Databricks Connect dla języka Scala
Uwaga
W tym artykule opisano usługę Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego.
Databricks Connect umożliwia łączenie popularnych środowisk IDE, takich jak IntelliJ IDEA, serwery notebooków i inne aplikacje niestandardowe z klastrami usługi Azure Databricks. Zobacz Co to jest usługa Databricks Connect?.
W tym artykule pokazano, jak szybko rozpocząć pracę z programem Databricks Connect dla języka Scala przy użyciu środowiska IntelliJ IDEA oraz wtyczki Scala.
- Aby zapoznać się z wersją języka Python tego artykułu, zobacz Databricks Connect dla języka Python.
- Aby zapoznać się z wersją języka R tego artykułu, zobacz Databricks Connect for R.
Poradnik
W poniższym samouczku utworzysz projekt w środowisku IntelliJ IDEA, zainstalujesz program Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego, a następnie uruchomisz prosty kod na komputerze w obszarze roboczym usługi Databricks z poziomu środowiska IntelliJ IDEA. Aby uzyskać dodatkowe informacje i przykłady, zobacz Następne kroki.
Wymagania
Aby ukończyć ten samouczek, musisz spełnić następujące wymagania:
Docelowy obszar roboczy i klaster usługi Azure Databricks muszą spełniać wymagania konfiguracji obliczeniowej dla usługi Databricks Connect.
Musisz mieć dostępny identyfikator klastra. Aby uzyskać identyfikator klastra, w swoim obszarze roboczym kliknij pozycję Compute na pasku bocznym, a następnie kliknij nazwę swojego klastra. Na pasku adresu przeglądarki internetowej skopiuj ciąg znaków między
clustersiconfigurationw adresie URL.Masz zainstalowany zestaw Java Development Kit (JDK) na komputerze deweloperskim. Usługa Databricks zaleca, aby wersja instalacji zestawu JDK odpowiadała wersji zestawu JDK w klastrze usługi Azure Databricks. Zobacz wymagania .
Uwaga
Jeśli nie masz zainstalowanego zestawu JDK lub masz wiele instalacji zestawu JDK na komputerze deweloperskim, możesz zainstalować lub wybrać określony zestaw JDK w dalszej części kroku 1. Wybranie instalacji zestawu JDK poniżej lub nowszej wersji zestawu JDK w klastrze może spowodować nieoczekiwane wyniki lub kod może w ogóle nie działać.
Masz zainstalowany program IntelliJ IDEA. Ten samouczek został przetestowany przy użyciu środowiska IntelliJ IDEA Community Edition 2023.3.6. Jeśli używasz innej wersji lub wydania środowiska IntelliJ IDEA, poniższe instrukcje mogą się różnić.
Masz zainstalowaną wtyczkę Scala dla środowiska IntelliJ IDEA.
Krok 1. Konfigurowanie uwierzytelniania usługi Azure Databricks
W tym samouczku używane jest uwierzytelnianie użytkownika do maszyny (U2M) usługi Azure Databricks oraz profil konfiguracji usługi Azure Databricks do uwierzytelniania i autoryzacji w obszarze roboczym usługi Azure Databricks. Aby zamiast tego użyć innego typu uwierzytelniania, zobacz Konfigurowanie właściwości połączenia.
Konfigurowanie uwierzytelniania OAuth U2M wymaga wiersza polecenia usługi Databricks, jak poniżej:
Jeśli nie został jeszcze zainstalowany, zainstaluj Databricks CLI w następujący sposób:
Linux, macOS
Użyj Homebrew, aby zainstalować Databricks CLI, uruchamiając następujące dwa polecenia:
brew tap databricks/tap brew install databricksWindows
Do zainstalowania interfejsu wiersza polecenia usługi Databricks można użyć zestawu narzędzi winget, Chocolatey lub Podsystem Windows dla systemu Linux (WSL). Jeśli nie możesz użyć
wingetpolecenia, Chocolatey lub WSL, powinieneś pominąć tę procedurę i użyć wiersza polecenia lub programu PowerShell, żeby zainstalować CLI usługi Databricks ze źródła.Uwaga
Instalowanie Databricks CLI za pomocą platformy Chocolatey jest eksperymentalne.
wingetAby zainstalować interfejs wiersza polecenia usługi Databricks, uruchom następujące dwa polecenia, a następnie uruchom ponownie wiersz polecenia:winget search databricks winget install Databricks.DatabricksCLIAby zainstalować CLI Databricks za pomocą Chocolatey, uruchom następujące polecenie:
choco install databricks-cliAby użyć programu WSL do zainstalowania CLI Databricks:
Zainstaluj
curlizippoprzez WSL. Aby uzyskać więcej informacji, zobacz dokumentację systemu operacyjnego.Użyj programu WSL, aby zainstalować interfejs wiersza polecenia usługi Databricks, uruchamiając następujące polecenie:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Upewnij się, że interfejs wiersza polecenia usługi Databricks jest zainstalowany, uruchamiając następujące polecenie, które wyświetla bieżącą wersję zainstalowanego interfejsu wiersza polecenia usługi Databricks. Ta wersja powinna mieć wartość 0.205.0 lub nowszą:
databricks -vUwaga
Jeśli uruchomisz
databrickspolecenie , ale wystąpi błąd, taki jakcommand not found: databricks, lub jeśli uruchomiszdatabricks -vpolecenie i zostanie wyświetlony numer wersji 0.18 lub poniżej, oznacza to, że maszyna nie może odnaleźć poprawnej wersji pliku wykonywalnego interfejsu wiersza polecenia usługi Databricks. Aby rozwiązać ten problem, zapoznaj się z Weryfikowaniem instalacji CLI.
Zainicjuj uwierzytelnianie OAuth U2M w następujący sposób:
Użyj Databricks CLI, aby lokalnie zainicjować zarządzanie tokenami OAuth, uruchamiając następujące polecenie dla każdej docelowej przestrzeni roboczej.
W poniższym poleceniu, zastąp
<workspace-url>swoim adresem URL dla konkretnej przestrzeni roboczej Azure Databricks, na przykładhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Interfejs CLI Databricks prosi o zapisanie wprowadzonych informacji jako profil konfiguracji Azure Databricks
. Naciśnij Enter, aby zaakceptować sugerowaną nazwę profilu lub wprowadź nazwę nowego lub istniejącego profilu. Każdy istniejący profil o tej samej nazwie zostanie zastąpiony wprowadzonymi informacjami. Profile umożliwiają szybkie przełączanie kontekstu uwierzytelniania między wieloma obszarami roboczymi.Aby uzyskać listę wszystkich istniejących profilów, w osobnym terminalu lub wierszu polecenia użyj interfejsu wiersza polecenia usługi Databricks, aby uruchomić polecenie
databricks auth profiles. Aby wyświetlić istniejące ustawienia określonego profilu, uruchom poleceniedatabricks auth env --profile <profile-name>.W przeglądarce internetowej wykonaj instrukcje na ekranie, aby zalogować się do obszaru roboczego usługi Azure Databricks.
Na liście dostępnych klastrów wyświetlanych w terminalu lub wierszu polecenia użyj strzałek w górę i w dół, aby wybrać docelowy klaster usługi Azure Databricks w obszarze roboczym, a następnie naciśnij
Enter. Możesz również wpisać dowolną część nazwy wyświetlanej klastra, aby filtrować listę dostępnych klastrów.Aby wyświetlić bieżącą wartość tokenu OAuth profilu i zbliżający się znacznik czasu wygaśnięcia tokenu, uruchom jedno z następujących poleceń:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Jeśli masz wiele profilów o tej samej wartości
--host, może być konieczne określenie opcji--hosti-p, aby ułatwić Databricks CLI znalezienie prawidłowych pasujących informacji o tokenie OAuth.
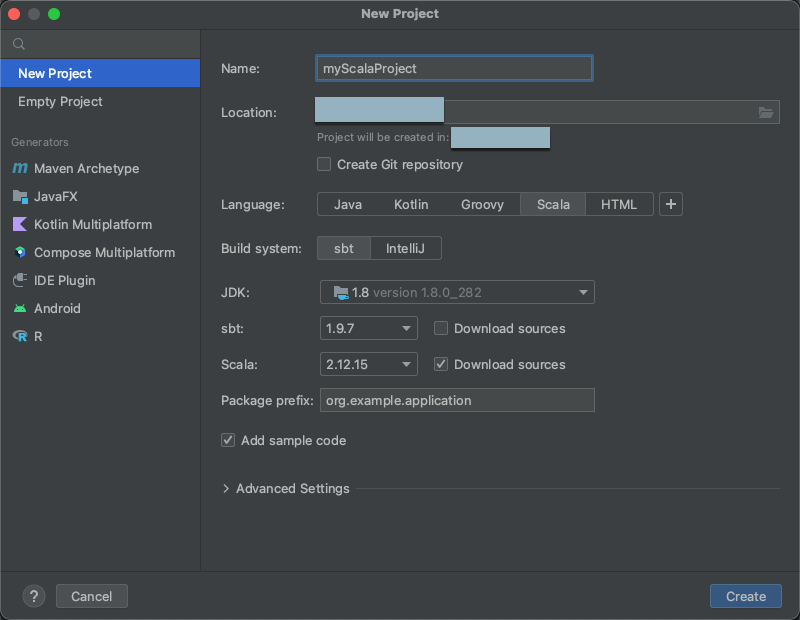
Krok 2. Tworzenie projektu
Uruchom środowisko IntelliJ IDEA.
W menu głównym kliknij pozycję Plik > Nowy > Projekt.
Nadaj projektowi znaczącą nazwę.
W obszarze Lokalizacja kliknij ikonę folderu i ukończ wskazówki na ekranie, aby określić ścieżkę do nowego projektu Scala.
W obszarze Język kliknij Scala.
W obszarze System budowania kliknij pozycję sbt.
Z listy rozwijanej zestaw JDK wybierz istniejącą instalację zestawu JDK na maszynie dewelopera zgodnej z wersją zestawu JDK w klastrze lub wybierz pozycję Pobierz zestaw JDK i postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby pobrać zestaw JDK zgodny z wersją zestawu JDK w klastrze. Zobacz wymagania .
Uwaga
Wybranie instalacji zestawu JDK, która znajduje się powyżej lub poniżej wersji zestawu JDK w klastrze, może spowodować nieoczekiwane wyniki lub kod może w ogóle nie działać.
Z listy rozwijanej sbt wybierz najnowszą wersję.
Z listy rozwijanej Scala wybierz wersję języka Scala zgodną z wersją języka Scala w klastrze. Zobacz wymagania .
Uwaga
Wybranie wersji języka Scala poniżej lub nowszej wersji języka Scala w klastrze może spowodować nieoczekiwane wyniki lub kod może w ogóle nie działać.
Upewnij się, że pole Pobierz źródła obok pozycji Scala jest zaznaczone.
W polu Prefiks pakietu wprowadź wartość prefiksu pakietu dla źródeł projektu, na przykład
org.example.application.Upewnij się, że pole Dodaj przykładowy kod jest zaznaczone.
Kliknij pozycję Utwórz.
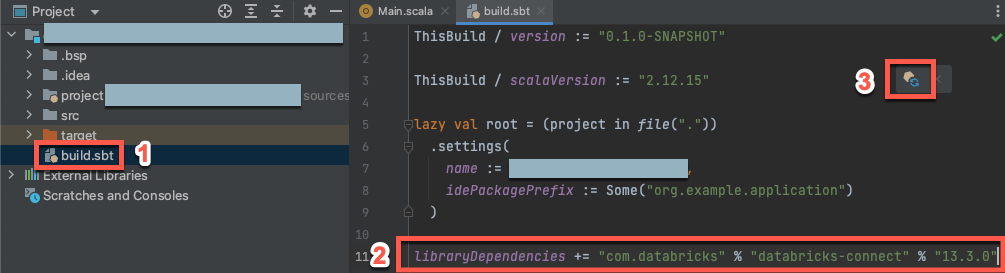
Krok 3. Dodawanie pakietu Databricks Connect
Po otwarciu nowego projektu Scala w oknie narzędzia Project (Wyświetl > narzędzie > Windows Project), otwórz plik o nazwie
build.sbt, w katalogu project-name> target.Dodaj następujący kod na końcu pliku
build.sbt, który deklaruje zależność projektu od określonej wersji biblioteki Databricks Connect dla języka Scala zgodnej z wersją środowiska Databricks Runtime klastra:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Zastąp
14.3.1element wersją biblioteki Databricks Connect zgodną z wersją środowiska Databricks Runtime w klastrze. Na przykład usługa Databricks Connect 14.3.1 pasuje do środowiska Databricks Runtime 14.3 LTS. Numery wersji biblioteki usługi Databricks Connect można znaleźć w centralnym repozytorium Maven.Kliknij ikonę powiadomienia Załaduj zmiany sbt, aby zaktualizować projekt Scala, uwzględniając nową lokalizację biblioteki i zależności.
Poczekaj,
sbtaż wskaźnik postępu w dolnej części środowiska IDE zniknie. Processbtładowania może potrwać kilka minut.
Krok 4. Dodawanie kodu
W oknie narzędzia Project otwórz plik o nazwie
Main.scala, w project-name> src > main > scala.Zastąp istniejący kod w pliku następującym kodem, a następnie zapisz plik w zależności od nazwy profilu konfiguracji.
Jeśli profil konfiguracji z kroku 1 nosi nazwę
DEFAULT, zastąp dowolny istniejący kod w pliku następującym kodem, a następnie zapisz plik:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Jeśli profil konfiguracji z kroku 1 nie ma nazwy
DEFAULT, zastąp dowolny istniejący kod w pliku poniższym kodem. Zastąp symbol zastępczy<profile-name>nazwą profilu konfiguracji z kroku 1, a następnie zapisz plik:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Krok 5. Uruchamianie kodu
- Uruchom klaster docelowy w zdalnym obszarze roboczym usługi Azure Databricks.
- Po uruchomieniu klastra w menu głównym kliknij Uruchom > ‘Main’.
-
W oknie narzędzia Uruchom (Widok > Okna Narzędzi > Uruchom), na karcie Main (Główne) wyświetlone zostaną pierwsze pięć wierszy
samples.nyctaxi.tripstabeli.
Krok 6. Debugowanie kodu
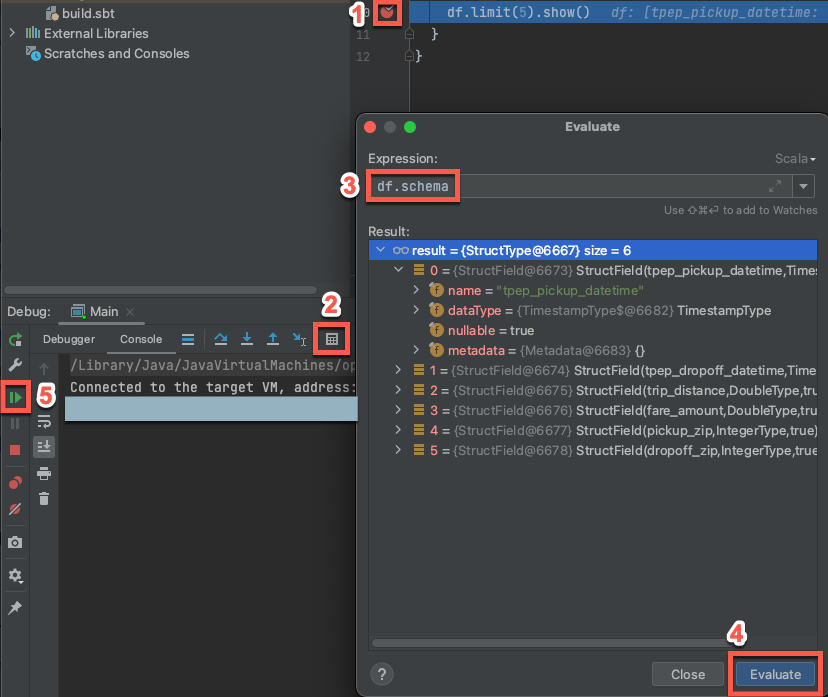
- Gdy klaster docelowy jest wciąż uruchomiony, w poprzednim kodzie kliknij w margen obok
df.limit(5).show(), aby ustawić punkt przerwania. - W menu głównym kliknij Uruchom debugowanie 'Main'.
- W oknie narzędziowym Debug (Widok > Okna narzędzi > Debug), na karcie Konsola, kliknij ikonę kalkulatora (Oceń wyrażenie).
- Wprowadź wyrażenie
df.schemai kliknij przycisk Oceń , aby wyświetlić schemat ramki danych. - Na pasku bocznym okna narzędzia debugowania kliknij ikonę zielonej strzałki (wznów program).
- W okienku Konsola zostanie wyświetlonych pierwszych 5 wierszy
samples.nyctaxi.tripstabeli.
Następne kroki
Aby dowiedzieć się więcej o programie Databricks Connect, zobacz artykuły, takie jak:
- Aby użyć typów uwierzytelniania usługi Azure Databricks innych niż osobisty token dostępu usługi Azure Databricks, zobacz Konfigurowanie właściwości połączenia.
- Aby wyświetlić dodatkowe proste przykłady kodu, zobacz Przykłady kodu dla programu Databricks Connect dla języka Scala.
- Aby wyświetlić bardziej złożone przykłady kodu, zobacz przykładowe aplikacje dla repozytorium Databricks Connect w usłudze GitHub, w szczególności:
- Aby przeprowadzić migrację z usługi Databricks Connect dla środowiska Databricks Runtime 12.2 LTS i poniżej do usługi Databricks Connect dla środowiska Databricks Runtime 13.3 LTS lub nowszego, zobacz Migrowanie do usługi Databricks Connect dla języka Scala.
- Zobacz również informacje o rozwiązywaniu problemów i ograniczeniach.