Funkcje rozszerzenia pakietu zasobów usługi Databricks
Rozszerzenie Databricks dla programu Visual Studio Code udostępnia dodatkowe funkcje w programie Visual Studio Code, które umożliwiają łatwe definiowanie, wdrażanie i uruchamianie pakietów zasobów usługi Databricks w celu zastosowania najlepszych rozwiązań dotyczących ciągłej integracji/ciągłego wdrażania do zadań usługi Azure Databricks, potoków tabel delta live tables i stosów MLOps. Zobacz Co to są pakiety zasobów usługi Databricks?.
Aby zainstalować rozszerzenie usługi Databricks dla programu Visual Studio Code, zobacz Instalowanie rozszerzenia usługi Databricks dla programu Visual Studio Code.
Obsługa pakietów zasobów usługi Databricks w projektach
Rozszerzenie usługi Databricks dla programu Visual Studio Code dodaje następujące funkcje dla projektów pakietu zasobów usługi Databricks:
- Łatwe uwierzytelnianie i konfiguracja pakietów zasobów usługi Databricks za pośrednictwem interfejsu użytkownika programu Visual Studio Code, w tym wyboru profilu AuthType . Zobacz Konfigurowanie uwierzytelniania dla rozszerzenia usługi Databricks dla programu Visual Studio Code.
- Selektor docelowy w panelu rozszerzenia usługi Databricks, aby szybko przełączać się między środowiskami docelowymi pakietu. Zobacz Zmienianie docelowego obszaru roboczego wdrożenia.
- Opcja Zastąpij zadania klastra w pakiecie w panelu rozszerzenia, aby umożliwić łatwe zastępowanie klastra.
- Widok Eksplorator zasobów pakietu, który umożliwia przeglądanie zasobów pakietu przy użyciu interfejsu użytkownika programu Visual Studio Code, wdrażanie lokalnych zasobów pakietu zasobów usługi Databricks w zdalnym obszarze roboczym usługi Azure Databricks jednym kliknięciem i przechodzenie bezpośrednio do wdrożonych zasobów w obszarze roboczym z poziomu programu Visual Studio Code. Zobacz Temat Bundle Resource Explorer (Eksplorator zasobów pakietu).
- Widok zmiennych pakietu, który umożliwia przeglądanie i edytowanie zmiennych pakietu przy użyciu interfejsu użytkownika programu Visual Studio Code. Zobacz Widok zmiennych pakietu.
Eksplorator zasobów pakietu
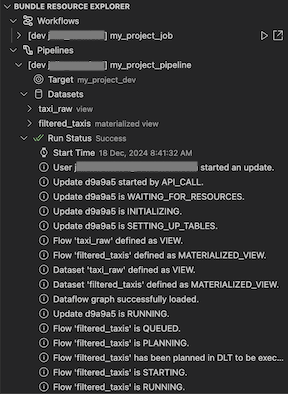
Widok Bundle Resource Explorer w rozszerzeniu Databricks, dla programu Visual Studio Code, używa definicji zadań i potoków w konfiguracji pakietu projektu do wyświetlania zasobów, w tym zestawów danych potoków i ich schematów. Umożliwia również wdrażanie i uruchamianie zasobów, weryfikowanie i wykonywanie częściowych aktualizacji potoków, wyświetlanie zdarzeń uruchamiania potoku i diagnostyki oraz przechodzenie do zasobów w zdalnym obszarze roboczym usługi Azure Databricks. Aby uzyskać informacje o zasobach konfiguracji pakietu, zobacz zasoby.
Na przykład biorąc pod uwagę prostą definicję zadania:
resources:
jobs:
my-notebook-job:
name: "My Notebook Job"
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
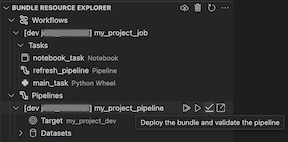
Widok Eksplorator zasobów pakietu w rozszerzeniu wyświetla zasób zadania notesu:
Aby wdrożyć pakiet, kliknij ikonę chmury (wdróż pakiet).
Aby uruchomić zadanie, w widoku Eksplorator zasobów pakietu wybierz nazwę zadania, czyli Moje zadanie notesu w tym przykładzie. Następnie kliknij ikonę odtwarzania (Wdróż pakiet i uruchom zasób).
Aby wyświetlić uruchomione zadanie, w widoku Eksplorator zasobów pakietu rozwiń nazwę zadania, kliknij pozycję Stan uruchomienia, a następnie kliknij link (Otwórz link zewnętrznie).
W przypadku potoku można wyzwolić walidację i częściową aktualizację, wybierając potok, a następnie ikonę z napisem (Wdróż pakiet i zweryfikuj potok). Zostaną wyświetlone zdarzenia przebiegu, a wszystkie błędy można zdiagnozować w panelu Problémów programu Visual Studio Code.
Widok zmiennych pakietu
Widok Widoku zmiennych pakietu w rozszerzeniu Databricks dla programu Visual Studio Code wyświetla wszystkie zmienne niestandardowe i skojarzone ustawienia zdefiniowane w konfiguracji pakietu. Zmienne można również definiować bezpośrednio przy użyciu widoku Zmiennych pakietów. Te wartości zastępują te ustawione w plikach konfiguracji pakietu. Aby uzyskać informacje o zmiennych niestandardowych, zobacz Zmienne niestandardowe.
Na przykład widok Widok zmiennych pakietu w rozszerzeniu wyświetli następujące elementy:

Dla zmiennej my_custom_var zdefiniowanej w tej konfiguracji pakietu:
variables:
my_custom_var:
description: "Max workers"
default: "4"
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}