Nawiązywanie połączenia z usługą Google Cloud Storage
W tym artykule opisano sposób konfigurowania połączenia z usługi Azure Databricks w celu odczytywania i zapisywania tabel i danych przechowywanych w usłudze Google Cloud Storage (GCS).
Aby odczytywać lub zapisywać z zasobnika GCS, musisz utworzyć dołączone konto usługi i musisz skojarzyć zasobnik z kontem usługi. Nawiąż połączenie z zasobnikiem bezpośrednio przy użyciu klucza wygenerowanego dla konta usługi.
Uzyskiwanie dostępu do zasobnika GCS bezpośrednio przy użyciu klucza konta usługi Google Cloud
Aby odczytywać i zapisywać bezpośrednio w zasobniku, należy skonfigurować klucz zdefiniowany w konfiguracji platformy Spark.
Krok 1. Konfigurowanie konta usługi Google Cloud przy użyciu konsoli Google Cloud Console
Musisz utworzyć konto usługi dla klastra usługi Azure Databricks. Usługa Databricks zaleca nadanie temu kontu usługi najmniejszych uprawnień potrzebnych do wykonywania zadań.
Kliknij pozycję Zarządzanie dostępem i tożsamościami i administratorem w okienku nawigacji po lewej stronie.
Kliknij pozycję Konta usług.
Kliknij pozycję + UTWÓRZ KONTO USŁUGI.
Wprowadź nazwę i opis konta usługi.
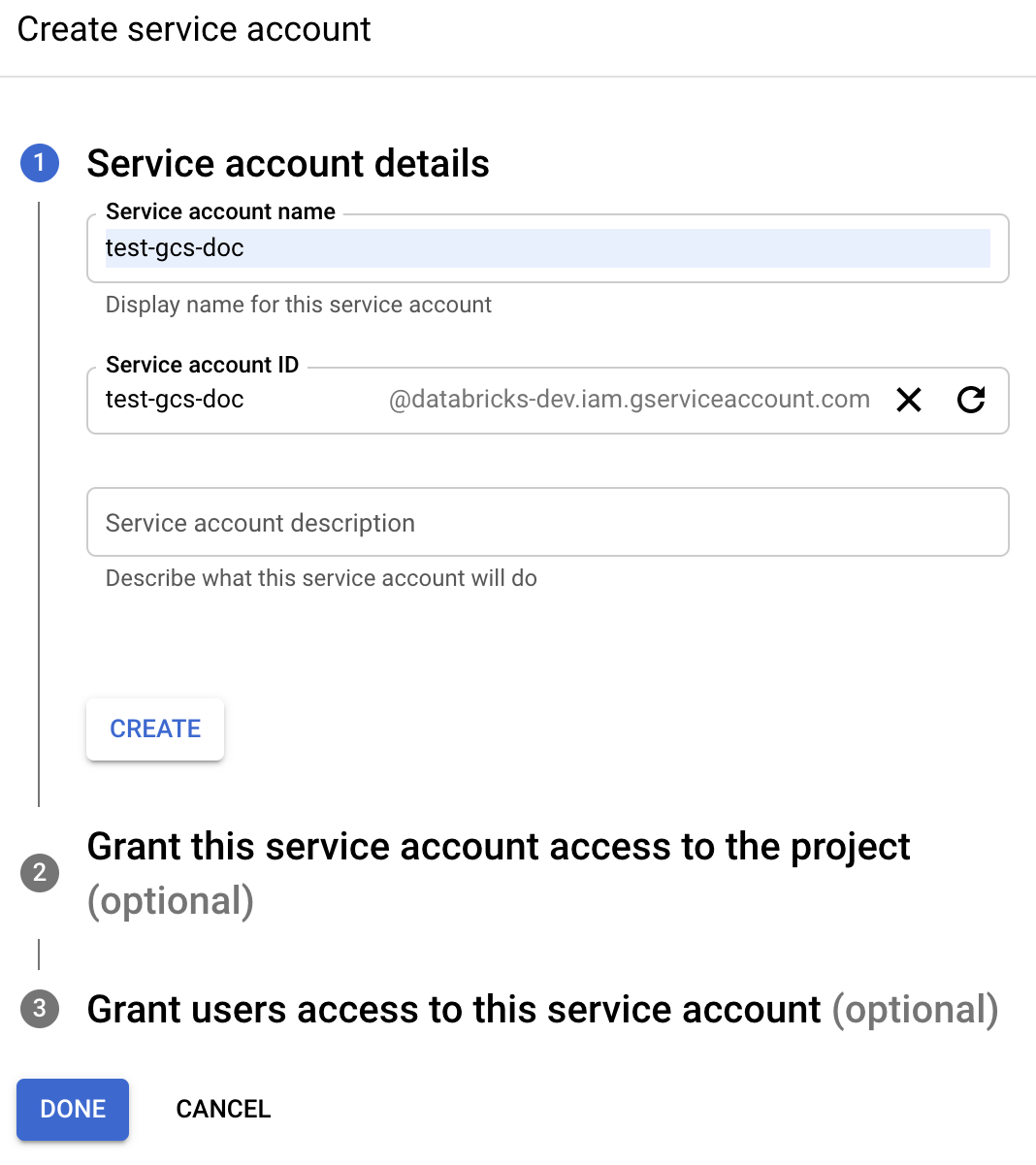
Kliknij przycisk UTWÓRZ.
Kliknij pozycję CONTINUE (KONTYNUUJ).
Kliknij przycisk GOTOWE.
Krok 2. Tworzenie klucza w celu uzyskania bezpośredniego dostępu do zasobnika GCS
Ostrzeżenie
Klucz JSON generowany dla konta usługi jest kluczem prywatnym, który powinien być udostępniany tylko autoryzowanym użytkownikom, ponieważ kontroluje dostęp do zestawów danych i zasobów na koncie usługi Google Cloud.
- W konsoli Google Cloud na liście kont usług kliknij nowo utworzone konto.
- W sekcji Klucze kliknij pozycję DODAJ KLUCZ > Utwórz nowy klucz.
- Zaakceptuj typ klucza JSON.
- Kliknij przycisk UTWÓRZ. Plik klucza jest pobierany na komputer.
Krok 3. Konfigurowanie zasobnika GCS
Tworzenie zasobnika
Jeśli nie masz jeszcze zasobnika, utwórz go:
Kliknij pozycję Magazyn w okienku nawigacji po lewej stronie.
Kliknij pozycję UTWÓRZ ZASOBNIK.
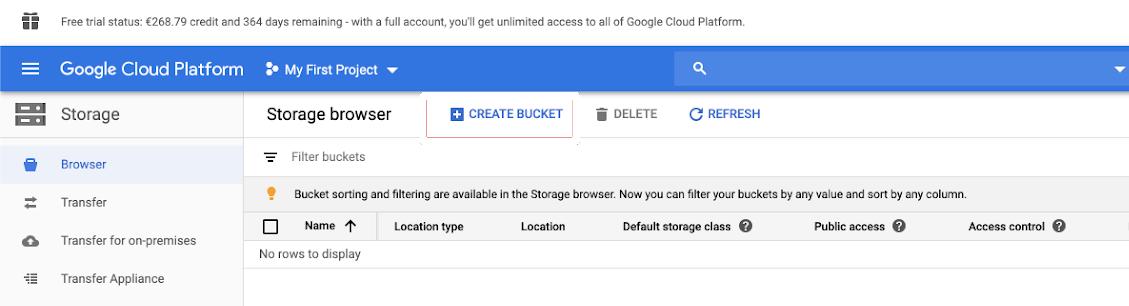
Kliknij przycisk UTWÓRZ.
Konfigurowanie zasobnika
Skonfiguruj szczegóły zasobnika.
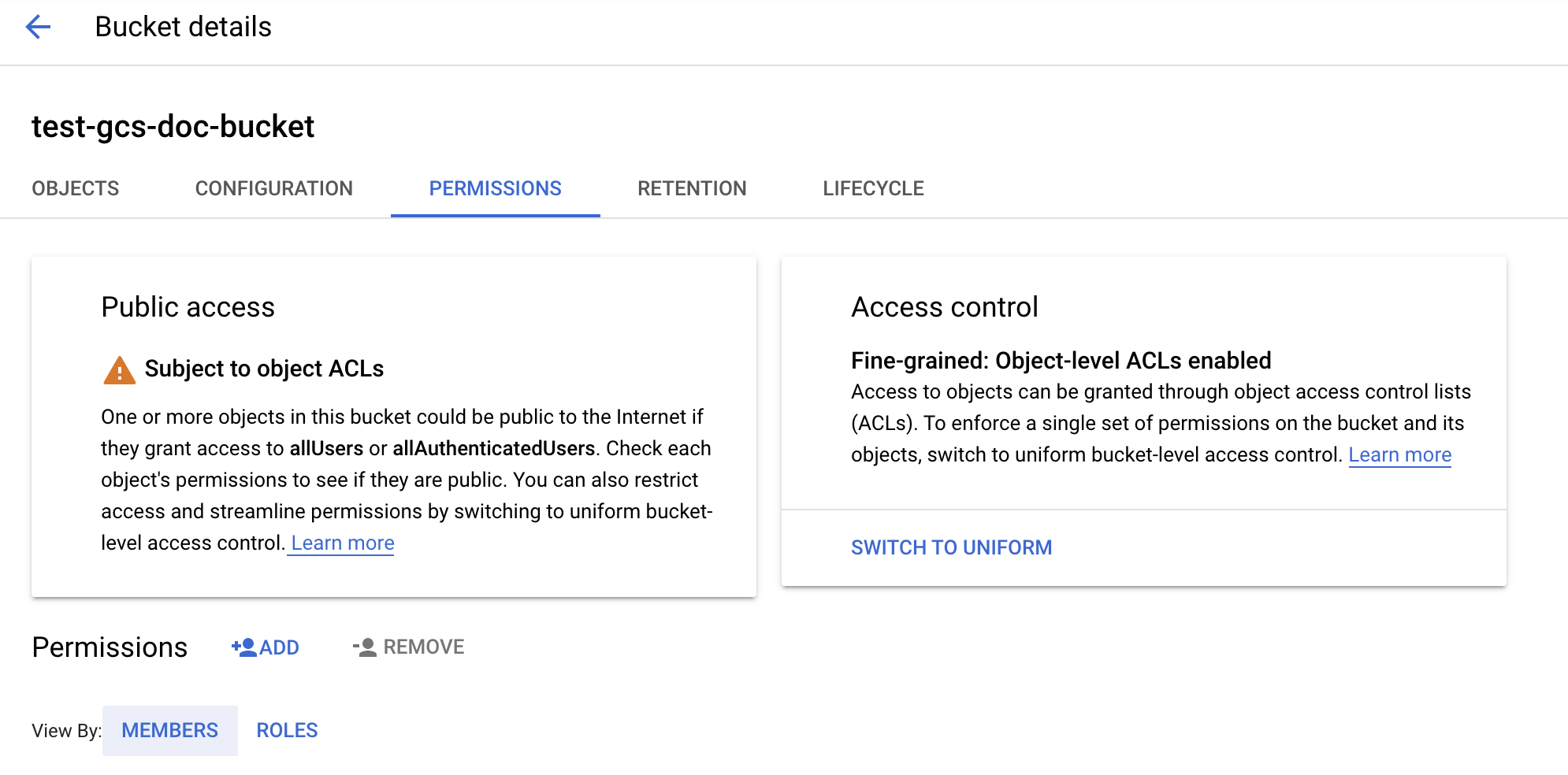
Kliknij kartę Uprawnienia .
Obok etykiety Uprawnienia kliknij pozycję DODAJ.
Podaj uprawnienia administratora magazynu do konta usługi w zasobniku z ról magazynu w chmurze.
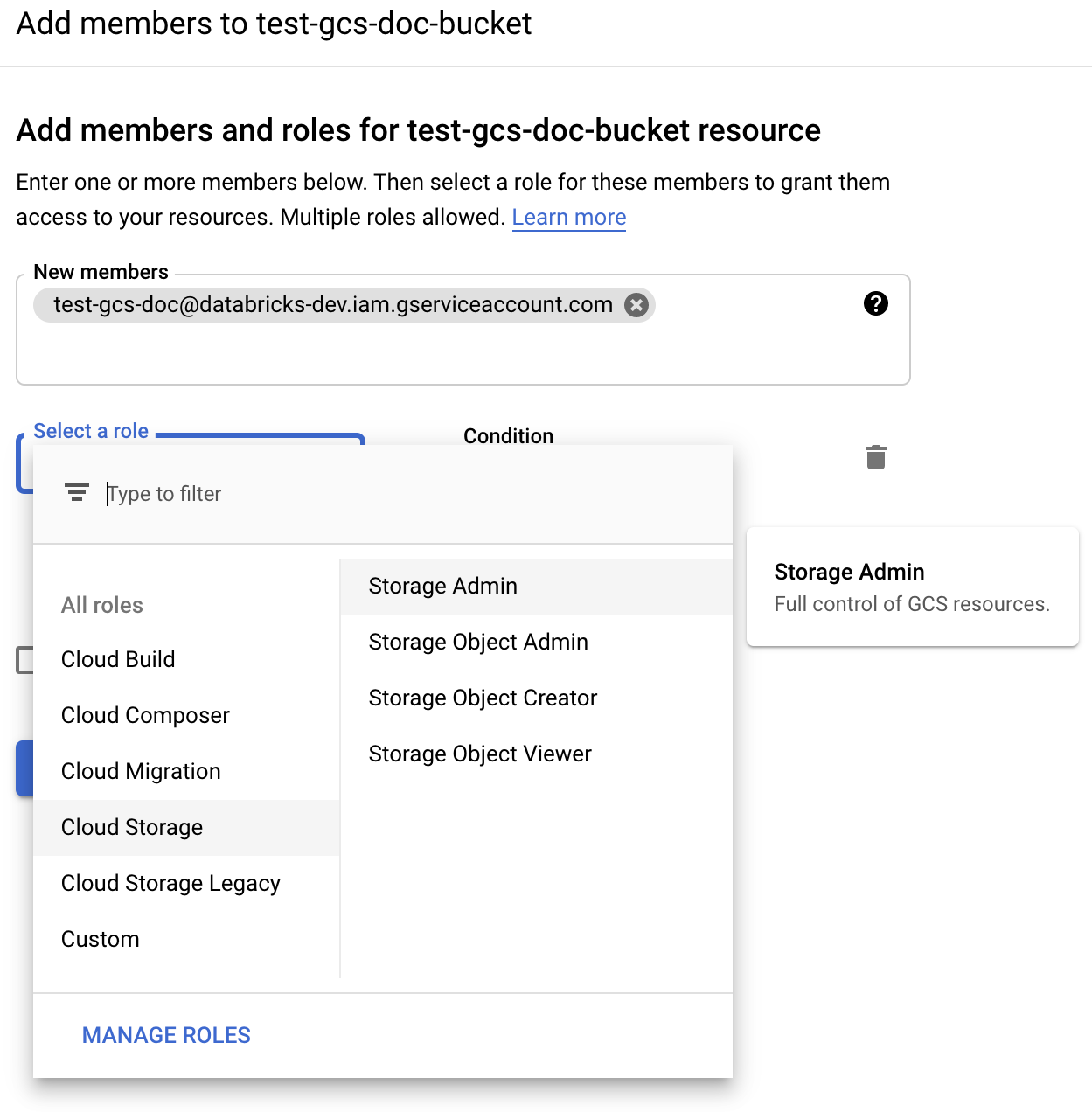
Kliknij przycisk SAVE (Zapisz).
Krok 4. Umieszczenie klucza konta usługi w wpisach tajnych usługi Databricks
Usługa Databricks zaleca używanie zakresów wpisów tajnych do przechowywania wszystkich poświadczeń. Klucz prywatny i identyfikator klucza prywatnego można umieścić z pliku JSON klucza w zakresach wpisów tajnych usługi Databricks. Możesz przyznać użytkownikom, jednostkom usługi i grupom w obszarze roboczym dostęp do odczytu zakresów wpisów tajnych. Chroni to klucz konta usługi, umożliwiając użytkownikom dostęp do usługi GCS. Aby utworzyć zakres wpisów tajnych, zobacz Zarządzanie wpisami tajnymi.
Krok 5. Konfigurowanie klastra usługi Azure Databricks
Na karcie Konfiguracja platformy Spark skonfiguruj konfigurację globalną lub konfigurację zasobnika. W poniższych przykładach klucze są ustawiane przy użyciu wartości przechowywanych jako wpisy tajne usługi Databricks.
Uwaga
Użyj kontroli dostępu do klastra i kontroli dostępu do notesu razem, aby chronić dostęp do konta usługi i danych w zasobniku GCS. Zobacz Uprawnienia obliczeniowe i Współpraca przy użyciu notesów usługi Databricks.
Konfiguracja globalna
Użyj tej konfiguracji, jeśli podane poświadczenia powinny być używane do uzyskiwania dostępu do wszystkich zasobników.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Zastąp ciąg <client-email>, <project-id> wartościami tych dokładnych nazw pól z pliku JSON klucza.
Konfiguracja zasobnika
Użyj tej konfiguracji, jeśli musisz skonfigurować poświadczenia dla określonych zasobników. Składnia konfiguracji poszczególnych zasobników dołącza nazwę zasobnika na końcu każdej konfiguracji, jak w poniższym przykładzie.
Ważne
Konfiguracje poszczególnych zasobników mogą być używane oprócz konfiguracji globalnych. Po określeniu konfiguracje poszczególnych zasobników zastępują konfiguracje globalne.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Zastąp ciąg <client-email>, <project-id> wartościami tych dokładnych nazw pól z pliku JSON klucza.
Krok 6. Odczyt z usługi GCS
Aby odczytać z zasobnika GCS, użyj polecenia odczytu platformy Spark w dowolnym obsługiwanym formacie, na przykład:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Aby zapisać w zasobniku GCS, użyj polecenia zapisu platformy Spark w dowolnym obsługiwanym formacie, na przykład:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Zastąp <bucket-name> ciąg nazwą zasobnika utworzonego w kroku 3: Konfigurowanie zasobnika GCS.