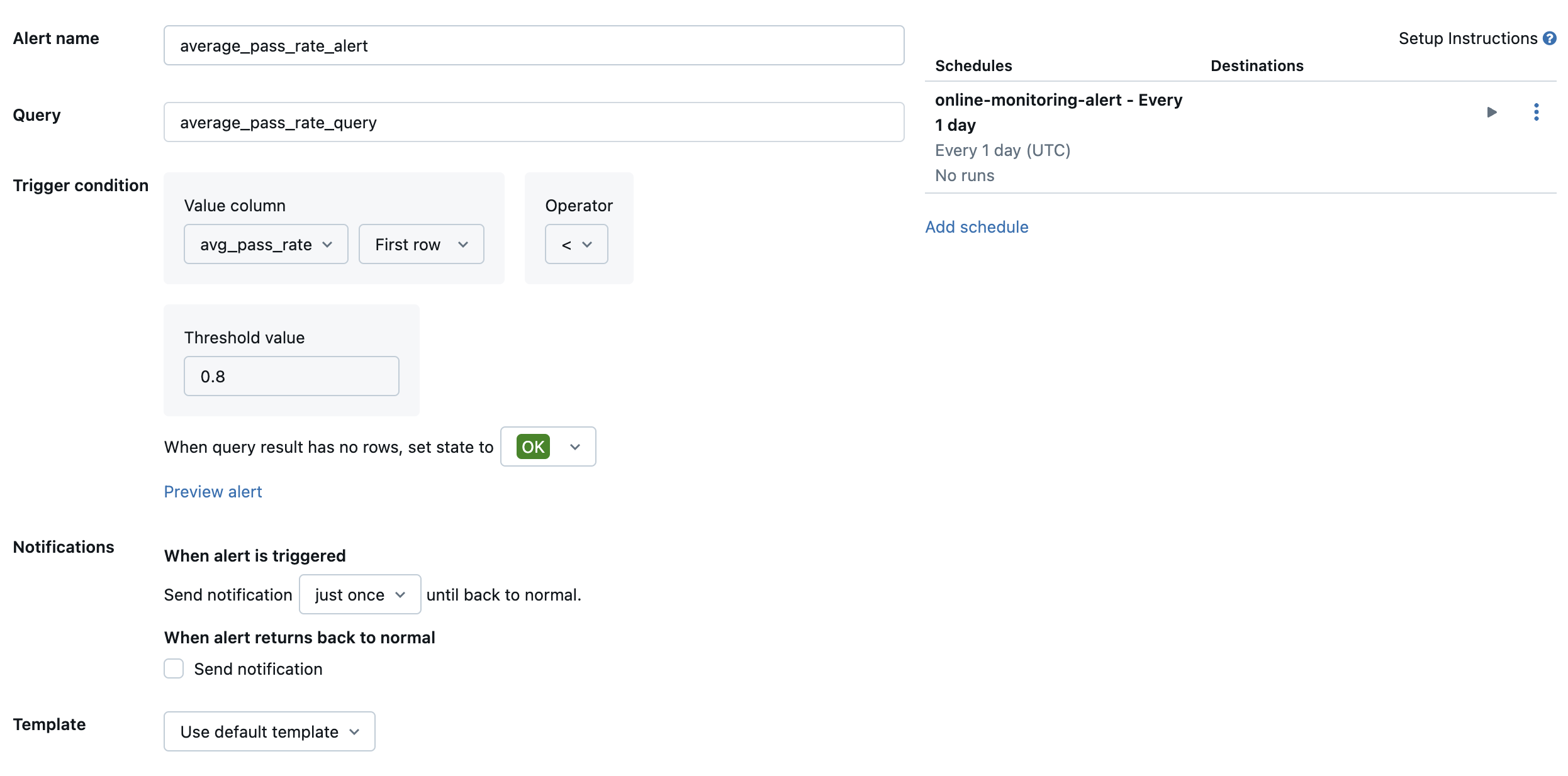
Domyślnie jest wysyłane powiadomienie e-mail. Możesz również skonfigurować element webhook lub wysyłać powiadomienia do innych aplikacji, takich jak Slack lub PagerDuty.
Dodawanie wybranych dzienników produkcyjnych do aplikacji do przeglądu przez człowieka
Gdy użytkownicy przekazują opinie na temat Twoich żądań, możesz poprosić ekspertów o przejrzenie żądań z negatywną opinią (żądania z kciukami w dół odpowiedzi lub pobierania). W tym celu należy dodać określone dzienniki do aplikacji do przeglądu w celu zażądania przeglądu ekspertów.
Poniższy kod przedstawia przykładowe zapytanie do tabeli dziennika ocen, aby uzyskać najnowszą ocenę ludzką na podstawie identyfikatora żądania i identyfikatora źródła.
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
W poniższym kodzie zastąp ciąg ... w wierszu human_ratings_query = "..." zapytaniem podobnym do powyższego. Następnie poniższy kod wyodrębnia żądania z negatywną opinią i dodaje je do aplikacji do przeglądu:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Aby uzyskać więcej informacji na temat aplikacji recenzenckiej, zobacz Uzyskaj informacje zwrotne na temat jakości aplikacji o cechach agentowości.