Konfigurowanie usługi Delta Lake w celu kontrolowania rozmiaru pliku danych
Uwaga
Zalecenia zawarte w tym artykule nie dotyczą tabel zarządzanych w programie Unity Catalog. Databricks zaleca używanie tabel zarządzanych przez Unity Catalog z ustawieniami domyślnymi dla wszystkich nowych tabel Delta.
W środowisku Databricks Runtime 13.3 lub nowszym usługa Databricks zaleca używanie klastrowania dla układu tabeli delty. Zobacz Użyj klastrowania cieczy dla tabel Delta.
Usługa Databricks zaleca korzystanie z optymalizacji predykcyjnej do automatycznego uruchamiania OPTIMIZE i VACUUM dla tabel Delta. Zobacz Optymalizację predykcyjną dla tabel zarządzanych w Unity Catalog.
W środowisku Databricks Runtime 10.4 LTS i nowszym automatyczne kompaktowanie i zoptymalizowane zapisy są zawsze włączone dla operacji MERGE, UPDATE i DELETE. Nie można wyłączyć tej funkcji.
Usługa Delta Lake udostępnia opcje ręcznego lub automatycznego konfigurowania docelowego rozmiaru pliku dla operacji zapisu i operacji OPTIMIZE . Usługa Azure Databricks automatycznie dostraja wiele z tych ustawień i umożliwia funkcje, które automatycznie zwiększają wydajność tabeli, szukając plików o odpowiednim rozmiarze.
W przypadku tabel zarządzanych przez Unity Catalog, Databricks dostraja większość tych konfiguracji automatycznie, jeśli używasz SQL warehouse lub Databricks Runtime 11.3 LTS lub nowszej.
Jeżeli modernizujesz obciążenie robocze ze środowiska Databricks Runtime 10.4 LTS lub starszego, zobacz Uaktualnianie do automatycznego kompaktowania w tle.
Kiedy należy uruchomić OPTIMIZE
Automatyczne kompaktowanie i zoptymalizowane zapisy zmniejszają problemy z małymi plikami, ale nie są pełnym zamiennikiem dla OPTIMIZE. Szczególnie w przypadku tabel większych niż 1 TB usługa Databricks zaleca uruchamianie OPTIMIZE zgodnie z harmonogramem w celu dalszego skonsolidowania plików. Azure Databricks nie uruchamia automatycznie ZORDER na tabelach, dlatego należy uruchomić OPTIMIZE z ZORDER aby umożliwić pomijanie rozszerzonych danych. Zobacz Pomijanie danych dla usługi Delta Lake.
Co to jest automatyczna optymalizacja w usłudze Azure Databricks?
Termin autooptymalizowanie jest czasami używany do opisywania funkcji kontrolowanych przez ustawienia delta.autoOptimize.autoCompact i delta.autoOptimize.optimizeWrite. Ten termin został wycofany na rzecz opisywania każdego ustawienia osobno. Zobacz Automatyczne kompaktowanie usługi Delta Lake w usłudze Azure Databricks i Zoptymalizowane zapisy dla usługi Delta Lake w usłudze Azure Databricks.
Automatyczne kompaktowanie dla Delta Lake na Azure Databricks
Automatyczne kompaktowanie łączy małe pliki w partycjach tabeli delty, aby automatycznie zmniejszyć małe problemy z plikami. Automatyczne kompaktowanie występuje po pomyślnym zakończeniu zapisu w tabeli i jest synchronicznie uruchamiane w klastrze, który wykonał zapis. Automatyczne kompaktowanie tylko kompaktuje pliki, które nie zostały wcześniej skompaktowane.
Rozmiar pliku wyjściowego można kontrolować, ustawiając konfiguracjęSpark. Usługa Databricks zaleca używanie automatycznego dostrajania na podstawie obciążenia lub rozmiaru tabeli. Zobacz Automatyczne dostrajanie rozmiaru pliku na podstawie obciążenia i Automatyczne dostrajanie rozmiaru pliku na podstawie rozmiaru tabeli.
Automatyczne kompaktowanie jest wyzwalane tylko dla partycji lub tabel, które mają co najmniej określoną liczbę małych plików. Opcjonalnie możesz zmienić minimalną liczbę plików wymaganych do wyzwolenia automatycznego kompaktowania, ustawiając wartość spark.databricks.delta.autoCompact.minNumFiles.
Automatyczne kompaktowanie można włączyć na poziomie tabeli lub sesji przy użyciu następujących ustawień:
- Właściwość tabeli:
delta.autoOptimize.autoCompact - Ustawienie SparkSession:
spark.databricks.delta.autoCompact.enabled
Te ustawienia akceptują następujące opcje:
| Opcje | Zachowanie |
|---|---|
auto (zalecane) |
Dostosowuje docelowy rozmiar pliku, uwzględniając inne funkcje automatycznego dostrajania. Wymaga środowiska Databricks Runtime 10.4 LTS lub nowszego. |
legacy |
Alias dla elementu true. Wymaga środowiska Databricks Runtime 10.4 LTS lub nowszego. |
true |
Użyj 128 MB jako rozmiaru pliku docelowego. Brak dynamicznego określania rozmiaru. |
false |
Wyłącza automatyczne kompaktowanie. Można ustawić na poziomie sesji, aby zastąpić automatyczne kompaktowanie dla wszystkich tabel Delta zmodyfikowanych w ramach obciążenia. |
Ważne
W środowisku Databricks Runtime 9.1 LTS, gdy inne osoby wykonują operacje, takie jak DELETE, MERGE, UPDATE lub OPTIMIZE jednocześnie, automatyczne kompaktowanie może spowodować niepowodzenie tych zadań z powodu konfliktu transakcji. Nie jest to problem w środowisku Databricks Runtime 10.4 LTS i nowszym.
Zoptymalizowane operacje zapisu dla Delta Lake w Azure Databricks
Zoptymalizowane zapisy zwiększają rozmiar pliku, ponieważ dane są zapisywane, a kolejne operacje odczytu w tabeli są korzystne.
Zoptymalizowane zapisy są najbardziej skuteczne w przypadku tabel partycjonowanych, ponieważ zmniejszają liczbę małych plików zapisywanych w każdej partycji. Zapisywanie mniejszej liczby dużych plików jest bardziej wydajne niż zapisywanie wielu małych plików, ale nadal może wystąpić wzrost opóźnienia zapisu, ponieważ dane są przetasowane przed zapisaniem.
Na poniższym obrazie przedstawiono, jak działają zoptymalizowane zapisy:
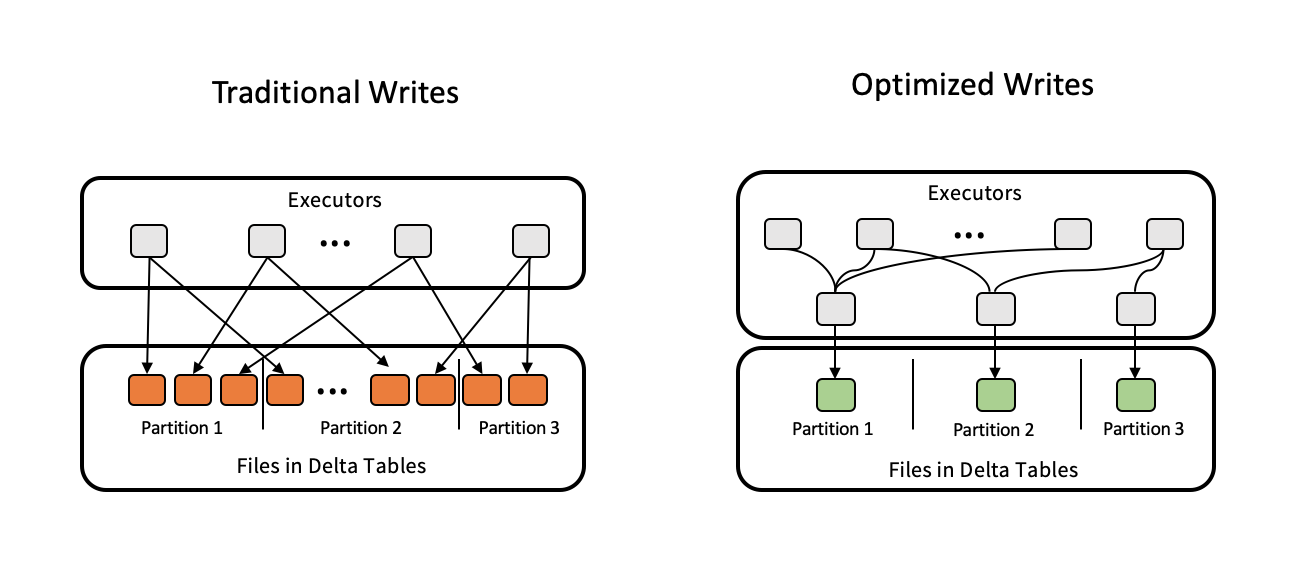
Uwaga
Może istnieć kod uruchamiany coalesce(n) lub repartition(n) tuż przed zapisaniem danych w celu kontrolowania liczby zapisanych plików. Zoptymalizowane zapisy eliminują konieczność używania tych wzorców.
Zoptymalizowane zapisy są domyślnie włączone dla następujących operacji w środowisku Databricks Runtime 9.1 LTS lub nowszym:
MERGE-
UPDATEz podzapytaniami -
DELETEz podzapytaniami
Zoptymalizowane zapisy są również włączone dla CTAS instrukcji i INSERT operacji podczas korzystania z usługi SQL Warehouse. W środowisku Databricks Runtime 13.3 LTS i nowszym wszystkie tabele Delta zarejestrowane w katalogu Unity mają włączone zoptymalizowane zapisy dla instrukcji CTAS i operacji INSERT dla tabel partycjonowanych.
Zoptymalizowane zapisy można włączyć na poziomie tabeli lub sesji przy użyciu następujących ustawień:
- Ustawienie tabeli:
delta.autoOptimize.optimizeWrite - Ustawienie SparkSession:
spark.databricks.delta.optimizeWrite.enabled
Te ustawienia akceptują następujące opcje:
| Opcje | Zachowanie |
|---|---|
true |
Użyj 128 MB jako rozmiaru pliku docelowego. |
false |
Wyłącza zoptymalizowane zapisy. Można ustawić na poziomie sesji, aby zastąpić automatyczne kompaktowanie dla wszystkich tabel delty zmodyfikowanych w obciążeniu. |
Ustawianie rozmiaru pliku docelowego
Jeśli chcesz dostroić rozmiar plików w tabeli delty, ustaw właściwośćdelta.targetFileSize tabeli na żądany rozmiar. Jeśli ta właściwość jest ustawiona, wszystkie operacje optymalizacji układu danych będą podejmować najlepszą próbę wygenerowania plików o określonym rozmiarze. Przykłady obejmują optymalizację lub porządek Z, automatyczne kompaktowanie i optymalizowane zapisy.
Uwaga
W przypadku korzystania z tabel zarządzanych przez Unity Catalog oraz magazynów SQL lub środowiska Databricks Runtime 11.3 LTS i nowszych, tylko polecenia OPTIMIZE są zgodne z ustawieniem targetFileSize.
| Właściwość tabeli |
|---|
|
delta.targetFileSize Typ: rozmiar w bajtach lub wyższych jednostkach. Rozmiar pliku docelowego. Na przykład 104857600 (bajty) lub 100mb.Wartość domyślna: Brak |
W przypadku istniejących tabel, można ustawić i usunąć ustawienia za pomocą polecenia SQL ALTER TABLESET WŁAŚCIWOŚCI TABELI. Te właściwości można również ustawić automatycznie podczas tworzenia nowych tabel przy użyciu konfiguracji sesji platformy Spark. Aby uzyskać szczegółowe informacje, zobacz odniesienie do właściwości tabeli Delta.
Automatyczne dostrajania rozmiaru pliku na podstawie obciążenia
Usługa Databricks zaleca ustawienie właściwości delta.tuneFileSizesForRewrites tabeli na true dla wszystkich tabel, na które nakierowane jest wiele operacji MERGE lub DML, bez względu na środowisko Databricks Runtime, katalog Unity czy inne optymalizacje. W przypadku ustawienia true, rozmiar docelowego pliku dla tabeli jest ustawiony na znacznie niższy próg, co przyspiesza operacje intensywnego zapisu.
Jeśli nie ustawiono jawnie, usługa Azure Databricks automatycznie wykrywa, czy 9 z ostatnich 10 poprzednich operacji w Tabeli Delty dotyczyło operacji MERGE i ustawia tę właściwość tabeli na true. Aby uniknąć tego zachowania, należy jawnie ustawić tę właściwość na false.
| Właściwość tabeli |
|---|
|
delta.tuneFileSizesForRewrites Typ: BooleanCzy dostroić rozmiary plików na potrzeby optymalizacji układu danych. Wartość domyślna: Brak |
W przypadku istniejących tabel, można ustawić i usunąć ustawienia za pomocą polecenia SQL ALTER TABLESET WŁAŚCIWOŚCI TABELI. Te właściwości można również ustawić automatycznie podczas tworzenia nowych tabel przy użyciu konfiguracji sesji platformy Spark. Aby uzyskać szczegółowe informacje, zobacz Dokumentację właściwości tabeli delty.
Automatyczne dostrajania rozmiaru pliku na podstawie rozmiaru tabeli
Aby zminimalizować potrzebę ręcznego dostrajania, usługa Azure Databricks automatycznie dostraja rozmiar pliku tabel delty na podstawie rozmiaru tabeli. Usługa Azure Databricks będzie używać mniejszych rozmiarów plików dla mniejszych tabel i większych rozmiarów plików dla większych tabel, aby liczba plików w tabeli nie rosła zbyt duża. Azure Databricks nie dostraja automatycznie tabel, które zostały dostrojone z określonym rozmiarem docelowym lub na podstawie obciążenia z częstymi przepisywaniami.
Rozmiar pliku docelowego jest oparty na bieżącym rozmiarze tabeli delty. W przypadku tabel mniejszych niż 2,56 TB dostrojony automatycznie rozmiar pliku docelowego wynosi 256 MB. W przypadku tabel o rozmiarze od 2,56 TB do 10 TB rozmiar docelowy wzrośnie liniowo z 256 MB do 1 GB. W przypadku tabel większych niż 10 TB rozmiar pliku docelowego wynosi 1 GB.
Uwaga
Gdy rozmiar pliku docelowego tabeli wzrośnie, istniejące pliki nie są optymalizowane na nowo za pomocą polecenia OPTIMIZE. W związku z tym duża tabela może mieć zawsze pliki mniejsze niż rozmiar docelowy. Jeśli wymagane jest zoptymalizowanie tych mniejszych plików na większe pliki, można również skonfigurować stały rozmiar pliku docelowego dla tabeli przy użyciu delta.targetFileSize właściwości tabeli.
Gdy tabela jest zapisywana przyrostowo, rozmiary plików docelowych i liczby plików będą zbliżone do następujących liczb na podstawie rozmiaru tabeli. Liczby plików w tej tabeli są tylko przykładem. Rzeczywiste wyniki będą się różnić w zależności od wielu czynników.
| Rozmiar tabeli | Rozmiar pliku docelowego | Przybliżona liczba plików w tabeli |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Ograniczanie wierszy zapisanych w pliku danych
Czasami tabele z wąskimi danymi mogą napotkać błąd polegający na tym, że liczba wierszy w danym pliku danych przekracza limity obsługi formatu Parquet. Aby uniknąć tego błędu, możesz użyć konfiguracji spark.sql.files.maxRecordsPerFile sesji SQL, aby określić maksymalną liczbę rekordów do zapisu w jednym pliku dla tabeli usługi Delta Lake. Określenie wartości zerowej lub ujemnej nie reprezentuje żadnego limitu.
W środowisku Databricks Runtime 11.3 LTS lub nowszym można również użyć opcji maxRecordsPerFile DataFrameWriter podczas korzystania z DataFrame API do zapisywania w tabeli Delta Lake. Po maxRecordsPerFile określeniu wartość konfiguracji spark.sql.files.maxRecordsPerFile sesji SQL jest ignorowana.
Uwaga
Usługa Databricks nie zaleca używania tej opcji, chyba że konieczne jest uniknięcie wyżej wymienionego błędu. To ustawienie może być nadal konieczne w przypadku niektórych tabel zarządzanych przez Katalog Unity o małej objętości danych.
Uaktualnienie do automatycznej kompresji w tle
Automatyczne kompaktowanie w tle jest dostępne dla tabel zarządzanych przez Unity Catalog w środowisku Databricks Runtime 11.3 LTS i nowszych. Podczas migracji starszego obciążenia lub tabeli wykonaj następujące czynności:
- Usuń konfigurację
spark.databricks.delta.autoCompact.enabledSpark z ustawień konfiguracji klastra lub notatnika. - Dla każdej tabeli uruchom polecenie
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact), aby usunąć wszystkie starsze ustawienia automatycznego kompaktowania.
Po usunięciu tych zbędnych konfiguracji powinno zostać automatycznie wyzwolone automatyczne kompaktowanie w tle dla wszystkich tabel zarządzanych przez Unity Catalog.