Google BigQuery
W tym artykule opisano sposób odczytywania i zapisywania w tabelach Google BigQuery w usłudze Azure Databricks.
Ważne
Konfiguracje opisane w tym artykule są eksperymentalne. Funkcje eksperymentalne są udostępniane zgodnie z oczekiwaniami i nie są obsługiwane przez usługę Databricks za pośrednictwem pomocy technicznej klienta. Aby uzyskać pełną obsługę federacji zapytań, należy zamiast tego użyć usługi Lakehouse Federation, która umożliwia użytkownikom usługi Azure Databricks korzystanie ze składni wykazu aparatu Unity i narzędzi do zapewniania ładu danych.
Musisz nawiązać połączenie z usługą BigQuery przy użyciu uwierzytelniania opartego na kluczach.
Uprawnienia
Twoje projekty muszą mieć określone uprawnienia Google do odczytu i zapisu przy użyciu trybu BigQuery.
Uwaga
W tym artykule omówiono zmaterializowane poglądy BigQuery. Aby uzyskać szczegółowe informacje, zobacz artykuł Google Introduction to materialized views (Wprowadzenie do zmaterializowanych widoków). Aby poznać inną terminologię bigquery i model zabezpieczeń BigQuery, zobacz dokumentację usługi Google BigQuery.
Odczytywanie i zapisywanie danych za pomocą trybu BigQuery zależy od dwóch projektów Google Cloud:
- Project (
project): identyfikator projektu Google Cloud, z którego usługa Azure Databricks odczytuje lub zapisuje tabelę BigQuery. - Projekt nadrzędny (
parentProject): identyfikator projektu nadrzędnego, który jest identyfikatorem projektu Google Cloud do rozliczania za odczytywanie i zapisywanie. Ustaw tę opcję na projekt Google Cloud skojarzony z kontem usługi Google, dla którego będą generowane klucze.
Musisz jawnie podać project wartości i parentProject w kodzie, który uzyskuje dostęp do trybu BigQuery. Użyj kodu podobnego do następującego:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Wymagane uprawnienia dla projektów Google Cloud zależą od tego, czy project i parentProject są takie same. W poniższych sekcjach wymieniono wymagane uprawnienia dla każdego scenariusza.
Uprawnienia wymagane, jeśli project i parentProject są zgodne
Jeśli identyfikatory dla Użytkownika project i parentProject są takie same, użyj poniższej tabeli, aby określić minimalne uprawnienia:
| Zadanie usługi Azure Databricks | Uprawnienia Google wymagane w projekcie |
|---|---|
| Odczytywanie tabeli BigQuery bez zmaterializowanego widoku | W projekcie project :— Użytkownik sesji odczytu bigquery — Podgląd danych BigQuery (opcjonalnie przyznaj to na poziomie zestawu danych/tabeli zamiast na poziomie projektu) |
| Odczytywanie tabeli BigQuery zmaterializowanym widokiem | W projekcie project :— Użytkownik zadania BigQuery — Użytkownik sesji odczytu bigquery — Podgląd danych BigQuery (opcjonalnie przyznaj to na poziomie zestawu danych/tabeli zamiast na poziomie projektu) W projekcie materializacji: - Edytor danych bigquery |
| Pisanie tabeli BigQuery | W projekcie project :— Użytkownik zadania BigQuery - Edytor danych bigquery |
Uprawnienia wymagane, jeśli project i parentProject są inne
Jeśli identyfikatory dla Użytkownika project i parentProject są różne, użyj poniższej tabeli, aby określić minimalne uprawnienia:
| Zadanie usługi Azure Databricks | Wymagane uprawnienia google |
|---|---|
| Odczytywanie tabeli BigQuery bez zmaterializowanego widoku | W projekcie parentProject :— Użytkownik sesji odczytu bigquery W projekcie project :— Podgląd danych BigQuery (opcjonalnie przyznaj to na poziomie zestawu danych/tabeli zamiast na poziomie projektu) |
| Odczytywanie tabeli BigQuery zmaterializowanym widokiem | W projekcie parentProject :— Użytkownik sesji odczytu bigquery — Użytkownik zadania BigQuery W projekcie project :— Podgląd danych BigQuery (opcjonalnie przyznaj to na poziomie zestawu danych/tabeli zamiast na poziomie projektu) W projekcie materializacji: - Edytor danych bigquery |
| Pisanie tabeli BigQuery | W projekcie parentProject :— Użytkownik zadania BigQuery W projekcie project :- Edytor danych bigquery |
Krok 1. Konfigurowanie chmury Google
Włączanie interfejsu API usługi BigQuery Storage
Interfejs API usługi BigQuery Storage jest domyślnie włączony w nowych projektach Google Cloud, w których jest włączona funkcja BigQuery. Jeśli jednak masz istniejący projekt i interfejs API usługi BigQuery Storage nie jest włączony, wykonaj kroki opisane w tej sekcji, aby je włączyć.
Interfejs API usługi BigQuery Storage można włączyć przy użyciu interfejsu wiersza polecenia usługi Google Cloud lub konsoli Google Cloud Console.
Włączanie interfejsu API usługi BigQuery Storage przy użyciu interfejsu wiersza polecenia usługi Google Cloud
gcloud services enable bigquerystorage.googleapis.com
Włączanie interfejsu API magazynu BigQuery przy użyciu konsoli Google Cloud Console
Kliknij pozycję Interfejsy API i usługi w okienku nawigacji po lewej stronie.
Kliknij przycisk WŁĄCZ INTERFEJSY API I USŁUGI.
Wpisz
bigquery storage apina pasku wyszukiwania i wybierz pierwszy wynik.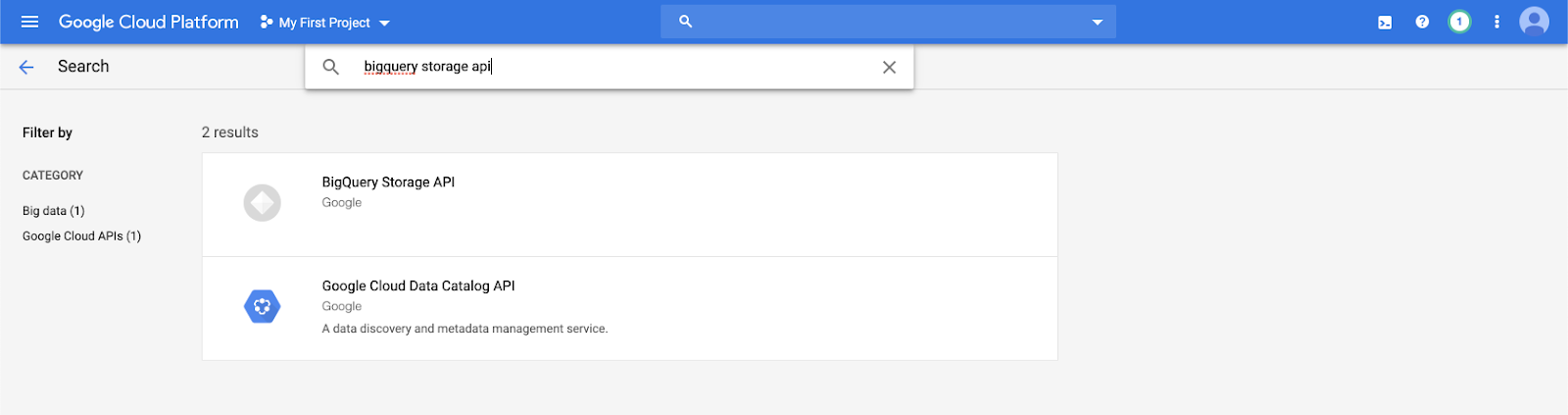
Upewnij się, że interfejs API usługi BigQuery Storage jest włączony.
Tworzenie konta usługi Google dla usługi Azure Databricks
Utwórz konto usługi dla klastra usługi Azure Databricks. Usługa Databricks zaleca nadanie temu kontu usługi najmniejszych uprawnień potrzebnych do wykonywania zadań. Zobacz Role i uprawnienia bigquery.
Konto usługi można utworzyć przy użyciu interfejsu wiersza polecenia usługi Google Cloud lub konsoli Google Cloud Console.
Tworzenie konta usługi Google przy użyciu interfejsu wiersza polecenia usługi Google Cloud
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Utwórz klucze dla konta usługi:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Tworzenie konta usługi Google przy użyciu konsoli Google Cloud Console
Aby utworzyć konto:
Kliknij pozycję Zarządzanie dostępem i tożsamościami i administratorem w okienku nawigacji po lewej stronie.
Kliknij pozycję Konta usług.
Kliknij pozycję + UTWÓRZ KONTO USŁUGI.
Wprowadź nazwę i opis konta usługi.
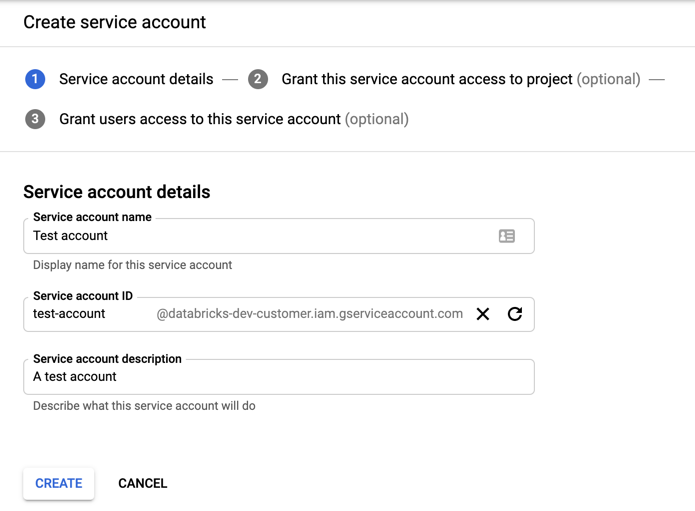
Kliknij przycisk UTWÓRZ.
Określ role dla konta usługi. Na liście rozwijanej Wybierz rolę wpisz
BigQueryi dodaj następujące role: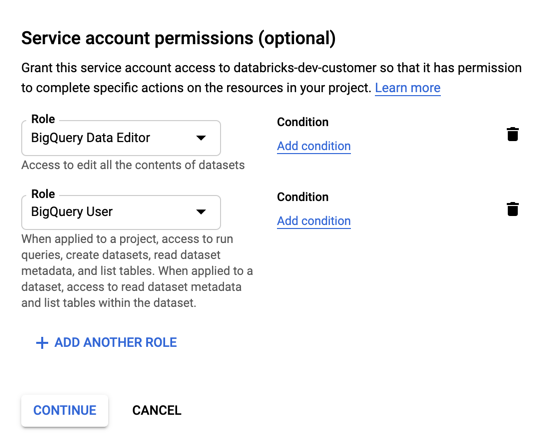
Kliknij pozycję CONTINUE (KONTYNUUJ).
Kliknij przycisk GOTOWE.
Aby utworzyć klucze dla konta usługi:
Na liście kont usług kliknij nowo utworzone konto.
W sekcji Klucze wybierz przycisk DODAJ KLUCZ > Utwórz nowy klucz .
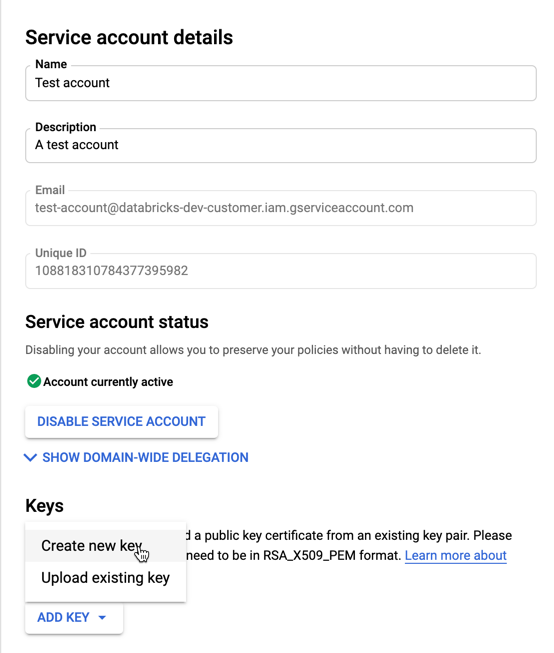
Zaakceptuj typ klucza JSON.
Kliknij przycisk UTWÓRZ. Plik klucza JSON jest pobierany na komputer.
Ważne
Plik klucza JSON generowany dla konta usługi jest kluczem prywatnym, który powinien być udostępniany tylko autoryzowanym użytkownikom, ponieważ kontroluje dostęp do zestawów danych i zasobów na koncie usługi Google Cloud.
Tworzenie zasobnika usługi Google Cloud Storage (GCS) dla magazynu tymczasowego
Aby zapisywać dane w trybie BigQuery, źródło danych musi mieć dostęp do zasobnika GCS.
Kliknij pozycję Magazyn w okienku nawigacji po lewej stronie.
Kliknij pozycję UTWÓRZ ZASOBNIK.
Skonfiguruj szczegóły zasobnika.
Kliknij przycisk UTWÓRZ.
Kliknij kartę Uprawnienia i Dodaj członków.
Podaj następujące uprawnienia do konta usługi w zasobniku.
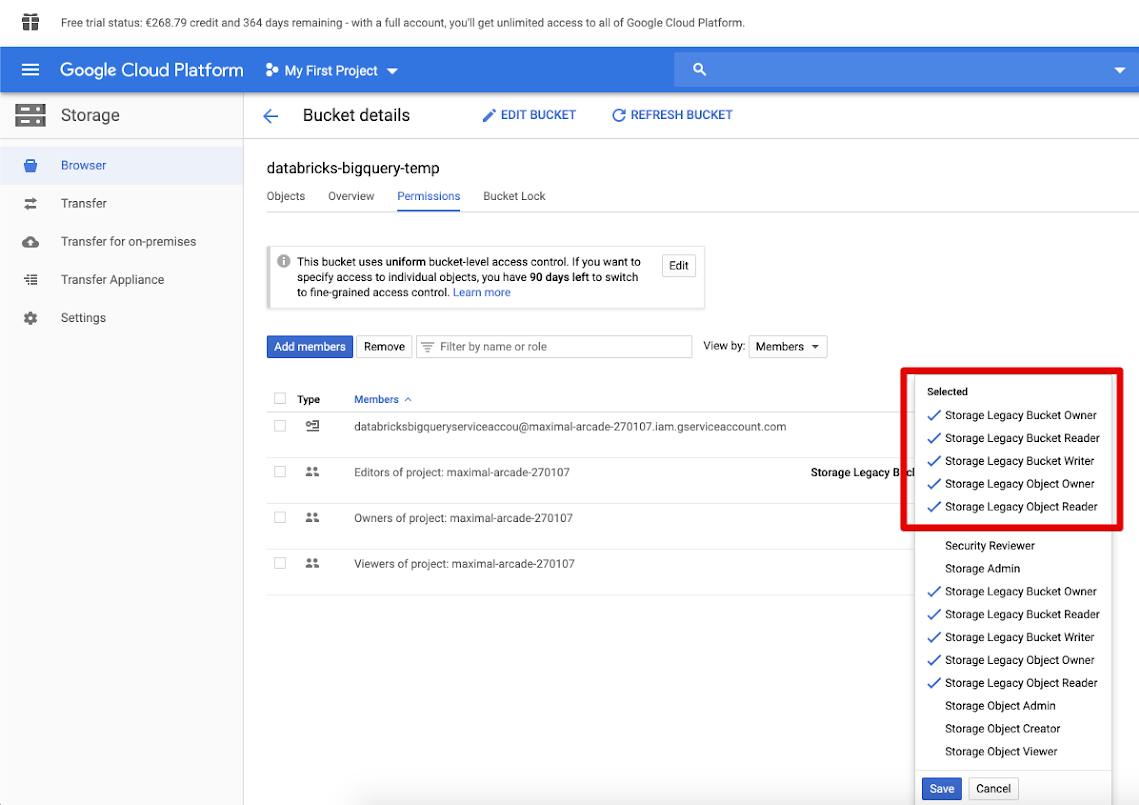
Kliknij przycisk SAVE (Zapisz).
Krok 2. Konfigurowanie usługi Azure Databricks
Aby skonfigurować klaster w celu uzyskania dostępu do tabel BigQuery, należy podać plik klucza JSON jako konfigurację platformy Spark. Użyj narzędzia lokalnego, aby zakodować plik klucza JSON w formacie Base64. W celach bezpieczeństwa nie należy używać internetowego ani zdalnego narzędzia, które może uzyskiwać dostęp do kluczy.
Podczas konfigurowania klastra:
Na karcie Konfiguracja platformy Spark dodaj następującą konfigurację platformy Spark. Zastąp <base64-keys> ciąg ciągiem pliku klucza JSON zakodowanego w formacie Base64. Zastąp inne elementy w nawiasach kwadratowych (na przykład <client-email>) wartościami tych pól z pliku klucza JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Odczytywanie i zapisywanie w tabeli BigQuery
Aby odczytać tabelę BigQuery, określ
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Aby zapisać dane w tabeli BigQuery, określ
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
gdzie <bucket-name> to nazwa zasobnika utworzonego w zasobniku Tworzenie zasobnika usługi Google Cloud Storage (GCS) dla magazynu tymczasowego. Zobacz Uprawnienia , aby dowiedzieć się więcej o wymaganiach <project-id> i <parent-id> wartościach.
Tworzenie tabeli zewnętrznej na podstawie zapytania BigQuery
Ważne
Ta funkcja nie jest obsługiwana przez wykaz aparatu Unity.
Tabelę niezarządzaną można zadeklarować w usłudze Databricks, która odczytuje dane bezpośrednio z trybu BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Przykład notesu języka Python: ładowanie tabeli Google BigQuery do ramki danych
Poniższy notes języka Python ładuje tabelę Google BigQuery do ramki danych usługi Azure Databricks.
Przykładowy notes Google BigQuery Python
Przykład notesu Scala: ładowanie tabeli Google BigQuery do ramki danych
Poniższy notes Scala ładuje tabelę Google BigQuery do ramki danych usługi Azure Databricks.