Przyrostowe ładowanie danych z wielu tabel w programie SQL Server do bazy danych w usłudze Azure SQL Database przy użyciu witryny Azure Portal
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz usługę Azure Data Factory z potokiem, który ładuje dane różnicowe z wielu tabel w bazie danych programu SQL Server do bazy danych w usłudze Azure SQL Database.
Ten samouczek obejmuje następujące procedury:
- Przygotowanie źródłowych i docelowych magazynów danych
- Tworzenie fabryki danych.
- Utwórz własne środowisko Integration Runtime.
- Instalowanie środowiska Integration Runtime.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie, uruchamianie i monitorowanie potoku
- Przejrzyj wyniki.
- Dodawanie lub aktualizowanie danych w tabelach źródłowych.
- Ponowne uruchamianie i monitorowanie potoku.
- Przegląd wyników końcowych.
Omówienie
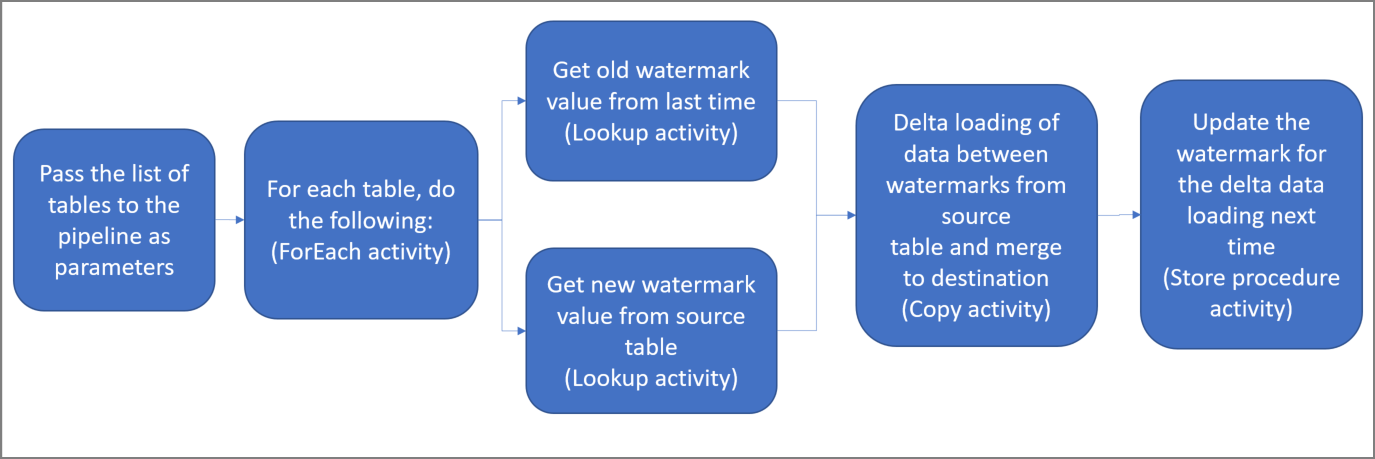
Poniżej przedstawiono ważne czynności związane z tworzeniem tego rozwiązania:
Wybierz kolumnę limitu.
Wybierz jedną kolumnę dla każdej tabeli w magazynie danych źródłowych, która może służyć do identyfikowania nowych lub zaktualizowanych rekordów dla każdego uruchomienia. Zazwyczaj dane w tej wybranej kolumnie (na przykład last_modify_time lub ID) rosną wraz z tworzeniem i aktualizacją wierszy. Maksymalna wartość w tej kolumnie jest używana jako limit.
Przygotuj magazyn danych do przechowywania wartości limitu.
W tym samouczku wartość limitu jest przechowywana w bazie danych SQL.
Utwórz potok z następującymi działaniami:
a. Utwórz działanie ForEach służące do przeprowadzania iteracji po liście nazw tabel źródłowych przekazywanych jako parametr do potoku. Dla każdej tabeli źródłowej wywołuje ono następujące działania służące do wykonywania ładowania przyrostowego dla tej tabeli.
b. Utwórz dwa działania lookup. Użyj pierwszego działania Lookup do pobrania ostatniej wartości limitu. Użyj drugiego działania Lookup do pobrania nowej wartości limitu. Te wartości limitu są przekazywane do działania Copy.
c. Utwórz działanie Copy, które kopiuje wiersze z magazynu danych źródłowych o wartości kolumny limitu większej niż poprzednia wartość limitu i mniejszej niż nowa wartość limitu. Następnie kopiuje dane różnicowe ze źródłowego magazynu danych do usługi Azure Blob Storage jako nowy plik.
d. Utwórz działanie StoredProcedure, które aktualizuje wartość limitu dla potoku przy następnym uruchomieniu.
Diagram ogólny rozwiązania wygląda następująco:
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- SQL Server. Baza danych programu SQL Server jest używana jako źródłowy magazyn danych w tym samouczku.
- Usługa Azure SQL Database. Baza danych w usłudze Azure SQL Database jest używana jako magazyn danych ujścia. Jeśli nie masz bazy danych w usłudze SQL Database, zobacz Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
Tworzenie tabel źródłowych w bazie danych SQL Server
Otwórz program SQL Server Management Studio i połącz się z bazą danych programu SQL Server.
W Eksploratorze serwera kliknij prawym przyciskiem myszy bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych w celu utworzenia tabel o nazwach
customer_tableiproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Tworzenie tabel docelowych w bazie danych
Otwórz program SQL Server Management Studio i połącz się z bazą danych w usłudze Azure SQL Database.
W Eksploratorze serwera kliknij prawym przyciskiem myszy bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych w celu utworzenia tabel o nazwach
customer_tableiproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Utwórz inną tabelę w bazie danych, aby przechowywać wartość wysokiego limitu
Uruchom następujące polecenie SQL względem bazy danych, aby utworzyć tabelę o nazwie
watermarktabledo przechowywania wartości limitu:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Wstaw początkowe wartości limitu dla obu tabel źródłowych w tabeli wartości limitu.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Tworzenie procedury składowanej w bazie danych
Uruchom następujące polecenie, aby utworzyć procedurę składowaną w bazie danych. Ta procedura składowana służy do aktualizowania wartość limitu po każdym uruchomieniu potoku.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Tworzenie typów danych i dodatkowych procedur składowanych w bazie danych
Uruchom następujące zapytanie, aby utworzyć dwie procedury składowane i dwa typy danych w bazie danych. Służą one do scalania danych z tabel źródłowych w tabelach docelowych.
Aby ułatwić rozpoczęcie podróży, użyjemy bezpośrednio tych procedur składowanych przekazujących dane różnicowe za pośrednictwem zmiennej tabeli, a następnie scalimy je z magazynem docelowym. Należy zachować ostrożność, że nie oczekuje się, że w zmiennej tabeli będzie przechowywana "duża" liczba wierszy różnicowych (ponad 100).
Jeśli musisz scalić dużą liczbę wierszy różnicowych z magazynem docelowym, zalecamy użycie działania kopiowania w celu skopiowania wszystkich danych różnicowych do tymczasowej tabeli przejściowej w magazynie docelowym, a następnie skompilowanie własnej procedury składowanej bez użycia zmiennej tabeli tabeli w celu scalenia ich z tabeli "przejściowej" do tabeli "końcowej".
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Tworzenie fabryki danych
Uruchom przeglądarkę internetową Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko przez przeglądarki internetowe Microsoft Edge i Google Chrome.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Integration>Data Factory:
Na stronie Nowa fabryka danych wprowadź wartość ADFMultiIncCopyTutorialDF w polu nazwa.
Nazwa usługi Azure Data Factory musi być globalnie unikatowa. Jeśli pojawi się czerwony wykrzyknik z poniższym błędem, zmień nazwę fabryki danych (np. twojanazwaADFIncCopyTutorialDF) i spróbuj utworzyć ją ponownie. Artykuł Data Factory — Naming Rules (Usługa Data Factory — reguły nazewnictwa) zawiera reguły nazewnictwa artefaktów usługi Data Factory.
Data factory name "ADFIncCopyTutorialDF" is not availableWybierz subskrypcję Azure, w której chcesz utworzyć fabrykę danych.
Dla opcji Grupa zasobów wykonaj jedną z następujących czynności:
- Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
- Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
Wybierz opcję V2 w obszarze Wersja.
Na liście lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (Azure Storage, Azure SQL Database itp.) i jednostki obliczeniowe (HDInsight itp.) używane przez fabrykę danych mogą mieścić się w innych regionach.
Kliknij pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych, jak pokazano na poniższej ilustracji.

Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio , aby uruchomić interfejs użytkownika usługi Azure Data Factory na osobnej karcie.
Create self-hosted integration runtime (Tworzenie środowiska Integration Runtime (Self-hosted)
Podczas przenoszenia danych z magazynu danych w sieci prywatnej (lokalnej) do magazynu danych platformy Azure zainstaluj własne środowisko Integration Runtime (IR) w środowisku lokalnym. Własne środowisko IR przenosi dane między siecią prywatną a platformą Azure.
Na stronie głównej interfejsu użytkownika usługi Azure Data Factory wybierz kartę Zarządzanie w okienku po lewej stronie.
Wybierz pozycję Środowiska Integration Runtime w okienku po lewej stronie, a następnie wybierz pozycję +Nowy.
W oknie Konfiguracja środowiska Integration Runtime wybierz pozycję Wykonaj przenoszenie danych i wysyłanie działań do obliczeń zewnętrznych, a następnie kliknij przycisk Kontynuuj.
Wybierz pozycję Self-Hosted (Self-Hosted), a następnie kliknij przycisk Kontynuuj.
Wprowadź wartość MySelfHostedIR w polu Nazwa, a następnie kliknij pozycję Utwórz.
Kliknij pozycję Click here to launch the express setup for this computer (Kliknij tutaj, aby uruchomić instalację ekspresową dla tego komputera) w sekcji Opcja 1: Instalacja ekspresowa.
W oknie Instalacja ekspresowa środowiska Integration Runtime (Self-hosted) kliknij przycisk Zamknij.
W przeglądarce internetowej w oknie instalatora środowiska Integration Runtime kliknij przycisk Zakończ.
Upewnij się, że na liście środowisk Integration Runtime jest widoczna pozycja MySelfHostedIR.
Tworzenie połączonych usług
Połączone usługi tworzy się w fabryce danych w celu połączenia magazynów danych i usług obliczeniowych z fabryką danych. W tej sekcji utworzysz połączone usługi z bazą danych programu SQL Server i bazą danych w usłudze Azure SQL Database.
Tworzenie usługi połączonej z serwerem SQL Server
W tym kroku połączysz bazę danych programu SQL Server z fabryką danych.
W oknie Połączenia przejdź z karty Środowiska Integration Runtime do karty Połączone usługi, a następnie kliknij pozycję + Nowa.
W oknie Nowa połączona usługa wybierz pozycję SQL Server, a następnie kliknij pozycję Kontynuuj.
W oknie Nowa połączona usługa wykonaj następujące czynności:
- Wprowadź jako nazwę wartość SqlServerLinkedService.
- Wybierz pozycję MySelfHostedIR w polu Połącz za pośrednictwem środowiska Integration Runtime. Jest to ważny krok. Domyślne środowisko Integration Runtime nie może połączyć się z lokalnym magazynem danych. Użyj własnego środowiska Integration Runtime utworzonego wcześniej.
- W polu Nazwa serwera wprowadź nazwę komputera, na którym znajduje się baza danych programu SQL Server.
- W polu Nazwa bazy danych wprowadź nazwę bazy danych programu SQL Server, która zawiera dane źródłowe. Tworzenie tabeli i wstawienie danych do tej bazy danych zostało przeprowadzone w ramach wymagań wstępnych.
- W polu Typ uwierzytelniania wybierz typ uwierzytelniania, którego chcesz używać podczas łączenia się z bazą danych.
- W polu Nazwa użytkownika wprowadź nazwę użytkownika mającego dostęp do bazy danych programu SQL Server. Jeśli musisz użyć znaku ukośnika (
\) w nazwie konta użytkownika lub nazwie serwera, użyj znaku ucieczki (\). Może to być na przykładmydomain\\myuser. - W polu Hasło wprowadź hasło użytkownika.
- Aby sprawdzić, czy fabryka danych może połączyć się z bazą danych programu SQL Server, kliknij pozycję Testuj połączenie. Usuń wszelkie błędy, tak aby połączenie zostało nawiązane pomyślnie.
- Aby zapisać połączoną usługę, kliknij przycisk Zakończ.
Tworzenie połączonej usługi Azure SQL Database
W ostatnim kroku utworzysz połączoną usługę w celu połączenia źródłowej bazy danych programu SQL Server z fabryką danych. W tym kroku połączysz docelową/ujścia bazę danych z fabryką danych.
W oknie Połączenia przejdź z karty Środowiska Integration Runtime do karty Połączone usługi, a następnie kliknij pozycję + Nowa.
W oknie Nowa połączona usługa wybierz pozycję Azure SQL Database, a następnie kliknij pozycję Kontynuuj.
W oknie Nowa połączona usługa wykonaj następujące czynności:
- Wprowadź wartość AzureSqlDatabaseLinkedService w polu Nazwa.
- W polu Nazwa serwera wybierz nazwę serwera z listy rozwijanej.
- W polu Nazwa bazy danych wybierz bazę danych, w której utworzono customer_table i project_table w ramach wymagań wstępnych.
- W polu Nazwa użytkownika wprowadź nazwę użytkownika, który ma dostęp do bazy danych.
- W polu Hasło wprowadź hasło użytkownika.
- Aby sprawdzić, czy fabryka danych może połączyć się z bazą danych programu SQL Server, kliknij pozycję Testuj połączenie. Usuń wszelkie błędy, tak aby połączenie zostało nawiązane pomyślnie.
- Aby zapisać połączoną usługę, kliknij przycisk Zakończ.
Upewnij się, że lista zawiera dwie połączone usługi.
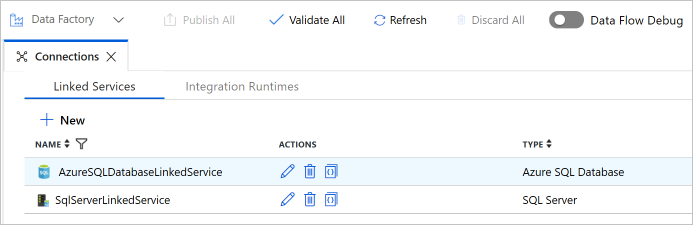
Tworzenie zestawów danych
W tym kroku utworzysz zestawy danych reprezentujące źródło danych, docelową lokalizację danych i lokalizację, w której będzie przechowywana wartość limitu.
Tworzenie zestawu danych źródłowych
W lewym okienku kliknij pozycję + (plus), a następnie kliknij pozycję Zestaw danych.
W oknie Nowy zestaw danych wybierz pozycję SQL Server, kliknij przycisk Kontynuuj.
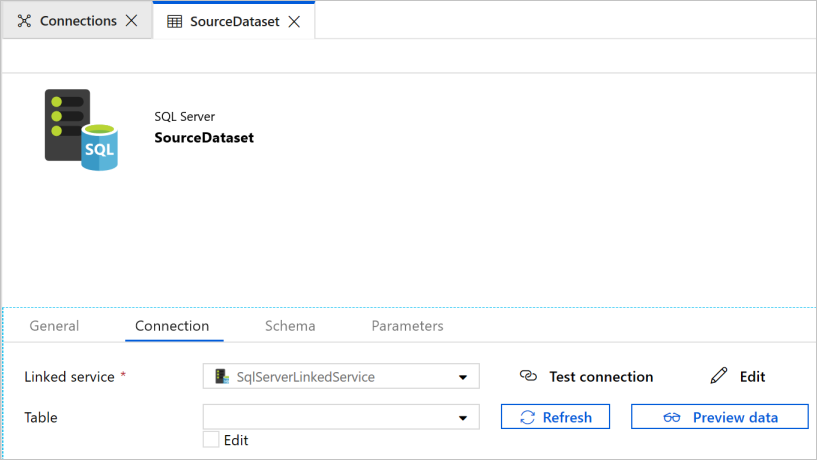
W przeglądarce sieci Web zostanie otwarta nowa karta służąca do konfigurowania zestawu danych. Zestaw danych jest również widoczny w widoku drzewa. U dołu karty Ogólne w oknie właściwości wprowadź wartość SourceDataset w polu Nazwa.
Przejdź do karty Połączenie w oknie właściwości, a następnie wybierz pozycję SqlServerLinkedService w polu Połączona usługa. Nie należy wybierać tabeli w tym miejscu. Działanie Copy w potoku korzysta z zapytania SQL do załadowania danych, a nie całej tabeli.
Tworzenie ujścia zestawu danych
W lewym okienku kliknij pozycję + (plus), a następnie kliknij pozycję Zestaw danych.
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
W przeglądarce sieci Web zostanie otwarta nowa karta służąca do konfigurowania zestawu danych. Zestaw danych jest również widoczny w widoku drzewa. U dołu karty Ogólne w oknie właściwości wprowadź wartość SinkDataset w polu Nazwa.
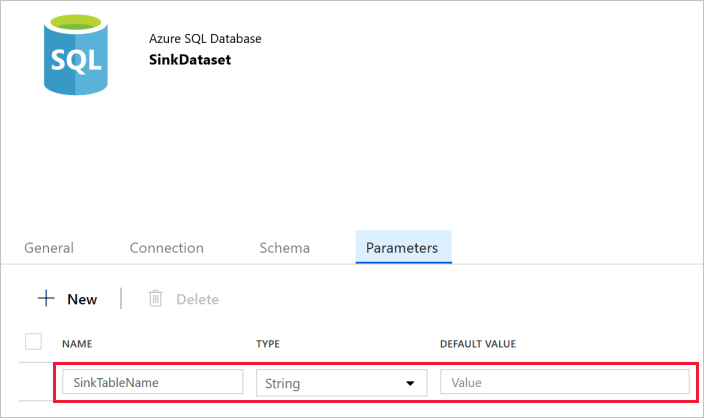
Przejdź do karty Parametry w oknie Właściwości i wykonaj następujące czynności:
Kliknij pozycję Nowy w sekcji Parametry tworzenia/aktualizacji.
Wprowadź wartość SinkTableName w polu nazwa i wartość Ciąg w polu typ. Ten zestaw danych otrzymuje wartość SinkTableName jako parametr. Parametr SinkTableName jest ustawiany dynamicznie przez potok w czasie wykonywania. Działanie ForEach w potoku przeprowadza iterację po liście nazw i przekazuje nazwę tabeli do tego zestawu danych w każdej iteracji.
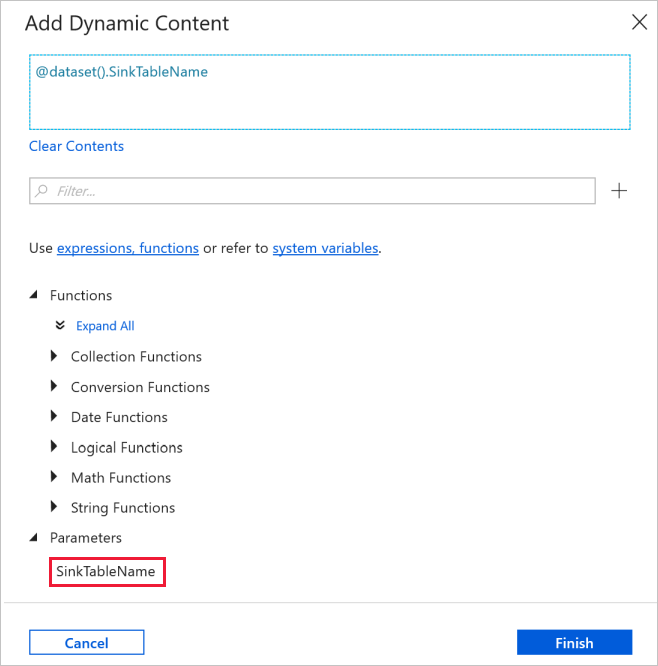
Przejdź do karty Połączenie w okno Właściwości i wybierz pozycję AzureSqlDatabaseLinkedService dla pozycji Połączona usługa. W obszarze właściwości Tabela kliknij pozycję Dodaj zawartość dynamiczną.
W oknie Dodawanie zawartości dynamicznej wybierz pozycję SinkTableName w sekcji Parametry.
Po kliknięciu przycisku Zakończ zostanie wyświetlony komunikat "@dataset(). SinkTableName" jako nazwa tabeli.
Tworzenie zestawu danych dla limitu
W tym kroku utworzysz zestaw danych do przechowywania wartości górnego limitu.
W lewym okienku kliknij pozycję + (plus), a następnie kliknij pozycję Zestaw danych.
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
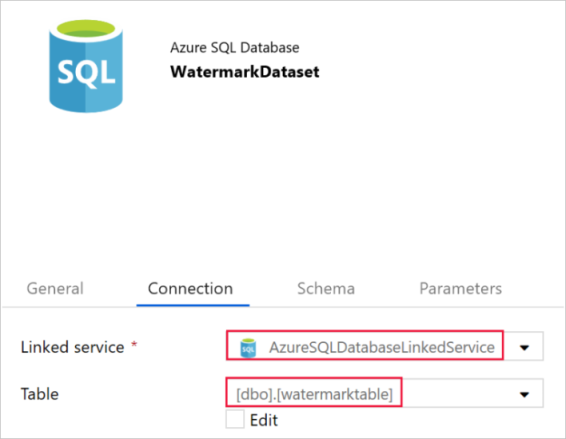
U dołu karty Ogólne w oknie właściwości wprowadź wartość WatermarkDataset w polu Nazwa.
Przejdź do karty Połączenie i wykonaj następujące czynności:
Wybierz wartość AzureSqlDatabaseLinkedService w polu Połączona usługa.
Wybierz element [dbo].[watermarktable] dla pozycji Tabela.
Tworzenie potoku
Potok przyjmuje listę nazw tabel jako parametr. Działanie ForEach służy do przeprowadzania iteracji po liście nazw tabel i wykonywania następujących operacji:
Użyj działania Lookup do pobrania starej wartość limitu (wartości początkowej lub wartości użytej w ostatniej iteracji).
Użyj działania Lookup do pobrania nowej wartości limitu (maksymalnej wartości kolumny limitu w tabeli źródłowej).
Użyj działania Copy do skopiowania danych między tymi dwiema wartościami limitu ze źródłowej bazy danych do docelowej bazy danych.
Użyj działania StoredProcedure do zaktualizowania starej wartości limitu, która zostanie użyta w pierwszym kroku następnej iteracji.
Tworzenie potoku
W lewym okienku kliknij pozycję + (plus), a następnie kliknij pozycję Potok.
W panelu Ogólne w obszarze Właściwości określ wartość IncrementalCopyPipeline w polu Nazwa. Następnie zwiń panel, klikając ikonę Właściwości w prawym górnym rogu.
Na karcie Parametry wykonaj następujące czynności:
- Kliknij pozycję + Nowy.
- Wprowadź ciąg tableList jako nazwę parametru.
- Wybierz pozycję Tablica dla typu parametru.
W przyborniku Działania rozwiń pozycję Iteracja i warunki, a następnie przeciągnij i upuść działanie ForEach na powierzchni projektanta potoku. Na karcie Ogólne w oknie Właściwości wprowadź wartość IterateSQLTables.
Przejdź do karty Ustawienia, a następnie wprowadź wartość
@pipeline().parameters.tableListw polu Elementy. Działanie ForEach przeprowadza iterację po liście tabel i wykonuje operację kopiowania przyrostowego.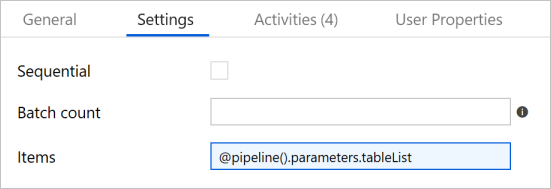
Wybierz działanie ForEach w potoku, jeśli jeszcze nie zostało wybrane. Kliknij przycisk Edytuj (ikonę ołówka).
W przyborniku Działania rozwiń pozycję SQL Database, przeciągnij i upuść działanie Lookup (Wyszukiwanie) na powierzchni projektanta potoku, a następnie wprowadź wartość LookupOldWaterMarkActivity w polu Nazwa.
Przejdź do karty Ustawienia w oknie Właściwości i wykonaj następujące czynności:
Wybierz pozycję WatermarkDataset w polu Zestaw danych będący źródłem.
Wybierz pozycję Zapytanie w polu Użyj zapytania.
W obszarze Zapytanie wprowadź następujące zapytanie SQL.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'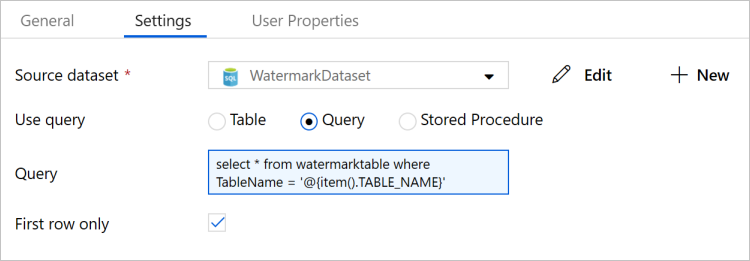
Przeciągnij działanie Lookup z przybornika Działania i wprowadź wartość LookupNewWaterMarkActivity w polu Nazwa.
Przejdź do karty Ustawienia.
Wybierz pozycję SourceDataset w obszarze Zestaw danych będący źródłem.
Wybierz pozycję Zapytanie w polu Użyj zapytania.
W obszarze Zapytanie wprowadź następujące zapytanie SQL.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}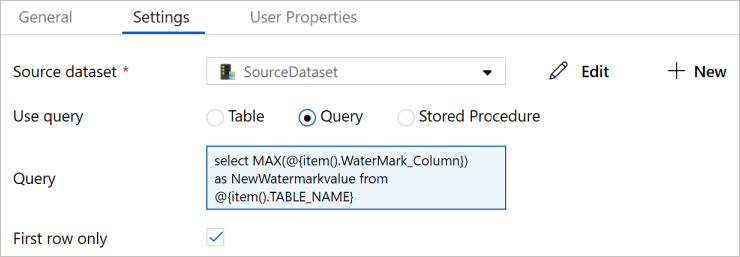
Przeciągnij działanie Copy (Kopiuj) z przybornika Działania i wprowadź wartość IncrementalCopyActivity w polu Nazwa.
Kolejno połącz działania Lookup z działaniem Copy. Aby utworzyć połączenie, zacznij przeciąganie w zielonym polu połączonym z działaniem Lookup i upuść je na działaniu Copy. Po zmianie koloru obramowania działania Copy na niebieski zwolnij przycisk myszy.
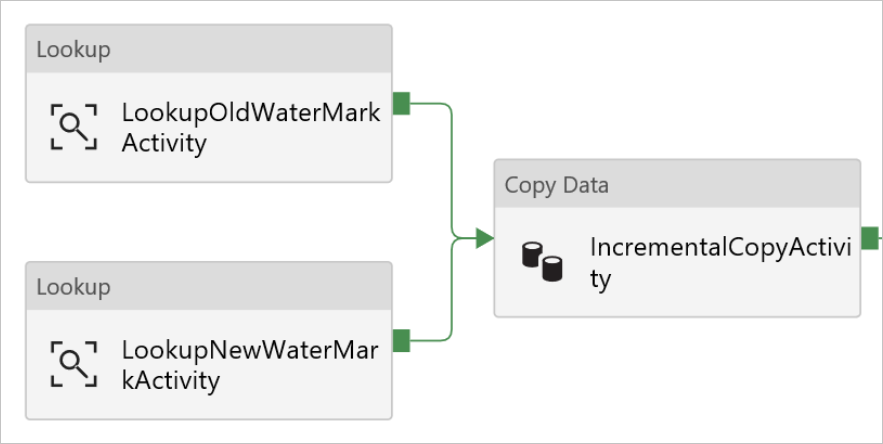
Wybierz działanie Copy w potoku. Przejdź do karty Źródło w oknie Właściwości.
Wybierz pozycję SourceDataset w obszarze Zestaw danych będący źródłem.
Wybierz pozycję Zapytanie w polu Użyj zapytania.
W obszarze Zapytanie wprowadź następujące zapytanie SQL.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'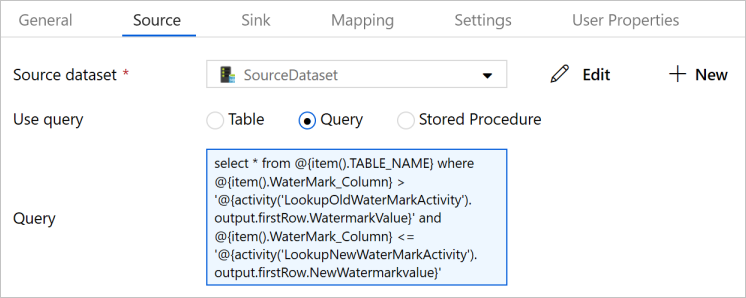
Przejdź do karty Ujście i wybierz pozycję SinkDataset w polu Zestaw danych będący ujściem.
Wykonaj poniższe kroki:
We właściwościach zestawu danych dla parametru SinkTableName wprowadź wartość
@{item().TABLE_NAME}.W polu Właściwość Nazwa procedury składowanej wprowadź wartość
@{item().StoredProcedureNameForMergeOperation}.W polu Właściwość typ tabeli wprowadź wartość
@{item().TableType}.W polu Nazwa parametru typu tabeli wprowadź wartość
@{item().TABLE_NAME}.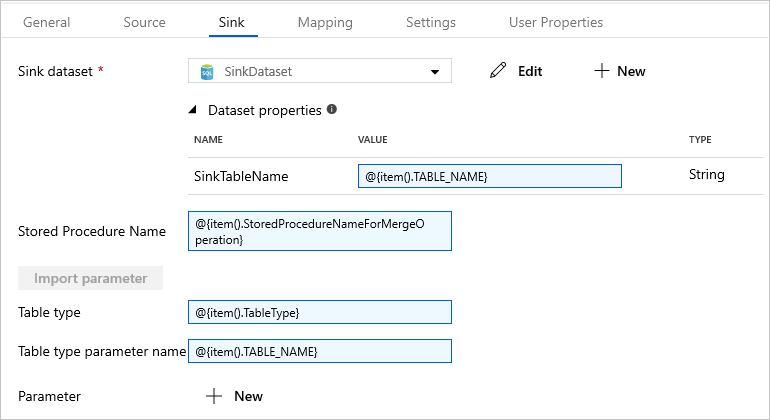
Przeciągnij działanie Stored Procedure (Procedura składowana) z przybornika Działania do powierzchni projektanta potoku. Połącz działanie Copy z działaniem Stored Procedure.
Wybierz działanie Stored Procedure w potoku, a następnie wprowadź wartość StoredProceduretoWriteWatermarkActivity w polu Nazwa na karcie Ogólne w oknie Właściwości.
Przejdź do karty Konto SQL i wybierz wartość AzureSqlDatabaseLinkedService w polu Połączona usługa.

Przejdź do karty Procedura składowana i wykonaj następujące czynności:
W polu Nazwa procedury składowanej wybierz wartość
[dbo].[usp_write_watermark].Wybierz pozycję Importuj parametr.
Określ wartości następujących parametrów:
Nazwisko Typ Wartość LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}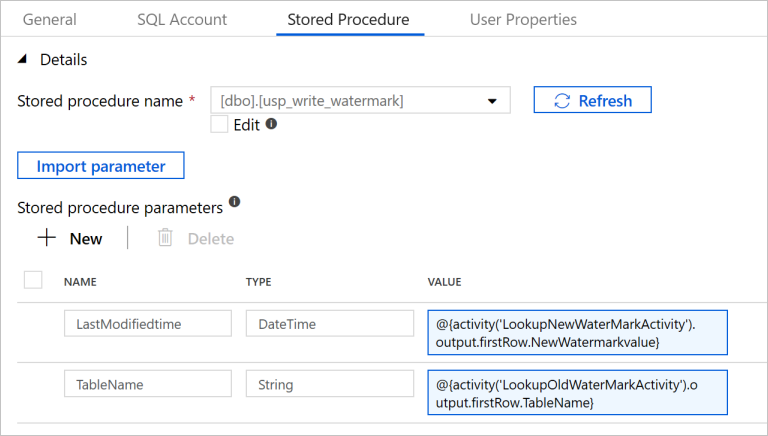
Wybierz pozycję Opublikuj wszystko , aby opublikować jednostki utworzone w usłudze Data Factory.
Poczekaj na wyświetlenie komunikatu Pomyślnie opublikowano. Aby wyświetlić powiadomienia, kliknij link Pokaż powiadomienia. Zamknij okno powiadomień, klikając przycisk X.
Uruchamianie potoku
Na pasku narzędzi potoku kliknij pozycję Dodaj wyzwalacz, a następnie kliknij pozycję Wyzwól teraz.
W oknie Uruchamianie potoku wprowadź następującą wartość dla parametru tableList, a następnie kliknij pozycję Zakończ.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]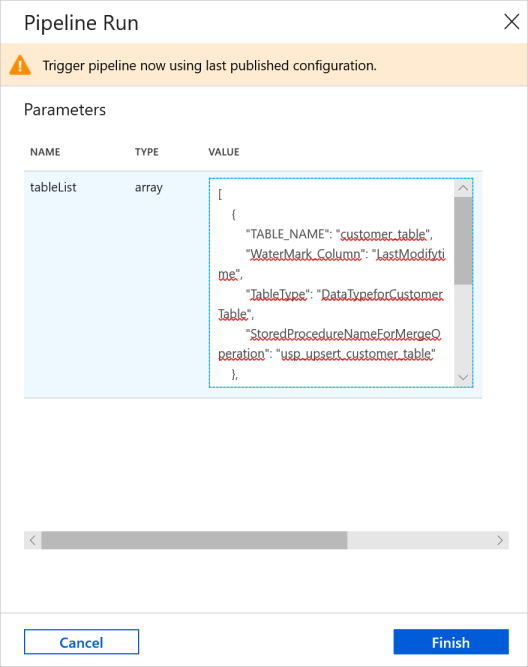
Monitor the pipeline (Monitorowanie potoku)
Przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlone uruchomienie potoku, które zostało wyzwolone za pomocą wyzwalacza ręcznego. Możesz użyć linków w kolumnie NAZWA POTOKu, aby wyświetlić szczegóły działania i ponownie uruchomić potok.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link w kolumnie NAZWA POTOKU. Aby uzyskać szczegółowe informacje na temat przebiegów działań, wybierz link Szczegóły (ikona okularów) w kolumnie NAZWA DZIAŁANIA.
Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku Uruchomienia potoku. Aby odświeżyć widok, wybierz pozycję Odśwież.
Sprawdzanie wyników
W programu SQL Server Management Studio uruchom następujące zapytania względem docelowej bazy danych Azure SQL Database, aby sprawdzić, czy dane zostały skopiowane z tabel źródłowych do tabel docelowych:
Zapytanie
select * from customer_table
Wyjście
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Zapytanie
select * from project_table
Wyjście
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Zapytanie
select * from watermarktable
Wyjście
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Należy zauważyć, że wartości limitu dla obu tabel zostały zaktualizowane.
Dodawanie większej ilości danych do tabel źródłowych
Uruchom następujące zapytanie względem źródłowej bazy danych programu SQL Server, aby zaktualizować istniejący wiersz w tabeli customer_table. Wstaw nowy wiersz do tabeli project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Ponowne uruchamianie potoku
W oknie przeglądarki sieci Web przejdź do karty Edycja po lewej stronie.
Na pasku narzędzi potoku kliknij pozycję Dodaj wyzwalacz, a następnie kliknij pozycję Wyzwól teraz.
W oknie Uruchamianie potoku wprowadź następującą wartość dla parametru tableList, a następnie kliknij pozycję Zakończ.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Ponowne monitorowanie potoku
Przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlone uruchomienie potoku, które zostało wyzwolone za pomocą wyzwalacza ręcznego. Możesz użyć linków w kolumnie NAZWA POTOKu, aby wyświetlić szczegóły działania i ponownie uruchomić potok.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link w kolumnie NAZWA POTOKU. Aby uzyskać szczegółowe informacje na temat przebiegów działań, wybierz link Szczegóły (ikona okularów) w kolumnie NAZWA DZIAŁANIA.
Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku Uruchomienia potoku. Aby odświeżyć widok, wybierz pozycję Odśwież.
Przegląd wyników końcowych
W programie SQL Server Management Studio uruchom następujące zapytania względem docelowej bazy danych SQL, aby sprawdzić, czy zaktualizowane/nowe dane zostały skopiowane z tabel źródłowych do tabel docelowych.
Zapytanie
select * from customer_table
Wyjście
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Zwróć uwagę na nowe wartości właściwości Name i LastModifytime dla identyfikatora PersonID numeru 3.
Zapytanie
select * from project_table
Wyjście
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Zwróć uwagę, że do tabeli project_table dodano pozycję NewProject.
Zapytanie
select * from watermarktable
Wyjście
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Należy zauważyć, że wartości limitu dla obu tabel zostały zaktualizowane.
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Przygotowanie źródłowych i docelowych magazynów danych
- Tworzenie fabryki danych.
- Tworzenie własnego środowiska Integration Runtime.
- Instalowanie środowiska Integration Runtime.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie, uruchamianie i monitorowanie potoku
- Przejrzyj wyniki.
- Dodawanie lub aktualizowanie danych w tabelach źródłowych.
- Ponowne uruchamianie i monitorowanie potoku.
- Przegląd wyników końcowych.
Przejdź do następującego samouczka, aby dowiedzieć się więcej o przekształcaniu danych za pomocą klastra Spark na platformie Azure: